不用框架,实现非连续语音识别Demo(python源码)
GMM-HMM语音识别原理
1. HMM
隐马尔科夫模型(HMM)是一种统计模型,用来描述含有隐含参数的马尔科夫过程。难点是从隐含状态确定出马尔科夫过程的参数,以此作进一步的分析。下图是一个三个状态的隐马尔可夫模型状态转移图,其中x 表示隐含状态,y 表示可观察的输出,a 表示状态转换概率,b 表示输出概率:
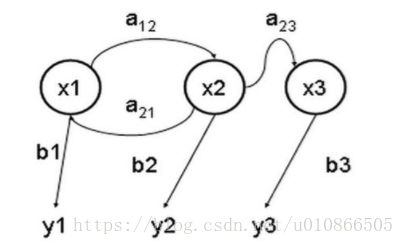
a:转移概率
b:输出概率
y:观测状态
x:隐含状态
一个HMM模型是一个五元组(π,A,B,O,S)
其中π:初始概率向量
A: 转移概率
B: 输出概率
O:观测状态
S:隐含状态
围绕着HMM,有三个和它相关的问题:
1. 已知隐含状态数目,已知转移概率,根据观测状态,估计观测状态对应的隐含状态
2. 已知隐含状态数目,已知转移概率,根据观测状态,估计输出这个观测状态的概率
3. 已知隐含状态数目,根据大量实验结果(很多组观测状态),反推转移概率
对于第一个问题,所对应的就是维特比算法
对于第二个问题,所对应的就是前向算法
对于第三个问题,就是前向后向算法
语音识别的过程其实就是上述的第一个问题。根据HMM模型和观测状态(即语音信号数字信号处理后的内容),得到我们要的状态,而状态的组合就是识别出来的文本。
为啥呢?
1) 在语音处理中,一个word有一个或多个音素构成。怎么说呢?这里补充一下语言学的一些知识。在语言学中,word(字)还可以再分解成音节(syllable),音节可以再分成音素(phoneme),音素之后就不能再分了.因此音素是语音中最小的单元,不管语音识别还是语音合成,都是在最小单元上进行操作的,即phoneme。比如我们的“我”,它的拼音是wo3(这个其实就是word,即字),由于中文的word和syllable是相同的,即中文是单音节语言,即中文有且只有一个音节,但英文就不一样,比如hello这个单词,他就是有两个音节,hello=hae|low,即hello有hae和low这两个音节组成.音节下一层是phoneme(音素),语音识别的过程就是把这些 音素找到,然后音素拼接成音节,音节在拼接成word.如下图所示
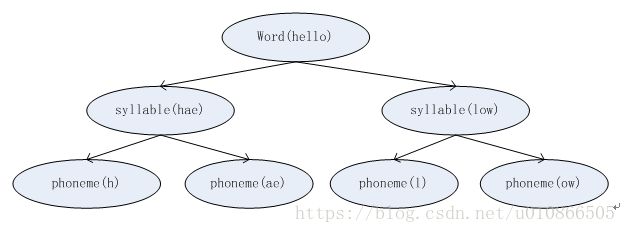
在识别过程中如果识别出来了音素,向上递归,就能得到word。
因此我们的目标是获取音素phoneme.
2) 在训练时,一个HMM对应一个音素,每个HMM包含n个state(状态),有的是3个状态,有的是5个状态,状态数在训练前确定后,一旦训练完成所有HMM的状态个数都是一致的,比如3个。
GMM是当做发射概率的,即在已知观测状态情况下,哪一种音素会产生这种状态的概率,概率最大的就是我们要的音素。因此,GMM是来计算某一个音素的概率。
GMM的全称是gaussmixture model(高斯混合模型),在训练前,一般会定义由几个高斯来决定音素的概率(高斯数目是超参数)。如下图所示为3高斯:
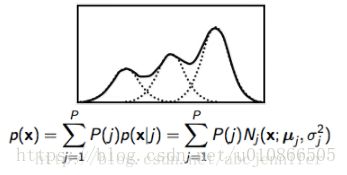
假设现在我们定义一个HMM由3个状态组成,每个状态中有一个GMM,每个GMM中是由3个gauss。
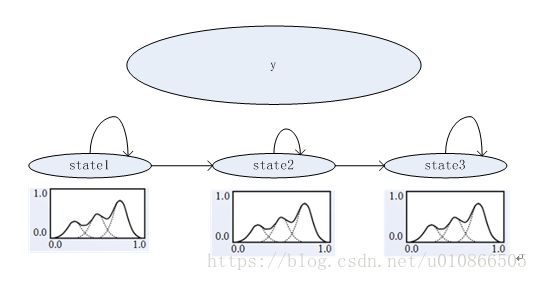
如上图假设y有状态1,2,3组成,每一个状态下面有一个GMM,高斯个数是3.
由此我们训练的参数有HMM的转移概率矩阵+每一个单高斯的方差,均值和权重(当然还有一个初始概率矩阵).如果我们能得到这些参数,我们是不是就能进行语音识别了?
接下来,就看看GMM-HMM到底是如何做到的?
1:将送进来的语音信号进行分帧(一般是20ms一帧,帧移是10ms),然后提取特征
2:用GMM,判断当前的特征序列属于哪个状态(计算概率)
3:根据前面两个步骤,得出状态序列,其实就得到了音素序列,即得到了声韵母序列。
如下面图所示.

对于GMM-HMM实现语音识别(确切的说是非连续语音识别),到此基本上就结束了,对于连续语音识别而言,还有一个语言模型(主要是通过语料库,n-gram模型)。而前面的GMM-HMM就是声学模型.
代码解析:
下面是关于GMM-HMM声学模型,特征序列提取到训练,并且实现识别的完整代码(操作系统:ubuntu16.04,python2)
该demo总共有三个文件,
1:gParam.py,主要是为了配置一些参数
2:核心文件是my_hmm.py,里面实现的是主要代码。
3:test.py是运行文件.
该demo主要是实现识别阿拉伯数字,1,2,3,4.....你可以自己录制训练数据和测试数据.然后设置好路径,运行下面的程序.
程序是完整的
程序是完整的
程序是完整的
说三遍.
wav数据的格式是:

gParam.py 代码解析:
#! /usr/bin python
# encoding:utf-8
TRAIN_DATA_PATH = './data/train/'
TEST_DATA_PATH = './data/test/'
NSTATE = 4
NPDF = 3
MAX_ITER_CNT = 100
NUM=10这个就没什么好说的。设置路径参数而已.
核心文件my_hmm.py:
#! /usr/bin python
# encoding:utf_8
import numpy as np
from numpy import *
from sklearn.cluster import KMeans
from scipy import sparse
import scipy.io as sio
from scipy import signal
import wave
import math
import gParam
import copy
def pdf(m,v,x):
'''计算多元高斯密度函数
输入:
m---均值向量 SIZE×1
v---方差向量 SIZE×1
x---输入向量 SIZE×1
输出:
p---输出概率'''
test_v = np.prod(v,axis=0)
test_x = np.dot((x-m)/v,x-m)
p = (2*math.pi*np.prod(v,axis=0))**-0.5*np.exp(-0.5*np.dot((x-m)/v,x-m))
return p
# class of every sample infomation
class sampleInfo:
"""docstring for ClassName"""
def __init__(self):
self.smpl_wav = []
self.smpl_data = []
self.seg = []
def set_smpl_wav(self,wav):
self.smpl_wav.append(wav)
def set_smpl_data(self,data):
self.smpl_data.append(data)
def set_segment(self, seg_list):
self.seg = seg_list
#class of mix info from KMeans
class mixInfo:
"""docstring for mixInfo"""
def __init__(self):
self.Cmean = []
self.Cvar = []
self.Cweight = []
self.CM = []
class hmmInfo:
'''hmm model param'''
def __init__(self):
self.init = [] #初始矩阵
self.trans = [] #转移概率矩阵
self.mix = [] #高斯混合模型参数
self.N = 0 #状态数
# class of gmm_hmm model
class gmm_hmm:
def __init__(self):
self.hmm = [] #单个hmm序列,
self.gmm_hmm_model = [] #把所有的训练好的gmm-hmm写入到这个队列
self.samples = [] # 0-9 所有的音频数据
self.smplInfo = [] #这里面主要是单个数字的音频数据和对应mfcc数据
self.stateInfo = [gParam.NPDF,gParam.NPDF,gParam.NPDF,gParam.NPDF]#每一个HMM对应len(stateInfo)个状态,每个状态指定高斯个数(3)
def loadWav(self,pathTop):
for i in range(gParam.NUM):
tmp_data = []
for j in range(gParam.NUM):
wavPath = pathTop + str(i) + str(j) + '.wav'
f = wave.open(wavPath,'rb')
params = f.getparams()
nchannels,sampwidth,framerate,nframes = params[:4]
str_data = f.readframes(nframes)
#print shape(str_data)
f.close()
wave_data = np.fromstring(str_data,dtype=short)/32767.0
#wave_data.shape = -1,2
#wave_data = wave_data.T
#wave_data = wave_data.reshape(1,wave_data.shape[0]*wave_data.shape[1])
#print shape(wave_data),type(wave_data)
tmp_data.append(wave_data)
self.samples.append(tmp_data)
#循环读数据,然后进行训练
def hmm_start_train(self):
Nsmpls = len(self.samples)
for i in range(Nsmpls):
tmpSmplInfo0 = []
n = len(self.samples[i])
for j in range(n):
tmpSmplInfo1 = sampleInfo()
tmpSmplInfo1.set_smpl_wav(self.samples[i][j])
tmpSmplInfo0.append(tmpSmplInfo1)
#self.smplInfo.append(tmpSmplInfo0)
print '现在训练第%d个HMM模型' %i
hmm0 = self.trainhmm(tmpSmplInfo0,self.stateInfo)
print '第%d个模型已经训练完毕' %i
# self.gmm_hmm_model.append(hmm0)
#训练hmm
def trainhmm(self,sample,state):
K = len(sample)
print '首先进行语音参数计算-MFCC'
for k in range(K):
tmp = self.mfcc(sample[k].smpl_wav)
sample[k].set_smpl_data(tmp) # 设置MFCCdata
hmm = self.inithmm(sample,state)
pout = zeros((gParam.MAX_ITER_CNT,1))
for my_iter in range(gParam.MAX_ITER_CNT):
print '第%d遍训练' %my_iter
hmm = self.baum(hmm,sample)
for k in range(K):
pout[my_iter,0] = pout[my_iter,0] + self.viterbi(hmm,sample[k].smpl_data[0])
if my_iter > 0:
if(abs((pout[my_iter,0] - pout[my_iter-1,0])/pout[my_iter,0]) < 5e-6):
print '收敛'
self.gmm_hmm_model.append(hmm)
return hmm
self.gmm_hmm_model.append(hmm)
#获取MFCC参数
def mfcc(self,k):
M = 24 #滤波器的个数
N = 256 #一帧语音的采样点数
arr_mel_bank = self.melbank(M,N,8000,0,0.5,'m')
arr_mel_bank = arr_mel_bank/np.amax(arr_mel_bank)
#计算DCT系数, 12*24
rDCT = 12
cDCT = 24
dctcoef = []
for i in range(1,rDCT+1):
tmp = [np.cos((2*j+1)*i*math.pi*1.0/(2.0*cDCT)) for j in range(cDCT)]
dctcoef.append(tmp)
#归一化倒谱提升窗口
w = [1+6*np.sin(math.pi*i*1.0/rDCT) for i in range(1,rDCT+1)]
w = w/np.amax(w)
#预加重
AggrK = double(k)
AggrK = signal.lfilter([1,-0.9375],1,AggrK)# ndarray
#AggrK = AggrK.tolist()
#分帧
FrameK = self.enframe(AggrK[0],N,80)
n0,m0 = FrameK.shape
for i in range(n0):
#temp = multiply(FrameK[i,:],np.hamming(N))
#print shape(temp)
FrameK[i,:] = multiply(FrameK[i,:],np.hamming(N))
FrameK = FrameK.T
#计算功率谱
S = (abs(np.fft.fft(FrameK,axis=0)))**2
#将功率谱通过滤波器组
P = np.dot(arr_mel_bank,S[0:129,:])
#取对数后做余弦变换
D = np.dot(dctcoef,log(P))
n0,m0 = D.shape
m = []
for i in range(m0):
m.append(np.multiply(D[:,i],w))
n0,m0 = shape(m)
dtm = zeros((n0,m0))
for i in range(2,n0-2):
dtm[i,:] = -2*m[i-2][:] - m[i-1][:] + m[i+1][:] + 2*m[i+2][:]
dtm = dtm/3.0
# cc = [m,dtm]
cc =np.column_stack((m,dtm))
# cc.extend(list(dtm))
cc = cc[2:n0-2][:]
#print shape(cc)
return cc
#melbank
def melbank(self,p,n,fs,f1,fh,w):
f0 = 700.0/(1.0*fs)
fn2 = floor(n/2.0)
lr = math.log((float)(f0+fh)/(float)(f0+f1))/(float)(p+1)
tmpList = [0,1,p,p+1]
bbl = []
for i in range(len(tmpList)):
bbl.append(n*((f0+f1)*math.exp(tmpList[i]*lr) - f0))
#b1 = n*((f0+f1) * math.exp([x*lr for x in tmpList]) - f0)
#print bbl
b2 = ceil(bbl[1])
b3 = floor(bbl[2])
if(w == 'y'):
pf = np.log((f0+range(b2,b3)/n)/(f0+f1))/lr #note
fp = floor(pf)
r = [ones((1,b2)),fp,fp+1, p*ones((1,fn2-b3))]
c = [range(0,b3),range(b2,fn2)]
v = 2*[0.5,ones((1,b2-1)),1-pf+fp,pf-fp,ones((1,fn2-b3-1)),0.5]
mn = 1
mx = fn2+1
else:
b1 = floor(bbl[0])+1
b4 = min([fn2,ceil(bbl[3])])-1
pf = []
for i in range(int(b1),int(b4+1),1):
pf.append(math.log((f0+(1.0*i)/n)/(f0+f1))/lr)
fp = floor(pf)
pm = pf - fp
k2 = b2 - b1 + 1
k3 = b3 - b1 + 1
k4 = b4 - b1 + 1
r = fp[int(k2-1):int(k4)]
r1 = 1+fp[0:int(k3)]
r = r.tolist()
r1 = r1.tolist()
r.extend(r1)
#r = [fp[int(k2-1):int(k4)],1+fp[0:int(k3)]]
c = range(int(k2),int(k4+1))
c2 = range(1,int(k3+1))
# c = c.tolist()
# c2 = c2.tolist()
c.extend(c2)
#c = [range(int(k2),int(k4+1)),range(0,int(k3))]
v = 1-pm[int(k2-1):int(k4)]
v = v.tolist()
v1 = pm[0:int(k3)]
v1 = v1.tolist()
v.extend(v1)#[1-pm[int(k2-1):int(k4)],pm[0:int(k3)]]
v = [2*x for x in v]
mn = b1 + 1
mx = b4 + 1
if(w == 'n'):
v = 1 - math.cos(v*math.pi/2)
elif (w == 'm'):
tmpV = []
# for i in range(v):
# tmpV.append(1-0.92/1.08*math.cos(v[i]*math))
v = [1 - 0.92/1.08*math.cos(x*math.pi/2) for x in v]
#print type(c),type(mn)
col_list = [x+int(mn)-2 for x in c]
r = [x-1 for x in r]
x = sparse.coo_matrix((v,(r,col_list)),shape=(p,1+int(fn2)))
matX = x.toarray()
#np.savetxt('./data.csv',matX, delimiter=' ')
return matX#x.toarray()
#分帧函数
def enframe(self,x,win,inc):
nx = len(x)
try:
nwin = len(win)
except Exception as err:
# print err
nwin = 1
if (nwin == 1):
wlen = win
else:
wlen = nwin
#print inc,wlen,nx
nf = fix(1.0*(nx-wlen+inc)/inc) #here has a bug that nf maybe less than 0
f = zeros((int(nf),wlen))
indf = [inc*j for j in range(int(nf))]
indf = (mat(indf)).T
inds = mat(range(wlen))
indf_tile = tile(indf,wlen)
inds_tile = tile(inds,(int(nf),1))
mix_tile = indf_tile + inds_tile
for i in range(nf):
for j in range(wlen):
f[i,j] = x[mix_tile[i,j]]
#print x[mix_tile[i,j]]
if nwin>1: #TODOd
w = win.tolist()
#w_tile = tile(w,(int))
return f
# init hmm
def inithmm(self,sample,M):
K = len(sample)
N0 = len(M)
self.N = N0
#初始概率矩阵
hmm = hmmInfo()
hmm.init = zeros((N0,1))
hmm.init[0] = 1
hmm.trans = zeros((N0,N0))
hmm.N = N0
#初始化转移概率矩阵
for i in range(self.N-1):
hmm.trans[i,i] = 0.5
hmm.trans[i,i+1] = 0.5
hmm.trans[self.N-1,self.N-1] = 1
#概率密度函数的初始聚类
#分段
for k in range(K):
T = len(sample[k].smpl_data[0])
#seg0 = []
seg0 = np.floor(arange(0,T,1.0*T/N0))
#seg0 = int(seg0.tolist())
seg0 = np.concatenate((seg0,[T]))
#seg0.append(T)
sample[k].seg = seg0
#对属于每个状态的向量进行K均值聚类,得到连续混合正态分布
mix = []
for i in range(N0):
vector = []
for k in range(K):
seg1 = int(sample[k].seg[i])
seg2 = int(sample[k].seg[i+1])
tmp = []
tmp = sample[k].smpl_data[0][seg1:seg2][:]
if k == 0:
vector = np.array(tmp)
else:
vector = np.concatenate((vector, np.array(tmp)))
#vector.append(tmp)
# tmp_mix = mixInfo()
# print id(tmp_mix)
tmp_mix = self.get_mix(vector,M[i],mix)
# mix.append(tmp_mix)
hmm.mix = mix
return hmm
# get mix data
def get_mix(self,vector,K,mix0):
kmeans = KMeans(n_clusters = K,random_state=0).fit(np.array(vector))
#计算每个聚类的标准差,对角阵,只保存对角线上的元素
mix = mixInfo()
var0 = []
mean0 = []
#ind = []
for j in range(K):
#ind = [i for i in kmeans.labels_ if i==j]
ind = []
ind1 = 0
for i in kmeans.labels_:
if i == j:
ind.append(ind1)
ind1 = ind1 + 1
tmp = [vector[i][:] for i in ind]
var0.append(np.std(tmp,axis=0))
mean0.append(np.mean(tmp,axis=0))
weight0 = zeros((K,1))
for j in range(K):
tmp = 0
ind1 = 0
for i in kmeans.labels_:
if i == j:
tmp = tmp + ind1
ind1 = ind1 + 1
weight0[j] = tmp
weight0=weight0/weight0.sum()
mix.Cvar = multiply(var0,var0)
mix.Cmean = mean0
mix.CM = K
mix.Cweight = weight0
mix0.append(mix)
return mix0
#baum-welch 算法实现函数体
def baum(self,hmm,sample):
mix = copy.deepcopy(hmm.mix)#高斯混合
N = len(mix) #HMM状态数
K = len(sample) #语音样本数
SIZE = shape(sample[0].smpl_data[0])[1] #参数阶数,MFCC维数
print '计算样本参数.....'
c = []
alpha = []
beta = []
ksai = []
gama = []
for k in range(K):
c0,alpha0,beta0,ksai0,gama0 = self.getparam(hmm, sample[k].smpl_data[0])
c.append(c0)
alpha.append(alpha0)
beta.append(beta0)
ksai.append(ksai0)
gama.append(gama0)
# 重新估算概率转移矩阵
print '----- 重新估算概率转移矩阵 -----'
for i in range(N-1):
denom = 0
for k in range(K):
ksai0 = ksai[k]
tmp = ksai0[:,i,:]#ksai0[:][i][:]
denom = denom + sum(tmp)
for j in range(i,i+2):
norm = 0
for k in range(K):
ksai0 = ksai[k]
tmp = ksai0[:,i,j]#[:][i][j]
norm = norm + sum(tmp)
hmm.trans[i,j] = norm/denom
# 重新估算发射概率矩阵,即GMM的参数
print '----- 重新估算输出概率矩阵,即GMM的参数 -----'
for i in range(N):
for j in range(mix[i].CM):
nommean = zeros((1,SIZE))
nomvar = zeros((1,SIZE))
denom = 0
for k in range(K):
gama0 = gama[k]
T = shape(sample[k].smpl_data[0])[0]
for t in range(T):
x = sample[k].smpl_data[0][t][:]
nommean = nommean + gama0[t,i,j]*x
nomvar = nomvar + gama0[t,i,j] * (x - mix[i].Cmean[j][:])**2
denom = denom + gama0[t,i,j]
hmm.mix[i].Cmean[j][:] = nommean/denom
hmm.mix[i].Cvar[j][:] = nomvar/denom
nom = 0
denom = 0
#计算pdf权值
for k in range(K):
gama0 = gama[k]
tmp = gama0[:,i,j]
nom = nom + sum(tmp)
tmp = gama0[:,i,:]
denom = denom + sum(tmp)
hmm.mix[i].Cweight[j] = nom/denom
return hmm
#前向-后向算法
def getparam(self,hmm,O):
'''给定输出序列O,计算前向概率alpha,后向概率beta
标定系数c,及ksai,gama
输入: O:n*d 观测序列
输出: param: 包含各种参数的结构'''
T = shape(O)[0]
init = hmm.init #初始概率
trans = copy.deepcopy(hmm.trans) #转移概率
mix = copy.deepcopy(hmm.mix) #高斯混合
N = hmm.N #状态数
#给定观测序列,计算前向概率alpha
x = O[0][:]
alpha = zeros((T,N))
#----- 计算前向概率alpha -----#
for i in range(N): #t=0
tmp = hmm.init[i] * self.mixture(mix[i],x)
alpha[0,i] = tmp #hmm.init[i]*self.mixture(mix[i],x)
#标定t=0时刻的前向概率
c = zeros((T,1))
c[0] = 1.0/sum(alpha[0][:])
alpha[0][:] = c[0] * alpha[0][:]
for t in range(1,T,1): # t = 1~T
for i in range(N):
temp = 0.0
for j in range(N):
temp = temp + alpha[t-1,j]*trans[j,i]
alpha[t,i] = temp *self.mixture(mix[i],O[t][:])
c[t] = 1.0/sum(alpha[t][:])
alpha[t][:] = c[t]*alpha[t][:]
#----- 计算后向概率 -----#
beta = zeros((T,N))
for i in range(N): #T时刻
beta[T-1,i] = c[T-1]
for t in range(T-2,-1,-1):
x = O[t+1][:]
for i in range(N):
for j in range(N):
beta[t,i] = beta[t,i] + beta[t+1,j]*self.mixture(mix[j],x) * trans[i,j]
beta[t][:] = c[t] * beta[t][:]
# 过渡概率ksai
ksai = zeros((T-1,N,N))
for t in range(0,T-1):
denom = sum(np.multiply(alpha[t][:],beta[t][:]))
for i in range(N-1):
for j in range(i,i+2,1):
norm = alpha[t,i]*trans[i,j]*self.mixture(mix[j],O[t+1][:])*beta[t+1,j]
ksai[t,i,j] = c[t]*norm/denom
# 混合输出概率 gama
gama = zeros((T,N,max(self.stateInfo)))
for t in range(T):
pab = zeros((N,1))
for i in range(N):
pab[i] = alpha[t,i]*beta[t,i]
x = O[t][:]
for i in range(N):
prob = zeros((mix[i].CM,1))
for j in range(mix[i].CM):
m = mix[i].Cmean[j][:]
v = mix[i].Cvar[j][:]
prob[j] = mix[i].Cweight[j] * pdf(m,v,x)
if mix[i].Cweight[j] == 0.0:
print pdf(m,v,x)
tmp = pab[i]/pab.sum()
tmp = tmp[0]
temp_sum = prob.sum()
for j in range(mix[i].CM):
gama[t,i,j] = tmp*prob[j]/temp_sum
return c,alpha,beta,ksai,gama
def mixture(self,mix,x):
'''计算输出概率
输入:mix--混合高斯结构
x--输入向量 SIZE*1
输出: prob--输出概率'''
prob = 0.0
for i in range(mix.CM):
m = mix.Cmean[i][:]
v = mix.Cvar[i][:]
w = mix.Cweight[i]
tmp = pdf(m,v,x)
#print tmp
prob = prob + w * tmp #* pdf(m,v,x)
if prob == 0.0:
prob = 2e-100
return prob
#维特比算法
def viterbi(self,hmm,O):
'''%输入:
hmm -- hmm模型
O -- 输入观察序列, N*D, N为帧数,D为向量维数
输出:
prob -- 输出概率
q -- 状态序列
'''
init = copy.deepcopy(hmm.init)
trans = copy.deepcopy(hmm.trans)#hmm.trans
mix = hmm.mix
N = hmm.N
T = shape(O)[0]
#计算Log(init)
n_init = len(init)
for i in range(n_init):
if init[i] <= 0:
init[i] = -inf
else:
init[i]=log(init[i])
#计算log(trans)
m,n = shape(trans)
for i in range(m):
for j in range(n):
if trans[i,j] <=0:
trans[i,j] = -inf
else:
trans[i,j] = log(trans[i,j])
#初始化
delta = zeros((T,N))
fai = zeros((T,N))
q = zeros((T,1))
#t=0
x = O[0][:]
for i in range(N):
delta[0,i] = init[i] + log(self.mixture(mix[i],x))
#t=2:T
for t in range(1,T):
for j in range(N):
tmp = delta[t-1][:]+trans[:][j].T
tmp = tmp.tolist()
delta[t,j] = max(tmp)
fai[t,j] = tmp.index(max(tmp))
x = O[t][:]
delta[t,j] = delta[t,j] + log(self.mixture(mix[j],x))
tmp = delta[T-1][:]
tmp = tmp.tolist()
prob = max(tmp)
q[T-1]=tmp.index(max(tmp))
for t in range(T-2,-1,-1):
q[t] = fai[t+1,int(q[t+1,0])]
return prob
# ----------- 以下是用于测试的程序 ---------- #
#
def vad(self,k,fs):
'''语音信号端点检测程序
k ---语音信号
fs ---采样率
返回语音信号的起始和终止端点'''
k = double(k)
k = multiply(k,1.0/max(abs(k)))
# 计算短时过零率
FrameLen = 240
FrameInc = 80
FrameTemp1 = self.enframe(k[0:-2], FrameLen, FrameInc)
FrameTemp2 = self.enframe(k[1:], FrameLen, FrameInc)
signs = np.sign(multiply(FrameTemp1, FrameTemp2))
signs = map(lambda x:[[i,0] [i>0] for i in x],signs)
signs = map(lambda x:[[i,1] [i<0] for i in x], signs)
diffs = np.sign(abs(FrameTemp1 - FrameTemp2)-0.01)
diffs = map(lambda x:[[i,0] [i<0] for i in x], diffs)
zcr = sum(multiply(signs, diffs),1)
# 计算短时能量
amp = sum(abs(self.enframe(signal.lfilter([1,-0.9375],1,k),FrameLen, FrameInc)),1)
# print '短时能量%f' %amp
# 设置门限
print '设置门限'
ZcrLow = max([round(mean(zcr)*0.1),3])#过零率低门限
ZcrHigh = max([round(max(zcr)*0.1),5])#过零率高门限
AmpLow = min([min(amp)*10,mean(amp)*0.2,max(amp)*0.1])#能量低门限
AmpHigh = max([min(amp)*10,mean(amp)*0.2,max(amp)*0.1])#能量高门限
# 端点检测
MaxSilence = 8 #最长语音间隙时间
MinAudio = 16 #最短语音时间
Status = 0 #状态0:静音段,1:过渡段,2:语音段,3:结束段
HoldTime = 0 #语音持续时间
SilenceTime = 0 #语音间隙时间
print '开始端点检测'
StartPoint = 0
for n in range(len(zcr)):
if Status ==0 or Status == 1:
if amp[n] > AmpHigh or zcr[n] > ZcrHigh:
StartPoint = n - HoldTime
Status = 2
HoldTime = HoldTime + 1
SilenceTime = 0
elif amp[n] > AmpLow or zcr[n] > ZcrLow:
Status = 1
HoldTime = HoldTime + 1
else:
Status = 0
HoldTime = 0
elif Status == 2:
if amp[n] > AmpLow or zcr[n] > ZcrLow:
HoldTime = HoldTime + 1
else:
SilenceTime = SilenceTime + 1
if SilenceTime < MaxSilence:
HoldTime = HoldTime + 1
elif (HoldTime - SilenceTime) < MinAudio:
Status = 0
HoldTime = 0
SilenceTime = 0
else:
Status = 3
elif Status == 3:
break
if Status == 3:
break
HoldTime = HoldTime - SilenceTime
EndPoint = StartPoint + HoldTime
return StartPoint,EndPoint
def recog(self,pathTop):
N = gParam.NUM
for i in range(N):
wavPath = pathTop + str(i) + '.wav'
f = wave.open(wavPath,'rb')
params = f.getparams()
nchannels,sampwidth,framerate,nframes = params[:4]
str_data = f.readframes(nframes)
#print shape(str_data)
f.close()
wave_data = np.fromstring(str_data,dtype=short)/32767.0
x1,x2 = self.vad(wave_data,framerate)
O = self.mfcc([wave_data])
O = O[x1-3:x2-3][:]
print '第%d个词的观察矢量是:%d' %(i,i)
pout = []
for j in range(N):
pout.append(self.viterbi(self.gmm_hmm_model[j],O))
n = pout.index(max(pout))
print '第%d个词,识别是%d' %(i,n)
接下来就是test.py文件:
#! /usr/bin python
# encoding:utf-8
import numpy as np
from numpy import *
import gParam
from my_hmm import gmm_hmm
my_gmm_hmm = gmm_hmm()
my_gmm_hmm.loadWav(gParam.TRAIN_DATA_PATH)
#print len(my_gmm_hmm.samples[0])
my_gmm_hmm.hmm_start_train()
my_gmm_hmm.recog(gParam.TEST_DATA_PATH)
#my_gmm_hmm.melbank(24,256,8000,0,0.5,'m')
# my_gmm_hmm.mfcc(range(17280))
#my_gmm_hmm.enframe(range(0,17280),256,80)
最后运行的结果如下图所示:


最后:如果您想直接跑程序,您可以通过以下方式获取我的数据和源程序。由于考虑到个人的人工成本,我形式上只收取5块钱的人工费,既是对我的支持,也是对我的鼓励。谢谢大家的理解。把订单后面6位号码发送给我,我把源码和数据给您呈上。谢谢。
1:扫如下支付宝或微信二维码,支付5元
2:把支付单号的后6位,以邮件发送到我的邮箱[email protected]
3:您也可以在下方留言,把订单号写上来,我会核实。
谢谢大家。

