Kafka 单机和分布式环境搭建与案例使用
实验环境:
1、Ubuntu Server 16.04
2、kafka_2.11-0.11.0.0
一、单机环境搭建
官方参考文章:
http://kafka.apache.org/quickstart
1、下载和解压安装包
这里下载了zookeeper和kafaka两个安装包,下载地址:
zookeeper:http://www.apache.org/dyn/closer.cgi/zookeeper/
kafka:http://kafka.apache.org/downloads

2、启动Zookeeper服务
这里的kafka默认是由内置的zookeeper的,如果使用内置的zookeeper的话,启动的方式如下:
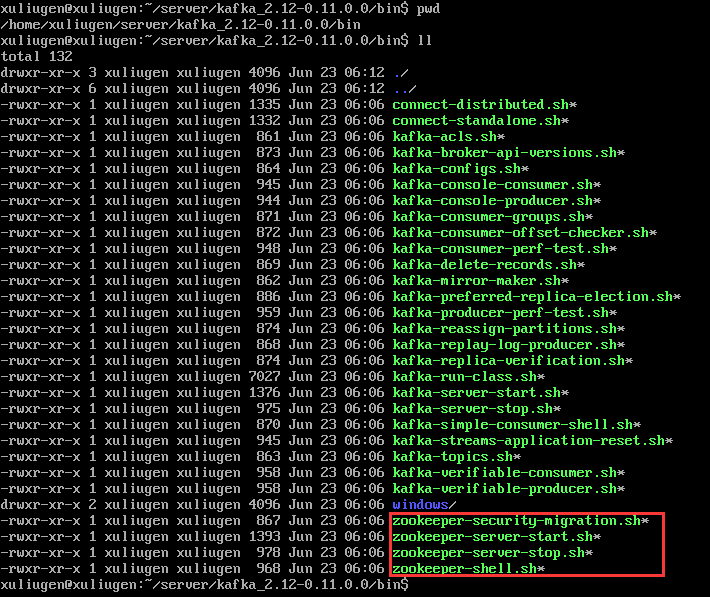
zookeeper的配置文件是在:/kafka_2.12-0.11.0.0/config 目录下
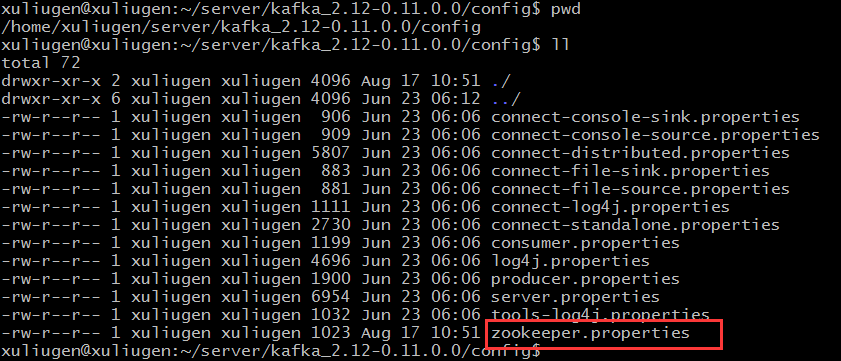
启动Zookeeper:
>bin/zookeeper-server-start.sh config/zookeeper.properties
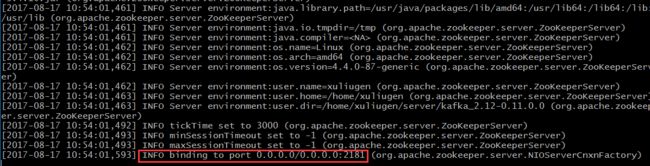
当看到如下信息的时候,就表示成功了!
3、启动Kafka
kafka的配置文件是在/kafka_2.12-0.11.0.0/config 目录下,默认情况下不需要修改。
>bin/kafka-server-start.sh config/server.properties
4、创建一个Topic
> bin/kafka-topics.sh --create --zookeeper localhost:2181 --replication-factor 1 --partitions 1 --topic testTopic
–replication-factor 复制因子为1;
–partitions 分区为1;
查看已创建的Topic:

5、发送测试消息
kafka支持从Console发送信息,消费者从Console接受信息。
>bin/kafka-console-producer.sh --broker-list localhost:9092 --topic testTopic
–broker-list 表示代理服务器的列表,这里只有一个;
创建一个消费者:
>bin/kafka-console-consumer.sh --bootstrap-server localhost:9092 --topic testTopic --from-beginning
–from-beginning 表示从消息开始处读取;
然后在生产者的Console输入数据,消费者的Console就可以看到信息:


二、伪集群环境搭建
官方提供了一种方式在一台机器上启动多个Broker机器构成multi-broker cluster,这是一种伪集群的方式,下边就配置一下。
1、修改配置文件
思路是配置多个config/server.properties文件,修改其中的broker.id=1 和端口号,日志文件位置。
> cp config/server.properties config/server-1.properties
> cp config/server.properties config/server-2.properties
编辑配置文件,修改如下对应的位置:
config/server-1.properties:
broker.id=1
listeners=PLAINTEXT://:9093
log.dir=/tmp/kafka-logs-1
config/server-2.properties:
broker.id=2
listeners=PLAINTEXT://:9094
log.dir=/tmp/kafka-logs-2
2、分别启动另外两个Kafka
>bin/kafka-server-start.sh config/server-1.properties &
>>bin/kafka-server-start.sh config/server-2.properties &
&表示在后台运行
3、查看运行结果:
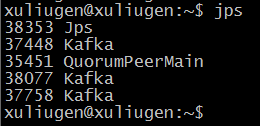
QuorumPeerMain表示Zookeeper进行;
另外有3个Kafka进程;
4、创建Topic
新建一个复制因子为3的Topic
>bin/kafka-topics.sh --create --zookeeper localhost:2181 --replication-factor 3 --partitions 1 --topic my-replicated-topic

查看Topic的描述信息:
>bin/kafka-topics.sh --describe --zookeeper localhost:2181 --topic my-replicated-topic

5、发送消息
启动生产者,这里有3个Kafka实例,但是–broker-list 仍是启动的Zookeeper服务。
>bin/kafka-console-producer.sh --broker-list localhost:9092 --topic my-replicated-topic
启动消费者:
>bin/kafka-console-consumer.sh --bootstrap-server localhost:9092 --from-beginning --topic my-replicated-topic
和单机的情况是一样的。
三、分布式集群环境搭建
搭建的分布式集群和伪集群的方式大致相同,这里假设使用3台服务器模拟实验,部署3个Zookeeper实例和3个Kafka实例,当然也可以直接部署一个Zookeeper实例,这里只是演示分布式Zookeeper和kafka的搭建。
工具使用的是SecureCRT。
1、分布式Zookeeper的搭建
(1)将Zookeeper安装包分别上传到3台服务器,我的是放在:/home/xuliugen/server 目录下。
(2)配置第一台Zookeeper
复制zookeeper-3.4.10/conf/zoo_sample.cfg 为 zookeeper-3.4.10/conf/zoo.cfg,修改zoo.cfg文件如下,只更改data的目录:

因为,修改了dataDir目录的位置,那么就需要创建一个/zookeeper-3.4.6/data目录。
(3)按同样的方式修改第二台Zookeeper和第三台Zookeeper服务器配置。
(4)然后,在每一台Zookeeper的配置文件中的最下边添加Zookeeper的集群配置:

(5)最后创建每一个Zookeeper的 myid 文件,在/data/myid文件
xuliugen@xuliugen-pc:~/server/zookeeper-3.4.6/data$ echo 1 > myid
则,另外两台分别为:
xuliugen@xuliugen-pc:~/server/zookeeper-3.4.6/data$ echo 2 > myid
xuliugen@xuliugen-pc:~/server/zookeeper-3.4.6/data$ echo 3 > myid
注意:
1、myid和IP地址的对应
server.1=
server.2=
server.3=
这里的1、2、3是和我们刚才配置的myid的数值是相对应的,即1的IP地址为192.168.1.120,那么server.1=192.168.1.120:2888:3888
2、防火墙端口的配置
另外,2888:3888端口要设置防火墙权限
2、启动Zookeeper服务器
依此使用命令./bin/zkServer.sh start 启动Zookeeper服务。
使用jps 查看是否已经启动

查看zookeeper日志的话,是在/zookeeper-3.4.6/bin 目录下的zookeeper.out 文件:
使用tailf zookeeper.out 可以进行查看。
3、分布式Kafka的搭建
(1)将Kafka安装包分别上传到3台服务器,我的是放在:/home/xuliugen/server 目录下。
(2)配置第一台Kafka
Kafka的配置文件是在/conf/server.properties ,修改日志的目录:

配置主机IP或者hostname:
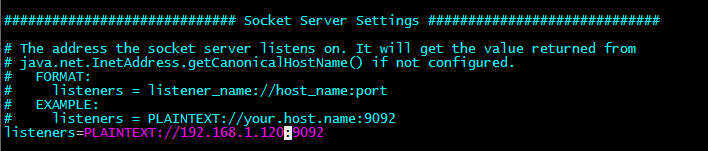
然后修改kafka中使用的Zookeeper集群地址:

多个Zookeeper之间以英文逗号分开。
注意:
这里需要注意的是,如果按照上述的方式配置:
listeners=PLAINTEXT://192.168.1.120:9092
这样配置的话,是在内网环境下允许的,如果使用外网进行访问的话,可以配置为如下:

具体请参考:
http://blog.csdn.net/fengcai19/article/details/54695874?utm_source=itdadao&utm_medium=referral
(3)按同样的方式配置第二台kafka和第三台kafka服务器。
要注意的是不同的kafka的broker.id 一定要不一样,我这里分别配置的是0、1、2。

4、分别启动Kafka服务
>bin/kafka-server-start.sh config/server.properties
四、代码测试
1、项目结构
2、pom文件内容
org.apache.kafka
kafka-clients
0.11.0.0
org.slf4j
slf4j-log4j12
1.7.12
org.slf4j
slf4j-api
1.7.12
3、日志配置log4j.properties
log4j.rootLogger=DEBUG,rolling,errlog,stdout
#stdout log
log4j.appender.stdout=org.apache.log4j.ConsoleAppender
log4j.appender.stdout.layout=org.apache.log4j.PatternLayout
log4j.appender.stdout.layout.ConversionPattern=%d{HH:mm:ss} [%-5p] %c{1}.%M:%L-[%X{traceId}]-%m%n
#common log
log4j.appender.rolling=org.apache.log4j.DailyRollingFileAppender
log4j.appender.rolling.File=${catalina.base}/logs/kafka-demo.log
log4j.appender.rolling.DatePattern='.'yyyy-MM-dd-HH
log4j.appender.rolling.layout=org.apache.log4j.PatternLayout
log4j.appender.rolling.layout.ConversionPattern=%d{HH:mm:ss.SSS} [%-5p] %-20c{1} [%t]%x [%X{traceId}]-%m%n
#error log
log4j.appender.errlog=org.apache.log4j.DailyRollingFileAppender
log4j.appender.errlog.Threshold=ERROR
log4j.appender.errlog.File=${catalina.base}/logs/error.log
log4j.appender.errlog.DatePattern='.'yyyy-MM-dd-HH
log4j.appender.errlog.layout=org.apache.log4j.PatternLayout
log4j.appender.errlog.layout.ConversionPattern=%d{MM-dd HH:mm:ss.SSS} [%-5p] %-20c{1} [%.11t] [%X{traceId}]%x-%m%n
3、生产者
import org.apache.kafka.clients.producer.KafkaProducer;
import org.apache.kafka.clients.producer.ProducerRecord;
import java.util.Properties;
public class ProducerDemo {
// Topic
private static final String topic = "kafkaTopic";
public static void main(String[] args) throws Exception {
Properties props = new Properties();
props.put("bootstrap.servers", "192.168.1.120:9092,192.168.1.135:9093,192.168.1.227:9094");
props.put("acks", "0");
props.put("group.id", "1111");
props.put("retries", "0");
props.put("key.serializer", "org.apache.kafka.common.serialization.StringSerializer");
props.put("value.serializer", "org.apache.kafka.common.serialization.StringSerializer");
//生产者实例
KafkaProducer producer = new KafkaProducer(props);
int i = 1;
// 发送业务消息
// 读取文件 读取内存数据库 读socket端口
while (true) {
Thread.sleep(1000);
producer.send(new ProducerRecord(topic, "key:" + i, "value:" + i));
System.out.println("key:" + i + " " + "value:" + i);
i++;
}
}
}
4、消费者
import org.apache.kafka.clients.consumer.ConsumerRecord;
import org.apache.kafka.clients.consumer.ConsumerRecords;
import org.apache.kafka.clients.consumer.KafkaConsumer;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import java.util.Arrays;
import java.util.Properties;
public class ConsumerDemo {
private static final Logger logger = LoggerFactory.getLogger(ConsumerDemo.class);
private static final String topic = "kafkaTopic";
public static void main(String[] args) {
Properties props = new Properties();
props.put("bootstrap.servers", "192.168.1.120:9092,192.168.1.135:9093,192.168.1.227:9094");
props.put("group.id", "1111");
props.put("enable.auto.commit", "true");
props.put("auto.commit.interval.ms", "1000");
props.put("auto.offset.reset", "earliest");
props.put("key.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
props.put("value.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
KafkaConsumer consumer = new KafkaConsumer(props);
consumer.subscribe(Arrays.asList(topic));
while (true) {
ConsumerRecords records = consumer.poll(1000);
for (ConsumerRecord record : records) {
System.out.printf("offset = %d, key = %s, value = %s%n", record.offset(), record.key(), record.value());
}
}
}
}
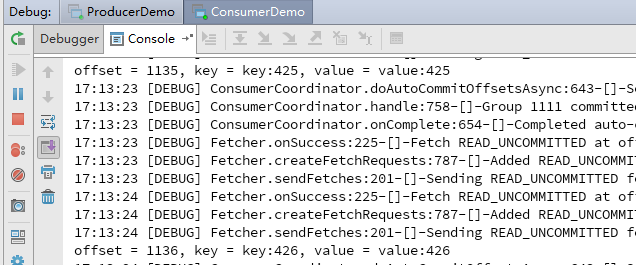
5、测试结果
生产者:

消费者:
代码下载地址:http://download.csdn.net/download/u010870518/9938605
也可以到官网下载Kafka的源代码包,包里边有example代码可以参考
https://www.apache.org/dyn/closer.cgi?path=/kafka/0.11.0.0/kafka-0.11.0.0-src.tgz