【CVPR 2020】用于目标检测的统一样本加权网络

喜欢就关注我们吧!
随着CVPR 2020论文结果的公布,我们也将紧跟CVPR的步伐为大家带来一系列论文的解读。今天为大家解读的是一篇来自中科大和京东研究院关于目标检测的论文《Learning a Unified Sample Weighting Network for Object Detection》
喜欢的话,记得帮我们转发一下哦~


摘要
区域采样或加权对于现代基于区域的目标检测器的成功至关重要。之前的工作在优化目标函数时一般更加关注“难”样本,但是我们认为权重应该根据数据集和任务而定。样本对于目标函数优化的重要性取决于样本对对象分类和边界框回归任务的不确定性。为此,我们设计了一个通用损失函数,以各种采样策略覆盖大多数基于区域的目标检测器,然后在此基础上,我们提出了一个统一的样本加权网络来预测样本的任务权重。我们的框架简单而有效,利用样本在分类损失,回归损失,IoU和置信度上的不确定性分布来预测样本权重。我们方法的优点是:
(1)同时学习分类和回归的样本权重,这与之前大部分的工作不同
(2)该方法是一个数据驱动的过程,避免了手动参数的调整
(3)可以轻松与大多数物体检测器结合,在不影响其推理时间的情况下实现了显着的性能提升。
背景简介
现代基于区域的目标检测框架是一种多任务的框架,其中包含目标的分类和定位,涉及到区域采样(滑动窗口或者region proposal),区域的分类,回归和非极大值抑制(NMS)。正是由于区域采样,我们可以将目标检测的任务转化为一个分类问题,对区域进行分类或者回归。根据区域搜索方式的不同,可以将检测器分为一阶段(SSD,Yolo,RetinaNet)的和两阶段(Faster RCNN,Mask RCNN)。通常两阶段的检测器的精度较高,例如Faster RCNN,在region proposal阶段会迅速缩小区域,因为大部分的区域来自于背景。与此相反的是Yolo和SSD这样的单阶段检测器,虽然速度较快但是精度较低,这是由于前景和背景的类别不平衡问题造成的。两阶段检测器处理的方法是使用region proposal机制和各种采样采样策略,例如固定前景和背景之比以及难样本挖掘,尽管难样本挖掘也可以用于单阶段目标检测,但是由于大量简单负样本的存在,使得难样本挖掘在单阶段目标检测中的效果并不好。
所谓“难”样本就是指分类损失函数值较大的样本,通常而言,困难的样本并不一定重要,即权重并不一定很大。下图为训练过程三种情况

图(a)为分类损失较大但是权重较小的示例;图(b)为损失较小但是权重较大的示例;图(c)为样本分类和IoU所得到的结论并不一致的情况。此外,由于遮挡,不正确的标注和模糊的边界,在边界框注解中存在歧义。换句话说,训练数据具有不确定性。
采样加权是一个动态复杂的过程,在多任务问题的损失函数中,每个样本之间存在着很大的不确定性。我们认为采样加权应该是依赖于数据以及依赖于任务的,一方面,样本的权重应该是由样本的内在属性,即与Ground Truth相比的属性以及对于损失函数的响应决定,另一方面,目标检测是一个多任务的问题,样本的权重应该在不同任务之间取得一个平衡。如果检测器选择了高精度的分类效果而忽视了回归的任务,定位能力较差的结果也将降低最终的精度,尤其是对于IoU要求较高的场景下,反之亦然。
遵循上述思想,本文提出了一种用于目标检测的统一动态采样加权网络,这是一种简单有效的,学习样本权重的方法,还可以在分类和回归的任务之间取得平衡。具体而言,除了基础的检测网络之外,我们设计了一个样本加权网络(Sample Weighting Network,SWN)来预测每个样本的分类和回归权重,类似于一个函数,输入为分类损失,回归损失,IoU和置信值,输出为样本的权重。
目标检测的损失函数
对于目标检测而言,损失函数的形式一般为:
cls代表分类,reg代表回归,A代表采样得到的anchor。加入权重以后,上式变为
其中s是分别对应的权重。为了简化符号,在这里s也可以代表各种的采样方法。
目标检测样本采样加权方法总结
1
RPN, 随机采样和难样本挖掘
RPN(region proposal network)将每个样本分类为与类别无关的前景类别和背景类别;
随机采样(random sampling)是均匀的从正锚框中选择n个样本,从负锚框中选择n个样本。被采样到的样本权值为1,未被采样到的样本权值为0。
难样本挖掘(online hard sample mining)的做法是根据损失值从高到低对正样本和负样本进行排名,选出其中最高的n个样本,被采样到的分类权值设定为1,未被选择的权值设定为0。
2
Focal Loss,KL Loss
Focal Loss给容易区分的样本赋予很低的权值,给不容易区分的样本赋予较高的权值;
KL Loss是估计样本的不确定度来确定回归损失的权重。
3
举例
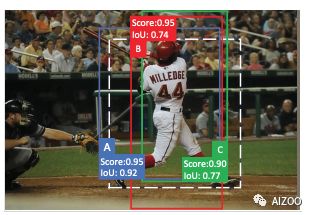
图二是Faster RCNN第一个epoch的结果,ABC分别是三个正样本的示例。NMS通过删除分数相对较低的框来过滤混乱的边界框。由于测试结果中与A和B相比得分较低,因此C不会被采用。相反,当应用OHEM时,由于其损失较高(分数较低),因此将选择C进行训练。过多地关注“C”这样的“困难”示例可能并不总是有帮助的,因为在推理过程中,我们也追求good ranking。Focal-Loss同样面临类似的问题,因为它为box A和B分配了相同的分类权重。但是,考虑到A的基本IoU高于B的IoU,提高A的得分可能会更加有益。这是因为mAP是在各种阈值下计算的,这有助于更精确地定位检测结果。另一方面,KL-Loss根据边界框不确定性为回归损失分配不同的样本权重,而忽略重新加权分类损失。
鉴于上述传统方法的诸多缺陷考虑到现有方法的这些缺点,本文建议从数据驱动的角度共同学习分类和回归的样本权重。简而言之,先前的方法集中于重新加权分类损失(例如OHEM和Focal-Loss)或回归损失(例如KL-Loss)。但是本文的方法联合加权分类和回归损失。此外,与在OHEM和Focal-Loss方法中挖掘“困难”示例(它们具有较高的分类损失)不同,本文的方法侧重于重要样本,这些样本也可能是“简单”样本。
联合学习样本权重
该部分数学知识较多,但是本文的精髓所在,如果读者看不懂,可以暂时跳过去。
本文受启发于,以概率形式重新构造了样本加权问题,并通过反映不确定性来衡量样本重要性。本文的方法不仅解决了样本采样的问题,而且解决了回归和分类平衡的问题。对第i个样本的回归模型使用高斯似然函数,可得
其中,a*是第i个样本的bounding box的坐标,为了优化回归网络,最大化对数似然概率
回归的损失最终被定义为:
随着偏差σ的增大,损失的权重增大。对于分类的损失为,使用softmax的似然函数:
其中t控制分布的平化程度,p的分布实际上是一个玻尔兹曼分布,为了与回归损失相对应,分类损失最后可以被写为:
因此最终的损失函数为:
如果直接预测偏差,可能得到0的结果导致分母为0,取而代之,对偏差取对数,
)
最终的损失函数为:
理论分析
长期以来,目标检测存在两派的建议,一派认为应该更加关注较难的样本,另一派认为简单的样本更有意义。但是这个概念很难一概而论,因此样本入手更灵活,也更有意义。假设常数为1,对σ求回归损失的偏导数可最优的参数为:
把这个值带回到损失函数,可得最优值为:
这个损失函数对于异常点和噪音的表现更加稳定,同时在回归损失太大时,可以抑制困难样本的权重。
统一采样加权网络设计
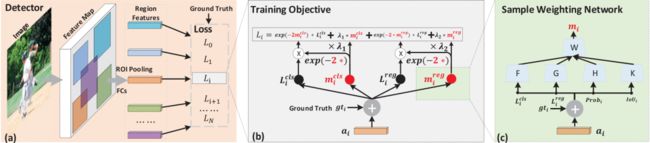
上图为SWN的结构图,SWN是检测器的一个子网络。SWN非常简单,就是一个如图c所示的两个阶段的多层感知机。SWN的输入为分类的损失,回归的损失,置信值和IoU,对于负样本而言置信值和IoU为0。之后F,G,H,K四个函数将输入转化为更有意义的表征。之后再样本层面做拼接的操作得到特征d:
在后续的网络中采样的权重m,由W网络学习得来。由于SWN不需要任何的先验假设,因此对于Fast RCNN,Faster RCNN和Mask RCNN都是适用的。
实验结果
实验使用的网络是Faster R-CNN,Mask RCNN和RetinaNet,使用的数据集是COCO和Pascal VOC。
1
实验结果示例

上图为检测结果的示例,第一行为原始RetinaNet的结果,第二行为加了SWN的RetinaNet的结果。原始的RetinaNet丢失了很多容易检测到的样本,而加了SWN的RetinaNet克服了这个缺陷。
2
COCO数据集测试结果

3
Pascal VOC数据集

4
IoU为导向的实验结果

5
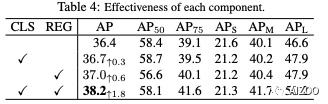
消融实验结果
结论
实验证明,基于区域的目标检测的样本加权问题既依赖于数据又依赖于任务。我们推导了一个通用的损失函数,该函数可以从训练数据中自动学习基于样本的任务权重。它是通过简单而有效的神经网络实现的,该网络可以轻松插入大多数基于区域的检测器,而无需增加推理成本。在公开数据集上的结果大致可以提高1.8%。一些定性结果清楚地表明,我们的方法可以检测到其他检测器遗漏的一些“容易”物体。在以后的工作中,我们将对这种现象进行完整的解释。另外,我们可以继续改进我们的方法,使其可以在不同的优化阶段更智能地处理“困难”和“简单”样本。
论文源码
作者已经将代码公布在Github上,使用的框架是mmdetection,项目的链接为https://github.com/caiqi/sample-weighting-network,点击阅读原文可以查看原始论文。
往期推荐

数据科学正在逐步失去吸引力,深度学习呢?
简单好用的深度学习论文绘图专用工具包--Science Plot

本是同根生,NCNN作者如何评价自家公司的TNN

AIZOO,打造中国最大的深度学习和人工智能社区,欢迎关注我们,也欢迎添加下方小助手的微信,邀请您加入我们的千人深度学习爱好者社区。

欢迎扫描下方的二维码添加小助手微信,邀请您加入我们的微信交流群。
群里有多位清北复交的大佬和众多深度学习er在一起愉快的交流技术,欢迎你的加入哦。

添加小助手微信,邀您进AIZOO技术交流群
听说点在看的,论文都会发到手软~