CMU开源:多目标人体关键点实时检测
OpenPose是一个利用OpenCV和Caffe并以C++写成的开源库,用来实现多线程的多人关键点实时检测,作者包括Gines Hidalgo,Zhe Cao,Tomas Simon,Shih-En Wei,Hanbyul Joo以及Yaser Sheikh。
即将加入(但是已经实现!)身体+手势+人脸估计展示:

尽管该库使用了Caffe,但是代码还是很容易向其他框架(如Tensorflow 或者Torch 等)中移植。如果你实现了任何这方面的代码,请发出合并请求我们会很乐意在该库中添加你的实现。
OpenPose对于自由的非商业用途的使用是免费的,同时也可以在这种情况下被重新发布。请查看证书了解详情。如果有商业用途请联系作者。
OpenPose库的主要功能性:
-
多人15或18关键点身体位姿估计和渲染:
-
多人2*21关键点手势估计和渲染(未来1-2月内开源!)

-
多人70关键点人脸估计和渲染(未来2-3月内开源!)
-
灵活并且易于配置的多线程模块。
-
图像,视频以及网络相机读取器。
-
能够以多种格式(JSON,XML,PNG,JPG,...)保存和加载结果。
-
用于结果可视化的小型显示窗口以及GUI。
-
所有这些功能性都封装进了一个易于使用的OpenPose Wrapper类中。
姿态估计的成果基于ECCV 2016样例"RealtimeMultiperson Pose Estimation",Zhe Cao,Tomas Simon,Shih-En Wei,Yaser Sheikh中的C++代码。完整的项目库包含Matlab和Python版本,以及训练代码。
ECCV 2016姿态估计视频
如何安装:
安装步骤详见Github内的:doc/installation.md文件。
如何快速上手:
大部分用户用例不需要对该库有太深入的了解,这样的用户可能只能够使用Demo或者简单的OpenPoes封装。因此你大可不必太在意OpenPose库中的细节。
样例:
如果在你的用例中你只是想处理一个图像或视频又或者网络相机文件夹并显示或者存储位姿结果。
那么你不必在意OpenPose库的实现细节同时只要阅读doc/demo_overview.md文件中一页的内容就可以了。
OpenPose封装:
在你的用例中如果你打算读取某一特定的图像格式并且/或者添加某个特定的后处理函数并且/或者实现你自己的显示或存储功能。
(几乎可以)不用理会该库本身的实现,只要看一下examples/tutorial_wrapper/.中关于Wrapper的教程即可。
注意:你并不需要修改OpenPose源代码或者例程,这样你将来就能随时无需修改你的代码直接升级OpenPose库。你可以在examples/user_code/中创建你自定义的代码并在OpenPose文件夹下使用make all命令编译它。
OpenPose库:
在你的用例中如果你想要改变内部函数并且/或者扩展它的功能性。首先,请先看一眼样例以及OpenPose封装。其次,阅读以下两个小节:OpenPose概览和功能性扩展。
1.OpenPose概览:在doc/library_overview.md中学习关于我们库源码的基础。
2.功能性扩展:在doc/library_extend_functionality.md中学习如何扩展我们的库。
3.添加一个额外的模块:在doc/library_add_new_module.md中学习如何添加一个额外的模块。
Doxygen文档自动生成
你可以通过运行如下命令来生成文档。文档将会在此doc/doxygen/html/index.html生成。你只需要双击就可以打开它(你的默认浏览器会自动显示它)。
cd doc/doxygen doc_autogeneration.doxygen
如何输出:
1.输出格式
这里有两种可替换的方法用来存储身体各部位的位置信息(x,y,score)。标志write_pose使用opencv中cv::FileStorage的默认格式存储(JSON,XML和YML)。然而,JSON格式只有OpenCV3.0以后的版本才支持。因此,标志位write_pose_json专门用来将人体位姿数据以自定义的JSON格式存储。这样一来,每一个JSON文件都有一个people对象数组,其中的每个对象都具有一个body_parts数组,该数组中包含了身体各部位的位置信息和检测置信度,其格式为x1,y1,c1,x2,y2,c2,...坐标x和y可以被归一化至区间[0,1],[-1,1],[0,源尺寸],[0,输出尺寸],等等,这取决于标志位scale_mode。另外,c值是位于区间[0,1]的置信度。

至于身体部位关键点的顺序,无论是COCO(18个身体部位)还是MPI(15个身体部位),都是由头文件include/openpose/pose/poseParameters.hpp中的POSE_BODY_PART_MAPPING来描述的。拿COCO格式举例:

对于热点图的存储格式,并不是独立存储67张热点图(18个身体部位+背景+2*19个PAF文件),而是将这些图垂直拼接起来形成一个巨大的(宽*热点图数量)*(高)矩阵。也就是说该库将热点图按列拼接起来。比如,向量[0,单个热点图宽]包含了第一张热点图,向量[单个热点图宽度+1,2*单个热点图宽]包含了第二章热点图,等等。要注意,有些显示工具在给定的尺寸下不能显示结果图像。然而,Chrome和Firefox能够恰当地打开他们。
存储的顺序是身体部位+背景+PAF文件。其中的任何一类信息都可以用程序的标志位屏蔽掉。如果背景被屏蔽了,那么最终的图像将会是身体部位和PAF信息的组合。身体部位信息和背景遵从POSE_COCO_BODY_PARTS或POSE_MPI_BODY_PARTS中的顺序,同时PAF信息遵循头文件poseParameters.hpp中POSE_BODY_PART_PAIRS指定的顺序。比如,对于COCO格式:
POSE_COCO_PAIRS {1,2, 1,5, 2,3, 3,4, 5,6, 6,7, 1,8, 8,9, 9,10, 1,11, 11,12, 12,13, 1,0, 0,14, 14,16, 0,15, 15,17, 2,16, 5,17};
其中每一个索引都是POSE_COCO_BODY_PARTS中相应身体部位的键值,比如0对应”Neck”,1对应”RShould”,诸如此类。
2.读取存储的结果
我们使用标准格式(JSON,XML,PNG,JPG,...)来存储结果,这样一来之后就有很多框架可以读取它们,但是你也可以直接在include/openpose/filestream.hpp上使用我们的函数。特别是使用loadData(针对JSON,XML和YML文件)和loadImage(针对例如PNG或者JPG这样的图像格式)将数据加载到cv::Mat格式中。
3.给我们发送反馈
对于研究目的,我们的库是开源的,同时我们也想要持续改善它!所以请让我们知道如果...
1.你发现了任何bug(在功能性或者速度方面)
2.你向某些类或者新的Worker子类中添加了某种功能性,我们可能会将其糅合进我们的库中
3.你知道如何提高速度或者让这个库的任何地方变得简洁
4.你有关于可能的功能性的需求
5.诸如此类
请在GibHub上评论或者发出合并请求!我们会尽快答复你!
4.自定义Caffe
我们仅仅修改了一些Caffe的汇编标志和一点点细节。你可以使用你自己的Caffe版本,下面是我们添加和修改的文件:
1.添加的文件:install_caffe.sh;以及Makefile.config.Ubuntu14.example,Makefile.config.Ubuntu16.example,Makefile.config.Ubuntu14_cuda_7.example和Makefile.config.Ubuntu16_cuda_7.example(从Makefile.config.example中抽取)。基本上你必须使能cuDNN。
2.修改的文件:在Makefile中搜索“#OpenPose:”来查找修改过的代码。总的来说我们添加了C++11标志来避免一些旧版机器上的问题。
3.可选项-删除Caffe文件:Makefile.config.example。
4.最后,在你的Caffe版本上运行make all && make distribute命令并在./Makefile.config.UbuntuX.example(其中X是14或16,取决于你的Ubuntu版本)中修改Caffe目录空间的变量,设置CAFFE_DIR参数为Caffe文件夹中include和lib所在的路径。
引用
如果这对你的研究有所帮助请在你的出版物中引用本文。
姿态估计:

论文地址:https://arxiv.org/abs/1611.08050
GitHub地址:https://github.com/CMU-Perceptual-Computing-Lab/openpose#output
Realtime Multi-Person 2D Pose Estimation using Part Affinity Fields 是CVPR2017的一篇论文,作者称是世界上第一个基于深度学习的实时多人二维姿态估计。
优酷演示地址:链接
前几天作者公布了windows下的代码,下面来说说如何配置:
英文配置地址可以参考作者的github:https://github.com/CMU-Perceptual-Computing-Lab/openpose/blob/master/doc/installation.md#windows
首先你得装好CUDA8,cudnn5.1,vs2015. 其他版本都不行,只有vs2015可以装
作者说要下载Python 2.4.13 64 bits,其实我的anaconda2也可以(2.7的那个版本)
cmake,ninja(我下载了,但是貌似没用到)
下载windows版的 openpose https://github.com/CMU-Perceptual-Computing-Lab/openpose/tree/windows
并解压,我放在D盘。下载model ,作者给了2个,
http://posefs1.perception.cs.cmu.edu/Users/tsimon/Projects/coco/data/models/coco/pose_iter_440000.caffemodel (精度高,速度较慢)下载后放到 D:\openpose-windows\models\pose\coco下
http://posefs1.perception.cs.cmu.edu/Users/tsimon/Projects/coco/data/models/mpi/pose_iter_160000.caffemodel(速度快,但是精度低)
下载后放到D:\openpose-windows\models\pose\mpi\下
打开D:\openpose-windows\3rdparty\caffe\caffe-windows\scripts 下的build_win.cmd,开始编译。
提示出错hash 什么不匹配的,原因是网的问题,https://github-production-release-asset-2e65be.s3.amazonaws.com/39632178/8053cdd0-0068-11e7-8b60-c46f580c47e0?X-Amz-Algorithm=AWS4-HMAC-SHA256&X-Amz-Credential=AKIAIWNJYAX4CSVEH53A%2F20170531%2Fus-east-1%2Fs3%2Faws4_request&X-Amz-Date=20170531T072412Z&X-Amz-Expires=300&X-Amz-Signature=1860d1ab5ee6598f6a93e6230d1b74a09200e95e22d72021043f5176b9d73de3&X-Amz-SignedHeaders=host&actor_id=28419338&response-content-disposition=attachment%3B%20filename%3Dlibraries_v140_x64_py27_1.1.0.tar.bz2&response-content-type=application%2Foctet-stream 下载后复制到D:\openpose-windows\3rdparty\caffe\dependencies\download下。再编译,等待半个小时,就会编译完毕。(若出现no c compiler could be found 请参考我另一篇博文)
接着 打开 D:\openpose-windows\windows_project\OpenPose.sln 右键点击OpenPoseDemo 生成,此时会报错。提示 找不到D:\openpose-windows\3rdparty\lib\Release caffe.lib 。其实它在 D:\openpose-windows\3rdparty\caffe\lib\Release下,路径的问题。
把release下的的两个文件 放到D:\openpose-windows\3rdparty\lib\Release下 就OK 了。 再编译 又提示错误,说找不到pythoh27(其实也可以在build_win.cmd下 把Python的路径改成你自己的python路径,这样这里就不会报错。)右键OpenPoseDemo,属性,连接器,常规,附加库目录,把你的python路径加进去,我为了防止出错,把2个路径都加了。

再生成,就成功了。顺便再生成一下openpose(貌似没什么东西生成)
此时你会在D:\openpose-windows\windows_project\x64\Release下找到OpenPoseDemo.exe。但是你双击它会提示你缺少各种东西。
作者说把{openpose_folder}\3rdparty\caffe\caffe-windows\build\install\bin\ 下的所有DLL文件复制到{openpose_folder}\windows_project\x64\Release.下
但是我没有找到这个路径。我把D:\openpose-windows\3rdparty\caffe\caffe-windows\scripts\build\tools\Release下的所有DLL文件复制过去。
再把{}openpose_folder}\3rdparty\caffe\dependencies\libraries_v140_x64_py27_1.1.0\libraries\x64\vc14\bin\下的
opencv_ffmpeg310_64.dll, opencv_video310.dll 和opencv_videoio310.复制到{openpose_folder}\windows_project\x64\Release下。
此时打开OpenPoseDemo.exe,发现还是缺少一些东西,我在D:\openpose-windows 下搜索缺少的文件,并复制到{openpose_folder}\windows_project\x64\Release下。
此时,发现oppenpose可以打开了,但是提示找不到model,其实是路径的问题,打开OpenPose.sln ,双击OpenPoseDemo下的openpose.cpp.
在第66行,手动设定models的绝对路径,比如我的是这个: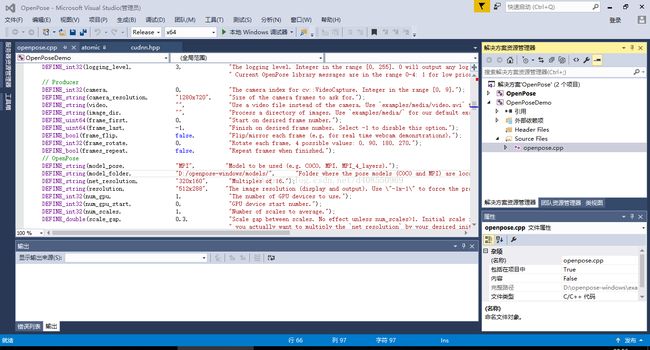
保存,并再次编译。发现oppenpose终于可以打开了!
有些同学可能会提示报错 out of memory (比如说我),其实就是显存不够,爆显存了(1G GT650M伤不起啊)
打开OpenPose.sln ,双击OpenPoseDemo下的openpose.cpp.
在第67行、68行 修改网络的大小,我设定成如上的大小,1G显存也可以跑了。
大功告成!
如果想在视频下跑,可以在cmd下使用如下命令:windows_project\x64\Release\OpenPoseDemo.exe --video examples/media/video.avi
如果是图片的话bin\OpenPoseDemo.exe --image_dir examples/media/