Spark连接MongoDB使用教程
一、前期准备

源自MongoDB官方文档,https://docs.mongodb.com/spark-connector/v1.1/getting-started/
二、编程实现
1. maven工程添加依赖
maven中央仓库搜索:http://mvnrepository.com/artifact/org.mongodb.spark/mongo-spark-connector

由于笔者的spark是1.6版本,scala是2.10版本,所以选择如下图的:

org.mongodb.spark
mongo-spark-connector_2.10
1.1.0
2. 参考MongoDB文档
1)spark-shell中启动命令
./bin/spark-shell --conf "spark.mongodb.input.uri=mongodb://127.0.0.1/test.myCollection?readPreference=primaryPreferred" \
--conf "spark.mongodb.output.uri=mongodb://127.0.0.1/test.myCollection" \
--packages org.mongodb.spark:mongo-spark-connector_2.10:1.1.0那么在用scala编程时,可以这样转换:
![]()
2)Read and Analyze Data from MongoDB
方式一:简单

方式二:设置参数

import com.mongodb.spark.config._
val readConfig = ReadConfig(Map("collection" -> "spark", "readPreference.name" -> "secondaryPreferred"), Some(ReadConfig(sc)))
val customRdd = MongoSpark.load(sc, readConfig)
println(customRdd.count)
println(customRdd.first.toJson)3)Write to MongoDB
方式一:简单

方式二:设置参数
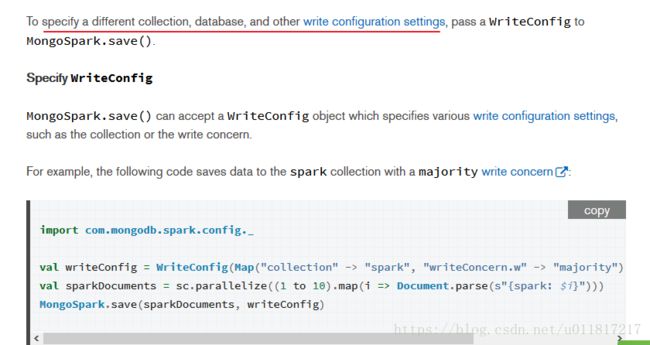
import com.mongodb.spark.config._
val writeConfig = WriteConfig(Map("collection" -> "spark", "writeConcern.w" -> "majority"), Some(WriteConfig(sc)))
val sparkDocuments = sc.parallelize((1 to 10).map(i => Document.parse(s"{spark: $i}")))
MongoSpark.save(sparkDocuments, writeConfig)三、笔者项目实战源码
从MongoDB数据库中获取到的RDD转换成DataFrame并保存为parquet文件,方便后续分析工作。
val sparkConf = new SparkConf().setAppName("ProcessEmployee")
sparkConf.setMaster("local[2]").set("spark.mongodb.input.uri","mongodb://127.0.0.1:27017/hp.employee?readPreference=primaryPreferred")
val sc = new SparkContext(sparkConf)
val hiveContext = new HiveContext(sc)
import com.mongodb.spark.config._
val readConfig = ReadConfig(Map("collection" -> "employee", "readPreference.name" -> "secondaryPreferred"), Some(ReadConfig(sc)))
val customRdd = MongoSpark.load(sc, readConfig)
println(customRdd.count)
println(customRdd.first.toJson)
import hiveContext.implicits._
val employee = customRdd.map(e => Employee(e.get("name").toString.trim,e.get("emp_id").toString.trim,e.get("department").toString.trim,
e.get("company").toString.trim,e.get("cc").toString.trim,e.get("sbu").toString.trim,e.get("landline_num").toString.trim,e.get("phone_num").toString.trim,
e.get("nt_num").toString.trim,e.get("email").toString.trim,e.get("work_city").toString.trim,e.get("sup_emp_id").toString.trim)).toDF()
employee.printSchema()
employee.registerTempTable("employee")
val employeeNew = hiveContext.sql("select distinct emp_id,name,department,company,cc,sbu,landline_num,phone_num,nt_num,email,work_city,sup_emp_id from employee ")
employeeNew.show()
employeeNew.write.format("parquet").save("file:///D:/XXX.parquet")
sc.stop()
}
case class Employee (name:String,emp_id:String,department:String,company:String,cc:String,sbu:String,landline_num:String,phone_num:String,nt_num:String,email:String,work_city:String,sup_emp_id:String)