Kears:如果你想要在大数据集上训练的话,必须要了解的一件事情
点击上方“AI公园”,关注公众号,选择加“星标“或“置顶”
导读作者:Soumendra P
编译:ronghuaiyang
我们在学习的时候,一般会使用minist,cifar10这样的数据集,这种小数据集可以非常方便的放到内存或显存中,那么,当我们在真实的大规模数据集上进行训练的时候,该怎么办呢?
如果你打算将keras的实验从toy数据集迁移到大型数据集,理解这一点非常重要:
如果使用来自ImageDataGenerator()的flow_from_directory()创建的数据生成器,predict_generator()和predict()的输出可能不匹配,即使训练数据、模型架构、超参数和随机种子是相同的。
如果你不知道这一点,predict_generator()可能会给你带来很垃圾的结果。
现在更难发现了,因为keras 1.0中处理这个问题的一些函数在keras 2.0中已经消失了。
这也使得在大型数据集上训练多标签模型变得更加困难。
在大数据集上训练

由于fit()需要将整个数据集作为numpy数组放入内存中,对于较大的数据集,我们必须使用fit_generator()。
在Keras中,使用fit()和predict()对于可以加载到内存中的较小的数据集很好。但是在实践中,对于大多数实际用例,几乎所有数据集都很大,不能一次加载到内存中。
解决方案是将fit_generator()和predict_generator()与定制的数据生成器函数一起使用,这些函数可以在训练或预测期间将图像加载到内存中。我们可以自己编写它们,但是Keras中的ImageDataGenerator()提供了这样一个生成器,我们可以使用flow()或flow_from_directory()创建它。由于大多数深度学习模型可能已经使用了ImageDataGenerator()(因为图像增强是必不可少的),这是一个很好的解决方案。
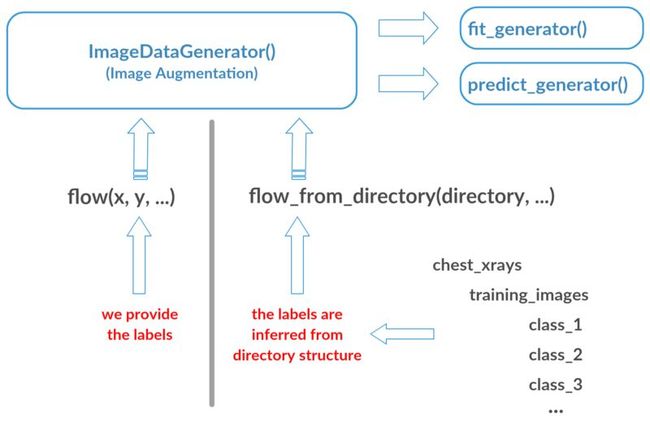
flow_from_directory()从目录结构推断标签
然而,这些函数如何学习与图像相关的标签是有差异的。
对于fit()或fit_generator(),通过使用ImageDataGenerator()中的flow(),我们自己提供标签。
flow_from_directory()自动从包含图像的文件夹的目录结构推断标签。训练文件夹(或验证文件夹)中的每个子文件夹将被视为目标类。
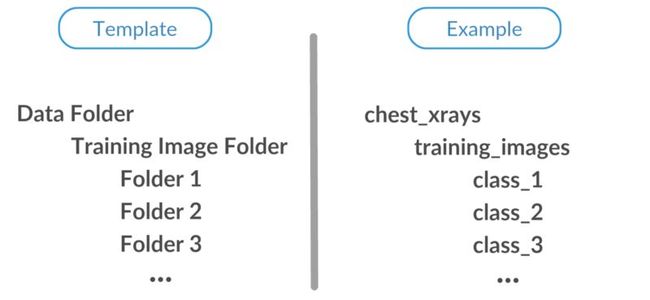
flow_from_directory()自动从文件夹的目录结构推断标签
问题
当使用flow_from_directory()时,从类标签(文件夹名称)到内部独热编码的映射可能并不直观。
假设我们正在处理CXR8数据集,它现在有14个不同的类。假设我们将它们保存在名为Class_1, Class_2, Class_3,…,Class_12, Class_13, Class_14的文件夹中。
如果我们自己传递标签,它将主要反映我们列出这些标签的顺序。如果flow_from_directory()正在推断它们,它将在编码之前对目录名进行排序。在这种情况下,Class_10将出现在Class_1之后,而不是我们可能期望的Class_2。映射是这样的:
这很可能不同于直观的排序,即Class_2在Class_1之后(而不是Class_10)。在这种情况下,predict()和predict_generate()的输出将看起来不同。

更好的做法是在没有数字索引的情况下对文件夹进行标记,或者将它们命名为class_01、class_02等,而不是class_1和class_2。
例子
本文收到keras issue #3477的提示。作者用keras做了两个实验,一个是图像增强(使用ImageDataGenerator()),另一个没有。作者想知道为什么predict()和predict_generator()的返回值不同?这是我们刚刚讨论的不同标签排序顺序的一个例子。
解决方案(代码)
Keras 1.0有两个用于sequence api的函数:' model.predict_classes() '和' model.predict_proba() '来处理这个问题,但是它们在Keras 2.0中已经消失了,我认为这是一个很好的决定。跨sequence 和Functional api的工作流应该是相似的,并且是可预测的。
无论如何,修复是相当容易的。来自flow_from_directory()的映射存储在数据生成器对象中名为' class_indexes '的属性中。
这个predictions现在很可能与fit()或fit_generator()使用flow()所做的预测相匹配。
我们也可以手动创建映射。下面的代码是来自这篇SO post。
上述代码中的变量name_id_map包含与flow_from_directory()的class_indexes函数获得的字典相同的字典。
 —
END—
—
END—
英文原文:https://medium.com/difference-engine-ai/keras-a-thing-you-should-know-about-keras-if-you-plan-to-train-a-deep-learning-model-on-a-large-fdd63ce66bd2

●人人都能看得懂的深度学习介绍!全篇没有一个数学符号!
●深度学习物体检测论文阅读路线图以及官方实现
●新手必看的Top10个机器学习算法(这些都学会了你就是老手了)
更多历史文章请关注公众号,点击“历史文章”获取

请长按或扫描二维码关注本公众号
喜欢的话,请给我个好看吧!