ApachePredictionIO使用
PredictionIO初步使用
文章目录
- 0 简介
- 0.1 什么是ApachePredictionIO®?
- 0.2 PredictionIO 组件构成
- 0.3 部署步骤
- 1 docker安装ApachePredictionIO
- 1.1 官网方式
- 1.1.1 下载docker源文件
- 1.1.2 Build Docker Image
- 1.2 从DockerHub拉取docker镜像
- 1.2.1 拉取镜像文件
- 1.2.2 启动事件引擎
- 2 使用Quick Start例子做推荐系统
- 2.1 下载模板引擎
- 2.2 生成应用程序ID和访问密钥
- 2.3 收集数据
- 2.3.1 通过url收集数据
- 2.3.2 python脚本批量导入
- 2.3.3 自定义其他事件
- 2.4 部署引擎即服务
- 2.4.1 build构建引擎
- 2.4.2 train训练引擎
- 2.4.3 deploy部署引擎
- 2.5 使用引擎推荐
- 2.6 定期更新推荐模型
0 简介
0.1 什么是ApachePredictionIO®?
ApachePredictionIO®是一个开源的机器学习服务器,它建立在最新的开源堆栈之上(基于:Apache Spark,MLlib,HBase,Akka HTTP和Elasticsearch),供开发人员和数据科学家使用,以为任何机器学习任务创建预测引擎。它可以让您:
- 使用可自定义的模板在生产环境中快速构建和部署引擎作为Web服务,RestfulAPI支持;
- 部署为Web服务后,可以实时响应动态查询;
- 系统地评估和调整多种引擎变体;
- 批量或实时统一来自多个平台的数据,以进行全面的预测分析;
- 通过系统的流程和预先建立的评估措施来加快机器学习建模;
- 支持机器学习和数据处理库,例如Spark MLLib和OpenNLP;
- 实施您自己的机器学习模型并将其无缝整合到您的引擎中;
- RestfulAPI支持
- 简化数据基础架构管理。
0.2 PredictionIO 组件构成

PredictionIO 由三大组件构成:
- PredictionIO platform (PredictionIO平台)-我们的开源机器学习堆栈,用于使用机器学习算法构建,评估和部署引擎。
- Event Server-我们的开源机器学习分析层,部署为Web服务后,它会侦听您的应用程序中的查询并实时响应预测结果。
- Engine(引擎)-引擎负责进行预测。它包含一种或多种机器学习算法。
- Template Gallery (官方模板库)-您可以在此下载用于不同类型的机器学习应用程序的引擎模板
0.3 部署步骤
部署和使用引擎需要6个简单的步骤:
- 安装并运行PredictionIO
- 通过下载引擎模板创建引擎
- 如果要将PredictionIO与新应用程序集成,请生成应用程序ID和访问密钥
- 收集数据
- 将引擎即服务部署
- 使用引擎推荐
1 docker安装ApachePredictionIO
1.1 官网方式
http://predictionio.apache.org/install/install-docker/
1.1.1 下载docker源文件
从v0.13.0开始,ApachePredictionIO®开始为生产环境提供docker支持。Dockerfile和依赖项配置可以在git存储库的docker文件夹中找到。
首先下载项目:
git clone https://github.com/apache/predictionio.git
然后进入docker文件夹下:
cd predictionio/docker
1.1.2 Build Docker Image
为了构建PredictionIO Docker image,在子目录pio中提供了Dockerfile。
使用上面的命令,您将能够使用标签prediction/pio:latest build 一个 image。
docker build -t predictionio/pio pio
1.2 从DockerHub拉取docker镜像
https://github.com/steveny2k/docker-predictionio
https://www.cnblogs.com/Yuanjing-Liu/p/9516536.html
1.2.1 拉取镜像文件
拉取镜像文件:
docker run -it -p 8000:8000 -p 7070:7070 steveny/predictionio:0.12.0 /bin/bash
该命令会自动发现你本地没有该镜像,然后主动去DockerHub拉取。
docker 容器操作:
# 查看所有的容器 及其状态
docker ps -a
# 开始/停止 容器
docker start/stop xxxx
# 查看容器日志
docker logs -f xxxx
#进入docker容器中,比attach命令更好,退出不会关闭
docker exec -it xxxxid bash
# 退出container时,这个container仍然在后台运行
exit # 或者按键“Ctrl + D”
1.2.2 启动事件引擎
拉去镜像之后, docker会直接启动一个 容器。并且进入容器。然后我们 启动所有PredictionIO事件服务器(HBase和Elasticsearch):
pio-start-all
查看有没有启动成功:
pio status
看到以下结果说明成功。

如果报错:Please make sure they are correct. Source Name: ELASTICSEARCH; Type: elasticsearch; xxxxxx 类似的错误 都表示 elasticsearch 没有启动成功,
https://github.com/shimamoto/docker-predictionio/issues/1 参考 解决方案为,增加docker对内存的限制 提高到2g以上
# 如果有问题,就用stop命令关闭,并重启
pio-stop-all
pio-start-all
2 使用Quick Start例子做推荐系统
http://predictionio.apache.org/templates/recommendation/quickstart/
基本Recommendation模板的QuickStart是一个很好的分步指南
2.1 下载模板引擎
这里下载的是一个数据推荐引擎,推荐原理是:
收集用户买了哪些商品,用户给商品打分这两项数据,通过协同过滤算法训练出用户喜好模型,推荐用户还会买哪些商品。
打开一个命令行:
git clone https://github.com/apache/predictionio-template-recommender.git MyRecommendation
cd MyRecommendation
这会创建一个新目录MyRecommendation,您可以在其中找到下载的引擎模板。
在docker中可能没有网,用 docker cp 命令,将文件夹拷贝到 docker中/去。
# 在pio中创建文件夹
cd /home/pio
mkdir engine
# 另外开启命令行,把在外面下载的模版存到 docker中。
docker cp MyRecommendation/ 06d3ba0fb17d:/home/pio/engine
2.2 生成应用程序ID和访问密钥
您将需要在PredictionIO中创建一个新的应用程序以存储您应用程序的所有数据。收集的数据将用于机器学习建模。
假设您要在名为“ MyApp1”的应用程序中使用此引擎。运行以下命令以创建一个新应用“ MyApp1”:
在 PredictionIO docker中:
pio app new MyApp1
您应该在控制台输出中找到以下内容:
...
[INFO] [HBLEvents] The table pio_event:events_1 doesn't exist yet. Creating now...
[INFO] [App$] Initialized Event Store for this app ID: 1.
[INFO] [Pio$] Created a new app:
[INFO] [Pio$] Name: MyApp1
[INFO] [Pio$] ID: 1
[INFO] [Pio$] Access Key: 7_BPHXMzGKKWOQMwwAP-YBvj_3OrMhrE9gbIbxfPQYQ_Ud_UmypIJgR2UlXQ-_IB
请注意,为此应用程序“MyApp1”创建了App ID ,** Access Key *。使用此应用程序的EventServer收集数据时,您将需要访问密钥。
您可以通过运行以下命令列出创建其相应ID和访问密钥的所有应用程序:
pio app list
你应该会看到你创建的应用列表,例如:
pio@bd7804a18b5b:/$ pio app list
[INFO] [Pio$] Name | ID | Access Key | Allowed Event(s)
[INFO] [Pio$] MyApp1 | 1 | 7_BPHXMzGKKWOQMwwAP-YBvj_3OrMhrE9gbIbxfPQYQ_Ud_UmypIJgR2UlXQ-_IB | (all)
[INFO] [Pio$] MyApp2 | 2 | io5lz6Eg4m3Xe4JZTBFE13GMAf1dhFl6ZteuJfrO84XpdOz9wRCrDU44EUaYuXq5 | (all)
[INFO] [Pio$] Finished listing 2 app(s).
2.3 收集数据
2.3.1 通过url收集数据
接下来,让我们收集一些训练数据。默认情况下,推荐引擎模板支持两种类型的事件:rate和buy。用户可以给商品评分或购买商品。该模板需要user-view-item和user-buy-item事件。
也可以轻松地自定义该模板,以考虑更多用户事件,例如like,dislike,嫌弃,超爱等。
您可以通过发出HTTP请求或通过提供的SDK轻松地将这些事件实时实时发送到PredictionIO Event Server。有关如何将您的应用程序与SDK集成的更多详细信息,请参见“ 应用程序集成概述 ”。
让我们尝试使用以下curl命令将事件发送到EventServer (相应的SDK代码显示在其他选项卡中)。
替换localhost:7070是事件服务器的默认URL。
为了方便起见,将访问密钥设置为shell变量,运行:
ACCESS_KEY=
PredictionIO提供了收集数据的接口,在启动了Prediction服务后可以调用它,这里需要用到Access Key。
$ curl -i -X POST http://localhost:7070/events.json?accessKey=$ACCESS_KEY \
-H "Content-Type: application/json" \
-d '{
"event" : "rate",
"entityType" : "user",
"entityId" : "u0",
"targetEntityType" : "item",
"targetEntityId" : "i0",
"properties" : {
"rating" : 5
}
"eventTime" : "2014-11-02T09:39:45.618-08:00"
}'
这个例子表示u0用户给i0产品,评价了5分。 这个请求也可以使用postman等工具进行模拟。
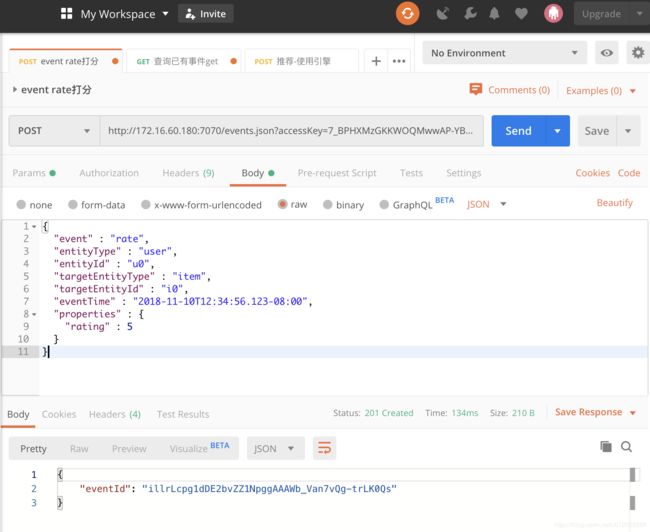
- 查询事件服务器:
现在,让我们查询EventServer,看看是否成功导入了这些事件。
$ curl -i -X GET "http://localhost:7070/events.json?accessKey=$ACCESS_KEY"
它应该以JSON格式返回导入的事件。
2.3.2 python脚本批量导入
该引擎需要更多数据才能训练有用的模型。为了进行快速入门演示,我们不是实时地一次发送更多事件,而是使用脚本批量导入更多事件。
模板中提供了Python导入脚本import_eventserver.py,以使用Python SDK将数据导入事件服务器。请安装Python SDK。
pip install predictionio
这些命令必须在Engine目录中执行,例如:MyRecomendation
cd MyRecommendation
curl https://raw.githubusercontent.com/apache/spark/master/data/mllib/sample_movielens_data.txt --create-dirs -o data/sample_movielens_data.txt
python data/import_eventserver.py --access_key $ACCESS_KEY
插入数据后显示:
Importing data...
1501 events are imported.
2.3.3 自定义其他事件
默认情况下,模板使用“评分”事件(显式评分)训练模型。您可以自定义引擎以读取其他自定义事件并处理隐式选项的事件(例如,查看,购买)
自定义引擎 http://predictionio.apache.org/templates/recommendation/reading-custom-events/
处理隐式 (Recommendation): http://predictionio.apache.org/templates/recommendation/training-with-implicit-preference/
xxxx待补充
2.4 部署引擎即服务
现在,您可以 build构建,train训练 和 deploy部署 引擎。首先,请确保您位于该MyRecommendation目录下。
cd MyRecommendation
在目录下,您应该找到一个engine.json文件;修改此文件,以确保appName参数与您先前创建的应用程序名称匹配(例如 MyApp1)。
...
"datasource": {
"params" : {
"appName": "MyApp1"
}
},
...
2.4.1 build构建引擎
在MyRecommendation目录,运行以下命令:
pio build --verbose
第一次,此命令应花费几分钟;所有后续构建应少于一分钟。–verbose如果您不想查看所有日志消息,也可以不运行它。
成功构建后,您应该看到类似于以下内容的控制台消息
[INFO] [Console$] Your engine is ready for training.
2.4.2 train训练引擎
要训练引擎,请运行以下命令:
pio train
成功训练引擎后,您应该看到类似于以下内容的控制台消息。
[INFO] [CoreWorkflow$] Training completed successfully.
2.4.3 deploy部署引擎
现在,您的引擎已准备好部署。运行:
pio deploy
引擎成功部署并运行后,您将看到类似于以下内容的控制台消息:
[INFO] [HttpListener] Bound to /0.0.0.0:8000
[INFO] [MasterActor] Bind successful. Ready to serve.
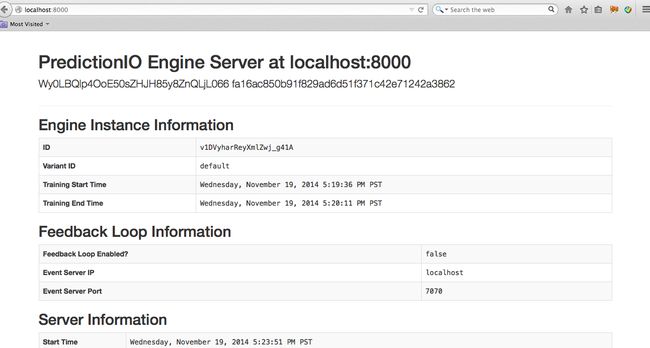
不要终止已部署的引擎进程。
默认情况下,已部署的引擎绑定到 http://localhost:8000。您可以在网络浏览器中访问该页面以检查其状态。
2.5 使用引擎推荐
现在,您可以尝试检索预测结果。要向ID为1的用户推荐4部电影,请将此JSON发送{ “user”: “1”, “num”: 4 }到已部署的引擎,它将返回推荐电影的JSON结果。只需通过发出HTTP请求或通过EngineClientSDK 发送查询即可。
在已部署的引擎运行的情况下,打开另一个终端并运行以下curl命令或使用SDK发送查询:
curl -H "Content-Type: application/json" \
-d '{ "user": "1", "num": 4 }' http://localhost:8000/queries.json
以下是示例JSON响应:
{
"itemScores":[
{"item":"22","score":4.072304374729956},
{"item":"62","score":4.058482414005789},
{"item":"75","score":4.046063009943821},
{"item":"68","score":3.8153661512945325}
]
}

2.6 定期更新推荐模型
要使用新数据定期更新模型,只需设置一个linux的 cron job来定时调用pio train和pio deploy。
在重新训练过程中,引擎将继续提供预测结果。
训练完成后,pio deploy将自动关闭现有引擎服务器,并在同一端口上启动新进程。