深度学习综述-01
加深神经网络
在之前的学习专题中,介绍了构成神经网络的各种层、学习时的有效技巧、对图像特别有效的CNN、参数的最优化方法等,这些都是深度学习中的重要技术。
首先,我们将学过的技术汇总起来,创建一个深度网络,并应用于MNIST数据集的手写数字识别。
构建深度CNN
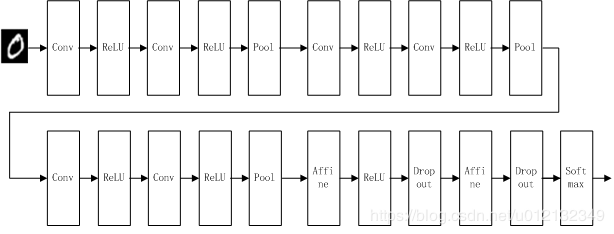 基于手写数字识别的深度CNN
基于手写数字识别的深度CNN
如上图,我们创建了一个比之前实现的网络都深的神经网络。这个网络有如下特点:
(1)基于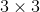 的小型滤波器的卷积层。
的小型滤波器的卷积层。
(2)激活函数是ReLU。
(3)全连接层的后面使用Dropout层。
(4)基于Adam的最优化。
(5)使用He初始值作为权重初始值。
代码请见附录,这里直接给出结论,这个网络的识别精度为99.38%,相当优秀了!
下面我们来看看0.62%的错误识别率所对应的部分图片。
 错误识别率的图像例子:左上角显示了正确解标签,右下角显示了本网络的推理结果。
错误识别率的图像例子:左上角显示了正确解标签,右下角显示了本网络的推理结果。
不难发现,识别错误的图像真的很难判断是哪个数字,即使是人类,也同样会犯"识别错误“。从这一点上,我们可以感受到深度CNN中蕴藏着巨大的可能性。
进一步提高识别精度
网站刊登了目前为止通过论文等渠道发表的针对各种数据集的方法的识别精度,如下图所示。可以发现“Neural Networks”、"Deep"、"Convolutional"等关键词特别显眼。截止到2016年6月,对MNIST数据集的最高识别精度是99.79%,该方法也是基于CNN为基础的。不过,它用的CNN并不是特别深层的网络(卷积层为2层。全连接层为2层的网络)。也就是说,并不是层越深,神经网络的性能就越好,这需要结合具体情况而定。
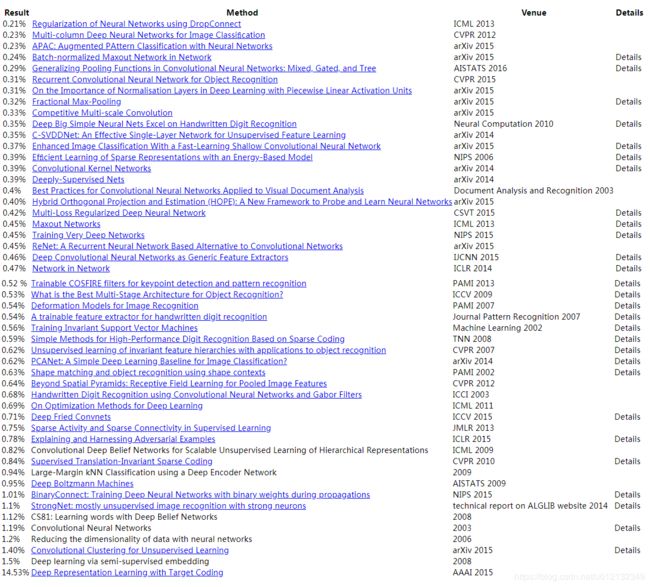 针对MNIST数据集的各种方法的排行
针对MNIST数据集的各种方法的排行
从排行榜前几名的方法,可以发现进一步提高识别精度的技术和线索。集成学习、学习率衰减、Data Augmentation(数据扩充)等都有助于提高识别精度。
需要强调的是,Data Augmentation基于算法“人为地”扩充图像(训练图像)。具体地说,如下图所示,对于输入图像,通过施加旋转、垂直或水平方向上的移动等微小变化,增加图像的数量。这在数据集的图像数量有限时尤其有效。
 Data Augmentation的例子
Data Augmentation的例子
Data Augmentation还可以通过其他各种方法扩充图像,比如裁剪图像的"crop处理"、将图像左右翻转的“flip处理”等。对于一般的图像,施加亮度等外观上的变化、放大缩小等尺度上的变化也是有效的。这里,我们不进行Data Augmentation的实现,有兴趣的读者请自己尝试一下。
加深层的好处
关于加深层的重要性,现状是理论研究还不够透彻。从现有研究结果来看,其中一个好处就是可以减少网络的参数数量。与没有加深层的网络相比,加深了层的网络可以用更少的参数达到同等水平的表现力。如下图所示,由5x5的滤波器构成的卷积层(没有加深层,参数数量有25个)。
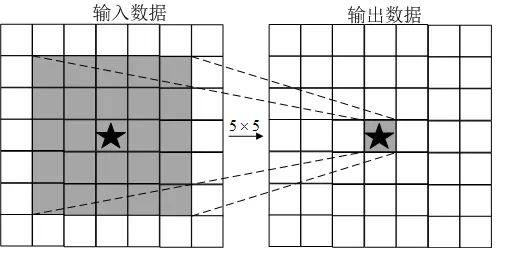 5 x 5的卷积运算的例子
5 x 5的卷积运算的例子
这里希望大家考虑一下输出数据的各个节点是从输入数据的哪个区域计算出来的。显然,在上图的例子中,每个输出节点都是从输入数据的某个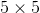 的区域算出来的。接下来我们思考下图中重复两次的卷积运算的情形。此时,每个输出节点将由中间数据的某个的区域计算出来。那么,中间数据的的区域又是由前一个输入数据(上图中的区域)的区域计算出来的。也就是说,下图的输出数据是“观察”了输入数据的某个的区域后计算出来的。
的区域算出来的。接下来我们思考下图中重复两次的卷积运算的情形。此时,每个输出节点将由中间数据的某个的区域计算出来。那么,中间数据的的区域又是由前一个输入数据(上图中的区域)的区域计算出来的。也就是说,下图的输出数据是“观察”了输入数据的某个的区域后计算出来的。
 重复两次3x3的卷积层的例子
重复两次3x3的卷积层的例子
一次的卷积运算的区域可以由两次的卷积运算抵充。并且,相对于前者的参数数量25(),后者一共是18(![]() ),通过叠加卷积层,参数数量减少了。
),通过叠加卷积层,参数数量减少了。
叠加小型滤波器来加深网络的好处是可以减少参数的数量,扩大感受野(receptive field,给神经元施加变化的某个布局空间区域)。并且,通过叠加层,将ReLu等激活函数夹在卷积层的中间,进一步提高了网络的表现力。这是因为向网络添加了基于激活函数的“非线性”表现力,通过非线性函数的叠加,可以表现更加复杂的东西。
加深层的另一个好处就是学习更加高效。一般地,通过加深层,可以分层地传递信息。也就是说,通过加深层,可以将各层要学习的问题分解成容易解决的简单问题,从而可以进行高效的学习。
深度学习的小历史
一般认为,现在深度学习之所以受到大量关注,其契机是2012年举办的大规模图像识别大赛ILSVRC(imageNet large scale visual recognition challenge)。在那年的比赛中,基于深度学习的方法(通称AlexNet)以压倒性的优势胜出,彻底颠覆了以往的图像识别方法。2012年深度学习的这场逆袭成为一个转折点,在之后的比赛中,深度学习一直活跃在舞台中央。以ILSVRC比赛为时间轴,看一下深度学习最近的发展趋势。
ImageNet
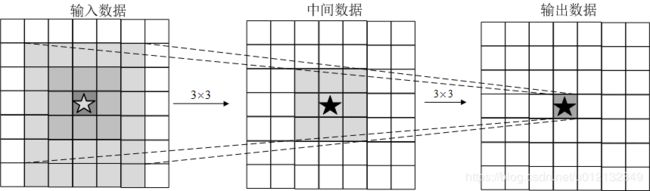
ImageNet是拥有超过100万张图像的数据集,并且每张图像都被关联了标签(类别名)。每年都会举办使用这个巨大数据集的ILSVRC图像识别大赛。其中一个测试项目是“类别分类”,比较识别精度。下图是从2010年到2015年的优胜队伍的成绩。从图中可知,在2015年的ResNet(一个超过150层的深度网络)将识别精度错误率降低到了3.5%,几乎超过了人类的识别能力。
 ILSCRV优胜队伍的成绩演变:竖轴是错误识别率,横轴是年份。横轴括号内是队伍名或者方法名
ILSCRV优胜队伍的成绩演变:竖轴是错误识别率,横轴是年份。横轴括号内是队伍名或者方法名
VGG
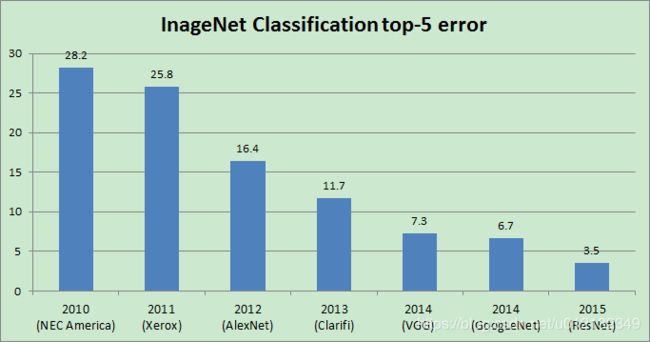
VGG是由卷积层和池化层构成的基础的CNN。如下图所示,它的特点在于将有权重的层(卷积层或者全连接层)叠加至16层(或者19层),具备了深度。需要注意的是,基于的小型滤波器的卷积层的运算是连续进行的。重复进行“卷积层重叠2次到4次,再通过池化层将大小减半”的处理,最后经由全连接层输出结果。
 VGG
VGG
GoogLeNet
GoogLeNet的网络结构如下图所示,图中的矩形表示卷积层、池化层等。
 GoogLeNet
GoogLeNet
GoogLeNet的特征是,网络不仅在纵向上有深度,在横向上也有深度(宽度)。GoogLeNet在横向上有“宽度”,这称为“Inception结构”,如下图所示。Inception结构使用了多个大小不同的滤波器(和池化),最后再合并它们的结果。GoogLeNet的特征就是将这个Inception结构用作一个构件(构成元素)。此外,在GoogLeNet中,很多地方都使用了大小为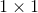 的滤波器的卷积层。这个的卷积层运算通过在通道方向上减小大小,有助于减少参数和实现高速化处理。
的滤波器的卷积层。这个的卷积层运算通过在通道方向上减小大小,有助于减少参数和实现高速化处理。
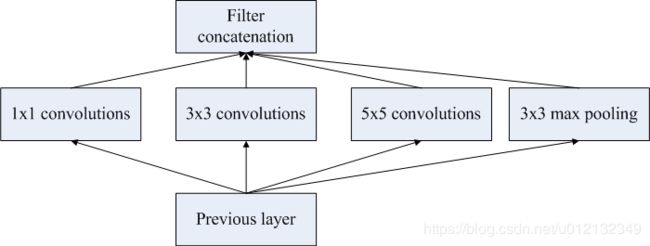 GoogLetNet的Inception结构
GoogLetNet的Inception结构
ResNet
ResNet是微软团队开发的网络,它的特征在于具有比以前的网络更深的结构。在深度学习中,过度地加深层的话,很多情况下学习将不能顺利进行,导致最终性能不佳。为解决这个问题,ResNet导入了“快捷结构”,使得随着层的加深而不断提高性能了。如下图所示,快捷结构横跨了输入数据的卷积层,将输入 合计到输出。
合计到输出。
图中,在连续2层的卷积层中,将输入跳着连接至2层后的输出。这里的重点是,通过快捷结构,原来的2层卷积层的输出 变成了
变成了![]() ,通过这种快捷结构,即使加深层,也能高效地学习。这是因为,通过快捷结构,反向传播时信号可以无衰减地传递。
,通过这种快捷结构,即使加深层,也能高效地学习。这是因为,通过快捷结构,反向传播时信号可以无衰减地传递。
 ResNet 的构成要素
ResNet 的构成要素
ResNet以前面介绍过的VGG网络为基础,引入快捷结构以加深层,其结果如下图所示。ResNet通过以2个卷积层为间隔跳跃式地连接来加深层。另外,根据实验结果,即便加深到150层以上,识别精度也会持续提高。并且,在ILSVRC大赛中,ResNet的错误识别率为3.5%。
 ResNet:方块对应3x3的卷积层,其特征在于引入了横跨层的快捷结构
ResNet:方块对应3x3的卷积层,其特征在于引入了横跨层的快捷结构
实践中经常会灵活应用使用ResNet这个巨大的数据集学习到的权重数据,这成为迁移学习,将学习完的权重(的一部分)复制到其他神经网络,进行再学习。比如,准备一个和VGG相同结构的网络,把学习完的权重作为初始值,以新数据集为对象,进行再学习。迁移学习在手头数据集较少时非常有效。
附录
# coding: utf-8
#基于手写数字识别的深度CNN的网络的源代码
import pickle
import numpy as np
from collections import OrderedDict
from common.layers import * #layer.py文件在下面
class DeepConvNet:
"""识别率为99%以上的高精度的ConvNet
网络结构如下所示
conv - relu - conv- relu - pool -
conv - relu - conv- relu - pool -
conv - relu - conv- relu - pool -
affine - relu - dropout - affine - dropout - softmax
"""
def __init__(self, input_dim=(1, 28, 28),
conv_param_1 = {'filter_num':16, 'filter_size':3, 'pad':1, 'stride':1},
conv_param_2 = {'filter_num':16, 'filter_size':3, 'pad':1, 'stride':1},
conv_param_3 = {'filter_num':32, 'filter_size':3, 'pad':1, 'stride':1},
conv_param_4 = {'filter_num':32, 'filter_size':3, 'pad':2, 'stride':1},
conv_param_5 = {'filter_num':64, 'filter_size':3, 'pad':1, 'stride':1},
conv_param_6 = {'filter_num':64, 'filter_size':3, 'pad':1, 'stride':1},
hidden_size=50, output_size=10):
# 初始化权重===========
# 各层的神经元平均与前一层的几个神经元有连接(TODO:自动计算)
pre_node_nums = np.array([1*3*3, 16*3*3, 16*3*3, 32*3*3, 32*3*3, 64*3*3, 64*4*4, hidden_size])
wight_init_scales = np.sqrt(2.0 / pre_node_nums) # 使用ReLU的情况下推荐的初始值
self.params = {}
pre_channel_num = input_dim[0]
for idx, conv_param in enumerate([conv_param_1, conv_param_2, conv_param_3, conv_param_4, conv_param_5, conv_param_6]):
self.params['W' + str(idx+1)] = wight_init_scales[idx] * np.random.randn(conv_param['filter_num'], pre_channel_num, conv_param['filter_size'], conv_param['filter_size'])
self.params['b' + str(idx+1)] = np.zeros(conv_param['filter_num'])
pre_channel_num = conv_param['filter_num']
self.params['W7'] = wight_init_scales[6] * np.random.randn(64*4*4, hidden_size)
self.params['b7'] = np.zeros(hidden_size)
self.params['W8'] = wight_init_scales[7] * np.random.randn(hidden_size, output_size)
self.params['b8'] = np.zeros(output_size)
# 生成层===========
self.layers = []
self.layers.append(Convolution(self.params['W1'], self.params['b1'],
conv_param_1['stride'], conv_param_1['pad']))
self.layers.append(Relu())
self.layers.append(Convolution(self.params['W2'], self.params['b2'],
conv_param_2['stride'], conv_param_2['pad']))
self.layers.append(Relu())
self.layers.append(Pooling(pool_h=2, pool_w=2, stride=2))
self.layers.append(Convolution(self.params['W3'], self.params['b3'],
conv_param_3['stride'], conv_param_3['pad']))
self.layers.append(Relu())
self.layers.append(Convolution(self.params['W4'], self.params['b4'],
conv_param_4['stride'], conv_param_4['pad']))
self.layers.append(Relu())
self.layers.append(Pooling(pool_h=2, pool_w=2, stride=2))
self.layers.append(Convolution(self.params['W5'], self.params['b5'],
conv_param_5['stride'], conv_param_5['pad']))
self.layers.append(Relu())
self.layers.append(Convolution(self.params['W6'], self.params['b6'],
conv_param_6['stride'], conv_param_6['pad']))
self.layers.append(Relu())
self.layers.append(Pooling(pool_h=2, pool_w=2, stride=2))
self.layers.append(Affine(self.params['W7'], self.params['b7']))
self.layers.append(Relu())
self.layers.append(Dropout(0.5))
self.layers.append(Affine(self.params['W8'], self.params['b8']))
self.layers.append(Dropout(0.5))
self.last_layer = SoftmaxWithLoss()
def predict(self, x, train_flg=False):
for layer in self.layers:
if isinstance(layer, Dropout):
x = layer.forward(x, train_flg)
else:
x = layer.forward(x)
return x
def loss(self, x, t):
y = self.predict(x, train_flg=True)
return self.last_layer.forward(y, t)
def accuracy(self, x, t, batch_size=100):
if t.ndim != 1 : t = np.argmax(t, axis=1)
acc = 0.0
for i in range(int(x.shape[0] / batch_size)):
tx = x[i*batch_size:(i+1)*batch_size]
tt = t[i*batch_size:(i+1)*batch_size]
y = self.predict(tx, train_flg=False)
y = np.argmax(y, axis=1)
acc += np.sum(y == tt)
return acc / x.shape[0]
def gradient(self, x, t):
# forward
self.loss(x, t)
# backward
dout = 1
dout = self.last_layer.backward(dout)
tmp_layers = self.layers.copy()
tmp_layers.reverse()
for layer in tmp_layers:
dout = layer.backward(dout)
# 设定
grads = {}
for i, layer_idx in enumerate((0, 2, 5, 7, 10, 12, 15, 18)):
grads['W' + str(i+1)] = self.layers[layer_idx].dW
grads['b' + str(i+1)] = self.layers[layer_idx].db
return grads
def save_params(self, file_name="params.pkl"):
params = {}
for key, val in self.params.items():
params[key] = val
with open(file_name, 'wb') as f:
pickle.dump(params, f)
def load_params(self, file_name="params.pkl"):
with open(file_name, 'rb') as f:
params = pickle.load(f)
for key, val in params.items():
self.params[key] = val
for i, layer_idx in enumerate((0, 2, 5, 7, 10, 12, 15, 18)):
self.layers[layer_idx].W = self.params['W' + str(i+1)]
self.layers[layer_idx].b = self.params['b' + str(i+1)]
# coding: utf-8
#layer.py文件
import numpy as np
from common.functions import * #function.py文件在下面
from common.util import im2col, col2im #util.py文件在下面
class Relu:
def __init__(self):
self.mask = None
def forward(self, x):
self.mask = (x <= 0)
out = x.copy()
out[self.mask] = 0
return out
def backward(self, dout):
dout[self.mask] = 0
dx = dout
return dx
class Sigmoid:
def __init__(self):
self.out = None
def forward(self, x):
out = sigmoid(x)
self.out = out
return out
def backward(self, dout):
dx = dout * (1.0 - self.out) * self.out
return dx
class Affine:
def __init__(self, W, b):
self.W =W
self.b = b
self.x = None
self.original_x_shape = None
# 权重和偏置参数的导数
self.dW = None
self.db = None
def forward(self, x):
# 对应张量
self.original_x_shape = x.shape
x = x.reshape(x.shape[0], -1)
self.x = x
out = np.dot(self.x, self.W) + self.b
return out
def backward(self, dout):
dx = np.dot(dout, self.W.T)
self.dW = np.dot(self.x.T, dout)
self.db = np.sum(dout, axis=0)
dx = dx.reshape(*self.original_x_shape) # 还原输入数据的形状(对应张量)
return dx
class SoftmaxWithLoss:
def __init__(self):
self.loss = None
self.y = None # softmax的输出
self.t = None # 监督数据
def forward(self, x, t):
self.t = t
self.y = softmax(x)
self.loss = cross_entropy_error(self.y, self.t)
return self.loss
def backward(self, dout=1):
batch_size = self.t.shape[0]
if self.t.size == self.y.size: # 监督数据是one-hot-vector的情况
dx = (self.y - self.t) / batch_size
else:
dx = self.y.copy()
dx[np.arange(batch_size), self.t] -= 1
dx = dx / batch_size
return dx
class Dropout:
"""
http://arxiv.org/abs/1207.0580
"""
def __init__(self, dropout_ratio=0.5):
self.dropout_ratio = dropout_ratio
self.mask = None
def forward(self, x, train_flg=True):
if train_flg:
self.mask = np.random.rand(*x.shape) > self.dropout_ratio
return x * self.mask
else:
return x * (1.0 - self.dropout_ratio)
def backward(self, dout):
return dout * self.mask
class BatchNormalization:
"""
http://arxiv.org/abs/1502.03167
"""
def __init__(self, gamma, beta, momentum=0.9, running_mean=None, running_var=None):
self.gamma = gamma
self.beta = beta
self.momentum = momentum
self.input_shape = None # Conv层的情况下为4维,全连接层的情况下为2维
# 测试时使用的平均值和方差
self.running_mean = running_mean
self.running_var = running_var
# backward时使用的中间数据
self.batch_size = None
self.xc = None
self.std = None
self.dgamma = None
self.dbeta = None
def forward(self, x, train_flg=True):
self.input_shape = x.shape
if x.ndim != 2:
N, C, H, W = x.shape
x = x.reshape(N, -1)
out = self.__forward(x, train_flg)
return out.reshape(*self.input_shape)
def __forward(self, x, train_flg):
if self.running_mean is None:
N, D = x.shape
self.running_mean = np.zeros(D)
self.running_var = np.zeros(D)
if train_flg:
mu = x.mean(axis=0)
xc = x - mu
var = np.mean(xc**2, axis=0)
std = np.sqrt(var + 10e-7)
xn = xc / std
self.batch_size = x.shape[0]
self.xc = xc
self.xn = xn
self.std = std
self.running_mean = self.momentum * self.running_mean + (1-self.momentum) * mu
self.running_var = self.momentum * self.running_var + (1-self.momentum) * var
else:
xc = x - self.running_mean
xn = xc / ((np.sqrt(self.running_var + 10e-7)))
out = self.gamma * xn + self.beta
return out
def backward(self, dout):
if dout.ndim != 2:
N, C, H, W = dout.shape
dout = dout.reshape(N, -1)
dx = self.__backward(dout)
dx = dx.reshape(*self.input_shape)
return dx
def __backward(self, dout):
dbeta = dout.sum(axis=0)
dgamma = np.sum(self.xn * dout, axis=0)
dxn = self.gamma * dout
dxc = dxn / self.std
dstd = -np.sum((dxn * self.xc) / (self.std * self.std), axis=0)
dvar = 0.5 * dstd / self.std
dxc += (2.0 / self.batch_size) * self.xc * dvar
dmu = np.sum(dxc, axis=0)
dx = dxc - dmu / self.batch_size
self.dgamma = dgamma
self.dbeta = dbeta
return dx
class Convolution:
def __init__(self, W, b, stride=1, pad=0):
self.W = W
self.b = b
self.stride = stride
self.pad = pad
# 中间数据(backward时使用)
self.x = None
self.col = None
self.col_W = None
# 权重和偏置参数的梯度
self.dW = None
self.db = None
def forward(self, x):
FN, C, FH, FW = self.W.shape
N, C, H, W = x.shape
out_h = 1 + int((H + 2*self.pad - FH) / self.stride)
out_w = 1 + int((W + 2*self.pad - FW) / self.stride)
col = im2col(x, FH, FW, self.stride, self.pad)
col_W = self.W.reshape(FN, -1).T
out = np.dot(col, col_W) + self.b
out = out.reshape(N, out_h, out_w, -1).transpose(0, 3, 1, 2)
self.x = x
self.col = col
self.col_W = col_W
return out
def backward(self, dout):
FN, C, FH, FW = self.W.shape
dout = dout.transpose(0,2,3,1).reshape(-1, FN)
self.db = np.sum(dout, axis=0)
self.dW = np.dot(self.col.T, dout)
self.dW = self.dW.transpose(1, 0).reshape(FN, C, FH, FW)
dcol = np.dot(dout, self.col_W.T)
dx = col2im(dcol, self.x.shape, FH, FW, self.stride, self.pad)
return dx
class Pooling:
def __init__(self, pool_h, pool_w, stride=1, pad=0):
self.pool_h = pool_h
self.pool_w = pool_w
self.stride = stride
self.pad = pad
self.x = None
self.arg_max = None
def forward(self, x):
N, C, H, W = x.shape
out_h = int(1 + (H - self.pool_h) / self.stride)
out_w = int(1 + (W - self.pool_w) / self.stride)
col = im2col(x, self.pool_h, self.pool_w, self.stride, self.pad)
col = col.reshape(-1, self.pool_h*self.pool_w)
arg_max = np.argmax(col, axis=1)
out = np.max(col, axis=1)
out = out.reshape(N, out_h, out_w, C).transpose(0, 3, 1, 2)
self.x = x
self.arg_max = arg_max
return out
def backward(self, dout):
dout = dout.transpose(0, 2, 3, 1)
pool_size = self.pool_h * self.pool_w
dmax = np.zeros((dout.size, pool_size))
dmax[np.arange(self.arg_max.size), self.arg_max.flatten()] = dout.flatten()
dmax = dmax.reshape(dout.shape + (pool_size,))
dcol = dmax.reshape(dmax.shape[0] * dmax.shape[1] * dmax.shape[2], -1)
dx = col2im(dcol, self.x.shape, self.pool_h, self.pool_w, self.stride, self.pad)
return dx
# coding: utf-8
#function.py文件
import numpy as np
def identity_function(x):
return x
def step_function(x):
return np.array(x > 0, dtype=np.int)
def sigmoid(x):
return 1 / (1 + np.exp(-x))
def sigmoid_grad(x):
return (1.0 - sigmoid(x)) * sigmoid(x)
def relu(x):
return np.maximum(0, x)
def relu_grad(x):
grad = np.zeros(x)
grad[x>=0] = 1
return grad
def softmax(x):
if x.ndim == 2:
x = x.T
x = x - np.max(x, axis=0)
y = np.exp(x) / np.sum(np.exp(x), axis=0)
return y.T
x = x - np.max(x) # 溢出对策
return np.exp(x) / np.sum(np.exp(x))
def mean_squared_error(y, t):
return 0.5 * np.sum((y-t)**2)
def cross_entropy_error(y, t):
if y.ndim == 1:
t = t.reshape(1, t.size)
y = y.reshape(1, y.size)
# 监督数据是one-hot-vector的情况下,转换为正确解标签的索引
if t.size == y.size:
t = t.argmax(axis=1)
batch_size = y.shape[0]
return -np.sum(np.log(y[np.arange(batch_size), t] + 1e-7)) / batch_size
def softmax_loss(X, t):
y = softmax(X)
return cross_entropy_error(y, t)
# coding: utf-8
#util.py文件
import numpy as np
def smooth_curve(x):
"""用于使损失函数的图形变圆滑
参考:http://glowingpython.blogspot.jp/2012/02/convolution-with-numpy.html
"""
window_len = 11
s = np.r_[x[window_len-1:0:-1], x, x[-1:-window_len:-1]]
w = np.kaiser(window_len, 2)
y = np.convolve(w/w.sum(), s, mode='valid')
return y[5:len(y)-5]
def shuffle_dataset(x, t):
"""打乱数据集
Parameters
----------
x : 训练数据
t : 监督数据
Returns
-------
x, t : 打乱的训练数据和监督数据
"""
permutation = np.random.permutation(x.shape[0])
x = x[permutation,:] if x.ndim == 2 else x[permutation,:,:,:]
t = t[permutation]
return x, t
def conv_output_size(input_size, filter_size, stride=1, pad=0):
return (input_size + 2*pad - filter_size) / stride + 1
def im2col(input_data, filter_h, filter_w, stride=1, pad=0):
"""
Parameters
----------
input_data : 由(数据量, 通道, 高, 长)的4维数组构成的输入数据
filter_h : 滤波器的高
filter_w : 滤波器的长
stride : 步幅
pad : 填充
Returns
-------
col : 2维数组
"""
N, C, H, W = input_data.shape
out_h = (H + 2*pad - filter_h)//stride + 1
out_w = (W + 2*pad - filter_w)//stride + 1
img = np.pad(input_data, [(0,0), (0,0), (pad, pad), (pad, pad)], 'constant')
col = np.zeros((N, C, filter_h, filter_w, out_h, out_w))
for y in range(filter_h):
y_max = y + stride*out_h
for x in range(filter_w):
x_max = x + stride*out_w
col[:, :, y, x, :, :] = img[:, :, y:y_max:stride, x:x_max:stride]
col = col.transpose(0, 4, 5, 1, 2, 3).reshape(N*out_h*out_w, -1)
return col
def col2im(col, input_shape, filter_h, filter_w, stride=1, pad=0):
"""
Parameters
----------
col :
input_shape : 输入数据的形状(例:(10, 1, 28, 28))
filter_h :
filter_w
stride
pad
Returns
-------
"""
N, C, H, W = input_shape
out_h = (H + 2*pad - filter_h)//stride + 1
out_w = (W + 2*pad - filter_w)//stride + 1
col = col.reshape(N, out_h, out_w, C, filter_h, filter_w).transpose(0, 3, 4, 5, 1, 2)
img = np.zeros((N, C, H + 2*pad + stride - 1, W + 2*pad + stride - 1))
for y in range(filter_h):
y_max = y + stride*out_h
for x in range(filter_w):
x_max = x + stride*out_w
img[:, :, y:y_max:stride, x:x_max:stride] += col[:, :, y, x, :, :]
return img[:, :, pad:H + pad, pad:W + pad]训练网络的代码:
# coding: utf-8
import sys, os
sys.path.append(os.pardir) # 为了导入父目录而进行的设定
import numpy as np
import matplotlib.pyplot as plt
from mnist import load_mnist #mnist.py文件在下面
from deep_convnet import DeepConvNet #deep_convnet.py文件在下面
from common.trainer import Trainer
(x_train, t_train), (x_test, t_test) = load_mnist(flatten=False)
network = DeepConvNet()
trainer = Trainer(network, x_train, t_train, x_test, t_test,
epochs=20, mini_batch_size=100,
optimizer='Adam', optimizer_param={'lr':0.001},
evaluate_sample_num_per_epoch=1000)
trainer.train()
# 保存参数
network.save_params("deep_convnet_params.pkl")
print("Saved Network Parameters!")
# coding: utf-8
#mnist.py文件
try:
import urllib.request
except ImportError:
raise ImportError('You should use Python 3.x')
import os.path
import gzip
import pickle
import os
import numpy as np
url_base = 'http://yann.lecun.com/exdb/mnist/'
key_file = {
'train_img':'train-images-idx3-ubyte.gz',
'train_label':'train-labels-idx1-ubyte.gz',
'test_img':'t10k-images-idx3-ubyte.gz',
'test_label':'t10k-labels-idx1-ubyte.gz'
}
dataset_dir = os.path.dirname(os.path.abspath(__file__))
save_file = dataset_dir + "/mnist.pkl"
train_num = 60000
test_num = 10000
img_dim = (1, 28, 28)
img_size = 784
def _download(file_name):
file_path = dataset_dir + "/" + file_name
if os.path.exists(file_path):
return
print("Downloading " + file_name + " ... ")
urllib.request.urlretrieve(url_base + file_name, file_path)
print("Done")
def download_mnist():
for v in key_file.values():
_download(v)
def _load_label(file_name):
file_path = dataset_dir + "/" + file_name
print("Converting " + file_name + " to NumPy Array ...")
with gzip.open(file_path, 'rb') as f:
labels = np.frombuffer(f.read(), np.uint8, offset=8)
print("Done")
return labels
def _load_img(file_name):
file_path = dataset_dir + "/" + file_name
print("Converting " + file_name + " to NumPy Array ...")
with gzip.open(file_path, 'rb') as f:
data = np.frombuffer(f.read(), np.uint8, offset=16)
data = data.reshape(-1, img_size)
print("Done")
return data
def _convert_numpy():
dataset = {}
dataset['train_img'] = _load_img(key_file['train_img'])
dataset['train_label'] = _load_label(key_file['train_label'])
dataset['test_img'] = _load_img(key_file['test_img'])
dataset['test_label'] = _load_label(key_file['test_label'])
return dataset
def init_mnist():
download_mnist()
dataset = _convert_numpy()
print("Creating pickle file ...")
with open(save_file, 'wb') as f:
pickle.dump(dataset, f, -1)
print("Done!")
def _change_one_hot_label(X):
T = np.zeros((X.size, 10))
for idx, row in enumerate(T):
row[X[idx]] = 1
return T
def load_mnist(normalize=True, flatten=True, one_hot_label=False):
"""读入MNIST数据集
Parameters
----------
normalize : 将图像的像素值正规化为0.0~1.0
one_hot_label :
one_hot_label为True的情况下,标签作为one-hot数组返回
one-hot数组是指[0,0,1,0,0,0,0,0,0,0]这样的数组
flatten : 是否将图像展开为一维数组
Returns
-------
(训练图像, 训练标签), (测试图像, 测试标签)
"""
if not os.path.exists(save_file):
init_mnist()
with open(save_file, 'rb') as f:
dataset = pickle.load(f)
if normalize:
for key in ('train_img', 'test_img'):
dataset[key] = dataset[key].astype(np.float32)
dataset[key] /= 255.0
if one_hot_label:
dataset['train_label'] = _change_one_hot_label(dataset['train_label'])
dataset['test_label'] = _change_one_hot_label(dataset['test_label'])
if not flatten:
for key in ('train_img', 'test_img'):
dataset[key] = dataset[key].reshape(-1, 1, 28, 28)
return (dataset['train_img'], dataset['train_label']), (dataset['test_img'], dataset['test_label'])
if __name__ == '__main__':
init_mnist()
# coding: utf-8
#deep_convet.py文件
import sys, os
sys.path.append(os.pardir) # 为了导入父目录的文件而进行的设定
import pickle
import numpy as np
from collections import OrderedDict
from common.layers import *
class DeepConvNet:
"""识别率为99%以上的高精度的ConvNet
网络结构如下所示
conv - relu - conv- relu - pool -
conv - relu - conv- relu - pool -
conv - relu - conv- relu - pool -
affine - relu - dropout - affine - dropout - softmax
"""
def __init__(self, input_dim=(1, 28, 28),
conv_param_1 = {'filter_num':16, 'filter_size':3, 'pad':1, 'stride':1},
conv_param_2 = {'filter_num':16, 'filter_size':3, 'pad':1, 'stride':1},
conv_param_3 = {'filter_num':32, 'filter_size':3, 'pad':1, 'stride':1},
conv_param_4 = {'filter_num':32, 'filter_size':3, 'pad':2, 'stride':1},
conv_param_5 = {'filter_num':64, 'filter_size':3, 'pad':1, 'stride':1},
conv_param_6 = {'filter_num':64, 'filter_size':3, 'pad':1, 'stride':1},
hidden_size=50, output_size=10):
# 初始化权重===========
# 各层的神经元平均与前一层的几个神经元有连接(TODO:自动计算)
pre_node_nums = np.array([1*3*3, 16*3*3, 16*3*3, 32*3*3, 32*3*3, 64*3*3, 64*4*4, hidden_size])
wight_init_scales = np.sqrt(2.0 / pre_node_nums) # 使用ReLU的情况下推荐的初始值
self.params = {}
pre_channel_num = input_dim[0]
for idx, conv_param in enumerate([conv_param_1, conv_param_2, conv_param_3, conv_param_4, conv_param_5, conv_param_6]):
self.params['W' + str(idx+1)] = wight_init_scales[idx] * np.random.randn(conv_param['filter_num'], pre_channel_num, conv_param['filter_size'], conv_param['filter_size'])
self.params['b' + str(idx+1)] = np.zeros(conv_param['filter_num'])
pre_channel_num = conv_param['filter_num']
self.params['W7'] = wight_init_scales[6] * np.random.randn(64*4*4, hidden_size)
self.params['b7'] = np.zeros(hidden_size)
self.params['W8'] = wight_init_scales[7] * np.random.randn(hidden_size, output_size)
self.params['b8'] = np.zeros(output_size)
# 生成层===========
self.layers = []
self.layers.append(Convolution(self.params['W1'], self.params['b1'],
conv_param_1['stride'], conv_param_1['pad']))
self.layers.append(Relu())
self.layers.append(Convolution(self.params['W2'], self.params['b2'],
conv_param_2['stride'], conv_param_2['pad']))
self.layers.append(Relu())
self.layers.append(Pooling(pool_h=2, pool_w=2, stride=2))
self.layers.append(Convolution(self.params['W3'], self.params['b3'],
conv_param_3['stride'], conv_param_3['pad']))
self.layers.append(Relu())
self.layers.append(Convolution(self.params['W4'], self.params['b4'],
conv_param_4['stride'], conv_param_4['pad']))
self.layers.append(Relu())
self.layers.append(Pooling(pool_h=2, pool_w=2, stride=2))
self.layers.append(Convolution(self.params['W5'], self.params['b5'],
conv_param_5['stride'], conv_param_5['pad']))
self.layers.append(Relu())
self.layers.append(Convolution(self.params['W6'], self.params['b6'],
conv_param_6['stride'], conv_param_6['pad']))
self.layers.append(Relu())
self.layers.append(Pooling(pool_h=2, pool_w=2, stride=2))
self.layers.append(Affine(self.params['W7'], self.params['b7']))
self.layers.append(Relu())
self.layers.append(Dropout(0.5))
self.layers.append(Affine(self.params['W8'], self.params['b8']))
self.layers.append(Dropout(0.5))
self.last_layer = SoftmaxWithLoss()
def predict(self, x, train_flg=False):
for layer in self.layers:
if isinstance(layer, Dropout):
x = layer.forward(x, train_flg)
else:
x = layer.forward(x)
return x
def loss(self, x, t):
y = self.predict(x, train_flg=True)
return self.last_layer.forward(y, t)
def accuracy(self, x, t, batch_size=100):
if t.ndim != 1 : t = np.argmax(t, axis=1)
acc = 0.0
for i in range(int(x.shape[0] / batch_size)):
tx = x[i*batch_size:(i+1)*batch_size]
tt = t[i*batch_size:(i+1)*batch_size]
y = self.predict(tx, train_flg=False)
y = np.argmax(y, axis=1)
acc += np.sum(y == tt)
return acc / x.shape[0]
def gradient(self, x, t):
# forward
self.loss(x, t)
# backward
dout = 1
dout = self.last_layer.backward(dout)
tmp_layers = self.layers.copy()
tmp_layers.reverse()
for layer in tmp_layers:
dout = layer.backward(dout)
# 设定
grads = {}
for i, layer_idx in enumerate((0, 2, 5, 7, 10, 12, 15, 18)):
grads['W' + str(i+1)] = self.layers[layer_idx].dW
grads['b' + str(i+1)] = self.layers[layer_idx].db
return grads
def save_params(self, file_name="params.pkl"):
params = {}
for key, val in self.params.items():
params[key] = val
with open(file_name, 'wb') as f:
pickle.dump(params, f)
def load_params(self, file_name="params.pkl"):
with open(file_name, 'rb') as f:
params = pickle.load(f)
for key, val in params.items():
self.params[key] = val
for i, layer_idx in enumerate((0, 2, 5, 7, 10, 12, 15, 18)):
self.layers[layer_idx].W = self.params['W' + str(i+1)]
self.layers[layer_idx].b = self.params['b' + str(i+1)]
欢迎关注微信公众号“Python生态智联”,学知识,享生活!