管程 --- 悲观锁(阻塞)
临界区
一段代码块对共享资源存在多个线程的读写操作, 我们就叫它临界区
临界区存在多个线程竞争共享资源的问题, 由于分时系统, 我们的cpu不能一直负责一条线程的执行, 所以在cpu切换的时候需要保存当时的场景, 之后cpu回来后需要恢复场景再次执行代码, 我们简称这个过程为线程上下文切换
而线程竞争共享资源的这个过程中, 由于执行序列不同而导致的结果无法预测, 我们称之为竞态条件
synchronized(重量级锁)
synchronized重量级锁我们称之为(对象锁)方案, 意味着这个方案的时候需要一个对象, 使用这个方案我们就再也不需要担心线程上下文切换导致的问题了, 在这个代码块中永远只会有一个线程执行, 直到线程释放了这个对象锁
官方版: 对象锁保证了临界区的原子性
注意: 同时我发现锁方案不能规避代码重排的问题, 前文懒汉模式对象的volatile关键字就是因为这个原因
synchronized修饰方式:
修饰在普通方法或者使用this作为对象锁的对象 ----- 都表示把this类对象当作对象锁的对象
修饰在静态方法或者类.class方法进行修饰 ----- 表示将类名作为对象锁的对象
JMM关于synchronized的两条规定
- 线程解锁前,必须把共享变量的最新值刷新到主内存
- 线程加锁时,将清空工作内存中共享变量的值,从而使用共享变量时需要从主内存中重新读取最新的值(注意加锁与解锁是同- -把锁)
@Slf4j
public class Demo01 {
private static int counter = 0;
private static Object lock = new Object();
@Test
public void test04() throws Exception {
Thread t1 = new Thread(() -> {
for (int i = 0; i < 5000; i++) {
synchronized (lock) {
counter++;
}
}
}, "t1");
Thread t2 = new Thread(() -> {
for (int i = 0; i < 5000; i++) {
synchronized (lock) {
counter--;
}
}
}, "t2");
t1.start();
t2.start();
t1.join();
t2.join();
log.debug("res counter = {}", counter);
}
}
注意: 对象锁的对象是非常重要的, 对象就是一把钥匙, 被线程1拿走了, 线程2只能等线程1用完了还回来继续用
其底层使用的是monitor锁的概念
Monitor概念
java对象头
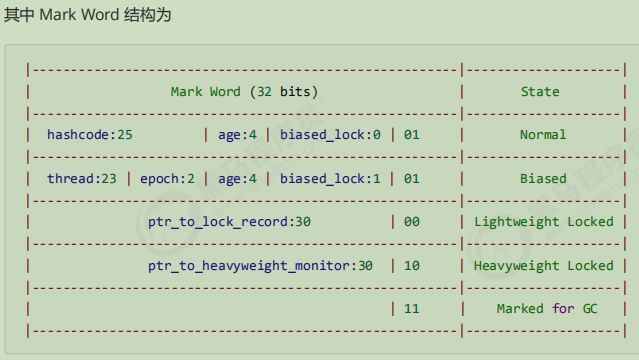
在32位虚拟机前提下:
首先要了解 JVM 对象结构, hotspot 虚拟机的对象头结构分成两个部分
第一部分用于存储对象运行时数据, 如hashcode, gc 分代年龄等等, 另一部分主要存储这部分数据的长度在32位和64位的Java虚拟机中分别会占用32个或64个比特,官方称它为“Mark Word”。这部分是实现轻量级锁和偏向锁的关键, 另外一部分用于存储指向方法区对象类型数据的指针

由于对象头信息是与对象自身定义的数据无关的额外存储成本,考虑到Java虚拟机的空间使用效率,Mark Word被设计成一个非固定的动态数据结构,以便在极小的空间内存储尽量多的信息。它会根据对象的状态复用自己的存储空间。
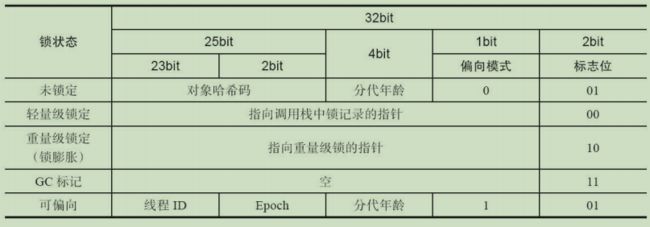
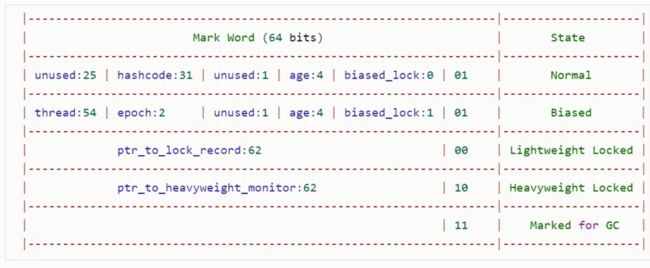
64 位虚拟机 Mark Word:
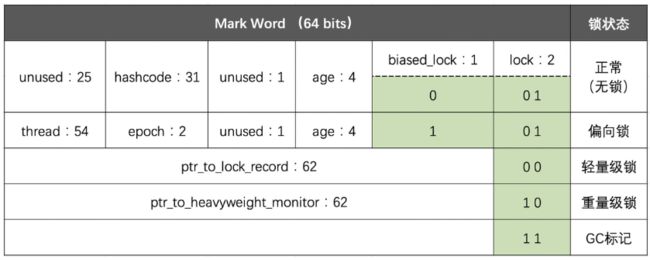

橙色部分可以代表锁状态
Klass World(代表类型) 指针指向了Class对象的地址; age: 幸存区年龄, 一次自增一次, 直到15次, 直接送到老年区
对象头只对象才会有, 如果是基本类型的话, 则没有
比如 int是4 Integer 则是12
注意: 为什么锁对象不能是
Integer?
很简单, 其实如果Integer对象的值在[-128, 127]之间由IntegerCache接管, 都是同一个对象, 如果超出这个范围则会创建一个新的对象
java对象内存布局
添加 jol java object layout 查看java对象mark word klass pointer 和 instance data 还有一个8字节对齐功能padding
java.lang.Object object internals:
| OFFSET | SIZE | TYPE | DESCRIPTION | VALUE |
|---|---|---|---|---|
| 0 | 4 | (object header) | 05 00 00 00 (00000101 00000000 00000000 00000000) (5) | mark word |
| 4 | 4 | (object header) | 00 00 00 00 (00000000 00000000 00000000 00000000) (0) | mark word |
| 8 | 4 | (object header) | 00 10 00 00 (00000000 00010000 00000000 00000000) (4096) | klass pointer |
| 12 | 4 | (loss due to the next object alignment) | alignment |
Instance size: 16 bytes
Space losses: 0 bytes internal + 4 bytes external = 4 bytes total
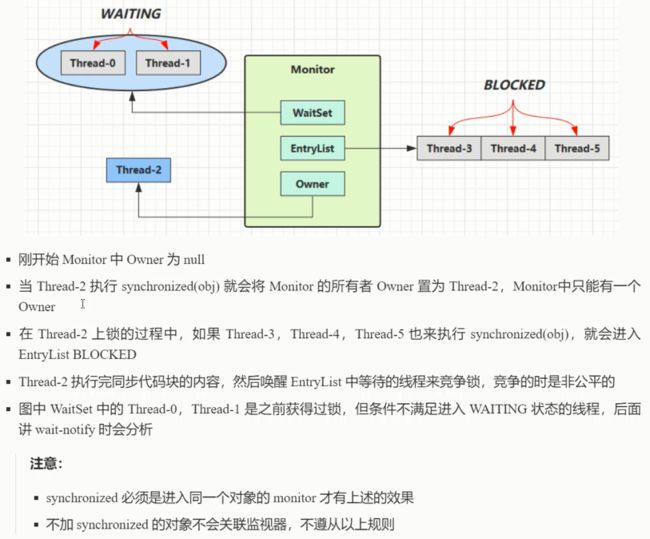
Monitor(锁) --- synchronized底层原理
是什么???
monitor被翻译成监视器或者管程
每个Java对象都可以关联一个Monitor对象,如果使用synchronized给对象上锁(重量级锁)之后, 该对象头的Mark Monitor 中被设置指向Monitor对象的指针
Monitor结构如下:
java源码:
@Slf4j
public class SynchronizedDemo {
final Object lock = new Object();
int counter = 0;
@Test
public void test() {
synchronized (lock) {
counter++;
}
}
}
字节码:
public void test();
Code:
0: aload_0
1: getfield #3 // lock 引用(synchronized开始)
4: dup
5: astore_1 // lock引用 -> slot 1
6: monitorenter // 将lock对象MarkWord置为Monitor指针
7: aload_0
8: dup
9: getfield #4 // i
12: iconst_1 // 准备常数 1
13: iadd // +1
14: putfield #4 // i
17: aload_1 // lock 引用
18: monitorexit // 将 lock 对象 MarkWord 重置, 唤醒 EntryList
19: goto 27
22: astore_2 // e -> slot2, 将异常放入 slot2
23: aload_1 // lock 引用
24: monitorexit // 将 lock 对象 MarkWord 重置, 唤醒 EntryList
25: aload_2 // slot2 (e)
26: athrow // throw e
27: return
Exception table:
from to target type
7 19 22 any // 监控异常 7~19行只要发生错误跳转到 22 行处理
22 25 22 any
Synchronized底层原理进阶(锁优化)
可重入代码(Reentrant Code):这种代码又称纯代码(Pure Code),是指可以在代码执行的任何时刻中断它, 转而去执行另一段代码, 而在控制权限返回之后, 重新回到这个方法后不会有任何的影响, 这种代码就是可重入代码
可重入代码有一些共同的特征,例如,不依赖全局变量、存储在堆上的数据和公用的系统资源,用到的状态量都由参数中传入,不调用非可重入的方法等。我们可以通过一个比较简单的原则来判断代码是否具备可重入性:如果一个方法的返回结果是可以预测的,只要输入了相同的数据,就都能返回相同的结果,那它就满足可重入性的要求,当然也就是线程安全的。
线程本地存储(Thread Local Storage):如果一段代码中所需要的数据必须与其他代码共享,那就看看这些共享数据的代码是否能保证在同一个线程中执行。如果能保证,我们就可以把共享数据的可见范围限制在同一个线程之内,这样,无须同步也能保证线程之间不出现数据争用的问题
案例: ThreadLocal web服务器, 一个请求一个线程
在我们使用事务时, 如果事务发起者的
Connection是不一样的, 那么这便是两个事务, 所以Connection将会被绑定在线程上, 让这个线程获取的Connection是同一个
小故事
故事角色
老王 - JVM
小南 - 线程
小女 - 线程
房间 - 对象
房间门上 - 防盗锁 - Monitor
房间门上 - 小南书包 - 轻量级锁
房间门上 - 刻上小南大名 - 偏向锁
批量重刻名 - 一个类的偏向锁撤销到达 20 阈值
不能刻名字 - 批量撤销该类对象的偏向锁,设置该类不可偏向
小南要使用房间保证计算不被其它人干扰(原子性),最初,他用的是防盗锁,当上下文切换时,锁住门。这样,即使他离开了,别人也进不了门,他的工作就是安全的。
但是,很多情况下没人跟他来竞争房间的使用权。小女是要用房间,但使用的时间上是错开的,小南白天用,小女晚上用。每次上锁太麻烦了,有没有更简单的办法呢?
小南和小女商量了一下,约定不锁门了,而是谁用房间,谁把自己的书包挂在门口,但他们的书包样式都一样,因此每次进门前得翻翻书包,看课本是谁的,如果是自己的,那么就可以进门,这样省的上锁解锁了。万一书包不是自己的,那么就在门外等,并通知对方下次用锁门的方式。
后来,小女回老家了,很长一段时间都不会用这个房间。小南每次还是挂书包,翻书包,虽然比锁门省事了,但仍然觉得麻烦。
于是,小南干脆在门上刻上了自己的名字:【小南专属房间,其它人勿用】,下次来用房间时,只要名字还在,那么说明没人打扰,还是可以安全地使用房间。如果这期间有其它人要用这个房间,那么由使用者将小南刻的名字擦掉,升级为挂书包的方式。
同学们都放假回老家了,小南就膨胀了,在 20 个房间刻上了自己的名字,想进哪个进哪个。后来他自己放假回老家了,这时小女回来了(她也要用这些房间),结果就是得一个个地擦掉小南刻的名字,升级为挂书包的方式。老王觉得这成本有点高,提出了一种批量重刻名的方法,他让小女不用挂书包了,可以直接在门上刻上自己的名字后来,刻名的现象越来越频繁(39次后),老王受不了了:算了,这些房间都不能刻名了,只能挂书包。(升级为轻量级锁了)
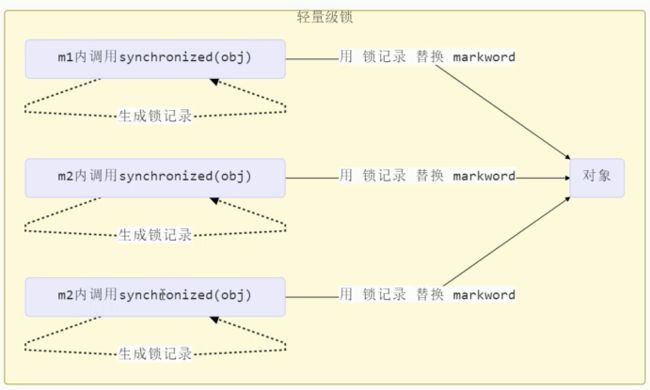
轻量级锁(自旋锁或无锁)
是什么???
顾名思义,轻量级锁是相对于重量级锁而言的。使用轻量级锁时,不需要申请互斥量,仅仅_将Mark Word中的部分字节CAS更新指向线程栈中的Lock Record,如果更新成功,则轻量级锁获取成功_,记录锁状态为轻量级锁;否则,说明已经有线程获得了轻量级锁,目前发生了锁竞争(不适合继续使用轻量级锁),接下来膨胀为重量级锁。
为什么要用轻量级锁???
为了防止某个时间段内不存在多线程竞争的环境使用上重量级锁浪费资源, 所以java引入了轻量级锁这个概念
什么时候使用轻量级锁?
如果一个对象虽然有多线程访问, 但是多线程的访问时间是错开的(也就是没有竞争关系), 那么就能够使用轻量级锁来优化, 轻量级锁对使用者是透明的, 关键字就是synchronized
怎么使用的轻量级锁?
假设存在两个同步块, 利用同一个对象加锁
@Slf4j
public class LightweightLockDemo {
private static final Object obj = new Object();
private static void method01() {
synchronized (obj) {
method02();
}
}
private static void method02() {
synchronized (obj) {
System.out.println("method02");
}
}
@Test
public void test() throws Exception {
method01();
}
}
加锁过程
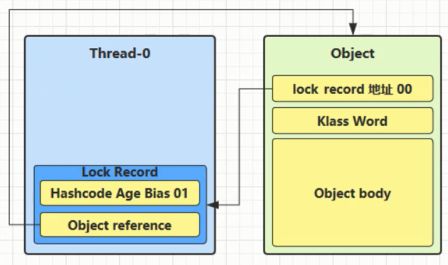
(1) 在线程栈里面创建一个锁记录(Lock Record)对象, 每个线程的栈帧都会存在一个锁记录(Lock Record)的结构, 内部可以存储对象的Mark Word
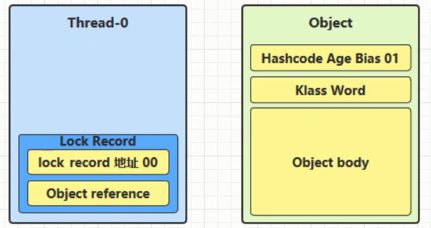
(2) 让锁记录中的Object reference指向锁对象的Object引用, 并尝试使用cas替换掉Object锁对象的Mark Word, 并将Mark Word 的值存入锁记录(交换)
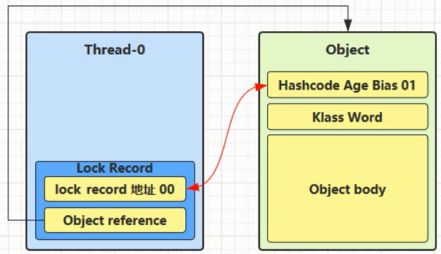
(3) 如果cas替换成功, 对象头中存储了锁记录地址和状态00, 表示由该线程对象加锁, 这时图示如下:
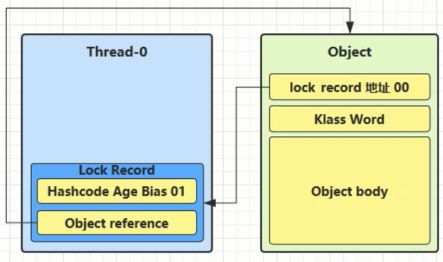

(4) 如果cas失败, 有两种情况:
-
如果是其他线程已经持有了该Object的轻量级锁, 这时表明有竞争, 进入说膨胀过程
-
如果时自己执行了 synchronized 锁重入, 那么再添加一条 Lock Record 作为重入的计数
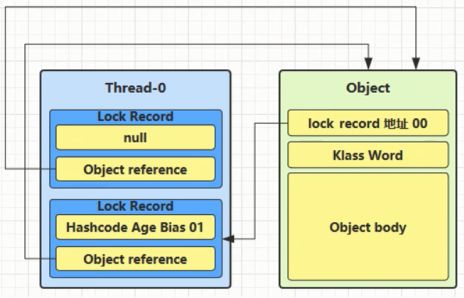
解锁过程
(1) 当退出 synchronized 代码块(解锁时)如果有取值为null的锁记录, 表示有重入, 这时重置锁记录, 表示重入计数减一
(2) 当退出 synchronized 代码块(解锁时)锁记录的值不为null, 这时使用 cas 将 Mark Word 的值恢复给对象头
- 成功, 则解锁成功
- 失败, 说明轻量级锁进行了锁膨胀或已经升级为重量级锁, 进入重量级锁解锁流程
锁膨胀
- 假设线程A获取了轻量级锁, 此时线程B也到了, 也需要获取轻量级锁, 此时线程B会自旋10次(不考虑自适应自旋), 如果超过10次还获取, 轻量级锁会膨胀到重量级
- 还有一种方式是自旋的线程超过cpu核心的一半, 那么也会膨胀
class Zhazha {
private static final Object obj = new Object();
private static void method01() {
synchronized (obj) {
// 同步代码块
}
}
}
(1) 当线程1进行轻量级锁加锁时, 发现线程0已经对该对象加上了轻量级锁
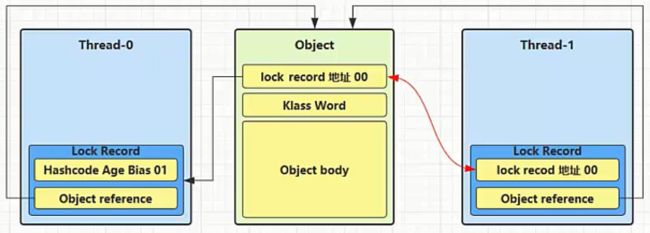

(2) 这时线程1加轻量级锁失败, 进入锁膨胀流程
-
即为Object对象申请Monitor锁, 让Object指向重量级锁地址
-
然后自己进入Monitor的EntryList BLOCKED
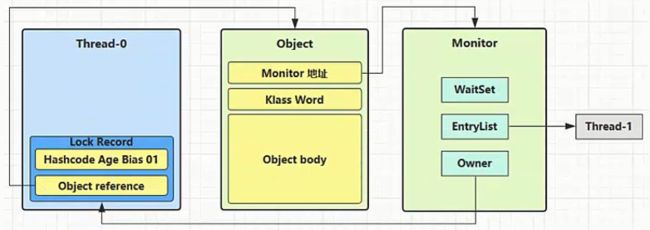
当线程0退出同步块解锁时, 使用cas将Mark Word 的值恢复给对象头, 失败. 这时会进入重量级解锁流程, 即按照Monitor地址找到Monitor对象, 设置Owner为null, 唤醒EntryList中BOCKED线程
优缺点
如果不存在竞争的话, 那么cas操作避免了互斥锁的重量级操作, 如果存在竞争的话, 那么这个操作不仅仅需要使用互斥量本身的开销之外, 还需要cas操作的开销, 比直接使用互斥量的开销还大
自旋锁与自适应自旋(适合多核CPU)
是什么???
重量级锁竞争的时候, 还可以使用自旋来进行优化, 如果当前线程自旋成功(即这时候持锁线程已经退出了同步块, 释放了锁), 这时当前线程就可以避免阻塞
线程阻塞之前做一个忙循环(自旋), 默认是10次循环, 可以使用参数-XX:PreBlockSpin来自行更改, 有前提, 要是多核cpu
下面是自旋重试成功的情况:
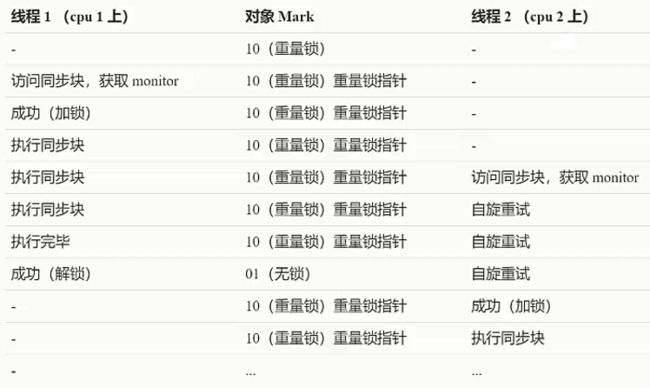
下面是自旋重试失败的情况:
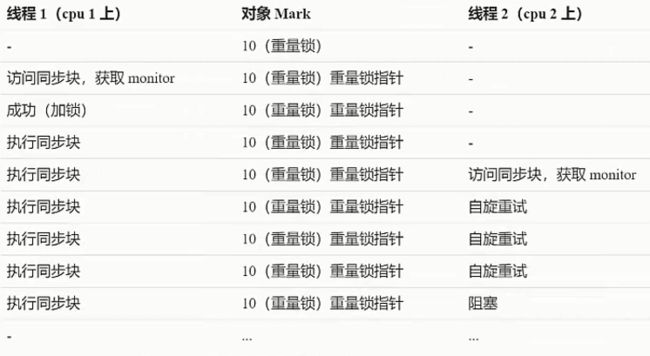
jdk6自动开启自旋锁, jdk7后不再默认开启
为什么要使用自旋锁?
线程的阻塞是需要挂起和恢复线程的, 两个操作需要转入内核态来完成, 所以效率比较低, 所以引入了一个忙循环的过程, 在这个过程中也许前面获得锁的线程已经结束释放了锁, 这时忙循环的线程就能够直接获得这个锁, 不需要转入内核态了
有什么优缺点?
优点
是减少了线程转入内核态所需要的时间
缺点
如果前一个获得锁的线程没有在十次循环的时间内结束, 则这个循环所需要的cpu资源却耗费了
如果使用的系统是单核系统, 不论如何自旋都是浪费时间的
什么是自适应自旋???
自适应代表了自旋的次数不再是固定的10次, 而是可变的
为什么使用自适应自旋???
自适应自旋是为了减少'不可能或者相对较少'进入自旋的锁, 用更多的时间放在经常成功进入自旋的锁上, 这样加快了性能
缺点:
自适应自旋锁的时间过高或者过低, 那么自适应自旋锁就无法适应到合适的范围了
锁消除
是什么?
锁消除就是消除那些根本不存在共享对象竞争却用到锁的代码块上的锁
什么时候使用锁消除?
通过逃逸分析判断来确认一段代码是否需要锁消除
逃逸分析: 一个对象在方法中产生, 如果被当作其他方法的参数, 这种叫方法逃逸, 如果被其他线程访问到, 则叫线程逃逸
有些时候程序员并没有主动调用到互斥同步方法, 它还是被动被调用了, 例如:
class Zhazha {
public String concatString(String s1, String s2, String s3) {
return s1 + s2 + s3;
}
}
上面这段代码在jdk1.5之前会被翻译成StringBuffer来完成字符串对象连接, 在jdk1.5之后会被优化为StringBuilder
class Zhazha {
public String concatString(String s1, String s2, String s3) {
StringBuffer sb = new StringBuffer();
sb.append(s1);
sb.append(s2);
sb.append(s3);
return sb.toString();
}
}
假设上面的方法就是jdk1.5之前的反汇编代码, 这个代码已经用到了同步互斥的功能了, 但是程序员看到的却是 s1 + s2 + s3 , 根本无法被判断, 但是逃逸分析分析出来了这里的代码并未发生逃逸现象, 这里的锁是 sb 对象, 但是 sb 是线程单独的对象(不是共享资源), 不会被多线程影响到, 还有 s1 s2 s3 都是不变对象, sb在连接字符串时sb的返回结果是不变的, 所以这也是一个可重入方法, 也是线程安全的(当然这一切都建立在 sb 不是共享资源的前提下, 如果sb是共享资源, 则这个方法是不安全的, append方法将被多次执行, 那就不是 s1 + s2+ s3这么简单了)
锁粗化
是什么? 为什么?
加锁的范围尽量小, 只在共享变量的修改操作范围上加锁就好, 但是如果锁的外面就是循环的话, 锁最好放在循环外面, 即使修改的只有循环内的共享资源, 这样便会减少锁过多的进行加锁释放阻塞恢复等操作, 如果虚拟机检测到一直出现对同一个对象进行多次加锁操作的代码块, 虚拟机便会把锁粗化到这些操作的范围上, 只需要一把锁就好, 这便是锁粗化
偏向锁
是什么???
轻量级锁在没有竞争时(就自己这个线程), 每次重入仍然需要执行cas操作
jdk6中引入了偏向锁来做进一步优化: 只有第一次使用cas将线程ID设置到对象的Mark Work头, 之后发现这个线程ID是自己的就表示没有竞争, 不用重新cas, 以后只要不发生竞争, 这个对象就归该线程所有
作比较:

细心的读者看到这里可能会发现一个问题:当对象进入偏向状态的时候,Mark Word大部分的空间(23个比特)都用于存储持有锁的线程ID了,这部分空间占用了原有存储对象哈希码的位置,那原来对象的哈希码怎么办呢?
在Java语言里面一个对象如果计算过哈希码,就应该一直保持该值不变(强烈推荐但不强制,因为用户可以重载hashCode()方法按自己的意愿返回哈希码),否则很多依赖对象哈希码的API都可能存在出错风险。而作为绝大多数对象哈希码来源的Object::hashCode()方法,返回的是对象的一致性哈希码(Identity Hash Code),这个值是能强制保证不变的,它通过在对象头中存储计算结果来保证第一次计算之后,再次调用该方法取到的哈希码值永远不会再发生改变。因此,当一个对象已经计算过一致性哈希码后,它就再也无法进入偏向锁状态了;而当一个对象当前正处于偏向锁状态,又收到需要计算其一致性哈希码请求时,它的偏向状态会被立即撤销,并且锁会膨胀为重量级锁。在重量级锁的实现中,对象头指向了重量级锁的位置,代表重量级锁的ObjectMonitor类里有字段可以记录非加锁状态(标志位为“01”)下的Mark Word,其中自然可以存储原来的哈希码
偏向状态
一个对象创建时:
- 如果开启了偏向锁(默认开启),那么对象创建后,markword值为0x05即最后3位为101,这时它的thread、epoch、 age 都为0
- 偏向锁是默认是延迟的,不会在程序启动时立即生效,如果想避免延迟,可以加VM参数-XX:BiasedLockingStartupDelay=e来禁用延迟
- 如果没有开启偏向锁,那么对象创建后,markword 值为0x01即最后3位为001,这时它的hashcode、age
都为0,第一次用到hashcode时才会赋值
测试禁用
在上面测试代码运行时在添加VM参数-XX:-UseBiasedLocking禁用偏向锁
OFFSET SIZE TYPE DESCRIPTION VALUE
0 4 (object header) 01 00 00 00 (00000001 00000000 00000000 00000000) (1)
4 4 (object header) 00 00 00 00 (00000000 00000000 00000000 00000000) (0)
8 4 (object header) 40 80 10 00 (01000000 10000000 00010000 00000000) (1081408)
12 4 (loss due to the next object alignment)
Instance size: 16 bytes
Space losses: 0 bytes internal + 4 bytes external = 4 bytes total
com.zhazha.sync.Dog object internals:
OFFSET SIZE TYPE DESCRIPTION VALUE
0 4 (object header) 30 e1 8f 52 (00110000 11100001 10001111 01010010) (1385161008)
4 4 (object header) 21 00 00 00 (00100001 00000000 00000000 00000000) (33)
8 4 (object header) 40 80 10 00 (01000000 10000000 00010000 00000000) (1081408)
12 4 (loss due to the next object alignment)
Instance size: 16 bytes
Space losses: 0 bytes internal + 4 bytes external = 4 bytes total
com.zhazha.sync.Dog object internals:
OFFSET SIZE TYPE DESCRIPTION VALUE
0 4 (object header) 01 00 00 00 (00000001 00000000 00000000 00000000) (1)
4 4 (object header) 00 00 00 00 (00000000 00000000 00000000 00000000) (0)
8 4 (object header) 40 80 10 00 (01000000 10000000 00010000 00000000) (1081408)
12 4 (loss due to the next object alignment)
Instance size: 16 bytes
Space losses: 0 bytes internal + 4 bytes external = 4 bytes total
为什么???
偏向锁就是在无竞争环境下, 消除同步使用互斥量, 把整个临界区的同步都消除掉, 甚至连cas都不需要
有什么优点和缺点???
偏向锁可以提高带有同步但无竞争的程序性能,但它同样是一个带有效益权衡(Trade Off)性质的优化,也就是说它并非总是对程序运行有利。如果程序中大多数的锁都总是被多个不同的线程访问,那偏向模式就是多余的。在具体问题具体分析的前提下,有时候使用参数-XX:-UseBiasedLocking来禁止偏向锁优化反而可以提升性能。
撤销 - 调用对象 hashCode
调用了对象的hashCode,但偏向锁的对象MarkWord中存储的是线程id,如果调用hashCode会导致偏向锁
被撤销
■轻量级锁会在锁记录中记录hashCode
■重量级锁会在Monitor中记录hashCode
在调用hashCode后使用偏向锁,记得去掉-XX: -UseBiasedLocking
撤销-其它线程使用对象
当有其它线程使用偏向锁对象时,会将偏向锁升级为轻量级锁
撤销-调用wait/notify
批量重偏向
如果对象虽然被多个线程访问,但没有竞争,这时偏向了线程T1的对象仍有机会重新偏向T2,重偏向会重置对象的Thread ID
当撤销偏向锁阈值超过20次后,jvm 会这样觉得,我是不是偏向错了呢,于是会在给这些对象加锁时重新偏向至加锁线程
@Slf4j(topic = "c.TestBiased")
public class TestBiased {
static Thread t1,t2,t3;
public static void main(String[] args) throws InterruptedException {
test4();
}
private static void test4() throws InterruptedException {
Vector list = new Vector<>();
int loopNumber = 38;
t1 = new Thread(() -> {
for (int i = 0; i < loopNumber; i++) {
Dog d = new Dog();
list.add(d);
synchronized (d) {
log.debug(i + "\t" + ClassLayout.parseInstance(d).toPrintableSimple(true));
}
}
LockSupport.unpark(t2);
}, "t1");
t1.start();
t2 = new Thread(() -> {
LockSupport.park();
log.debug("===============> ");
for (int i = 0; i < loopNumber; i++) {
Dog d = list.get(i);
log.debug(i + "\t" + ClassLayout.parseInstance(d).toPrintableSimple(true));
synchronized (d) {
log.debug(i + "\t" + ClassLayout.parseInstance(d).toPrintableSimple(true));
}
log.debug(i + "\t" + ClassLayout.parseInstance(d).toPrintableSimple(true));
}
LockSupport.unpark(t3);
}, "t2");
t2.start();
t3 = new Thread(() -> {
LockSupport.park();
log.debug("===============> ");
for (int i = 0; i < loopNumber; i++) {
Dog d = list.get(i);
log.debug(i + "\t" + ClassLayout.parseInstance(d).toPrintableSimple(true));
synchronized (d) {
log.debug(i + "\t" + ClassLayout.parseInstance(d).toPrintableSimple(true));
}
log.debug(i + "\t" + ClassLayout.parseInstance(d).toPrintableSimple(true));
}
}, "t3");
t3.start();
t3.join();
log.debug(ClassLayout.parseInstance(new Dog()).toPrintableSimple(true));
}
}
class Dog {}
如果切换过多(可能是39次), jvm可能会觉得这个临界区不适合使用偏向锁, 转而膨胀成轻量级锁
wait/notify
小故事-为什么需要wait
●由于条件不满足,小南不能继续进行计算
●但小南如果一直占用着锁,其它人就得一直阻塞,效率太低
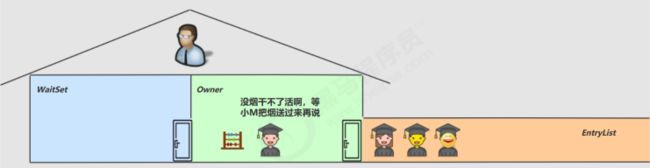
●于是老王单开了一间休息室(调用wait方法) ,让小南到休息室( WaitSet )等着去了,但这时锁释放开,
其它人可以由老王随机安排进屋
●直到小M将烟送来,大叫--声你的烟到了(调用notify方法)
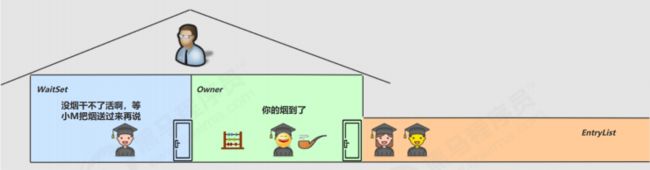
●小南于是可以离开休息室,重新进入竞争锁的
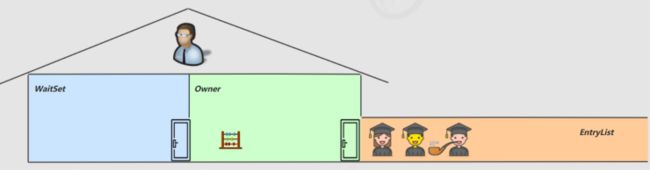
●此时小南要和其他线程重新抢夺进门的权限了(时间片)
wait和notify底层实现
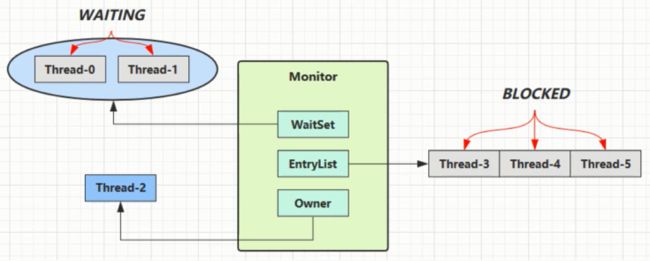
■Owner 线程发现条件不满足,调用wait方法,即可进入WaitSet变为WAITING状态
■BLOCKED和WAITING的线程都处于阻塞状态,不占用CPU时间片
■BLOCKED线程会在Owner线程释放锁时唤醒
■WAITING 线程会在Owner线程调用notify或notifyAll时唤醒,但唤醒后并不意味者立刻获得锁,仍需进入EntryList重新竞争
API介绍
■obj.wait() 让进入 object 监视器的线程到 waitSet 等待
■obj.notify() 在 object 上正在 waitSet 等待的线程中挑一个唤醒
■obj.notifyAll() 让 object 上正在 waitSet 等待的线程全部唤醒
它们都是线程之间进行协作的手段,都属于 Object 对象的方法。必须获得此对象的锁,才能调用这几个方法
class Zhazha {
final static Object obj = new Object();
public static void main(String[] args) {
new Thread(() -> {
synchronized (obj) {
log.debug("执行....");
try {
obj.wait(); // 让线程在obj上一直等待下去
} catch (InterruptedException e) {
e.printStackTrace();
}
log.debug("其它代码....");
}
}).start();
new Thread(() -> {
synchronized (obj) {
log.debug("执行....");
try {
obj.wait(); // 让线程在obj上一直等待下去
} catch (InterruptedException e) {
e.printStackTrace();
}
log.debug("其它代码....");
}
}).start();
// 主线程两秒后执行
sleep(2);
log.debug("唤醒 obj 上其它线程");
synchronized (obj) {
obj.notify(); // 唤醒obj上一个线程
// obj.notifyAll(); // 唤醒obj上所有等待线程
}
}
}
wait() 方法会释放对象的锁,进入 WaitSet 等待区,从而让其他线程就机会获取对象的锁。无限制等待,直到notify 为止
wait(long n) 有时限的等待, 到 n 毫秒后结束等待,或是被 notify
虚假唤醒
obj.notify(); // 随机唤醒obj上一个线程
// obj.notifyAll(); // 唤醒obj上所有等待线程
上面的情况需要考虑到虚假唤醒的情况, 不管是上面的notify唤醒还是下面的notifyAll唤醒, 都存在错误唤醒的问题, 比如: notify随机唤醒了相同锁上面的另一个锁, 虽然这个锁被唤醒了, 但是不是notify想要唤醒的那个线程, 所以它被虚假唤醒了
再比如: 使用notifyAll, 全部线程都被唤醒了, 这样子不需要唤醒的线程也被唤醒了, 这里也存在虚假唤醒
wait notify 的正确姿势
sleep(long n) 和 wait(long n) 的区别
- sleep是Thread方法,而wait是Object的方法
- sleep不需要强制和synchronized配合使用,但wait需要和synchronized 一起用
- sleep在睡眠的同时,不会释放对象锁的,但wait在等待的时候会释放对象锁。
- 它们状态TIMED_ WAITING
模式之保护性暂停
同步模式之保护性暂停
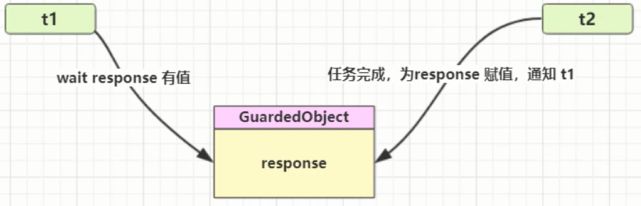
是什么?
即Guarded Suspension,用在一个线程等待另一个线程的执行结果
要点
■有一个结果需要从一个线程传递到另一个线程, 让他们关联同一个GuardedObject
■如果有结果不断从一个线程到另一个线程那么可以使用消息队列(见生产者消费者)
■JDK中,join的实现、Future的实现,采用的就是此模式
■因为要等待另一方的结果, 因此归类到同步模式
@Slf4j
public class GuardedObjectDemo {
@Test
public void test() throws Exception {
CountDownLatch latch = new CountDownLatch(2);
GuardedObject guardedObject = new GuardedObject();
new Thread(() -> {
try {
log.debug("等待结果...");
Optional> optional = Optional.ofNullable((List) guardedObject.getWaitTime(10000));
List list = optional.orElse(new ArrayList<>());
log.debug("结果大小: {}", list.size());
latch.countDown();
} catch (InterruptedException e) {
e.printStackTrace();
}
}, "t1").start();
new Thread(() -> {
log.debug("开始下载... ");
try {
List list = Downloader.download();
guardedObject.complete(list);
} catch (IOException e) {
e.printStackTrace();
}
latch.countDown();
}, "t2").start();
latch.await();
}
class GuardedObject {
// 结果
private Object response;
/**
* 获取结果
*
* @return
*
* @throws InterruptedException
*/
public Object get() throws InterruptedException {
synchronized (this) {
while (null == response) {
this.wait();
}
}
return response;
}
/**
* 获取结果, 设置最长超时时间
*
* @param timeOutTime
* 最长超时时间
*
* @return
*
* @throws InterruptedException
*/
public Object getWaitTime(long timeOutTime) throws InterruptedException {
synchronized (this) {
LocalDateTime start = LocalDateTime.now();
long passTime;
long waitTime = 0;
while (response == null) {
passTime = timeOutTime - waitTime;
if (passTime <= 0) {
break;
}
this.wait(passTime);
Duration duration = Duration.between(start, LocalDateTime.now());
waitTime = duration.toMillis();
}
}
return response;
}
/**
* 产生结果
*
* @param response
*/
public void complete(Object response) {
synchronized (this) {
this.response = response;
this.notifyAll();
}
}
}
}
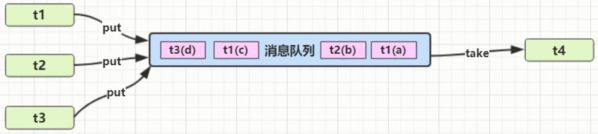
异步模式之生产者和消费者
要点
■与前面的保护性暂停中的GuardObject不同,不需要产生结果和消费结果的线程一- 对应
■消费队列可以用来平衡生产和消费的线程资源
■生产者仅负责产生结果数据,不关心数据该如何处理,而消费者专心处理结果数据
■消息队列是有容量限制的,满时不会再加入数据,空时不会再消耗数据
■JDK中各种阻塞队列,采用的就是这种模式
@Slf4j
public class MessageQueueDemo {
public static void main(String[] args) {
MessageQueue queue = new MessageQueue(2);
for (int i = 0; i < 3; i++) {
int tmp = i;
new Thread(() -> queue.put(new Message(tmp, "message " + tmp)), "生成者" + i).start();
}
new Thread(() -> {
while (true) {
try {
TimeUnit.SECONDS.sleep(1);
} catch (InterruptedException e) {
e.printStackTrace();
}
queue.task();
}
}, "消费者").start();
}
}
@Slf4j(topic = "c.MessageQueue")
class MessageQueue {
private final LinkedList messageList = new LinkedList<>();
private Integer capcity;
public MessageQueue(Integer capcity) {
this.capcity = capcity;
}
/**
* 获取消息
*
* @return
*/
public Message task() {
synchronized (messageList) {
Message message;
try {
while (messageList.isEmpty()) {
try {
log.debug("队列为空, 消费者线程等待");
messageList.wait();
} catch (InterruptedException e) {
e.printStackTrace();
}
}
message = messageList.removeFirst();
log.debug("消费了消息message = {}", message);
} finally {
messageList.notifyAll();
}
return message;
}
}
/**
* 存入消息
*
* @param message
*/
public void put(Message message) {
synchronized (messageList) {
try {
while (capcity == messageList.size()) {
try {
log.debug("消息队列满了, 线程等待消息被消费后再次存入消息");
messageList.wait();
} catch (InterruptedException e) {
e.printStackTrace();
}
}
messageList.add(message);
log.debug("生产了消息 message = {}", message);
} finally {
messageList.notifyAll();
}
}
}
}
@Slf4j(topic = "c.Message")
class Message {
private Integer id;
private String message;
@Override
public String toString() {
return "Message{" + "id=" + id + ", message='" + message + '\'' + '}';
}
public Integer getId() {
return id;
}
public void setId(Integer id) {
this.id = id;
}
public String getMessage() {
return message;
}
public void setMessage(String message) {
this.message = message;
}
public Message(Integer id, String message) {
this.id = id;
this.message = message;
}
}
Park && Unpark
它们是LockSupport类中的方法
class Zhazha {
public static void main(String[] args) throws InterruptedException {
Thread t1 = new Thread(() -> {
log.debug("线程{}运行了, 并且即将调用park", Thread.currentThread().getName());
LockSupport.park();
log.debug("线程{} unpark成功", Thread.currentThread().getName());
}, "t1");
t1.start();
TimeUnit.SECONDS.sleep(1);
LockSupport.unpark(t1);
log.debug("解锁了");
}
}
特点
与Object的wait & notify相比
■wait, notify 和notifyAll必须配合Object Monitdr一起使用,而unpark不必
■park & unpark是以线程为单位来阻塞和唤醒线程,而notify只能随机唤醒一个等待线程,notifyAll是唤醒所有等待线程,就不那么精确
■park & unpark可以先unpark,而wait & notify不能先notify
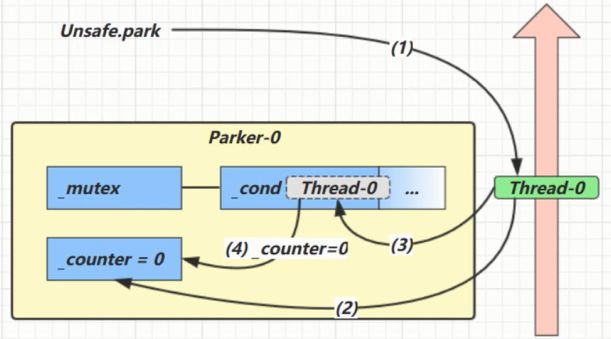
park/unpark原理
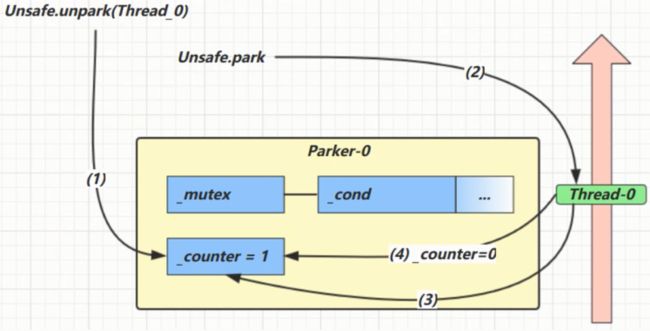
每个线程都有自己的一个Parker对象,由三部分组成 _counter, _cond 和 _mutex 打个比喻
■线程就像一个旅人,Parker 就像他随身携带的背包,条件变量就好比背包中的帐篷。_counter 就好比背包中的备用干粮(0 为耗尽,1 为充足)
■调用park就是要看需不需要停下来歇息
■如果备用干粮耗尽,那么钻进帐篷歇息
■如果备用干粮充足,那么不需停留,继续前进
■调用unpark, 就好比令干粮充足
■如果这时线程还在帐篷,就唤醒让他继续前进
■如果这时线程还在运行,那么下次他调用park时,仅是消耗掉备用干粮,不需停留继续前进
■因为背包空间有限,多次调用unpark仅会补充一 份备用干粮

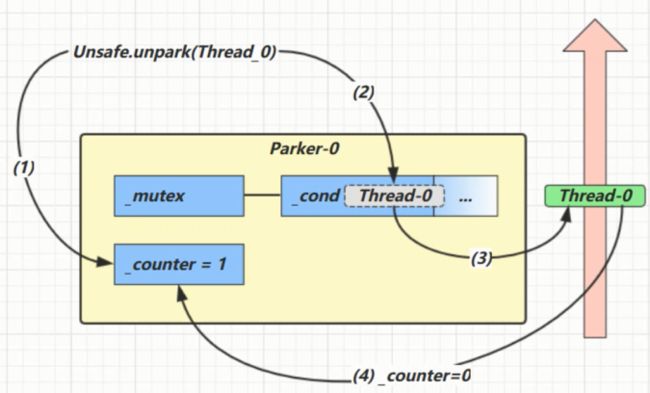

如果先调用unpark再调用park呢?

死锁、活锁、饥饿锁和公平锁等
死锁
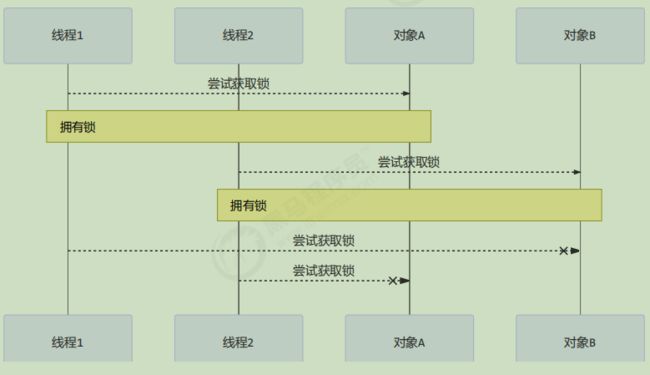
有这样的情况:一个线程需要同时获取多把锁,这时就容易发生死锁
t1 线程 获得 A 对象锁,接下来想获取 B 对象的锁 t2 线程 获得 B 对象锁,接下来想获取 A 对象的锁
例如:
@Slf4j
public class DeadLockDemo {
private static final Object lock1 = new Object();
private static final Object lock2 = new Object();
public static void main(String[] args) {
new Thread(() -> {
// 先 lock1 后 lock2
synchronized (lock1) {
log.debug("{}上锁lock1", Thread.currentThread().getName());
synchronized (lock2) {
log.debug("{}上锁lock2", Thread.currentThread().getName());
}
}
}, "t1").start();
new Thread(() -> {
// 先 lock2 后 lock1 和上面的加锁方向相反, 很容易发生死锁问题
synchronized (lock2) {
log.debug("{}上锁lock2", Thread.currentThread().getName());
synchronized (lock1) {
log.debug("{}上锁lock1", Thread.currentThread().getName());
}
}
}, "t2").start();
}
}
定位死锁
(1) 检测死锁可以使用 jconsole工具,或者使用 jps 定位进程 id,再用 jstack 定位死锁
(2) 还可以使用jvisualvm检测死锁
哲学家就餐问题
有五位哲学家,围坐在圆桌旁。
- 他们只做两件事,思考和吃饭,思考一会吃口饭,吃完饭后接着思考。
- 吃饭时要用两根筷子吃,桌上共有 5 根筷子,每位哲学家左右手边各有一根筷子。
- 如果筷子被身边的人拿着,自己就得等待
@Slf4j
public class PhilosopherDemo {
public static void main(String[] args) {
Chopstick c1 = new Chopstick("筷子①");
Chopstick c2 = new Chopstick("筷子②");
Chopstick c3 = new Chopstick("筷子③");
Chopstick c4 = new Chopstick("筷子④");
Chopstick c5 = new Chopstick("筷子⑤");
new Philosopher("苏格拉底", c1, c2).start();
new Philosopher("柏拉图", c2, c3).start();
new Philosopher("亚里士多德", c3, c4).start();
new Philosopher("赫拉克利特", c4, c5).start();
new Philosopher("阿基米德", c5, c1).start();
}
}
/**
* 哲学家
*/
@Slf4j(topic = "c.Philosopher")
@EqualsAndHashCode(callSuper = false)
@Data
@NoArgsConstructor
class Philosopher extends Thread {
// 左手筷子
private Chopstick left;
// 右手筷子
private Chopstick right;
Philosopher(String name, Chopstick left, Chopstick right) {
super(name);
this.left = left;
this.right = right;
}
private void eat() {
log.debug("eating");
try {
TimeUnit.SECONDS.sleep(1);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
@Override
public void run() {
while (true) {
synchronized (left) {
synchronized (right) {
eat();
}
}
}
}
}
/**
* 筷子类
*/
@Data
@NoArgsConstructor
@AllArgsConstructor
class Chopstick {
private String name;
@Override
public String toString() {
return "筷子{" + name + '}';
}
}
活锁
活锁就是两个线程相互谦让拿到了cpu时间片但是又把执行权限丢给对方, 一直互相谦让就成活锁了
还有一种情况就是出现在两个线程互相改变对方的结束条件,最后谁也无法结束
说白了, 对 i ++和对 i -- 线程无限停留都不满足自己的条件, 无限循环
饥饿
很多教程中把饥饿定义为,一个线程由于优先级太低,始终得不到 CPU 调度执行,也不能够结束,饥饿的情况不易演示,讲读写锁时会涉及饥饿问题
下面我讲一下我遇到的一个线程饥饿的例子,先来看看使用顺序加锁的方式解决之前的死锁问题
顺序加锁的解决方案
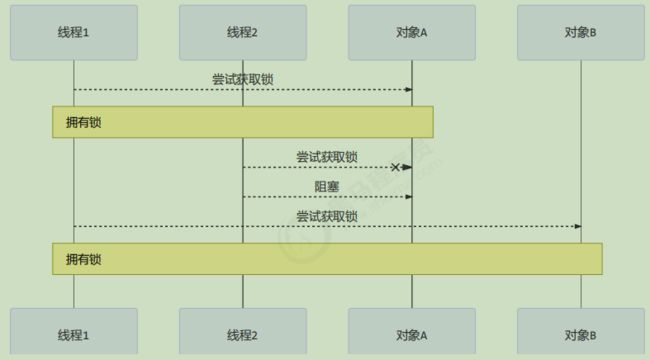
但是这种方式却导致了饥饿问题
// 这种方式是饥饿
// new Philosopher("阿基米德", c1, c5).start();
可打断
可打断锁
@Slf4j
public class LockInterruptorDemo {
public static final ReentrantLock lock = new ReentrantLock();
public static void main(String[] args) {
Thread t1 = new Thread(() -> {
log.debug("上锁了{}", Thread.currentThread().getName());
try {
lock.lockInterruptibly();
} catch (InterruptedException e) {
e.printStackTrace();
log.debug("等待锁过程中被打断...");
return;
}
try {
log.debug("上锁成功{}", Thread.currentThread().getName());
} finally {
lock.unlock();
}
}, "t1");
lock.lock();
log.debug("主线程上锁了");
t1.start();
t1.interrupt();
log.debug("主线程释放了 {} 线程", t1.getName());
}
}
锁超时
饥饿状态可以使用锁超时方式解决
立刻超时
@Slf4j
public class TryLockDemo {
public static void main(String[] args) {
ReentrantLock lock = new ReentrantLock();
Thread t1 = new Thread(() -> {
log.debug("子线程尝试上锁");
if (!lock.tryLock()) {
log.debug("获得锁失败");
return;
}
try {
log.debug("获得锁成功");
} finally {
lock.unlock();
}
}, "t1");
lock.lock();
log.debug("主线程上锁了");
t1.start();
}
}
公平锁
ReentrantLock 默认是不公平的
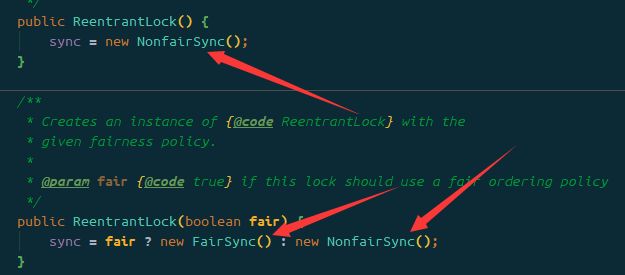
公平锁一般没有必要,会降低并发度,后面分析原理时会讲解
条件变量
synchronized 中也有条件变量,就是我们讲原理时那个 waitSet 休息室,当条件不满足时进入 waitSet 等待
ReentrantLock 的条件变量比 synchronized 强大之处在于,它是支持多个条件变量的,这就好比
- synchronized 是那些不满足条件的线程都在一间休息室等消息
- 而 ReentrantLock 支持多间休息室,有专门等烟的休息室、专门等早餐的休息室、唤醒时也是按休息室来唤
醒
使用要点:
- await 前需要获得锁
- await 执行后,会释放锁,进入 conditionObject 等待
- await 的线程被唤醒(或打断、或超时)取重新竞争 lock 锁
- 竞争 lock 锁成功后,从 await 后继续执行
@Slf4j(topic = "c.CorrectPostureDemo")
public class CorrectPostureDemo {
private static final ReentrantLock ROOM = new ReentrantLock();
private static Condition waitCigarette = ROOM.newCondition();
private static Condition waitTakeout = ROOM.newCondition();
// 是否抽烟
private static Boolean hasCigarette = false;
// 是否点外卖
private static Boolean hasTakeout = false;
public static void main(String[] args) {
new Thread(() -> {
ROOM.lock();
try {
log.debug("外卖到了没?[{}]", hasTakeout);
while (!hasTakeout) {
try {
log.debug("没到, 先休息会儿");
waitTakeout.await();
} catch (InterruptedException e) {
e.printStackTrace();
}
}
log.debug("外卖到了, 可以工作了");
} finally {
ROOM.unlock();
}
}, "小女").start();
new Thread(() -> {
ROOM.lock();
try {
log.debug("有烟没??[{}]", hasCigarette);
while (!hasCigarette) {
log.debug("没烟, 先休息会儿");
try {
waitCigarette.await();
} catch (InterruptedException e) {
e.printStackTrace();
}
}
log.debug("有烟, 可以干活了");
} finally {
ROOM.unlock();
}
}, "小南").start();
Sleeper.sleep(1);
new Thread(() -> {
ROOM.lock();
try {
hasTakeout = true;
log.debug("{} 外卖送到了[{}]", Thread.currentThread().getName(), hasTakeout);
waitTakeout.signal();
} finally {
ROOM.unlock();
}
}, "外卖小哥1").start();
new Thread(() -> {
ROOM.lock();
try {
hasCigarette = true;
log.debug("{} 烟送到了[{}]", Thread.currentThread().getName(), hasCigarette);
waitCigarette.signal();
} finally {
ROOM.unlock();
}
}, "外卖小哥2").start();
}
}
顺序控制
面试中经常会有的问题
@Slf4j
public class LockOrderControlDemo {
private final static ReentrantLock lock = new ReentrantLock();
private final static Condition cond = lock.newCondition();
private volatile static int flag = 0;
public static void main(String[] args) {
Thread a = new Thread(() -> {
while (true) {
try {
lock.lock();
if (0 == flag) {
System.err.print(Thread.currentThread().getName() + " -> ");
flag = 1;
cond.signalAll();
}
cond.await();
} catch (InterruptedException e) {
e.printStackTrace();
} finally {
lock.unlock();
}
}
}, "A");
Thread b = new Thread(() -> {
while (true) {
try {
lock.lock();
if (1 == flag) {
System.err.print(Thread.currentThread().getName() + " -> ");
flag = 2;
cond.signalAll();
}
cond.await();
} catch (InterruptedException e) {
e.printStackTrace();
} finally {
lock.unlock();
}
}
}, "B");
Thread c = new Thread(() -> {
while (true) {
try {
lock.lock();
if (2 == flag) {
System.err.print(Thread.currentThread().getName() + " -> ");
flag = 3;
cond.signalAll();
}
cond.await();
} catch (InterruptedException e) {
e.printStackTrace();
} finally {
lock.unlock();
}
}
}, "C");
Thread d = new Thread(() -> {
while (true) {
try {
lock.lock();
if (3 == flag) {
System.err.println(Thread.currentThread().getName());
flag = 0;
cond.signalAll();
}
cond.await();
} catch (InterruptedException e) {
e.printStackTrace();
} finally {
lock.unlock();
}
}
}, "D");
a.start();
b.start();
c.start();
d.start();
}
}