Adaboost应用系列之一:Opencv2.0中利用Adaboost训练Haar特征产生xml分类器
网上很多如题的内容,我结合自己的亲身使用整理归纳了一下,供大家参考:
1.采集样本
(1)正样本就是图片中只有你需要的目标,而负样本的图片只要其中不含有目标就可以了。使用批量截图工具(光影魔术手,美图看看之类的)或者人工截图采集正负样本,但是正样本图片最好是裁剪成同一尺寸或者高宽比大致相同;
(2)其次是训练样本要和最终的应用场合非常接近或者一致。否则,基于机器学习的算法并不能保证算法的有效性。举个例子,要检测的目标是汽车,那么正样本就应该是仅仅含有汽车的图片,而负样本应该尽量是包含摩托车、三轮车、自行车、行人、路面、灌木丛、花草、交通标志、广告牌等的图片;
(3)最后,训练样本要足够多,上千张是最低保证,而且负样本要稍微比正样本多(正负样本比例1:2.5至1:3左右),可以降低false positive。
2.预处理样本
(1)对所有的正样本进行尺寸归一化(可以编程实现或使用批量处理工具),负样本不需要,但是负样本图像尺寸应该比训练窗口(这里是30*30)的尺寸大,因为这些图像将被用于抠取负样本,并将负样本缩小到训练窗口大小。
(2)我这里是统一正样本尺寸等于训练窗口尺寸(30*30),样本尺寸大小会影响到后面的训练速度,建议不要太大。
(3)无论正样本负样本,图片命名时不要用特殊字符,建议简单化用数字名字。将正负样本分别放在两个不同的文件夹下面,分别取名pos和neg,其中pos用来存放正样本图像,neg用来存放负样本。

3.生成正负样本描述文件
(1)正样本描述文件的格式是:文件名 目标个数 目标在图片中的位置(x,y,width,height)。例如每个正样本图片只包含一个目标,图片尺寸为30*30,则格式如下:
0.bmp 1 0 0 30 30
1.bmp 1 0 0 30 30
2.bmp 1 0 0 30 30
…………
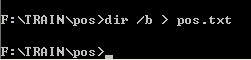
(2)生成正样本描述文件:在cmd下进入pos文件夹目录里,输入 dir /b > pos.txt:
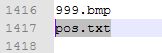
再用notepad++之类的编辑软件打开它,删除最后一行的pos.txt:
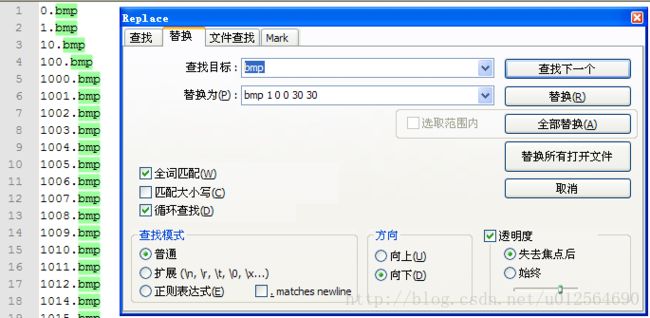
再使用查找替换的办法(编程实现当然更高端)将pos.txt的每行转化为(1)所说的描述文件的格式:
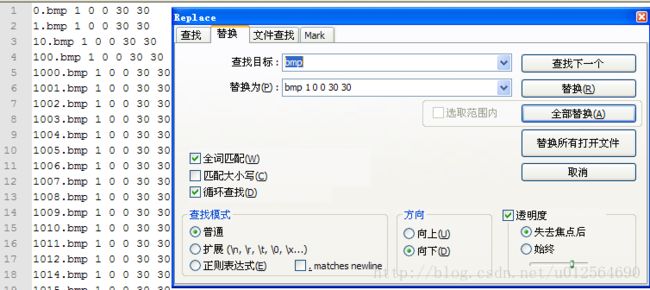
最后的结果如下:
(3)生成负样本描述文件:在cmd下进入neg文件夹目录里,输入 dir /b > neg.txt:
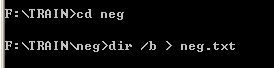
再用notepad++之类的编辑软件打开它,删除最后一行的neg.txt即可,不用更改格式:
4.创建正样本vec文件
(1)HaarTraining训练的需要输入的正样本是vec文件,所以这里使用opencv自带的opencv_createsamples程序(opencv安装路径下面的bin文件夹)来将正样本转换为vec文件。如图将程序拷贝到neg和pos同一目录:

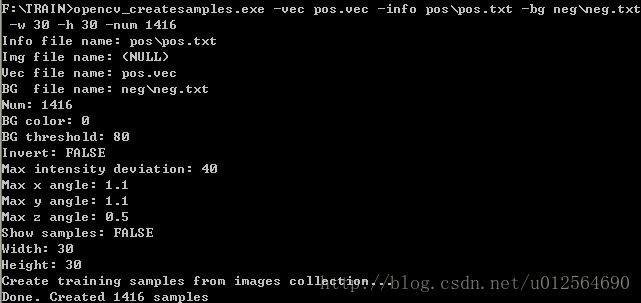
(2)在CMD下输入如下命令:
opencv_createsamples.exe -vec pos.vec -info pos\pos.txt -bg neg\neg.txt -w 30 -h 30 -num 1416
以上参数的含义如下:
-vec
-img
-bg
-num
-bgcolor
-bgthresh
-inv:如果指定,颜色会反色
-randinv:如果指定,颜色会任意反色
-maxidev
-maxangel
-maxangle
-maxzangle
-show:如果指定,每个样本会被显示出来,按下"esc"会关闭这一开关,即不显示样本图片,而创建过程
继续。这是个有用的debug 选项。
-w
-h
(3)执行之后就会在当前目录产生一个pos.vec的文件:
得到的vec文件: ,负样本不需要创建vec文件。
,负样本不需要创建vec文件。
5.训练样本
(1)可以使用opencv自带的opencv_haartraining.exe来训练,也可以使用opencv_traincascade.exe进行训练。他们的不同之处在于后者是前者的新版本;而且前者只针对Haar特征,而后者除了训练Haar之外可以训练别的特征,如HOG、LBP等。我这里使用opencv_haartraining.exe为例子。
(2)将程序拷贝至当前目录,并新建一个classifier目录用于存放训练好的分类器:

(3)在CMD下输入如下命令:
opencv_haartraining.exe -data classifier -vec pos.vec -bg neg\neg.txt -w 30 -h 30 -mem 500 -mode all
程序的命令行参数如下:
-data
-vec
-bg
-npos
-nneg
-nstages
-nsplits
-mem
-sym(default),
-nonsym:指定训练的目标对象是否垂直对称。垂直对称提高目标的训练速度,例如正面部是垂直对称的;
-minhitrate
-maxfalsealarm
-weighttrimming
-eqw
-mode
-w
-h
(4)开始训练,样本数目如果多的话时间挺长的:
![]()
训练完成的提示如下:
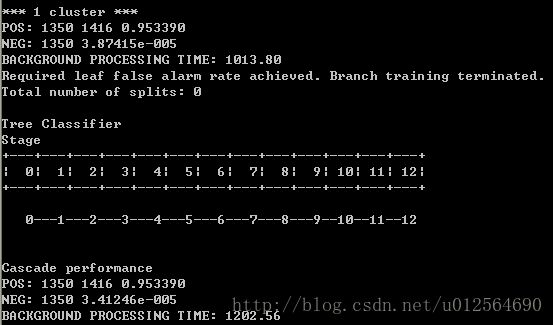
训练完成后classifier目录下生成中间数据(意义在于当训练程序被中断后,再重新运行训练程序将读入之前的训练结果,而不需从头重新训练。训练结束后,你可以删除这些中间文件),并同时生成classifier.xml分类器文件。

6.测试与使用
(1)测试:opencv_performance.exe可以测试得到的分类器性能,但只能评估 opencv_haartraining 输出的分类器。它读入一组标注好的图像,运行分类器并报告性能,如检测到物体的数目,漏检的数目,误检的数目,以及其他信息。
(2)使用:得到分类器后可以在程序中加载xml文件并使用对应接口来测试效果。
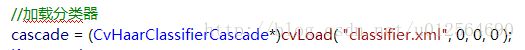

参考:
http://www.opencv.org.cn/opencvdoc/2.3.2/html/doc/user_guide/ug_traincascade.html
http://hi.baidu.com/ccb163163/item/22ba182edcc6fac00e37f9dd
http://blog.csdn.net/xidianzhimeng/article/details/10470839
http://blog.csdn.net/chlele0105/article/details/12043151
http://blog.csdn.net/carson2005/article/details/8171571
http://jingyan.baidu.com/article/4dc40848f50689c8d946f197.html
http://www.xuebuyuan.com/501993.html