人工智能之知识图谱概述(一)
文章目录
- 碎碎念
- 第一章 概念
- 一、知识图谱概念和分类
- 1、知识图谱的概念
- 2、知识图谱的分类
- 二、知识工程发展历程
- 三、知识图谱的知识图谱
- 第二章 技术人才篇
- 1、知识表示与建模
- (1)知识表示模型
- (2)知识表示学习
- (3)知识表示与建模人才介绍
- 2、知识获取
- (1)实体识别与链接
- ① 传统统计模型方法
- ② 深度学习方法
- ③ 文本挖掘方法
- (2)实体关系学习
- ① 限定域关系抽取 vs. 开放域关系抽取
- ② 基于规则的关系抽取 vs. 基于机器学习的关系抽取
- (3)事件知识学习
- ① 事件识别和抽取
- ② 事件检测和追踪
- ③ 事件知识库构建(起步阶段)
- (4)知识获取人才介绍
- 3、知识融合
- (1)本体匹配
- (2)实例匹配
- (3)知识融合人才介绍
- 4、知识图谱查询和推理计算
- (1)知识推理
- ① 基于符号的并行知识推理
- ② 链接预测
- ③ 模式归纳方法
- (2)知识存储和查询
- ① 基于关系数据模型的 RDF 数据存储和查询
- ② 基于图模型的 RDF 数据存储和查询
- (3) 知识查询与推理人才介绍
- 5、知识应用
- (1)典型应用
- ① 语义搜索
- ② 智能问答
- ③ 可视化决策支持
- (2)通用和领域知识图谱
- (3)知识应用人才介绍
- 6、高引论文(Top10)
- 第三章 应用篇
- 1、通用知识图谱应用
- 2、领域知识图谱应用
- 第四章 趋势篇
碎碎念
工作中心已经转移到现在的知识图谱,最近找到了一个很新的综述报告,资源如下,先对知识图谱进行整体把握,再逐步对各个关键技术进行学习。
传送门:
- 网站地址:2019年第二期《人工智能之知识图谱》
- 文件网盘地址:链接,提取码:putq
第一章 概念
一、知识图谱概念和分类
1、知识图谱的概念
知识工程(费根鲍姆,1994):将知识集成到计算机系统从而完成只有特定领域专家才能完成的复杂任务。
知识图谱(Knowledge Graph) 以结构化的形式描述客观世界中概念、实体及其之间的关系,已经成为互联网知识驱动的智能应用的 基础设施。
几个概念:
- 实体:指的是具有可区别性且独立存在的某种事物。实体是知识图谱中的最基本元素,不同的实体间存在不同的关系。eg:某一个人、某一座城市、某一种植物、某一件商品等
- 概念:具有同种特性的实体构成的集合,如国家、民族、书籍、电脑等。
- 属性:用于区分概念的特征,不同概念具有不同的属性。
- 对象属性:属性值对应的是概念或实体;
- 数据属性:属性值是具体的数值;
知识图谱作用:利用知识工程为大数据添加语义/知识,使数据产生智慧(Smart Data),完成从数据到信息到知识,最终到智能应用的转变过程,从而实现对大数据的洞察、提供用户关心问题的答案、为决策提供支持、改进用户体验等目标。
知识图谱主要应用:知识融合、语义搜索和推荐、问答和对话系统、大数据分析与决策。
2、知识图谱的分类
按领域方面分类:
- 通用知识图谱:面向通用领域的“结构化的百科
知识库”。 - 特定领域知识图谱(行业知识图谱,垂直知识图谱):面向某一特定领域,可看成是一个“基于语义技术的行业知识库”
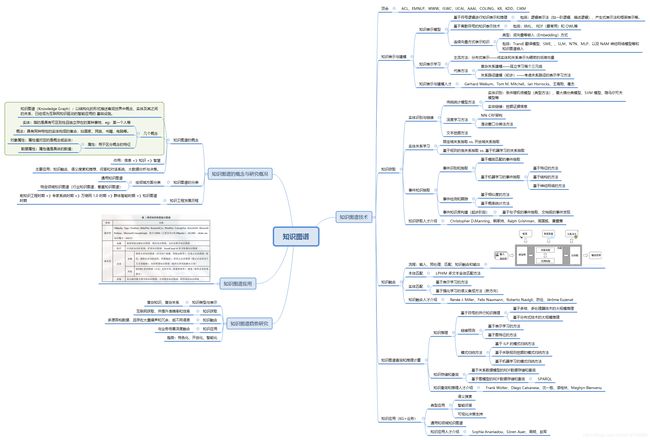
二、知识工程发展历程
知识工程发展历程 的 五个标志性阶段:前知识工程时期、专家系统时期、万维网 1.0 时期,群体智能时期以及知识图谱时期
- 图灵测试—知识工程诞生前期(1950-1970 时期)
- 主要方法:符号主义 和 连接主义
- 代表工作:通用问题求解程序(GPS):将问题进行形式化表达,通过搜索,从问题初始状态,结合规则或表示得到目标状态。
- 典型应用:博弈论和机器定理证明等
- 知识表示方法:逻辑知识表示、产生式规则、语义网络等。
- 先驱:Minsky, Mccarthy 和 Newell 以 Simon 四位学者因为他们在感知机、人工智能语言和通用问题求解和形式化语言方面
- 专家系统—知识工程蓬勃发展期(1970-1990 时期)
- 主要方法:“知识库 + 推理机”实现的限定领域专家系统
- 典型系统:MYCIN、DENRAL 、XCON等
- 知识表示方法:框架、脚本等
- 万维网(1990-2000 时期)
- 主要方法:基于万维网,使用HTML、XML语言
- 典型知识库:WordNet、Cyc、HowNet等
- 知识表示方法:本体
- 群体智能(2000-2006 时期)
- 主要方法:Web,旨在对互联网内容进行结构化语义表示, 利用本体描述互联网内容的语义结构,通过对网页进行语义标识得到网页语义信息,从而获得网页内容的语义信息, 使人和机器能够更好地协同工作。
- 知识表示方法:RDF(资源描述框架)和 OWL(万维网本体表述语言)
- 典型应用:维基百科,用户去建立知识
- 知识图谱—知识工程新发展时期(2006 年至今)
- 主要方法:知识获取是自动化的,并且在网络规模下运行。
- 典型KG:基于RDF数据模型的DBpedia、Freebase、KnowItAll、WikiTaxonomy和 YAGO,以及BabelNet、ConceptNet、DeepDive、 NELL、 Probase、 Wikidata、 XLORE、 Zhishi.me、 CNDBpedia 等;
- 应用:语义搜索、问答系统与聊天、大数据语义分析以及智能知识服务等
三、知识图谱的知识图谱
热门领域:知识表示(knowledge representation)、知识获取(knowledge acquisition)、知识推理(knowledge reasoning)、知识集成(knowledge integration)和知识存储(knowledge storage) 等。
第二章 技术人才篇
知识图谱技术(五个方面):知识表示与建模、知识获取、知识融合、知识图谱查询和推理计算及知识应用技术 。
知识图谱领域顶级学术会议列表
| 会议简称 | 会议全称 |
|---|---|
| ACL | Association of Computational Linguistics |
| EMNLP | Empirical Methods in Natural Language Processing |
| WWW | International World Wide Web Conference |
| ISWC | International Semantic Web Conference |
| IJCAI | International Joint Conference on Artificial Intelligence |
| AAAI | National Conference of the American Association for Artificial Intelligence |
| COLING | International Conference on Computational Linguistics |
| KR | International Conference on Principles of KR & Reasoning |
| KDD | ACM International Conference on Knowledge Discovery and Data Mining |
| CIKM | ACM International Conference on Information and Knowledge Management |
1、知识表示与建模
人类心智区别于其它物种心智的重要特征:具有获取、表示和处理知识的能力。
(1)知识表示模型
关键点:机器必须要掌握大量的知识,特别是常识知识才能实现真正类人的智能。
技术发展三阶段:
- 基于符号逻辑进行知识表示和推理
- 包括:逻辑表示法(如一阶逻辑、描述逻辑)、产生式表示法和框架表示等。
- 基于离散符号的知识表示技术
- 包括:基于标签的半结构置标语言XML、基于万维网资源语义元数据描述框架 RDF和基于描述逻辑的本体描述语言 OWL等
- most:基于 RDF 三元组的表示方法
- 连续向量方式表示知识
- 典型:词向量等嵌入(Embedding)方式
- 包括:TransE 翻译模型、SME、、SLM、NTN、MLP,以及 NAM 神经网络模型等
- 知识图谱嵌入也通常作为一种类型的先验知识辅助输入到很多深度神经网络模型中,用来约束和监督神经网络的训练过程。
- 特点:可规模化扩展

(2)知识表示学习
知识表示学习主流方法:将实体和关系表示为稠密的低维向量实现了对实体和关系的分布式表示, 已经成为知识图谱语义链接预测和知识补全的重要方法。
优点:显著提升计算效率,有效缓解数据稀疏,实现异质信息融合并有助于实现知识融合。
代表方法
- 复杂关系建模 ——孤立学习每个三元组
- TransE模型:将知识库中的关系看作实体间的某种平移向量,可用于大规模知识图谱,但不善于处理知识库的复杂关系。
- TransH 模型和 TransR 模型:可以让一个实体在不同关系下拥有不同表示、认为不同关系拥有不同语义空间让一个实体在不同关系下拥有不同表示、认为不同关系拥有不同语义空间。
- TransD 模型和 TranSparse 模型:对TransH 模型和 TransR 模型中矩阵参数过多问题改进优化;
- TransG 模型和 KG2E模型:利用高斯分布来表示知识库中的实体和关系,并考虑实体和关系本身语义上不确定性。
- 关系路径建模(初步)——考虑关系路径的表示学习方法
- Path-based TransE(PTransE)模型
- 相关实验表明:考虑关系路径能够极大提升知识表示学习的区分性,提高在知识图谱补全等任务上的性能。
(3)知识表示与建模人才介绍
Gerhard Weikum(萨尔大学)
- YAGO 知识库创始人之一,信息抽取与知识挖掘、数据库与信息系统领域著名研究专家。
- YAGO 知识库主要集成了 Wikipedia、WordNet 和 GeoNames三个来源的数据,拥有千万级实体知识,包含超过 1.2 亿条三元组知识,能够将 WordNet 的词汇定义与 Wikipedia 的分类体系进行了融合集成。 YAGO 还考虑了时间和空间知识,为很多知识条目增加了时间和空间维度的属性描述,具有更加丰富的实体分类体系,经过人工评估证实确认,准确度达到 95%。
- 研究方向:研究涵盖知识获取表示、分布式信息系统、数据库性能优化与自主计算、信息检索与信息提取等方向, 2006 年前后侧重于知识库的研究,并在此方向做出了持续性探索。
Tom M. Mitchell(卡内基梅隆大学)
- Tom M. Mitchell, NELL 系统、心灵阅读智能计算机系统核心研发成员。
- NELL 系统目标是能够开发用自然语言回答用户提出的问题的方法,而不需要人为干预,自 2010 年初以来, NELL 系统始终保持全天候运行的工作状态,筛选数亿个网页,寻找已知信息与搜索过程中发现的信息之间的联系并建立新的连接,模仿人类学习新信息方式的方式。
- 研究方向:知识表示、知识库构建、 机器学习、 人工智能,机器人和认知神经科学等方向
Ian Horrocks(牛津大学)
- 描述逻辑推理系统、网络本体语言 OWL 奠基人。
- 研究方向(现阶段):知识表示和推理,特别是描述逻辑的本体语言和表格决策程序的优化,他所完成的关于描述逻辑的表象推理研究已经成为大多数描述逻辑推理系统的基础。
王海勋(Google Research)
- 研究方向(现阶段):语义网络、自然语言处理、数据管理与普适计算等。
唐杰(清华大学)
- 研究者社会网络 AMiner 大数据平台创始人
2、知识获取
(1)实体识别与链接
实体识别与链接是海量文本分析的 核心技术,也是知识图谱构建、知识补全与知识应用的核心技术,是计算机类人推理和自然语言理解提供知识基础。
- 实体识别:是文本理解意义的基础,也就是识别文本中指定类别实体的过程,可以检测文本中的新实体,并将其加入到现有知识库中。
- 实体链接:识别出文本中提及实体的词或者短语并与知识库中对应实体进行链接的过程,通过发现现有实体在文本中的不同出现,可以针对性的发现关于特定实体的新知识。
常用的三种统计模型方法:传统统计模型方法、深度学习方法、文本挖掘方法
① 传统统计模型方法
实体识别
- 基本思想:将实体识别任务形式化为从文本输入到特定目标结构的预测,使用统计模型来建模输入与输出之间的关联,并使用机器学习方法来学习模型的参数。
- 常用方法:最大熵分类模型、SVM 模型、隐马尔可夫模型、条件随机场模型。
- 代表方法:条件随机场模型,将实体识别问题转化为序列标注问题。
实体链接:
- 核心:计算实体提及(mention)和知识库中实体的相似度,并基于上述相似度选择特定实体提及的目标实体。
- 过程的核心:挖掘可用于识别提及(mention)目标实体相互关联的证据信息。
- 证据信息:实体统计信息、名字统计信息、上下文词语分布、实体关联度、文章主题等信息。
- 考虑到一段文本中实体之间的相互关联,相关的全局推理算法也被提出用来寻找全局最优决策。
缺点:
- 需要大量的标注语料,在开放域或Web环境下的信息抽取系统会遇到标注语料的瓶颈。
- 需要人工构建大量的特征,其训练并非一个端到端的过程。
==》解决方法:弱监督或无监督策略
- eg:半监督算法、远距离监督算法、基于海量数据冗余性的自学习方法
② 深度学习方法
实体识别:
- NN-CRF 架构:CNN/LSTM 被用来学习每一个词位置处的向量表示,基于该向量表示, NN-CRF 解码该位置处的最佳标签。
- 滑动窗口分类思想:使用神经网络学习句子中的每一个 N-Gram 的表示,然后预测该 N-Gram 是否是一个目标实体。
实体链接:
- 核心:构建多类型多模态上下文及知识的统一表示,并建模不同信息、不同证据之间的相互交互。通过将不同类型的信息映射到相同的特征空间,并提供高效的端到端训练算法。
- 相关工作:多源异构证据的向量表示学习、以及不同证据之间相似度的学习等。
优点:
- 端到端,无需人工定义相关特征;
- DL可以学习任务特定的表示,建立不同模态、不同类型、不同语言之间信息的关联,从而取得更好的实体分析性能。
研究热点:如何在深度学习方法中融入知识指导(如语言学结构约束、知识结构)、考虑多任务之间的约束、以及如何将深度学习用于解决资源缺乏问题。
③ 文本挖掘方法
文本挖掘方法:
- 定义:应用于半结构Web数据源上的语义知识获取;
- 核心:从特定结构(如列表、 Infobox)构建实体挖掘的特定规则。
- 典型系统:DBPedia、 YAGO、BabelNet、 NELL 和 Kylin 等
- 基于特定算法来对语义知识进行评分和过滤
- 目的:规则本身可能带有不确定性和歧义性,同时目标结构可能会有一定的噪音;
- 实体获取常采用Bootstrapping策略;
- 典型系统: TextRunner 系统和 Snowball 系统
- 语义漂移问题
- 典型方法:互斥 Bootstrapping 技术、 Co-Training 技术和 Co-Bootstrapping 技术。
研究热点:如何结合文本挖掘方法(面向半结构化数据,抽取出的知识质量高但覆盖度低)和文本抽取方法(面向非结构化数据,抽取出的知识相比文本挖掘方法质量低但覆盖度高)的优点,融合来自不同数据源的知识,并将其与现有大规模知识库集成
(2)实体关系学习
实体关系:两个或多个实体间的某种联系,用于描述客观存在的事物之间的关联关系。
关系抽取(也称实体关系学习):自动从文本中检测和识别出实体之间具有的某种语义关系,是知识图谱自动构建和自然语言理解的基础。
- 预定义关系抽取:系统所抽取的关系是预先定义好的,如上下位关系、国家—首都关系等。
- 开放关系抽取:不预先定义抽取的关系类别,由系统自动从文本中发现并抽取关系。
① 限定域关系抽取 vs. 开放域关系抽取
限定域关系抽取(研究热点):系统所抽取的关系是预先定义好的(有限个数),可以抽取语义化的实体关系三元组,来辅助其他业务。
开放域关系抽取:由系统自动从文本中发现、抽取关系。难以抽取语义化三元组。
② 基于规则的关系抽取 vs. 基于机器学习的关系抽取
基于规则的关系抽取方法:
- 规则设计:首先由专家根据抽取任务的要求设计出一些包含词汇、句法和语义特征的手工规则(或称为模式),
- 模式匹配:然后在文本分析的过程中寻找与这些模式相匹配的实例,从而推导出实体之间的语义关系。
基于机器学习的关系抽取
- 无监督关系抽取:把表示相同关系的模版聚合起来,不需要人工标注的数据。
- 有监督关系抽取:使用人工标注的训练语料进行训练,由于数据需要人工标注,难以应用到大规模场景。
- 弱监督关系抽取(研究热点):
- 代表方法:利用知识库回标文本来自动获得大量的弱监督数据
(3)事件知识学习
事件:促使事物状态和关系改变的条件,是动态的、结构化的知识。
事件知识学习:将非结构化文本中自然语言所表达的事件以结构化的形式呈现,对于知识表示、理解、计算和应用意义重大。
数据来源形式:已有的结构化的语义知识、数据库的结构化信息资源、半结构化信息资源以及非结构化资源。
① 事件识别和抽取
基于模式匹配的事件抽取
- 定义:采用模式匹配的方法对某种类型事件的识别和抽取。
- 步骤:模式获取(关键)、模式匹配。
- 按照模式构建过程中所需训练数据的来源可细分为:基于人工标注语料的方法和弱监督的方法
基于机器学习的事件抽取
- 定义:建立在统计模型基础上的多分类问题。
- 研究重点:特征选择 和 分类器选择。
- 方法(三类):
- 基于特征的方法:
- 研究重点:如何提取和集成具有区分性的特征(局部和全局特征)
- 多用于阶段性的管道(Pipeline )抽取,即顺序执行事件触发词识别和元素抽取.
- 基于结构的方法:将事件结构看作依存树,抽取任务则相应地转化为依存树结构预测问题,触发词识别和元素抽取可以同时完成。
- 神经网络的方法:
- 利用CNN抽取特征完成两阶段的识别任务,以便更好地考虑事件内部结构和各个元素间的关系。
- 将联合抽取模型与 RNN 相结合,利用带记忆的双向 RNN 抽取句子中的特征,并联合预测事件触发词和事件元素,进一步提升了抽取效果。
- 基于特征的方法:
② 事件检测和追踪
基于相似度的方法
- 过程:首先需要定义相似度度量,而后基于此进行聚类或者分类。
- 典型方法:VSM(向量空间模型)+ 组平均聚类(Group Average Clustering, GAC)\ 单一通过法(Single Pass Algorithm, SPA)
- GAC 只适用于历史事件发现,它利用分治策略进行聚类。
- SPA 可以顺序处理文档并增量式产生聚类结果,能同时应用于历史事件发现和在线事件发现。
概率统计方法(研究热点)
- 通常使用生成模型,适用于历史事件检测(有大量数据支持)。
- 特点:模型复杂,但当数据充足时,准确率更高。
- 研究方向:针对新闻等比较正式的规范文档、用于不规则或没有规律的非规范文档
③ 事件知识库构建(起步阶段)
事件知识学习的最终目的:从非结构化的文本数据中抽取结构化的事件表示,构建事件知识库弥补现有知识图谱的动态事件信息缺失问题。
研究方向:基于句子级的事件抽取、文档级的事件发现。
(4)知识获取人才介绍
Christopher D.Manning(斯坦福 NLP 实验室)
- 研究方向:知识管理、计算机科学、自然语言处理等方向,2000年后开始对知识应用领域的研究工作;
- 斯坦福 NLP 小组:工作范围从计算语言学的基础研究到人类语言技术的关键应用,涵盖句子翻译、句法分析与标记、自动问答、机器翻译、文本及视觉场景模拟等领域。
韩家炜(美国伊利诺伊大学厄巴纳-香槟分校)
- 研究方向:知识获取、数据挖掘、数据库系统、关联规则、时空数据挖掘、 Web 数据及信息网络数据等方向,侧重于数据挖掘。
Ralph Grishman(纽约大学数学科学院计算机科学)
- 研究方向:自然语言处理、信息检索、信息抽取、语义学、知识获取、机器翻译等方向,后来侧重于信息抽取的研究。
- 代表方法:“MENE”的统计命名实体识别系统(“A maximum entropy approach to named entity recognition”)
周国栋(苏州大学计算机科学与技术学院)
- 研究方向:自然语言处理、知识获取、信息抽取、隐马尔科夫模型研究等方向
黄萱菁(复旦大学计算机科学技术学院)
- 研究方向:问答系统、自然语言处理、中文信息编译等方向。
3、知识融合
知识图谱的多样性和异构性:由于数据来源广泛、质量参差不齐造成的。
语义集成:将不同的知识图谱融合为一个统一、一致、简洁的形式,为使用不同知识图谱的应用程序间的交互建立操作性。
- 常用技术:本体匹配(也称为本体映射)、实体匹配(也称为实体对齐、对象公指消解)以及知识融合等
常见流程:
- 包括(5 个环节):输入、预处理、匹配、知识融合和输出
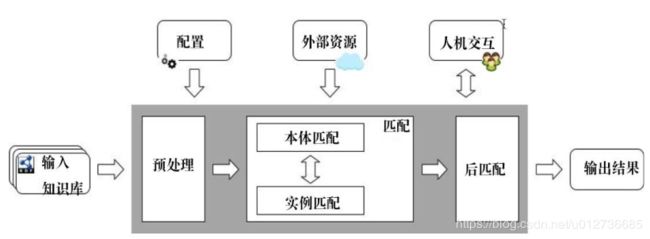
- 输入:待集成的若干个知识库以及配置、外部资源等。
(1)待集成的知识库格式一般为 RDF/OWL 数据文件或 SPARQL 端点(endpoint)
(2)外部资源是语义集成过程中使用到的背景知识,例如字/辞典背景知识(例如 WordNet)、常识背景知识(例如 Cyc)、实时背景知识(例如搜索引擎)等。 - 预处理:对输入知识库进行清洗和后续步骤的准备。
(1) 清洗:解决输入质量问题,与自有文本不同,知识库通常基于 RDF/OWL 语言构建,质量较好。
(2)后续步骤的准备:包括配置和数据两方面。 - 匹配:
(1)根据匹配对象的不同,匹配一般分为本体匹配和实体匹配两方面。
(2)文本相似性度是发现匹配的最基础方法,大致可分为四种类型:基于字符的(例如 Leven-shtein 编辑距离)、基于单词的(例如 Jaccard 系数)、混合型(例如 soft TF-IDF)和基于语义的(例如 WordNet) - 知识融合:一般通过冲突检测、真值发现等技术消解知识集成过程中的冲突,再对知识进行关联与合并,最终形成一个一致的结果。
- 输出:语义集的输出是一个统一的、一致的、简洁的知识库
(1)本体匹配
现状:现有大多数本体匹配方法处理的是成对的本体,但是成对匹配方法在同时匹配多个本体时会产生一些问题,最主要的问题是它们得到的结果从全局看可能存在冲突。
- 典型方法:LPHIM 多文本全体匹配方法——能够在匹配多个本体的同时保证结果是全局最优解
跨语言本体匹配:更加困难,特别是影响文本相似性度量的准确性。
- 典型方法: EAFG 和双语主题模型
(2)实例匹配
研究热点:众包和主动学习等人机协作方法。 这些方法雇佣普通用户,通过付出较小的人工代价来获得丰富的先验数据,从而提高匹配模型的性能。
基于表示学习的方法:
- 将实体、关系等 ==》低维空间中的实质向量(即分布式语义表示),并在知识图谱补全、知识库问答等应用中取得了不错的效果。
基于强化学习的语义集成方法——新动向
- 典型方法:ALEX 是一个通过利用用户提供的查询答案反馈来提高实例匹配质量的系统,它将每个匹配视作一个状态,用户反馈被转换为行为奖励,通过最大化收集到的行为奖励改善策略
(3)知识融合人才介绍
Renée J. Miller(NSERC 商业智能战略网络,多伦多大学)
- 研究方向:研究涵盖数据交换、知识融合、数据集成、知识管理和数据共享等方向
Felix Naumann(哈索·普拉特钠数字工程研究院)
- 研究方向:数据挖掘、数据完整性、知识融合等方向
Roberto Navigli(罗马大学计算机科学系)
- BabelNet的创始人, BabelNet是最大的高质量多语言百科全书计算机辞典。
苏俭(大规模技术部署首席专家、 BIRC 自然语言处理部门主管、联合主任等)
- 研究方向:机器学习、信息提取、情感分析,文本挖掘、机器翻译、自然语言处理等方向, 2012 年前后开始专注研究生物信息。
Jérôme Euzenat(法国国家计算机科学与控制研究中心,NIRIA)
- 研究方向:语义知识表示、本体匹配等,并著有《Ontology Matching》
4、知识图谱查询和推理计算
(1)知识推理
知识推理:从给定的知识图谱推导出新的实体跟实体之间的关系。在知识计算中具有重要作用,如知识分类、知识校验、知识链接预测与知识补全等。
方法分类:基于符号的推理和基于统计的推理
- 基于符号的推理
- 一般是基于经典逻辑(一阶谓词逻辑或者命题逻辑)或者经典逻辑的变异(比如说缺省逻辑)
- 从一个已有的知识图谱推理出新的实体间关系,可用于建立新知识或者对知识图谱进行逻辑的冲突检测。
- 基于统计的方法
- 一般指关系机器学习方法,即通过统计规律从知识图谱中学习到新的实体间关系。
① 基于符号的并行知识推理
基于多核、多处理器技术的大规模推理:
- 单机环境(并行技术:共享内存模型——提升本体推理时间效率,适用于实时性较高的场景)
基于分布式技术的大规模推理:
- 多机搭建集群——突破大规模数据的处理界限
- 很多工作基于 MapReduce 提出大规模本体的推理方法
- 代表方法:推理系统 WebPIE(2010年, Urbani 等)
② 链接预测
基于表示学习的方法:
- 分布式表示:将实体与关系统一映射至低维连续向量空间——刻画语义特征,推断实体和实体之间潜在关系。
基于图特征的方法:
- 思想:利用抽取出的图特征来预测两个实体间可能存在的不同类型的边(关系)。
- eg:根据两个实体“姚明”和“叶莉”在KG中的联通路径可预测他们之间大概率具备“配偶”关系。
③ 模式归纳方法
基于 ILP 的模式归纳方法:
- 向下精化算子学习 ALC 的概念定义公理(Jens Lehmann 等)
- 相关算法实现:本体学习工具 DL-Learner
基于关联规则挖掘的模式归纳方法:
- 利用谓词偏好因子度量方法以及谓词语义相似度学习相反和对称公理;
- 利用模式层信息给规则的挖掘提供更多的语义;
- 对传统关联规则挖掘技术进行了改进,事务表中用 0 到 1 之间的一个实数代替原来的 0 或者 1,使得提出的方法更符合语义数据开放的特点
基于机器学习的模式归纳方法:
- 利用聚类的算法学习关系的定义域和值域;
- 应用统计的方法过滤属性的使用,并找出准确、健壮的模式,用于学习属性的数量约束公理。
(2)知识存储和查询
以图(Graph)的方式来展现实体、事件及其之间的关系。
研究内容:研究如何设计有效的存储模式支持对大规模图数据的有效管理,实现对知识图谱中知识高效查询。
① 基于关系数据模型的 RDF 数据存储和查询
简单三列表:
- 维护一张巨大的三元组表来管理 RDF 数据。
- 表包含三列:主体、谓词和客体(或者主体、属性和属性值)。
- 查询:将SPARQL转换为SQL,根据SQL执行多次自连接操作得以最终解。
水平存储:
- 行:将每一个RDF主体(subject),
- 列:包含该RDF数据集合中所有属性。
- 优点:设计简单,易于回答面向某单个主体的属性值的查询(星状查询)。
- 缺点:表中存在大量的列;表的稀疏性问题;水平存储存在多值性的问题;数据的变化可能带来很大的更新成本。
属性表:
- 为降低自连接操作次数,Jena利用聚类属性表、Oracle利用分类属性表等属性表进行RDF数据管理。
- 聚类属性表:Jena 通过聚类的方式将一些类似的三元组聚类到一起,然后将每一个聚类的三元组统一到一张属性表中进行管理;
- 分类属性表:利用 RDF 资源的类型信息将三元组进行分类,相同类的三元组放到同一张表中;
垂直划分策略——按照谓词(或属性)分割
- 对 RDF 数据按照谓词(或属性)分割成若干表的方法(SW-Store),具体而言, 将 RDF 三元组按照谓词(或属性)的不同分成不同的表,每张表能保存在谓词(或属性)上相同的三元组。
全索引策略:
- “全索引(exhaustive indexing)”策略。提高简单三列表存储的查询效率
② 基于图模型的 RDF 数据存储和查询
优点:最大限度的保持 RDF 数据的语义信息,利于对语义信息的
查询。
SPARQL 查询就可以视为在 RDF 数据图上进行子图匹配运算。
- 子图匹配运算(经典问题,NP难问题):给定一个数据图和一个查询图,找出数据上所有与查询图子图同态的位置。
- 典型系统:gStore、TurboHOM++等
(3) 知识查询与推理人才介绍
Frank Wolter(利物浦大学计算机)
- 研究方向:模态逻辑、语义、逻辑推理、人工智能、知识表示与推理等方向,自 1994 年起在知识查询与推理领域的研究从未间断并屡次获奖。
Diego Calvanese(KRDB,意大利波尔扎诺自由大学)
- 研究方向:知识表示和推理、本体语言、描述逻辑、概念数据建模、数据集成、图形数据等方向。
- 在 2005 年前后有大量研究成果产出,主要为逻辑描述与数据完整性方向,现阶段负责 Euregio 知识运营支持、 SMartDF 等科研项目。
沈一栋(中国科学院软件研究所)
- 研究方向:逻辑描述、逻辑程序设计、数据挖掘、联合查询、知识推理与查询等方向
漆桂林(东南大学)
- 研究方向:知识库构建与清理、知识挖掘、语义 Web、深度学习等方向, 2005 年至今在知识图谱领域从事长期研究。
Meghyn Bienvenu(波尔多大学 LaBRI 研究实验室)
- 研究方向:逻辑模型、知识表示和推理、逻辑描述、联合查询等方向, 现阶段的主要研究方向围绕描述逻辑本体及其在查询数据中的应用展开。
5、知识应用
(1)典型应用
知识图谱的典型应用(KG + 业务场景)
- 包括:语义搜索、智能问答以及可视化决策支持三种。
- 关键研究内容:如何针对业务需求设计实现知识图谱应用,并基于数据特点进行优化调整。
① 语义搜索
- 语义搜索:当前基于关键词的搜索技术在KG的知识支持下可以上升到基于实体和关系的检索。
- 作用:准确捕捉用户搜索意图,解决关键字语义多样性及语义消歧难题;
- 结果:直接给出满足用户搜索意图的答案,而不是包含关键词的相关网页的链接;
② 智能问答
- 问答系统(Question Answering, QA)任务:智能问答需要针对用户输入的自然语言进行理解,从知识图谱中或目标数据中给出用户问题的精准的自然语言形式的答案。
- 关键技术及难点:准确的语义解析、正确理解用户的真实意图、以及对返回答案的评分评定以确定优先级顺序。
③ 可视化决策支持
- 可视化决策支持:通过提供统一的图形接口,结合可视化、推理、检索等,为用户提供信息获取的入口。
- 关键问题:通过可视化方式辅助用户快速发现业务模式、
提升可视化组件的交互友好程度、以及大规模图环境下底层算法的效率等。
(2)通用和领域知识图谱
通用知识图谱 vs. 领域知识图谱
- 相同:本质相同;
- 不同:覆盖范围与使用方式。
- 通用知识图谱:强调知识的广度,可看成一个面向通用领域的结构化百科知识库,其中包含了大量的现实世界中的常识性知识,覆盖面广,通常运用百科数据进行自底向上(Top-Down)的方法进行构建。
- 领域知识图谱(行业知识图谱、垂直知识图谱):面向某一特定领域的基于语义技术的行业知识库,有着严格而丰富的数据模式,应用需求各不相同,因此没有一套通用的标准和规范来指导构建,需要基于特定行业通过工程师与业务专家的不断交互沟通与定制来实现, 所以对该领域知识的深度、知识准确性有着更高的要求。
(3)知识应用人才介绍
Sophia Ananiadou(英国国家文本挖掘中心(NaCTeM),曼彻斯特大学)
- 研究方向:信息提取、文本挖掘、数据挖掘、自然语言处理、生物信息、算法等方向,其中的文本挖掘方向贡献显著,为生物医学领域提供了工具、资源、系统及基础设施。
- 现阶段的研究侧重于提高知识发现速度。
Sören Auer(汉诺威大学)
- 研究方向:关联数据、知识库、文本分析、语义网络、开放数据等方向,对语义网络、 关联数据的研究较为深入。
周明(微软亚洲研究院)
- 研究方向:机器翻译、知识应用、统计模型、自然语言处理等方向。
赵军(中国科学院自动化所模式识别国家重点实验室)
- 研究方向:问答系统、信息提取、知识库构建、自然语言处理、中文信息处理等方向, 2005 年后在知识库构建领域有持续性研究。
6、高引论文(Top10)
| 序号 | paper |
|---|---|
| 1 | Distant supervision for relation extraction without labeled data Mike Mintz, Steven Bills, Rion Snow, and Dan Jurafsky.ACL/IJCNLP,2009. |
| 2 | You are where you tweet: a content-basedapproach to geo-locating twitter users Zhiyuan Cheng, James Caverlee, and Kyumin Lee.CIKM,2010. |
| 3 | YAGO2: a spatially and temporally enhanced knowledge base from wikipedia Johannes Hoffart, Fabian M. Suchanek, Klaus Berberich, and Gerhard Weikum.IJCAI,2013. |
| 4 | Knowledge vault: a web-scale approach to probabilistic knowledge fusion Xin Dong 0001, Evgeniy Gabrilovich, Geremy Heitz, Wilko Horn, Ni Lao, Kevin Murphy, Thomas Strohmann, Shaohua Sun, and Wei Zhang.KDD,2014. |
| 5 | Robust disambiguation of namedentities in text Johannes Hoffart, Mohamed Amir Yosef, Ilaria Bordino, Hagen Fürstenau, Manfred Pinkal, Marc Spaniol, Bilyana Taneva, Stefan Thater, and Gerhard Weikum.EMNLP,2011. |
| 6 | BabelNet: building a very large multilingual semantic network Roberto Navigli, and Simone Paolo Ponzetto.ACL,2010. |
| 7 | Driving with knowledge from the physical world Jing Yuan, Yu Zheng, Xing Xie, and Guangzhong Sun.KDD,2011. |
| 8 | Open domain event extraction from twitter Alan Ritter, Mausam, Oren Etzioni, and Sam Clark.KDD,2012. |
| 9 | Sentiment analysis of blogs by combining lexical knowledge with text classification57 Prem Melville, Wojciech Gryc, and Richard D. Lawrence. KDD,2009. |
| 10 | Open information extraction: the second generation Etzioni, Oren and Fader, Anthony and Christensen, Janara and Soderland, Stephen and Mausam, Mausam. IJCAI, 2011 |
第三章 应用篇

1、通用知识图谱应用
通用知识图谱:
- 面向通用领域的“结构化的百科知识库”,其中包含了大量的现实世界中的常识性知识,覆盖面极广。
- 由于现实世界的知识丰富多样且极其庞杂,通用知识图谱主要强调知识的广度,通常运用百科数据进行自底向上(Top-Down)的方法进行构建。
国外典型系统:
- DBpedia :使用固定的模式从维基百科中抽取信息实体,当前拥有 127 种语言的超过两千八百万实体以及数亿 RDF 三元组;
- YAGO: 则整合维基百科与 WordNet 的大规模本体,拥有 10 种语言约 459 万个实体, 2400 万个事实;
- Babelnet: 则采用将 WordNet 词典与Wikipedia 百科集成的方法,构建了一个目前最大规模的多语言词典知识库,包含 271 种语言 1400 万同义词组、 36.4 万词语关系和 3.8 亿链接关系。
国内典型系统:
- Zhishi.me: 从开放的百科数据中抽取结构化数据,当前已融合了包括百度百科、互动百科、中文维基三大百科的数据,拥有 1000 万个实体数据、一亿两千万个 RDF 三元组;
- CN-DBPedia:以通用百科为主线,结合垂直领域的 CN-DBPedia,则从百科类网站的纯文本页面中提取信息,经过滤、融合、推断等操作后形成高质量的结构化数据;
- XLore :则是基于中文维基百科、英文维基百科、百度百科、互动百科构建的大规模中英文知识平衡知识图谱。
2、领域知识图谱应用
领域知识图谱
- 用来辅助各种复杂的分析应用或决策支持,不同领域的构建方案与应用形式则有所不同
第四章 趋势篇
知识类型与表示
- 研究问题:面对包含大量实体及其之间的复杂关系的复杂知识,如何合理设计表示方案,更好地涵盖人类不同类型的知识。
知识获取
- 研究问题:如何从互联网大数据萃取知识,同时提升准确率、准确率和效率。
知识融合
- 研究问题:多源异构数据(且存在大量噪声和冗余),或使用不同的语言的数据的有机融合。
知识应用
- 研究问题:目前大规模知识图谱的应用场景和方式比较有限,如何有效实现知识图谱的应用,利用知识图谱实现深度知识推理,提高大规模知识图谱计算效率,需要人们不断锐意发掘用户需求,探索更重要的应用场景,提出新的应用算法。
趋势:特色化、开放化、智能化