知识图谱(五)——实体消歧
一、任务概述
多样性——同一实体在文本中会有不同的指称。eg:飞人、帮主、老大和MJ都指美国篮球运动员迈克尔·乔丹
歧义性——相同的实体指称在不同的上下文中可以指不同的实体。eg:迈克尔·乔丹指美国篮球运动员、爱尔兰政治家等
1、任务定义
实体消歧,定义为六元组。此处实体指的是命名实体。
M = N , E , D , O , K , δ M=N,E,D,O,K,\delta M=N,E,D,O,K,δ
- N = n 1 , n 2 , . . . , n l N=n_1,n_2,...,n_l N=n1,n2,...,nl 表示待消歧的实体名集合。eg:李娜、迈克尔·乔丹等
- E = e 1 , e 2 , . . . , e k E=e_1,e_2,...,e_k E=e1,e2,...,ek 表示待消歧实体名的目标实体列表,包括了所有待消歧实体名可能指向的实体。eg:李娜(网球运动员)、李娜(跳水运动员)、迈克尔·乔丹(NBA巨星)、迈克尔·乔丹(足球运动员)等。实际应用中,目标实体列表通常以知识库的形式给出,eg:Wikipedia、Freebase
- D = d 1 , d 2 , . . . , d n D=d_1,d_2,...,d_n D=d1,d2,...,dn 表示一个包含待消歧实体名的文档集,eg:“迈克尔·乔丹”的前100个Google搜索结果的网页集合。
- O = o 1 , o 2 , . . . , o m O=o_1,o_2,...,o_m O=o1,o2,...,om 表示 D D D 中所有待消歧的实体指称项集合。
- 实体指称项:在具体上下文中出现的待消歧实体名,是实体消歧任务的基本单位。
- eg:“迈克尔·乔丹是NBA最伟大的球星”中的“迈克尔·乔丹”是实体迈克尔·乔丹(NBA巨星)
的一个指称项。
- K K K 表示命名实体消歧任务所使用的背景知识,最常用的是关于目标实体的文本描述。
- 发展:从实体描述文本=》社会化网络中蕴含的实体社会化关联知识=》概念之间的语义关联知识等
- δ : O × K → E \delta:O\times K \to E δ:O×K→E 表示命名实体消歧函数,用于将待消歧的是实体指称项映射到目标实体列表(若 E E E是显示给定的)或按照其指向的目标实体进行聚类(若 E E E没有显示给定,是隐藏变量)
2、任务分类
按照目标实体列表是否给出,实体消歧系统可分为:
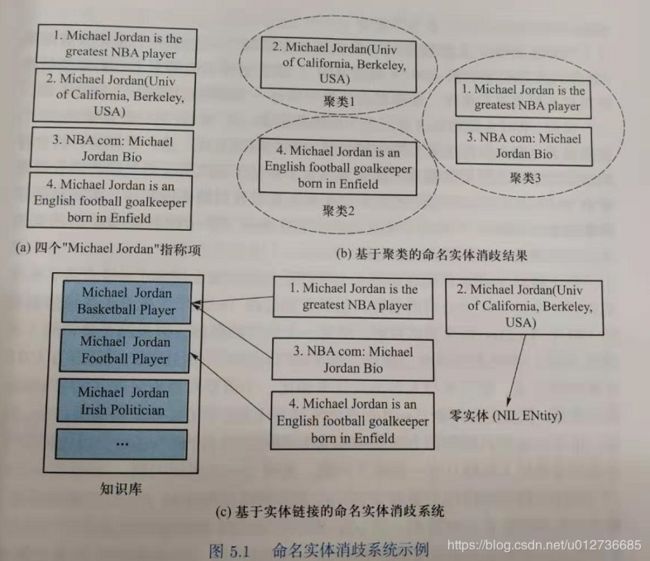
- 基于聚类的实体消歧系统:目标实体列表未给定,以聚类方式对实体指称项进行消歧。所有指向同一个目标实体的指称项被消歧系统聚类到同一类别下,聚类的结果中每一个类别对应一个目标实体。
- 基于实体链接的实体消歧系统:目标实体列表给定,将实体指称项与目标实体列表中的对应实体进行链接实现消歧
按照实体消歧任务领域不同,实体消歧系统可分为:(区别在于实体指称项的文本表示)
-
结构化文本实体消歧系统:
- 实体指称项被表示为一个结构化的文本记录,eg:list列表、知识库等
- 缺少上下文,主要依赖字符串比较和实体关系信息完成消歧;
-
非结构化文本实体消歧系统
- 实体指称项被表示为一段非结构化文本
- 存在大量上下文,主要利用指称项上下文和背景知识完成消歧。
- 常用方法:基于聚类的实体消歧、基于实体链接的实体消歧
3、相关测评
主流的命名实体消歧测评平台:
- WePS(Web Person Search Clustering Task)测评,主要针对基于聚类的命名实体消歧
- TAC KBP的Entity Linking测评,主要针对基于实体链接的命名实体消歧
二、基于聚类的实体消歧方法
在未给定目标实体的情况下,对于给定待消歧的实体指称集合 O = o 1 , o 2 , . . . , o k O=o_1,o_2,...,o_k O=o1,o2,...,ok,以聚类方式实现消歧的系统按以下步骤进行消歧:
- 对每一个实体指称项 o o o,抽取其特征(eg:上下文中的词、实体、概念),并将其表示称特征向量 o = w 1 , w 2 , . . . , w n o=w_1,w_2,...,w_n o=w1,w2,...,wn
- 计算实体指称项之间的相似度(关键)。
- 基于表层特征的实体指称项相似度计算;
- 基于扩展特征的实体指称项相似度计算;
- 基于社会化网络的实体指称项相似度计算;
- 采用某种聚类算法对实体指称项聚类,使得聚类结果中每一个类别都对应于一个目标实体上。
1、基于表层特征的实体指称项相似度计算
传统方法多利用表层特征计算相似度,这些方法通常是词袋模型(Bag of Words,BoW)模型的延伸,性能不好。
步骤:
- 特征表示:将实体指称项表示为 Term 向量形式,其中每个 Trem 的权重通常采用 TF-IDF 算法进行计算。
- 其他表示方法:上下文词向量、Bi-gram表示、句法和语义特征。。。
- 相似度计算:采用Cosine计算相似度
这类方法都是基于上下文表层特征的关联来计算它们之间的相似度,而没有考虑到上下文特征的内在关联,因此影响聚类效果。
2、基于扩展特征的实体指称项相似度计算
利用知识资源提升实体消歧的性能。
最直接的方法:使用知识资源来扩展实体指称项的特征表示。
- 通过抽取属性信息扩展指称项
- 通过上下文词和Wikipedia中的类别信息
- 层次化分类体系
- 结构化关联语义
- …
3、基于社会化网络的实体指称项相似度计算
基于社会化网络的实体指称项相似度通常使用基于图的算法,能够充分利用社会化关系的传递性,从而考虑隐藏的关系知识,在某些情况下(特别是结构化数据,eg:论文记录、电影记录等)能够更为准确的实体指称项相似度计算结果。
缺点:只用到上下文中的实体信息,不能完全利用实体指称项的其他上下文信息,因此不能在文本消歧领域取得有竞争力的性能。
过程:
- 表示成社会化关系图 G = ( V , E ) G=(V,E) G=(V,E) ,其中实体指称项和实体均被表示为节点,节点之间的边表示它们之间的社会化关系。
- 相似度计算:通常采用图算法中的随机游走算法来计算.
三、基于实体链接的实体消歧方法
基于实体链接的实体消歧方法:将实体指称项链接到知识库中特定的实体,也称实体链接(Entity Linking)。
实体链接:将一个命名实体的文本指称项(Textual Mention)链接到知识库中对应实体的过程(若不存在对应实体,则将实体指称项链接到空实体NIL)
实体链接的输入包括两部分:
- 目标实体知识库:最常用Wikipedia,或特定领域知识库。
- 知识库通常包括:实体表、实体的文本描述、实体的结构化信息(eg:属性/属性值对)、实体的辅助性信息(eg:实体类别);也经常提供额外的结构化语义信息,eg:实体之间的关联
- 待消歧实体指称项及其上下文信息
步骤:
- 链接候选过滤(Blocking):根据规则或知识过滤大部分指称项不可能指向的实体,仅仅保留少量链接实体候选。
- 实体链接(Linking):给定指称项及其链接候选,确定该实体指称项最终指向的目标实体。(重点研究)
1、链接候选过滤方法
大部分是基于实体指称项词典:通过在字典中记录一个指称项所有可能指向的目标实体来进行链接候选过滤。
例如:实体指称项字典实例,AI
| 实体名 | 目标实体 |
|---|---|
| AI | Artificial Intelligent Game Artificial Intelligent Ai(singer) Strong AI |
传统实体链接方法:使用Wikipedia等知识资源构建指称项词典,包括Wikipedia Entity Name、Wikipedia Redirection Page等。
为了匹配模糊或拼错的指称项,一些基于构词法的模糊匹配也在TAC评测中使用,eg:Metaphone算法和Soft TFIDF算法
2、实体链接方法(重点)
给定一个指称项 m m m 及其链接实体候选 E = e 1 , e 2 , . . . , e n E=e_1,e_2,...,e_n E=e1,e2,...,en,实体链接方法选择与指称项具有最高一致性打分的实体作为其目标实体。
e = arg max e S c o r e ( e , m ) e=\mathop{\arg\max_{e}}Score(e,m) e=argemaxScore(e,m)
如何计算 S c o r e ( e , m ) Score(e,m) Score(e,m)是关键,现有方法可分为:
- 向量空间模型
- 主题一致模型
- 协同实体链接模型
- 基于神经网络的模型
(1)向量空间模型
相似度计算依据:实体指称项上下文与目标实体上下文特征的共现信息来确定。
过程:实体概念和实体指称项都被表示为上下文中Term组成的向量(Term通常为词,还可能包括概念、类别等)。基于Term向量表示,向量空间模型通过计算两个向量之间的相似度对实体概念和指称项之间的一致性进行打分。
研究重点:
- 如何抽取有效的特征表示:上下文中的词、上下文抽取的概念和实体、从知识源获取实体指称项的额外信息
- 如何更有效地计算向量之间的相似度:Cosine相似度、上下文词重合度、分类器等机器学习方法
(2)主题一致模型
一致性依据:实体指称项的候选实体概念与指称项上下文中的其他实体概念的一致性程度。
计算一致性打分时,通常考虑如下两方面因素:
- 上下文实体的重要程度:与主题的相关程度。传统方法使用实体与文本内其他实体的语义关联的平均值作为重要程度的打分。
w ( e , o ) = ∑ e i ∈ O s r ( e , e i ) ∣ O ∣ w(e,o)=\frac{\sum_{e_i\in{O}}sr(e,e_i)}{|O|} w(e,o)=∣O∣∑ei∈Osr(e,ei)
其中, O O O是实体指称项上下文中所有实体的结合, s r ( e , e i ) sr(e,e_i) sr(e,ei)是实体 e e e和实体 e i e_i ei之间的语义关联值,通常基于知识资源计算。 - 如何计算一致性:大部分使用目标实体与上下文中其他实体的加权语义关联平均作为一致性打分。
C o h e r e n c e ( e , o ) = ∑ e i ∈ O w ( e , o ) s r ( e , e i ) ∑ e i ∈ O w ( e , o ) Coherence(e,o)=\frac{\sum_{e_i\in{O}}w(e,o)sr(e,e_i)}{\sum_{e_i\in O}w(e,o)} Coherence(e,o)=∑ei∈Ow(e,o)∑ei∈Ow(e,o)sr(e,ei)
其中, o o o是实体指称项, w ( e , o ) w(e,o) w(e,o)是实体 e e e的权重,而 s r ( e , e i ) sr(e,e_i) sr(e,ei)是实体之间的语义关联度。
(3)协同实体链接
上述两方法忽略了单篇文档内所有实体指称项的目标实体之间的关系。
方法:可将单篇文档的协同实体链接看成一个优化任务,其优化任务的目标函数由以下公式决定:
1 ( ∣ S o ∣ 2 ) ∑ s ≠ s ′ ∈ S o r ( y s , y s ′ ) + 1 ( ∣ S o ∣ ) w T f s ( y s ) \frac{1}{ \begin{pmatrix} |S_o| \\ 2 \\ \end{pmatrix} }\sum_{s \neq{s'}\in S_o}r(y_s,y'_s)+\frac{1}{(|S_o|)}w^Tf_s(y_s) (∣So∣2)1s̸=s′∈So∑r(ys,ys′)+(∣So∣)1wTfs(ys)
其中 y s y_s ys 指的是实体指称项 s s s 的目标实体, S o S_o So 是单篇文档内所有实体指称项的集合, r ( y s , y s ′ ) r(y_s,y'_s) r(ys,ys′) 是目标实体之间的语义关联, f s ( y s ) f_s(y_s) fs(ys) 是实体指称项 s s s 与其目标实体 y s y_s ys 的一致性打分。
- 第一部分:对单篇文档内所有实体指称项的目标实体之间的关系进行建模。
- 第二部分:对单篇文档内实体指称项与其目标实体之间的一致性进行建模。
(4)基于神经网络的实体消歧方法
卷积网络等
四、面向结构化文本的实体消歧方法
列表型数据没有上下文描述信息,需要利用实体的类别信息,实体的流行度和列表中的其他信息进行消歧。