Transformer
Transformer来自论文: All Attention Is You Need
别人的总结资源:
- 谷歌官方AI博客: Transformer: A Novel Neural Network Architecture for Language Understanding
- Attention机制详解(二)——Self-Attention与Transformer谷歌软件工程师
- 放弃幻想,全面拥抱Transformer:自然语言处理三大特征抽取器(CNN/RNN/TF)比较中科院软件所 · 自然语言处理 /搜索 10年工作经验的博士(阿里,微博);
- Calvo的博客:Dissecting BERT Part 1: The Encoder,尽管说是解析Bert,但是因为Bert的Encoder就是Transformer,所以其实它是在解析Transformer,里面举的例子很好;
- 再然后可以进阶一下,参考哈佛大学NLP研究组写的“The Annotated Transformer. ”,代码原理双管齐下,讲得也很清楚。
- 《Attention is All You Need》浅读(简介+代码)这个总结的角度也很棒。
A High-Level Look
可以将输入的语言序列转换成另外一种序列,比如下图的神经机器翻译:

Transformer模型由编码器-解码器组合组成,解码器负责对序列进行编码,提取时间和空间信息,解码器负责利用时间和空间特征信息进行上下文预测,下图是单个结构:
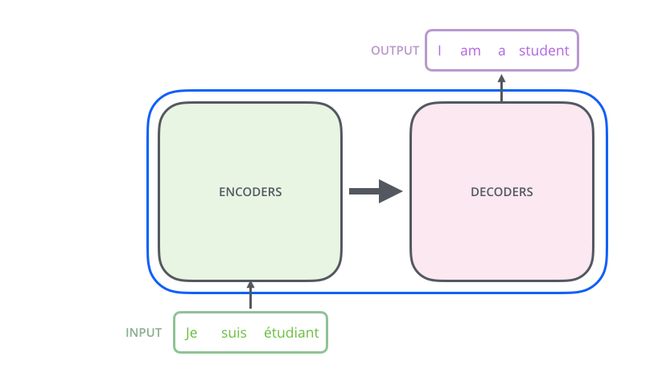
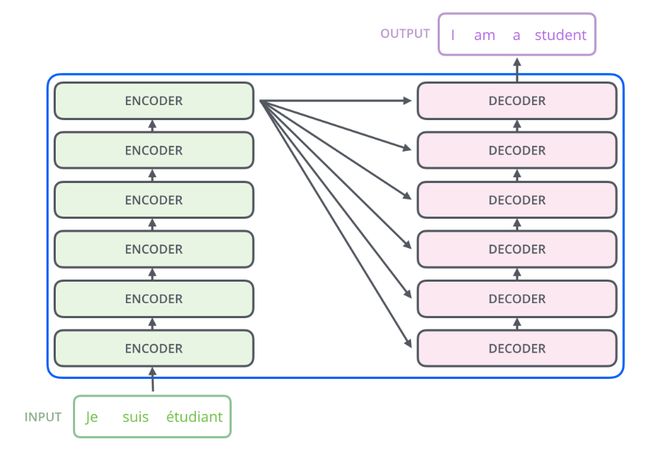
编码器和解码器堆栈的组合结构,在谷歌的实验结构中采用了6个编码器和6解码器相对应,使模型的编码能力和解码能力达到一个平衡状态(堆栈式结构):
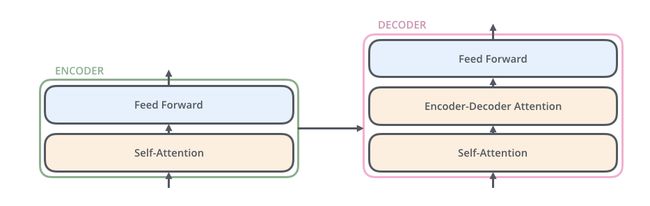
编码器-解码器的内部结构,类似seq2seq模型:
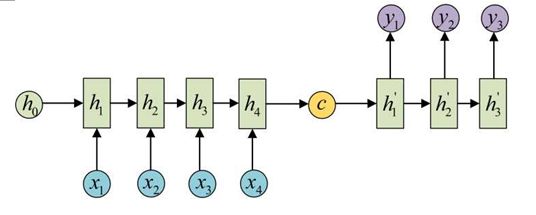
seq2seq模型:
Encoder: 由6个相同的层组成, 每层包含两个sub-layers.第一个sub-layer就是multi-head attention layer,然后是一个简单的全连接层。其中每个sub-layer都加了residual connection(残差连接)和normalisation(归一化)。
Decoder: 由6个相同的层组成,这里的layer包含三个sub-layers, 第一个sub-layer 是masked multi-head attention layer。这里有个特别点就是masked, 作用就是防止在训练的时候,使用未来的输出的单词。比如训练时,第一个单词是不能参考第二个单词的生成结果的。Masked是在点乘attention操作中加了一个mask的操作,这个操作是保证softmax操作之后不会将非法的values连到attention中,提高泛化性。

Self-Attention at a High Level
假设下面的句子就是我们需要翻译的输入句:
”The animal didn't cross the street because it was too tired”
当模型处理单词的时候,self attention层可以通过当前单词去查看其输入序列中的其他单词,以此来寻找编码这个单词更好的线索。

Self-Attention in Detail
第一步是将输入的嵌入词向量通过三个不同的参数矩阵得到三个向量,分别是一个Query向量,一个Key向量和一个Value向量,参数矩阵分别为Wq,Wk,Wv,,如下图所示:

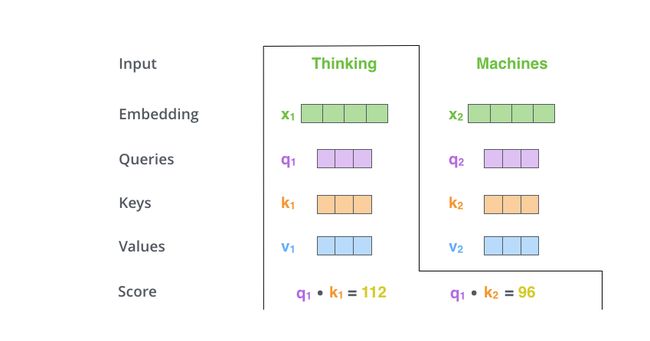
第二步是通过当前词的q向量与其他词的k向量计算当前词相对于其他词的得分,分数采用点积进行计算,如下图所示:
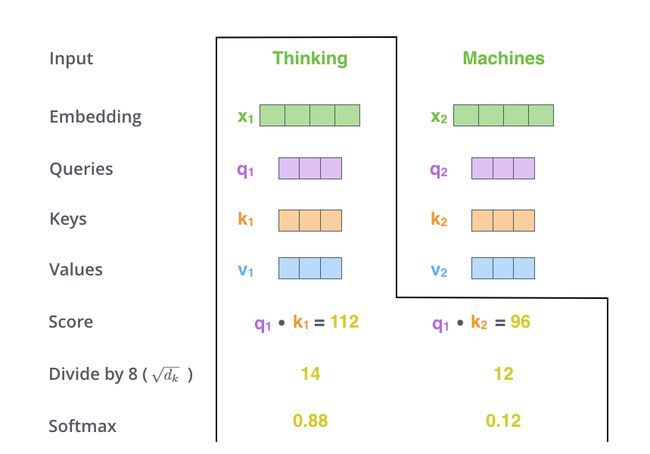
第三步和第四步是讲得到的分数除以k值维数的平方根(k值维数为64,可以使训练过程有更加稳定的梯度,这个归一化的值是经验所得),再通过softmax得到每个得分的标准化得分:
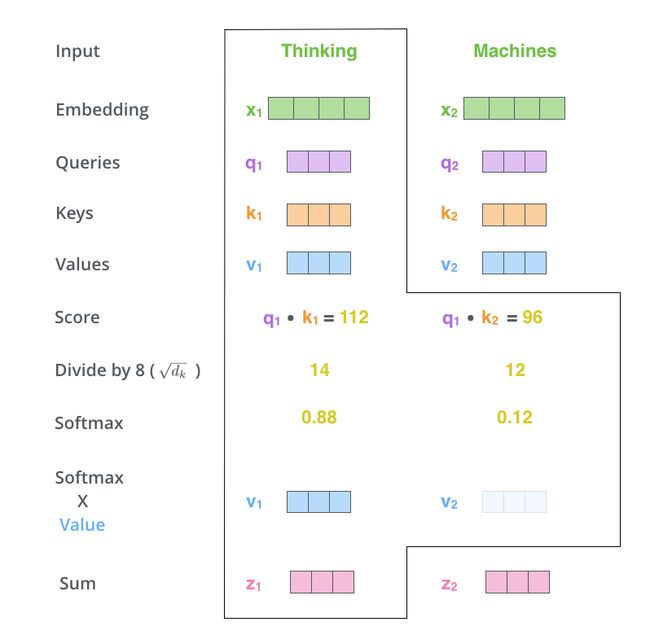
第五步是对当前词所得到的标准化值对所有value向量进行加权求和得到当前词的attention向量,这样就使不同单词的嵌入向量有了attention的参与,从而预测上下文句子的时候体现不同的重要的重要程度。
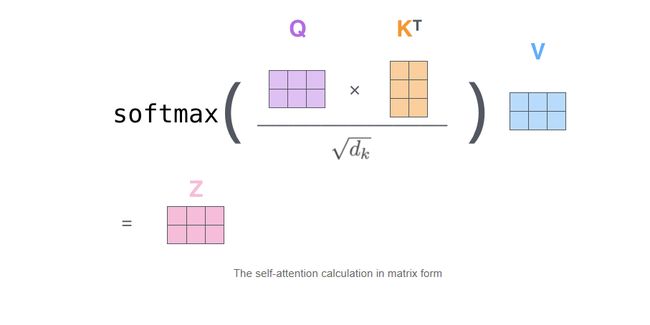
Matrix Calculation of Self-Attention
-
Attendtion向量计算的矩阵形式,通过全职矩阵进行词向量的计算大大加快了神经网络的速度
-
X矩阵中的每一行对应于输入句子中的一个单词。(图中的4个方框论文中为512个)和q / k / v向量(图中的3个方框论文中为64个)

公式中浓缩前面步骤2到5来计算self attention层的输出。
The Beast With Many Heads
使用“Multi-headed”的机制来进一步完善self-attention层。“Multi-headed”主要通过两个方面改善了Attention层的性能,参数组成和子空间映射:

Many Heads的优缺点:
-
它拓展了模型关注不同位置的能力。Multi head 的每个参数矩阵都会记录单词的位置信息,使原来的单个位置信息变得更加复杂。
-
它为attention层提供了多个“representation subspaces”。由下图可以看到,在self attention中,我们有多个个Query / Key / Value权重矩阵(Transformer使用8个attention heads),使特征的提取变得更加复杂,而不是作为一个整体的特征进行,每个单独的子空间都会进行上下文的信息融合
在8个不同的子空间进行self-attention的操作,每个单词生成独立的8个向量
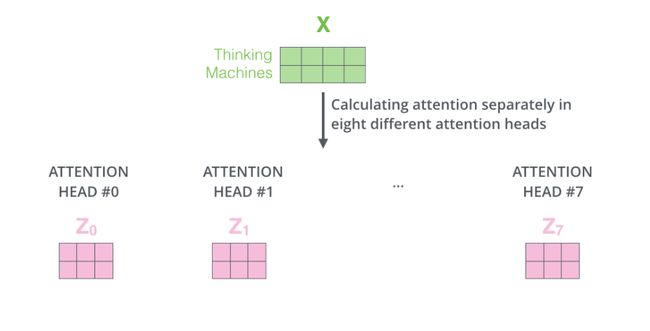
将8个子空间生成的向量压缩成一个大向量,每个向量的子空间矩阵能够学习到更多细节,压缩过程采用一个更大的参数矩阵进行,对multi-head向量进行组合,生成最终的特征向量。
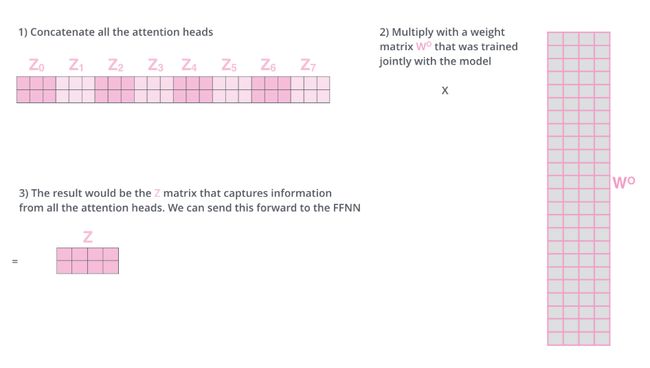
整体的框图来表示一下计算的过程:

Representing The Order of The Sequence Using Positional Encoding
其实上面介绍的网络里面并没有考虑序列的位置信息,在RNN中不同时刻的信息是通过递归网络的时间t来刻画的,有明显的时间刻度,所以引入了位置向量来解决时间刻度问题。
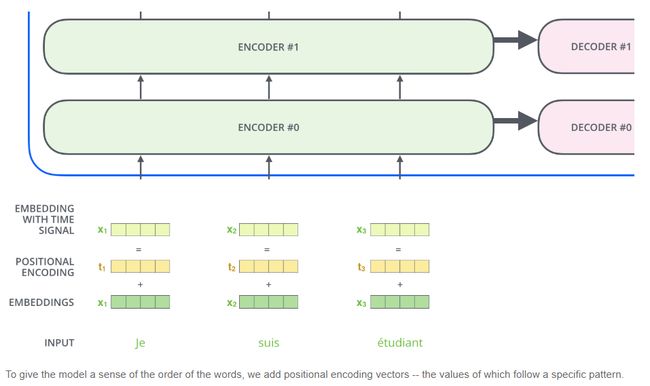
为了让模型捕捉到单词的顺序信息,添加位置编码向量信息(POSITIONAL ENCODING),位置编码向量不需要训练,它有一个规则的产生方式,生成与词嵌入向量有着相同的向量就可以。
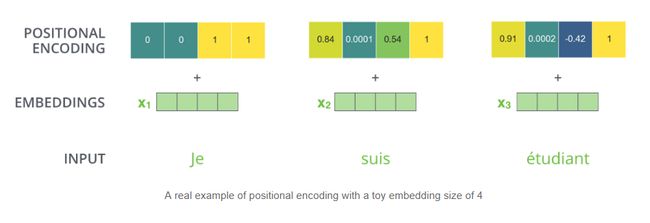
通过构造函数sin、cos来对位置进行嵌入,pos为单词位置信息,而i用来表达dimension 这里为了好说明,如果2i= dmodel, PE 的函数就是sin(pos/10000)。这样的sin, cos的函数是可以通过线性关系互相表达的,通过两个函数对奇偶维度进行编码。位置编码的公式如下图所示:
个人认为选择正余弦函数主要是在-1和1之间是一个对称关系,两个相邻的维度编码相差比较大,在位置上有更好的区分性,1000是序列的长度,一般尽量将取值范围控制在四分一个周期里面,这样会使每一个序列的每一个维度都取唯一的值。
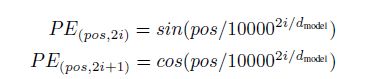
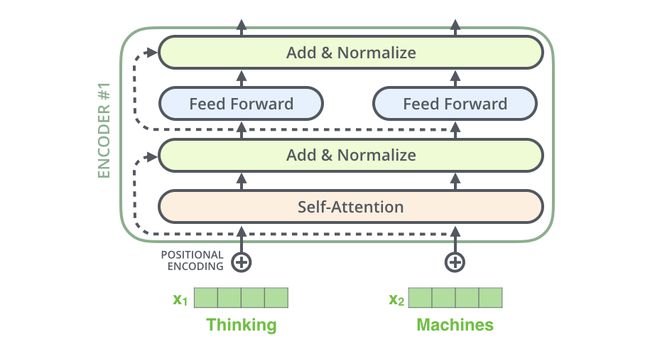
The Residuals
编码器和解码器里面的每一层都采用残差的思想进行训练,目的就是为了解决网络过深情况下的难训练问题,残差连接可以将目标值问题转化成零值问题,一定程度也可以减少网络的过拟合问题。
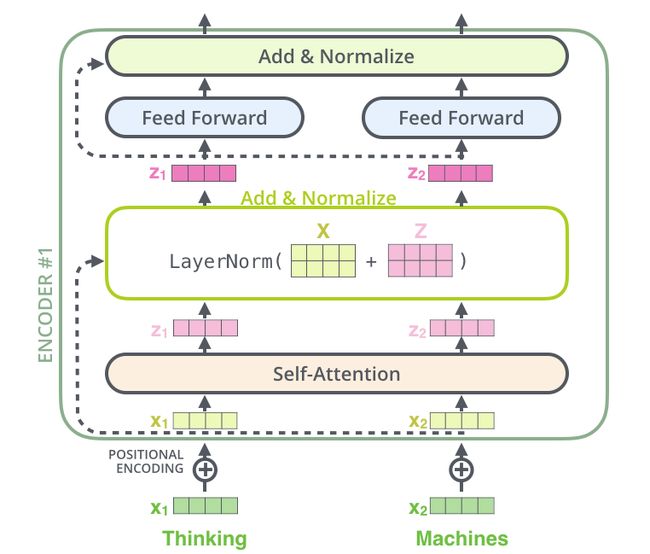
使用残差连接的编码器内部结构:
使用残差连接的编码器-解码器内部结构:
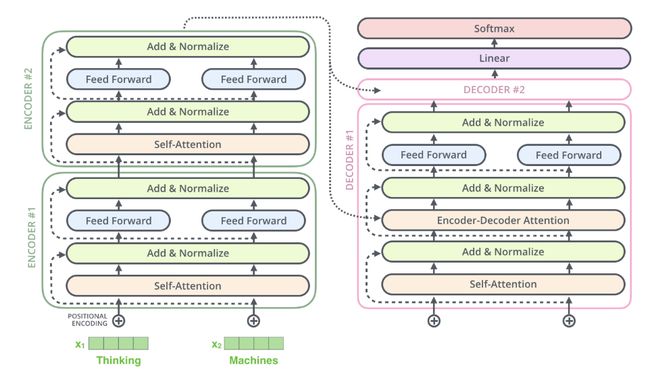
The Decoder Side
通过自回归方式进行预测,解码器每一个时间步输入一个单词,然后输出一个单词,将预测的单词作为下一时刻的输入进行单词的预测,直到预测结束。
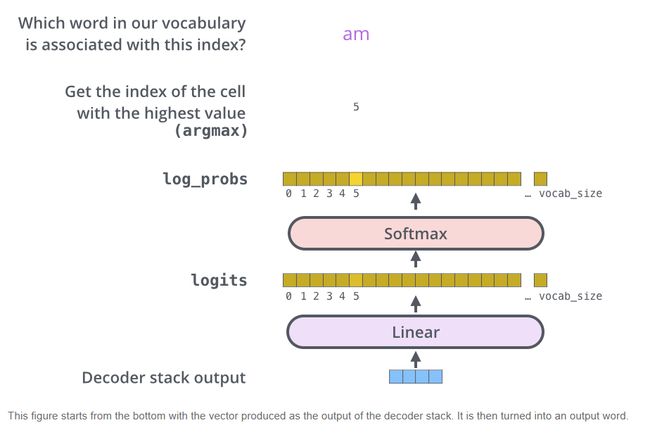
The Final Linear and Softmax Layer
-
线性层是一个简单的全连接神经网络,模型一次生成一个输出,我们可以假设模型从该概率分布中选择具有最高概率的单词并丢弃其余的单词。
-
对于最终句子的生成有2个方法:一个是贪婪算法(greedy decoding),一个是波束搜索(beam search)。
Bidirectional Encoder Representation from Transformers
Word Embedding
-
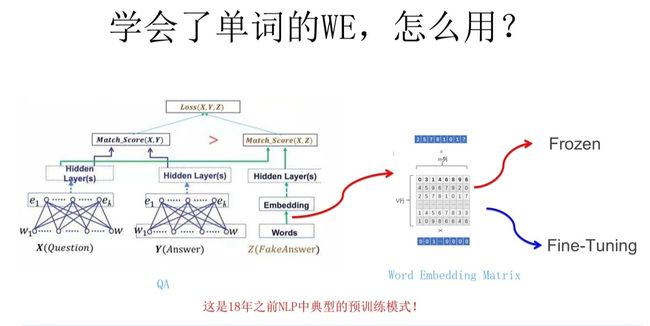
线性模型,主要是对高维空间进行映射,其实是对one-hot向量的空间转换。
-
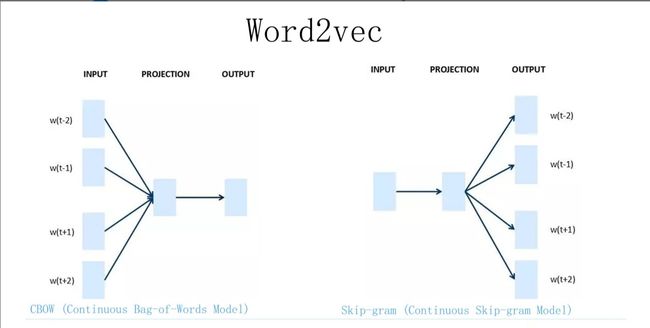
通过神经网络对输入的词进行映射,获取词向量,一般有cbow和skip-gram两种方法,此方法训练的词向量与上下文无关,并没有参考位置信息,只是对词的有无进行参考,采用的是负采样,预测的时候进行的是一个二分类器,模型认为只要在下文中找出正确的词就认为是完成了任务。
尚未解决一词多义等问题。比如多义词Bank,有两个常用含义,但是Word Embedding在对bank这个单词进行编码的时候,是区分不开这两个含义的,因为它们尽管上下文环境中出现的单词不同,但是在用语言模型训练的时候,不论什么上下文的句子经过word2vec,都是预测相同的单词bank,而同一个单词占的是同一行的参数空间,这导致两种不同的上下文信息都会编码到相同的word embedding空间里去。所以word embedding无法区分多义词的不同语义,这就是它的一个比较严重的问题。
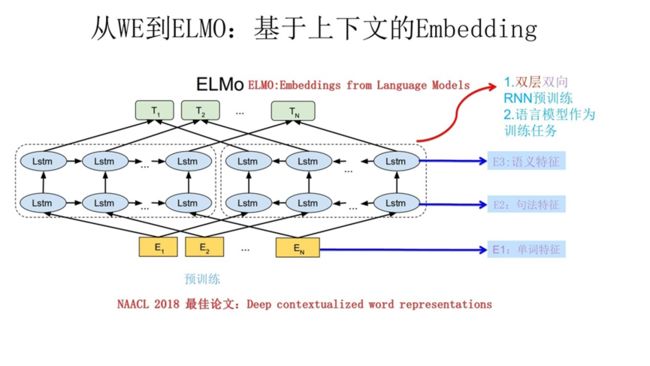
Embedding from Language Models(ELMO)
-
ElMO采用双向的LSTM做上下文相关的任务,从前到后和后到前分别做一遍LSTM的encoding操作,从而获得两个方向的token联系。
-
Word Embedding本质上是个静态的方式,所谓静态指的是训练好之后每个单词的表达就固定住了,以后使用的时候,不论新句子上下文单词是什么,这个单词的Word Embedding不会跟着上下文场景的变化而改变,所以对于比如Bank这个词,它事先学好的Word Embedding中混合了几种语义 ,在应用中来了个新句子,即使从上下文中(比如句子包含money等词)明显可以看出它代表的是“银行”的含义,但是对应的Word Embedding内容也不会变,它还是混合了多种语义。
ELMO的本质思想是:
事先用语言模型学好一个单词的Word Embedding,此时多义词无法区分,不过这没关系。在我实际使用Word Embedding的时候,单词已经具备了特定的上下文了,这个时候我可以根据上下文单词的语义去调整单词的Word Embedding表示,这样经过调整后的Word Embedding更能表达在这个上下文中的具体含义,自然也就解决了多义词的问题了。所以ELMO本身是个根据当前上下文对Word Embedding动态调整的思路。
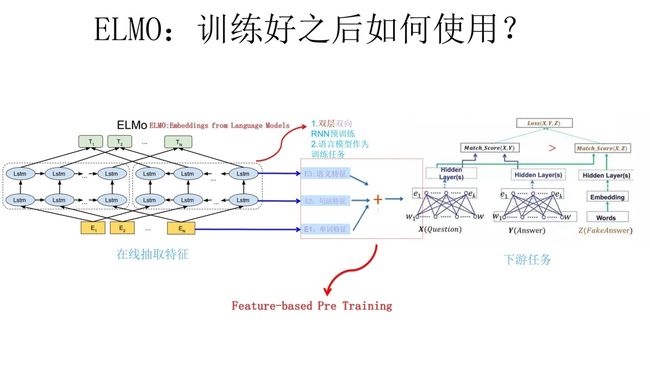
一样的,在具体进行下游任务的时候,采用神经网络参数微调的方法根据不同的词的上下文环境对词向量进行调整,从而得到同一词的不同向量表示。
缺点:
-
LSTM的抽取能力远远落后于Transformer,主要是并行计算能力
-
拼接方式融合双向特征能力偏弱
Bidirectional Encoder Representation from Transformers
BRET采用两阶段模型,首先是语言模型预训练;其次是使用Fine-Tuning模式解决下游任务。在预训练阶段采用了类似ELMO的双向语言模型,双向指的是对于预测单词的上文和下文是否参与,如果都参与预测那么就是双向,双向容易导致自己看自己的问题,后面提出mask来解决
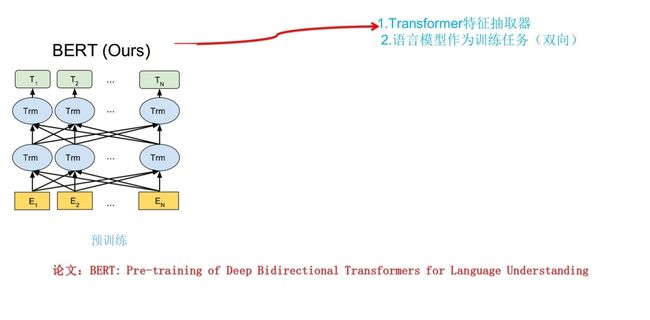
经过预训练的BRET模型,其已经具备了丰富的词向量特征信息,然后将此词向量信息与下游任务进行组合进行NLP下游任务,例如文本生成,文本分类。
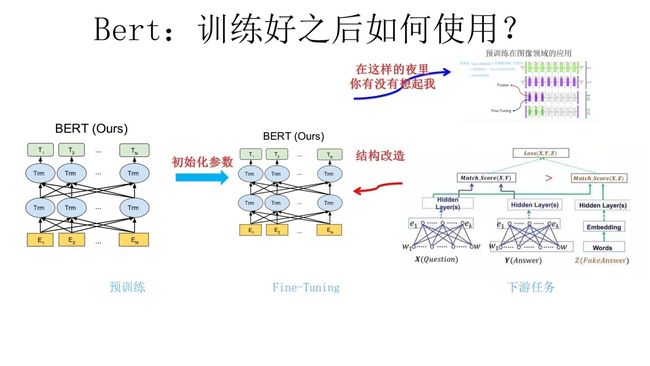
如何能够更好将BRET模型与下游任务进行改造是一个比较复杂的问题,再好的预训练语言模型都要与下游的任务模型相结合才有好的效果, BRET的优势在于可以自由根据预训练模型进行单词级别的任务和句子级的任务。
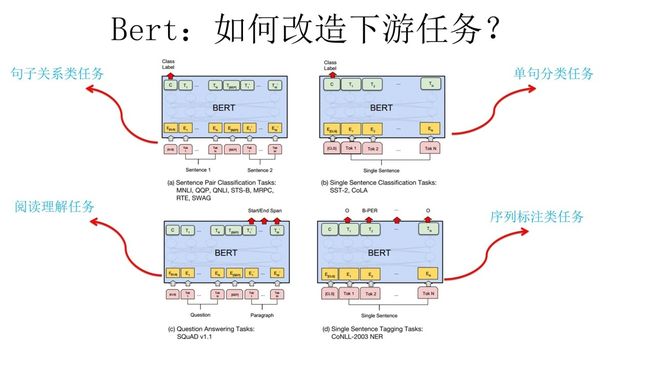
BRET模型的创新
就是论文中指出的Masked 语言模型和Next Sentence Prediction。而Masked语言模型上面讲了,本质思想其实是CBOW,但是细节方面有改进。
Masked 语言模型:
- 而Masked语言模型上面讲了,本质思想其实是CBOW,但是细节方面有改进,掩盖的同时,要输出掩盖的词的位置,然后用真实词来预测。
- Mask LM主要是为了增加模型的鲁棒性和实际性能,但是在训练时使用mask过多会影响实际任务的表现,所以做了一些处理:随机选择语料中15%的单词,把它抠掉,也就是用[Mask]掩码代替原始单词,然后要求模型去正确预测被抠掉的单词。但是这里有个问题:训练过程大量看到[mask]标记,但是真正后面用的时候是不会有这个标记的,这会引导模型认为输出是针对[mask]这个标记的,但是实际使用又见不到这个标记,这自然会有问题。为了避免这个问题, BRET改造了一下,15%的被选中要执行[mask]替身这项光荣任务的单词中,只有80%真正被替换成[mask]标记,10%被狸猫换太子随机替换成另外一个单词,10%情况这个单词还待在原地不做改动。这就是Masked双向语音模型的具体做法。

Next Sentence Prediction:
- 指的是做语言模型预训练的时候,分两种情况选择两个句子,一种是选择语料中真正顺序相连的两个句子;另外一种是第二个句子从语料库中抛色子,随机选择一个拼到第一个句子后面。
- 我们要求模型除了做上述的Masked语言模型任务外,附带再做个句子关系预测,判断第二个句子是不是真的是第一个句子的后续句子。之所以这么做,是考虑到很多NLP任务是句子关系判断任务,单词预测粒度的训练到不了句子关系这个层级,增加这个任务有助于下游句子关系判断任务。所以可以看到,它的预训练是个多任务过程。这也是BRET的一个创新,一般用于句级任务。

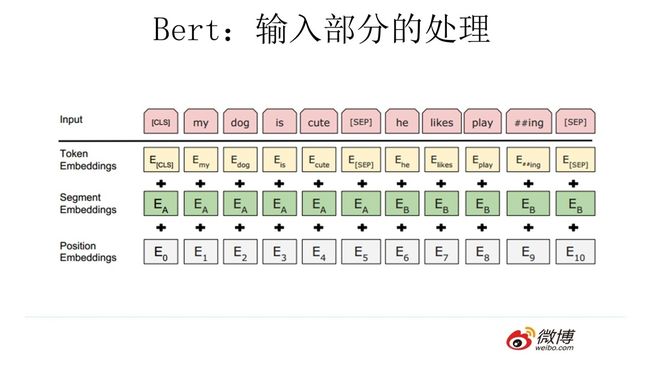
Transformer&BERT总结
-
首先是两阶段模型,第一阶段双向语言模型预训练,这里注意要用双向而不是单向,第二阶段采用具体任务Fine-tuning或者做特征集成;
-
第二是特征抽取要用Transformer作为特征提取器而不是RNN或者CNN;
-
第三,双向语言模型可以采取CBOW的方法去做(当然我觉得这个是个细节问题,不算太关键,前两个因素比较关键)。 BRET最大的亮点在于效果好及普适性强,几乎所有NLP任务都可以套用BRET这种两阶段解决思路,而且效果应该会有明显提升。可以预见的是,未来一段时间在NLP应用领域,Transformer将占据主导地位,而且这种两阶段预训练方法也会主导各种应用。