第三方库检测方法总结

库函数检测方法简要综述:
函数检测是一种二进制分析技术,将二进制代码分类为原始代码级别的函数相近的函数。用于二进制插桩、二值漏洞搜索、二元保护方案(包括流的完整性),以及帮助反向工程师分析代码区域间隔,推理复杂的二进制代码。目前的库函数识别技术中,主要包括白名单匹配方法、提取API级别的函数签名方法、字节码特征匹配方法、以及控制流图。
对于白名单匹配方法,最简单的是基于函数名字做匹配,但是由于函数名可以被轻易更改,因此不具有抵抗混淆的能力。函数名、参数名等可以被轻易更改,但是调用参数类型,返回值类型是不可修改的,因此,结合函数的这些固定的API特征,形成函数方法签名匹配方法。
Backes等人[1]提出了Pruned Method signatures,也就是对signatures在method级别进行必要的修剪。方法签名可以唯一确定这个函数,由方法名称和有序的参数列表组成。Backes等人在提取了方法签名后,去除函数名,参数名字用特定符号X表示,留下的列表是不可更改的方法签名,如下图所示:

得到修剪后的方法签名后,采用MD5将其hash成128位的比特串。这个bit值代表method级别的特征。但是我们要检测的库函数是一个package级别,一个package包含多个class,一个class包含多个method。于是利用Merkle trees将多个Method Hash集合再一次进行hash操作,形成class hash值,作为class级别的特征。
对于每一个已知的库函数名单,计算library中每个package的class级别的hash值,对于待测app,计算其package中的class级别的hash值。作者提出,对于library中的每一个package,若其class hash值能在app 的class级别hash值中找到相等的匹配,则匹配数目加1;最后匹配数目占library中class的百分比,则称为app所对应计算的这个package是库函数的得分。得分介于0到1之间,得分越接近1,说明被匹配数目越多,该函数是库函数的可能性越高。
![]()
字节码匹配方法被当前国内外研究机构进行研究。被广泛使用的IDA Pro使用的FLIRT技术就是字节码匹配方法进行库函数检测。其原理是,对于原生字节码,第一步提取函数开头的32个不变字节码,若有可变字节码则用特殊符号代替;第二步提取从第33个字节开始到之后第一个可变字节,并将其进行CRC16校验,记录其校验值和字节数。再加上外部符号引用等作为辅助特征,这些特征结合起来作为库函数的特征。这种方法的好处是,完全是基于二进制代码操作,与编译器、优化级别等完全无关。但是由于函数头的二进制字节码被修改后,此方法便无法很好地区分混淆。
控制流图方法与上面几种方法的区别是,其匹配特征深入到代码内部,而不仅仅依赖于函数名字或部分字节,并具有抗混淆性。Andriess等人[2]基于程序间的控制流图提出一个开源工具Nucleus。程序流图用一个有向图G=(V,E)表示,其中V表示反汇编代码划分出来的basic blocks;E表示块与块之间控制流的边E⊆V×V,也可表示basic block中程序间的控制流。目的是为了找到每个函数的入口点和函数边界。
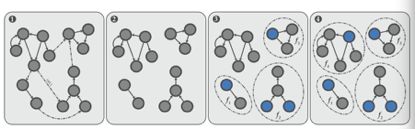
论文提出的方法首先对二进制反编译后的汇编代码进行basic blocks划分,以及根据控制流形成整个软件的控制流图,如上图图1所示。之后对汇编代码进行扫描,根据调用指令,如call指令,扫描到直接调用的函数,便可以检测到函数的入口块,那么连接入口块的调用边便可以擦除掉(调用边作为函数的连接点,不属于任何一个函数),如上图图2所示。接下来跟踪入口块的边缘知道形成一个完整的部件,圈起来就是一个函数,如图3所示。对于无法直接到达的调用函数,我们进行遍历基本块,找到还没拓展成函数块的基本块,通过连接分析,找到内部边不可达的基本块就是第一个入口点,再按照步骤3将其圈为一个函数块,如图4所示。如果还有没找到入口点的,默认函数从最低地址入口,最后可采用签名方法进行补充。这篇论文的方法优点在于支持不同编译器,能够顺利解决优化级别支持遇到的困难情况(非连续,多重输入)。最后评估476二进制文件,包括linux(ELF文件),windows(PE文件), gcc,clang,vs编译的二进制文件,涵盖x86,x64平台,优化级别从O0-O3级别不等。获得精确率0.96,召回率0.94,优于IDA Pro,Dyninst等检测技术。但是这篇论文仅仅实现了如何划分函数块,没有分析如何做库函数匹配,识别第三方库等问题。
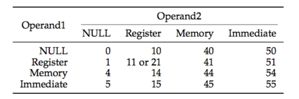
Qiu等人[3]提出简化执行流图Execution Flow Graph,把库函数检测看成是子图同构问题。与Andriesse相比,这篇论文能根据子图同构识别库函数。相似的,根据基本块出口对另一个基本块入口的依赖性,建立执行流图(EFG图)。每个EFG图,都将被转换为指令序列,相当于在保留语义的情况下重新调度块的指令。而每个指令,都将由一个ID表示,因此最终转化为一串ID序列。ID的构造方法如下:对于每个汇编指令,表示为一个二元组SR =(m,r),其中m表示指令助记符,如mov;r表示操作符的特征值。特征值根据操作数计算而得:先将操作数按照类型映射为数值,如下图所示:Null映射为0,Register映射为1,Memory映射为4,Immediate映射为5。r值就是汇编指令中两个操作数连接而得的特征值。例如mov eax,[ebx],的类型是mov register1,Memory,因此连接起来的SR值是(“mov”,14)。指令助记符m用于哈希操作的到一个32bit的整数,再连接到r值之后。例如(“mov”,14),mov的hash值是EBAC,因此最后的到的ID值为14EBAC。通过这样的操作,每个节点的指令转化为数值,更容易进行处理比较。
子图同构问题是不可解问题,本文将EFG图转换为ID序列,则可以通过比较ID序列来判断是否子图同构。如果两个EFG的ID序列不相同,那么这两个EFG不是同构的。反之不成立:因为一个ID序列可能对应多个EFG,如果两个ID序列相同,不一定EFG就是同构。因此,同一ID序列的判定方法是,建立Ordered Adjacency Matrix有序邻接矩阵(OAM),用0-1表示。相同ID序列的EFG图,如果其邻街矩阵相同,则EFG同构。然而:如果两个EFG同构,则它们的ID序列不一定相同,他们的OAM不一定相同。
匹配过程中,先反编译目标函数fT;采取在library函数列表F中去除不符合匹配条件的库函数,最后留下的则是匹配的函数。(1)去除指令数目与目标函数不对应的库函数。(2)去除library中比目标函数的basic block数目多的库函数;(3)比较每个basic block的长度,不符合匹配的库函数舍去;(4)建立目标函数和库函数的EFG,比较其对应的ID序列,与目标函数的ID序列不相同的库函数则舍去;(5)对于ID序列相同的两个函数,仍然要比较其OAM是否相同,不相同的库函数则舍去。最后library存留的则是与目标函数匹配的库函数。
很多技术采取从library列表中做减法操作,这样的检测技术工作量较大,但是Qiu等人提出的这篇论文,通过转换为ID序列,能节省一定的内存,也能将复杂的图比较转换为数值比较,但是其筛选速度仍需要考证。该文还针对EFG图提出一个简化执行流图的概念REFG,目的是去除函数头尾,保留函数主体,很大程度上也能加快运算速度。
Shiran等人[4]为了防止特征的特殊性和恶意软件的混淆,集合多个特征:CFG、指令级特征、统计特征、函数调用图多个特征,集合而得的特征为每个库函数生成一个特定的鲁棒签名,存储于B+trees中,有助于有效匹配。论文提出方法的主要步骤是,反编译,提取上述四个特征,采用互信息计算,选择最佳的特征子集,为每个函数构建特定的签名信息。排名靠前的特征被输入决策树,决策树的结果被存储在一个数据结构中,以形成每个库函数的签名。从目标二进制文件中提取特征,修剪搜索空间,最后返回一组候选函数,再用了最佳匹配得到最终结果。
CFG特征(Graph Feature Metrics)提取是从图中提取,比如节点的数量,边的数量,循环次数等特征;指令级别特征(Instruction-Level Features)包含反汇编函数的语法和语义信息,如retType用于描述返回的类型,此外,统计指令类别的频率也可作为一项特征;统计数据的特征(Statistical Features)使用公式计算操作码分布情况;函数调用图(Function-Call Graph)对指令级混淆更具有弹性,采用neighbor hash graph kernel (NHGK)应用于调用图的子集,这些子集包含库函数和它的邻居函数,也就是调用者和被调用者之间的联系。
收集特征后,采用互信息(MI)度量来表示特征X和库函数标签Y之间的依赖程度:
之后将决策树分类器应用于从特征排序过程中获得的排名靠前的特征,为每个函数创建一个签名,这个签名是特定的。反汇编后的库函数通过过滤器从存储库中获取一组候选函数。检测方法是采用目标函数和候选库函数的所有排名最靠前的特征之间最接近的欧几里得距离,由于可能无法满足处理数百万个功能的需求,采用B ++树,以有效地组织所有函数的签名,并找到最佳匹配。由于这样计算,最后的结果实际上是,在一组候选函数中找到与目标函数最接近的函数,即最后一定会筛选出距离相对较近的库函数。所以我认为可以对其进行改进,设置一个阈值,若是所有函数距离都小于阈值,则表示找不到相近的函数。
库函数检测大多数研究都是基于已知名单进行匹配操作。我认为上述多种库函数检测方法,可以划分为两大类,一类是静态检测,则基于函数签名,字节码特征等进行匹配;第二类是动态检测,通过运行得到控制流图,调用情况等作为特征匹配。而多特征则是动静结合,最终目的都是为了检测到库函数,服务于对应软件工程的研究。
参考文献
[1] Backes M, Bugiel S, Derr E. Reliable Third-Party Library Detection in Android and its Security Applications[C]// ACM Sigsac Conference on Computer and Communications Security. ACM, 2016:356-367.
[2] Andriesse D, Slowinska A, Bos H. Compiler-Agnostic Function Detection in Binaries[C]// IEEE European Symposium on Security and Privacy. IEEE, 2017:177-189.
[3] Qiu J, Su X, Ma P. Using Reduced Execution Flow Graph to Identify Library Functions in Binary Code[J]. IEEE Transactions on Software Engineering, 2016, 42(2):187-202.
[4] Shirani P, Wang L, Debbabi M. BinShape: Scalable and Robust Binary Library Function Identification Using Function Shape[M]// Detection of Intrusions and Malware, and Vulnerability Assessment. 2017:301-324.