哈希表系列:初探哈希,c语言实现
最初在阅读数据结构书籍时没有仔细看过哈希,潜意识认为太难了,应该用不到吧~但是,最近关注哈希表的原因是我在刷Leedcode时,有道题Two sum可以用哈希表求解,利用哈希特性“将庞大的数据进行压缩”,这就是哈希在处理大数据时的优势。
1、哈希表基本概念
哈希表(Hash table,又叫散列表),是根据关键码值而直接进行访问的数据结构。我在这里将其抽象为“数组+链表”的复合结构,所以在对哈希表进行建模的时候显得有些复杂。为什么哈希表能够提高查找的速度?我理解为1)它采纳了数组下标“快速访问”的特点,利用哈希函数对关键码值进行转换,来快速定位到具体位置,而不需要像链表那样从头结点开始一个个结点的遍历去查找;2)对数据进行了层次的划分。即哈希表的大小决定划分为多少层次。通过划分,有效减少了数据查找的量,加快了访问速度。
对哈希其他概念,这里不一一介绍,可以参照链接:点击打开链接。
接下来,主要介绍哈希表的实现。由于实现形式多样,这里重点介绍链地址法,哈希函数采用“除余法”。
链地址法的哈希表:
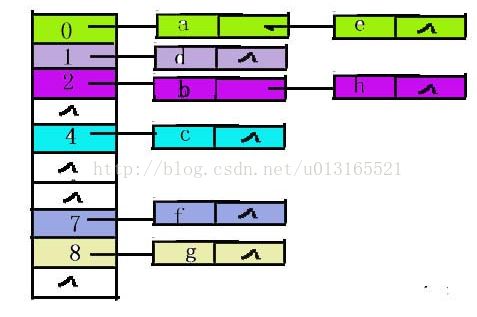
图片引自点击打开链接
2、哈希表的实现文件:
#include
#include
#include
#include
using namespace std;
typedef struct _node
{
char *name;
char *desc;
struct _node *next;
}node;
#define HASHSIZE 101
#define max 20
static node *hashtab[HASHSIZE];//全局变量
void initia_hash()
{
for (int i=0; inext)
{
if(!strcmp(p->name,s))
{
return p;
}
}
return NULL;
}
char* get_desc_pointer(char *c_name)
{
node *p=search_hash(c_name);
if(NULL==p)
{
return NULL;
}
else
{
return p->desc;
}
}
int create_hash_table(char *name,char *desc)
{
unsigned int hi=0;
node *p;
if( (p=search_hash(name))==NULL )
{
hi=c_hash(name);
p=(node *)malloc(sizeof(node));
if(p==NULL)
{
return 0;
}
p->next=NULL;
p->name=(char *)malloc(max*sizeof(char));
if (p->name==NULL)
{
return 0;
}
strcpy(p->name,name);
hashtab[hi]=p;
}
else
{
free(p->desc);
}
p->desc=(char *)malloc(max*sizeof(char));
if(p->desc==NULL)
{
return 0;
}
strcpy(p->desc,desc);
return 1;
}
void display_hash()
{
node *p;
for(int i=0; inext)
{
printf("%s %s",p->name,p->desc);
}
printf(" )\n");
}
else
{
printf("( )\n");
}
}
}
void delete_hash()
{
node *p, *t;
for(int i=0; inext;
free(p->name);
free(p->desc);
free(p);
p=NULL;
p=t;
}
}
}
}
int main()
{
char *name[]={"name","address","phone","k101","k102"};
char *desc[]={"LWJ","NINGBO","588222","value1","value2"};
initia_hash();
for(int i=0; i<5; i++)
{
if(create_hash_table(name[i],desc[i]))
{
continue;
}
else
{
cout<<"fail to create hash table\n";
}
}
// display_hash();
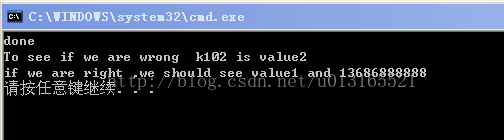
cout<<"done\n";
cout<<"To see if we are wrong ";
if(get_desc_pointer(name[4])!=NULL)
{
printf("k102 is %s\n",get_desc_pointer(name[4]));
}
else
{
cout<<"something wrong in function get_desc_pointer\n";
}
// printf("k102 is %s\n",get_desc_pointer("k102"));
create_hash_table("phone","13686888888");
printf("if we are right ,we should see %s and %s\n",get_desc_pointer("k101"), get_desc_pointer("phone"));
delete_hash();
return 1;
} 程序结果:
3、哈希表的改进
仔细观察上面,发现哈希表只有头结点,难道不能往链表后继续添加元素吗?
这里,本来想使拥有相同的哈希值的键值(key)用相同的链表链接。因为不同的字符串,经过哈希函数转换哈希值可能不同。所以为了简化问题,方便映射到相同的位置,采用相同的字符串进行实验。实验结果显示,最后相同的键值被成功构造成链表。
对上面程序进行稍微的改动,修改的函数如下。(记的屏蔽函数get_desc_pointer)
node* search_hash(char *s)
{
unsigned int hi=c_hash(s);
node *p=hashtab[hi];
for(; p!=NULL; p=p->next)
{
if (p->next==NULL)
{
return p;
}
}
return NULL;
}说明:对字符串进行映射,若是新的字符串则return null, 否则返回相同哈希值的链表的最后一个结点。
int create_hash_table(char *name,char *desc)
{
unsigned int hi=0;
node *p;
node *t;
if( (p=search_hash(name))==NULL )
{
hi=c_hash(name);
p=(node *)malloc(sizeof(node));
if(p==NULL)
{
return 0;
}
p->next=NULL;
p->name=(char *)malloc(max*sizeof(char));
if (p->name==NULL)
{
return 0;
}
strcpy(p->name,name);
p->desc=(char *)malloc(max*sizeof(char));
if(p->desc==NULL)
{
return 0;
}
strcpy(p->desc,desc);
hashtab[hi]=p;
}
else
{ //to add others in list having the same hash value
t=(node *)malloc(sizeof(node));
if(t==NULL)
{
return 0;
}
t->next=NULL;
t->name=(char *)malloc(max*sizeof(char));
if (t->name==NULL)
{
return 0;
}
strcpy(t->name,name);
t->desc=(char *)malloc(max*sizeof(char));
if(t->desc==NULL)
{
return 0;
}
strcpy(t->desc,desc);
//connect to node
p->next=t;
}
return 1;
}测试主函数:
int main()
{
char *name[]={"name","address","phone","k101","k102"};
char *desc[]={"LWJ","NINGBO","588239","value1","value2"};
initia_hash();
for(int i=0; i<5; i++)
{
if(create_hash_table(name[i],desc[i]))
{
continue;
}
else
{
cout<<"fail to create hash table\n";
}
}
display_hash();
create_hash_table("phone","13686888888");
create_hash_table("phone","15077890253");
create_hash_table("name","SunZhongShan");
display_hash();
delete_hash();
return 1;
}实验结果:

4、结论
这只是我对哈希表一点理解与认识,并作了对比实验记录与此,希望对希望了解哈希表的有所帮助。在此,顺便记录编程中的错误:if(p=NULL),最好写成if(NULL==p),易于查错,因为不然出现莫名的错误,耗时和让人崩溃。今天是端午节,时间2015.6.20,继续坚持,记录想法的美好瞬间。
奔跑吧~man!