视频中的3D人体姿态估计(3D human pose estimation in vide)--------Facebook research: VideoPose3D
视频中的3D人体姿态估计(3D human pose estimation in video)
解读Facebook AI Research in CVPR2019: 《3D human pose estimation in video with temporal convolutions and semi-supervised training》
这里写自sdsad定义目录标题
- 视频中的3D人体姿态估计(3D human pose estimation in video)
- Introduction:
- keywords
- Related Works
- Temporal dilated convolutional model
- Semi-supervised approach
- Trajectory model
- Bone length L2 loss
- Discussion
- Experimental Setup
- Dataset and evaluation
- Implementation details for 2D pose estimation
Introduction:
该文章创建了一个方法“将3D的姿态估计问题转化为2D关键点的检测问题“。然而,是否能将多个3D姿态完美映射成为同一个2D关键点一直以来都存在很大争议。
之前的方法通常是利用RNN网络对时间维度进行建模,例如:《Exploiting temporal information for 3d pose estimation》和《3d pose estimation based on joint interdependency》;
事实上,采用卷积网络同样可以达到对时间维度进行建模并且相较于传统的RNN网络效果也并不差,这其中就包括如:neural machine translation, language modeling, ** speech generation**, speech recognition等。而且,采用卷积网络的另一大优势是对于大量frames可以并行处理,这一点RNN网络无法做到。
基于以上结论, 该work提出了一个Temporal Convolutional Model, 该种结构接受2D keypoint sequences作为输入,最终输出3D pose extimation; 且该方法优势在于:
1. 兼容任意的2D Keypoint Detector;
2. 能够有效的解决large context(背景过大)问题 — 采用Dilated Convolutions
3. 就计算复杂度和参数量来说,比传统的RNN-based方法有同样量级的精度的同时更简单且更有效率
4. 采用“semi-supervised approach”, 可以更有效的处理训练集的标签稀少的情况 (和之前的semi-supervised方法不同,这里仅需要相机内参而不再需要实际的2D标注或者是带有相机外参的多视角图像),
之所以引进了新的半监督训练策略去利用未标记的视频,是因为对于需要大量标记的训练数据并收集用于3D人体姿态估计的标签的NN模型来说,低资源的设定情况尤其具有挑战性,这需要非常昂贵的动捕装置及相当长的信息记录采集工作
。
如下图 takes 2D key- point sequences (bottom) as input and generates 3D pose estimates as output (top), 中间结构为dilated temporal convolutions.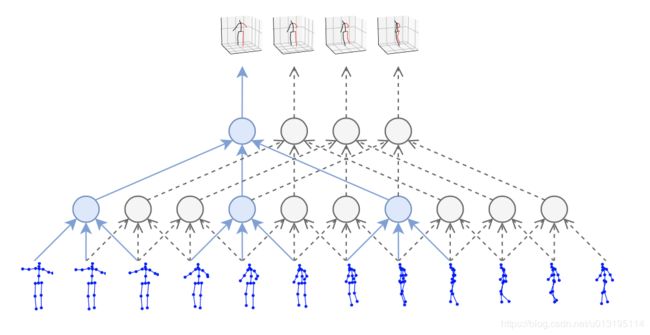
keywords
- Dilated temporal convolutions ---- to capture long-term information
- semi-supervised training ---- to leverage unlabeled video data
- intermediate supervision -----中间监督
出自于《Stacked Hourglass Networks》https://zhuanlan.zhihu.com/p/65123312;【作用】:如果直接对整个网络进行梯度下降,输出层的误差经过多层反向传播会大幅减小,即发生vanishing gradients现象。为解决此问题,在每个阶段的输出上都计算损失。这种方法可以保证底层参数正常更新
Related Works
传统大多数的3D姿态估计都是基于特征工程和对骨骼于关节运动的假设【48,42,20,18】,最早基于CNN的方法主要是通过无需中间监督直接从RGB图像预测3D姿态的端到端的重建来进行3D姿态预测【28,53,51,54】
- Two-step pose estimation
- 新的一类3D pose estimators, 构建于2D pose estimators之上,通过先在图像空间(keypoint)预测出2D关节点的位置,再将结果提升到3D的空间【21,34,41,52,4,16】。 该方法就是采用了中间监督模式,效果比端到端的方法更好。且有文章证明是:针对ground-truth 2D keypoints, 直接预测3D pose相对更简单直接, 而准确预测2D pose会更困难【34】。
- 早期的方法是简单的采用KNN方法是从一个大的2D关键点的集合中搜索得到一组预测2D keypoints,然后简单的输出对应的3D pose。 一些方法采用图像特征记忆以及2D ground-truth poses【39,41,52】, 或者可以从给定的一组2D关键点来简单地预测其深度信息,进而得到预测的3D pose【58】。
- Video pose estimation
- 很多之前的方法是在单帧图片上进行3D pose estimation, 而近年来的一些研究开始把目光转向如何从视频中探究时域信息从而产生鲁棒性更好的预测,减少对噪声的敏感【53】。涉及基于时空域体积的梯度直方图(HoG)特征
- 双向LSTM也一直是用来修正/精调从单帧图像上预测得到的3D pose的结果
其中最成功的方法是从2D关键点的运动轨迹(2D keypoint trajectories)中进行学习, 本文也是基于此方法。
- 最近提出的"LSTM sequence-to sequence"learning model可以将视频中1组2D pose序列进行编码为一个固定大小的向量,然后解码成为3D姿态序列【16】。但是该方法的输入和输出序列具有相同的长度并且2D pose的确定性变换是更自然的选择。实验了这中seq2seq模型发现输出序列趋向于在冗长的序列上飘移。处理这种问题是以牺牲时间上连续性为代价,通过每隔5帧重新初始化一次encoder来解决。考虑到首先要保证肢体部分的连续性,这种解决方法也被用于基于RNN的方法。
- Semi-supervised training
- 一直被用于多任务网络【3】来预测2D关节点及3D姿态,以及动作识别。有一些实现将从2D姿态预测的特征迁移至3D的任务中【35】。
- 通常未标注的多视角录像被用于3D姿态预测的预训练表示上, 但是这些录像无法被用于无监督学习。
- 当只有2D标注数据集的情况下,可以使用GAN从第二个数据集中的非实际的姿态中来判别得到实际姿态【56】,如此提供了一个有用的正则化形式【54】; 使用GAN从未匹配的2D/3D的数据集中学习,并且包好一个2D投影一致性项。
- 类似的,对经过随机投影操作转换为2D结果的生成3D poses数据进行判别【8】
- 还有像【40】这样提出一种弱监督学习方法,基于序数深度(ordinal depth)注释,这利用一个带有深度对比信息的2D pose数据集,例如:“左腿位置在右腿之后”
- 3D shape recovery
- 和精确3D pose重建领域并行的一个领域是从图像恢复人体完整3D形态的研究【1,23】。这些方法都是基于参数化的3D网格同时姿态精度对其并不重要
- Our work
- 不同于以上的方法,比较【41,40】,本文并没有使用热力图(heatmap)而是使用检测的关键点坐标来代替Pose。这样一来就可以在坐标时序上使用1D卷积,来代替在单独的热力图上使用2D卷积操作(或者是在热力图序列上使用3D卷积)。因为heatmap虽然可以传递更多信息但是需要更大的2D卷积(考虑时间维度就是3D卷积)。并且计算量和准确率取决于heatmap的分辨率。
- 本文提出的方法同样使得计算复杂度和关键点的空间分辨率不相关。
- 本文提出的模型能够在只有较少的参数的同时达到很高的准确率,并且能够快速的训练和运行;和【34】提出的单帧baseline及【16】提出的LSTM模型做对比,本文在时间维度上利用一维卷积操作探究了时域信息,并且提出了几种优化方法得到了更低的reconstruction error。和【16】不同的是, 本文采用确定性映射(deterministic mapping)来代替seq2seq模型
- 最后,本文发现了对于3D人体姿态预测来说,使用Mask R-CNN和CPN(级联金字塔网络)的检测器鲁棒性更好。这一点结论和之前提到的那些two-step模型(采用stacked hourglass network来做2D关键点检测)正好相反。
Temporal dilated convolutional model
文章中提出的模型是一个全卷积结构且带有残差连接,其采用一个2D的姿态序列作为输入,通过时域卷积进行变换操作。之所以这样做是因为RNN无法并行处理时间序列,而卷积模型就可以并行处理所有batch的2D姿态信息和时间维度信息。
在卷积模型中输入输出之间的梯度路径都是一个固定长度,而不论序列本身长度的大小,这样可以有效的减少梯度消失/爆照的风险(相较于RNN)。此外,卷积结构对时间维度的感受野有精准的控制,这有利于3D姿态预测模型的时间依赖性。再者,采用扩张卷积对长时间的以来建模,同时保持了效率。类似的结构在音频生成/语义分割/机器翻译/上的取得了不错的结果。

上图即文中提到的全卷积3D姿态预测结构的一个实例:
- 输入:243帧(B = 4 blocks)的2D关节点的感受野,每帧有J=17个关节点
- 绿色部分为卷积层:
2J:2 x J个输入通道
3d1: 卷积核Kernel size = 3, dilation = 1
1024 : 输出通道数为1024 - (243,43):代表一帧的3D预测需要(243, 34)输入,代表243帧和34个通道。
整个预测结构还对残差进行了切分操作(slice), 来匹配卷积操作的的tensor。
上面整个架构,将每帧的J个关节点的坐标(x, y) 做concat后作为输入项, 传入时域卷积(kernel_size=W; channels=C),然后应用B个残差网络风格的残差块 , 来形成一个skip-connection(跳层连接);每个残差快执行1D卷积操作(kernel_size=W;Dilation factor: D=W^B), 接着进行1X1的2D卷积操作,并且除了最后一层,每一层的人1x1卷积操作后都要做一次BatchNorm,RELU和Dropout操作。 这样一来, 每个block都通过参数W,进行了感受野的指数倍放大,同时新增的参数量只是线性的增长。超参数W和D的设置目的是使得感受野对于任意输出帧都是一种树状结构。最后一层输出包含对输入全部帧的3D姿态, 同时考虑了future和past的时间信息。(通过因果卷积(只对过去的信息进行卷积)来试验以上结构在实时场景的效果)
Semi-supervised approach
引入半监督训练方法是为了在没有足够的3D ground-truth姿态数据的标签的时候尽可能提高预测准确率,因为实际3D姿态预测的标注非常困难。利用现有的2D姿态检测器和unlabeled视频,将back-projection loss加入到supervised loss中。
关于解决unlabeled数据的自动编码问题:encoder执行从2D关节坐标信息得到的3D姿态预测结果, 同时decoder(projection layer)把3D姿态反响映射回2D关节坐标, 然后对decoder输出的2D关节坐标与原始输入坐标的误差做重建损失计算

如上图所示, 带有一个3D姿态模型的半监督训练采用了一个预测的2D姿态作为输入,通过对人体3D运动轨迹做回归并且增加了一个soft-constraint来将unlabeled预测的骨骼长度的平均值对应匹配到labeled的数据中。并且所有的都放在一起做训练,其中的“WMPJPE”代表带权重的MPJPE
从上图可以看到,该方法包含一个监督部分和一个非监督部分(充当正则化),并且这两个对象是联合优化的:labeled数据占据一个batch的前半部分,unlabeled数据则占据一个batch的后半部分。然后,采用ground-truth 3D姿态作为训练目标去训练labeled数据来得到一个supervised loss; unlabeled数据则被用于训练autoencoder loss;用来约束把3D姿态投影回2D的过程,然后检查它的输入的连贯性。
Trajectory model
根据透视投影的原理, 屏幕上的2D姿态都取决于运动轨迹(空间中人体root joint的全局位置)以及3D姿态(人体所有关节相对于root joint的位置)。这里,如果没有全局位置,物体则会永远被以一个固定的scale重新投影到屏幕中央。因此,对人体的3D运动轨迹做回归,可以使其正确的投影回2D。为此,本文又花了第二个网络来在camera space中回归全局的运动轨迹。后者再被投影回2D之前被添加到3D姿态。这两个网络拥有相同的结构但是不共享任何权重,因为,本文发现在进行多任务训练时两者会互相产生负面影响。因为随着目标物体逐渐远离camera的时候,想要回归得到精确地运动轨迹变得愈加困难,所以这里为运动轨迹引入了一个带权重的平均每个关节点位置误差损失函数(WMPJPE loss):
E = 1 y z ∣ ∣ f ( x ) − y ∣ ∣ E = \frac{1}{y_z}|| f(x) - y || E=yz1∣∣f(x)−y∣∣
即, 对每一个样本给定一个camera space的ground-truth深度 y z y_z yz的倒数作为权重。 因为对处于很远处的对象做回归得到精确地运动轨迹不是目标,因为这样对应到2D上的关节点会集中在一个很小的区域。
Bone length L2 loss
采用激励方式去预测大概的3D姿态要比单出的复制输入要更加合理。为此,如上图,文章发现: 对labeled batch中的目标对象,增加一个soft constraint来大概的匹配平均骨长度更加有效。这个操作在自监督的训练中作用很大。
Discussion
上面提出的方法仅需要相机内参即可:focal length/focus/distorsion factor; 此方法不需要一个特定的网络结构,并且能够应用到任意一种采用2D关节点作为输入的3D姿态detector。实验中,采用了时域空洞卷积模型来讲2D姿态映射到3D。为了再讲3D姿态映射回2D,文章采用了一个简单地投影层(考虑线性参数:focal length/principle point以及非线性参数:tangential/radial), 观察到非线性项(镜头畸变)对于数据及Human3.6M的姿态预测矩阵影响很小,但我们还是把这写因素考虑进来,目的是为了增加模型的准确性,使其更加能经确定描述真实的相机投影过程。
Experimental Setup
Dataset and evaluation
共两种动捕数据集:
- Human3.6M — 共包含11个目标对象的360万帧图像,其中7个对象对3D姿态做了标注。每个对象都使用了4部50Hz的同步相机分别记录了其15种动作姿势。同时,采用了与之前一样的17个关节点的骨架模型,并对其中的5个关节(S1/S5/S6/S7/S8)进行了训练,对其中2个关节(s9/S11)做了测试验证。最终训练得到一个覆盖所有姿势动作的单独的模型。
- HUmanEva-I — 相比于Human3.6M,该数据集小很多,仅包含使用了3台60Hz的相机采集的三个目标对象。文中针对每个姿势动作训练了不同的模型,并依次测试评估了三个动作(Walk/Jog/Box)。 采用15个关节点骨架模型已经划分好的训练/测试集来针对所有动作训练一个统一的模型。
- 以上的实验中, 主要考虑了3个评价规则:
-
protocol 1 :毫米级的平均关节点位置误差 (MPJPE) 就是 预测关节位置和ground-truth关节位置的平均欧氏距离; -
protocol 2 :通过平移/旋转/缩放(P-MPJPE)与ground-truth刚性对齐产生的误差; -
protocol 3 :在半监督实验中,尽在scale(N-MPJPE)上讲ground-truth姿态和预测姿态对齐
Implementation details for 2D pose estimation
之前的绝大多数工作都是从图片中提取人体ground-truth bounding box,然后在这个实际的边界框范围内应用stacked hourglass detector来预测2D关节点位置。本方法则不依赖任何特殊的2D关节检测器,因而探究了一些没有经过ground-truth边框标注的2D检测器,来让他们应用本实验方法:例如, 骨干网络是ResNet-101-FPN的Mask R-CNN,把它的参考实现用在Detectron,以及CPN(作为FPN的扩展)。CPN需要提供人体bounding box。