Attention is all you need 代码笔记
主要依据:http://jalammar.github.io/illustrated-transformer/
写作原因:文章太长,我必须总结做笔记。也可以认为是翻译,但是没有原文详细(应该)所以有那里卡主,过不去,就去看看原文相应的地方。严格来讲我这个不能算做翻译。
问题简述:利用attention机制进行语言翻译(可并行,不用RNN)。
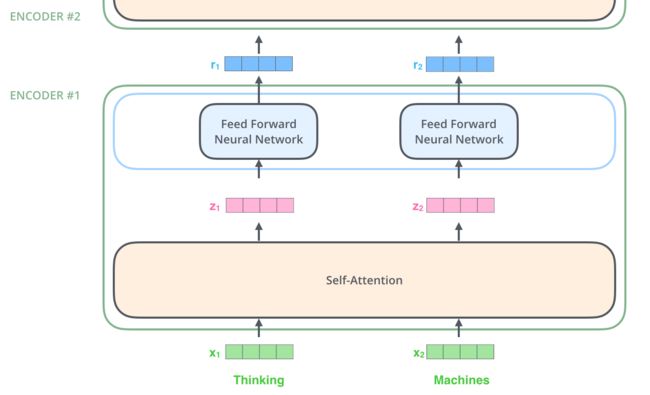
Self attention
embedding
embedding 后每个词被表达成了512的向量,在图中由绿色的四个方块表示。关于embedding,这里没有展开讲,但是不是重点,为了时间,仅仅了解其将文字变成编码即可。
self attention 特性
这里每个字被独立处理,可以并行处理,显而易金传统的RNN是用state状态记录之前走过的字的,这里为了能并行,没有这种顺序记录,上下文语义。(本篇博客只是学习笔记,所有图片的权利都属于Jay Alammar。)
原文说:
“The word at each position passes through a self-attention process. Then, they each pass through a feed-forward neural network -- the exact same network with each vector flowing through it separately.”
目前理解,这是说用的一个权重以及网络结构,但是实际操作中是数据并行的,类似于大家用了一模一样的卷积核。由于不确定,我先变个色
没有context肯定是不行的。于是就用self attention来弥补。
self attention直观理解
下面就来说说这个self attention,在第一层大家还是那个原始的词的时候,主要是计算别的词和我有多大关系,比如对于语句:
“The animal didn't cross the street because it was too tired”中的it,和其他词的关系,可以具体的画出来,颜色越深,说明越高,可以看到 The animal是最高的两个词。

基于这样的需求,可以看出,对于it来讲,需要对所有的单词 The animal didn't cross the street because it was too tired 生成权重。所以下面就是生成该权重的方式。
self attention具体实施方法
对每个字配个Q向量,K向量,V暂时别管。Q长度为64,长度由三个方块代表。可以理解为:我就想问问你和我什么关系。K也是64,可以理解为:我将我的所有特征表达成K,你可以用你的Q理解一下我的K,评价一下我对你有没有用.
这两个重要的向量生成方式是X1*WQ = q1就是做个矩阵乘法,同样的可以用k1 = X1*WK来确定k1.这里没有说矩阵WQ,WK,WV怎么来的,只说了他怎么被用的,实际上这些矩阵的内容正是我们需要训练的参数。

自然而然的根据上面定义的Q,K向量的作用,单词Thinking关于Machine的权重是个常数,该常数可以通过q1*k2计算,这里用的是点乘,就是向量内积。

然后为了得到更加稳定权重,将q1*k1/8 作为权重,也就是112/8 = 14.为了能够得到归一化的权重,用softmax可以得到比例,如下图所示:

下面再说这个value 向量v1,得到他的方法也是将X1*Wv得到,至于这个东西的作用,就是朴实的value,既不接待外宾(Q),也不拿出去给别人做运算(K)。
上面这一串的介绍最终是为了得到self attention的输出。接下来就介绍这个。
对于Thinking这个词来讲,他将考虑两个词的value(因为整个词库也就Thinking 和 machine),通过考虑他们的在之前求得的归一化权重0.88以及0.12来得到经过self attention层的输出。
Thinking_output = 0.88*v1+0.12*v2
将上一节的self attention处理成更快的矩阵操作
还是以两个词作为例子,绿色的是embedding之后的特征表示,还是512维度:
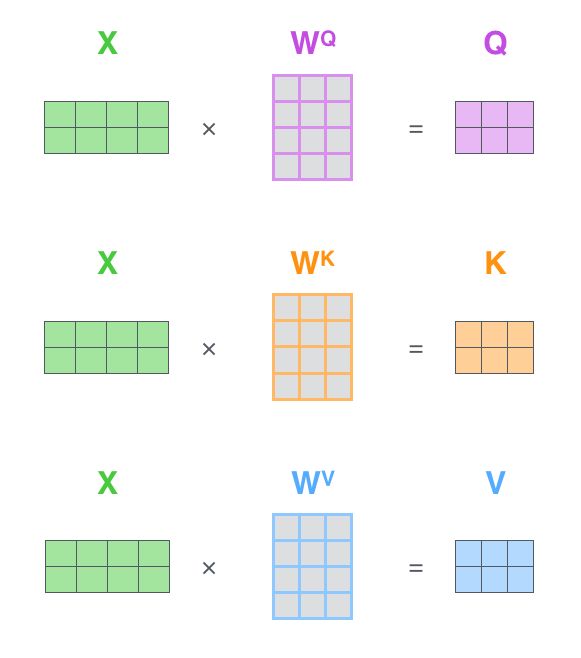
图 1 矩阵相乘解法
那么计算V也是同样的,这里一张图片就够了,眼熟这个Z,就是self attention的output。以前也是粉色的,就是没图。。。

图2 self attention输出就是矩阵Z
进化“multi-headed” attention
论文中说可以从两个方面改进self attention。
1.看到单词Thinking给自己的权重是0.88,但是对于一些任务比如:
“The animal didn’t cross the street because it was too tired”要知道it指代的是什么(答案:The animal)
并不利于找到The animal,因为会被it主导。所以multi-headed可以给不同的位置关注。
2.对一个词,可以配备好几套图1中的Q,K,V,比如两套的话,示例:

那实际上是几套呢?8套。每套都代表了一系列的输出,不过这样我想,如果比如你有5层attention,那么8*8*8*8*8,我是这么想的,原文没说,先放着。(这个不要信啊,就是个猜测)
将输出融合,比如你真用了8个QKV,然后你就有八个粉色输出:

但是feed forward不需要八个输入,所以需要将其融合。如果你和我有一样的疑问,那么此时就明白了,没有对应的8个feed forward的权重,就一个,所以需要融合z0,z1,z2,...,z7.
融合方法非常简单,就是concatenate 然后直接乘一个矩阵W0回到2*64大小(三个格子代表64 没忘吧)这个矩阵W0大小:列标号 (0,511),由四个格子表示。行标号(0,64*8)由24(3*8)个格子表示,不信你数数。这个矩阵里面的参数也是训练出来的。这样出来的维度就是(2*512)

然后辛勤的小天使Jay又将上面分散的multi-head attention过程梳理到了一张图上,注意这里的绿色的是embedding好的向量,也就是说,attention仅仅是个工具层,不具有上述任何attention福利!

图三 总流程
直观上看multi-head attention
用两个QKV来看刚才的句子,可以看到,关注点一个是The animal,一个是 tired。比较合理,这个东西是animal,他的状态是累了。

考虑单词顺序
目前依旧没有顺序,可以看出来,依旧是不考虑单词谁先谁后的问题。谁先谁后,说到底是个单词位置问题,在考虑位置的同时,要保证并行。给了精确的位置,机器能不能推出顺序?从信息角度来讲,能。那用位置来替代RNN中的顺序就没问题。
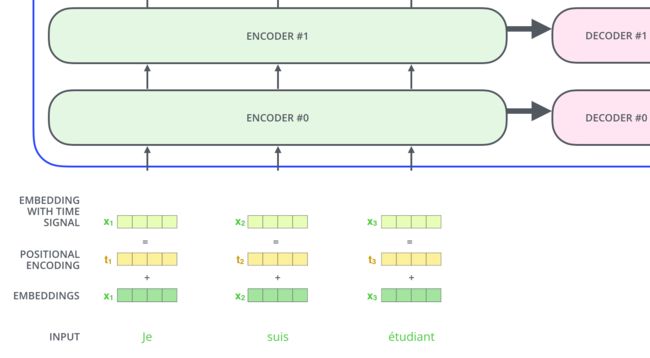
定下了要用单词位置,两个问题:一个是位置t(图中黄色向量,长度512)怎么传,一个是attention怎么用位置t。
下面这张图就是将t用于embedding,用的是加法,生成了一个伪时间信号。就是嫩绿色的四个方块,embedding with time signal。
目前还有很多没有说明白,先看下到底t长什么样:
t=positional encoding
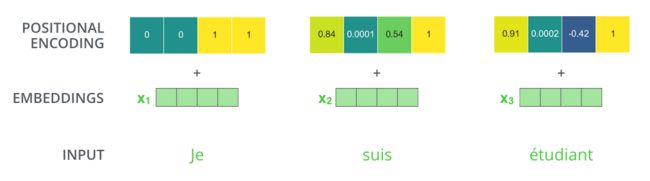
如果有20个词,512的length,向量维度,那么生成20行,512列的矩阵,就是下图:

“A real example of positional encoding for 20 words (rows) with an embedding size of 512 (columns). You can see that it appears split in half down the center. That's because the values of the left half are generated by one function (which uses sine), and the right half is generated by another function (which uses cosine). They're then concatenated to form each of the positional encoding vectors.”
左边用的sine函数生成,右边是cosine函数,之后将这两者concatenate。
这个部分没有公式,所以我不能确定。但目前看来,是设置了一个张量,与实际单词embedding后的张量相加的。
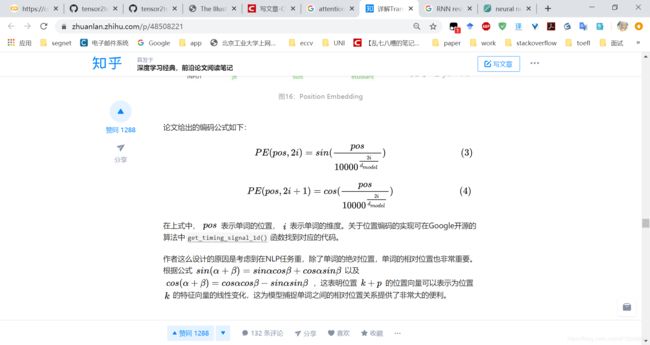
后来到知乎找到了公式,如下图所示,在目前position确定后,sin(pos) cos(pos)都是常数。
残差
残差块在CNN中异常好用,self attention也用了normalize,我是做CNN的不太清楚residual(残差)以及batch normalization(BN)在NLP里面的应用情况,不好评价其价值,不过可以肯定,这两在CNN中异常好用。在CNN中BN是基于batch的,这里没有提到batch,可能仅仅是对一个简单的数据,比如输出的是2*512的张量,对两个样本做,我猜字越多越准。
这里要先介绍残差,首先是原创何凯明等人设计的残差:

很简单就是本来经过两次权重层(weight layer),得到F(x),但是残差将两层之前的输入x也用上了,所以两层之后输出的是F(x)+x。
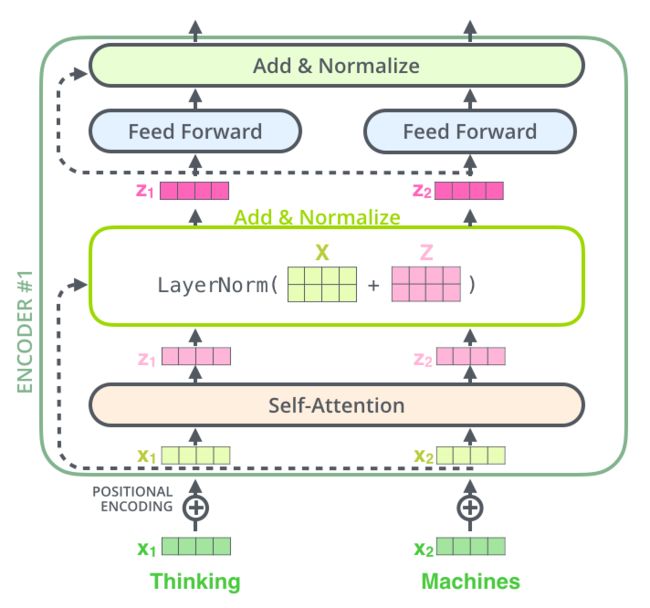
用于attention的话,是在self attention之后增加一个Add & Normalize 层,图中将该层细节画了出来。self attention其实有两个权重层的乘法,可以回顾下图三,总流程,第一个参数矩阵是八个(WQ,WK,WV),生辰了一些特征向量,之后将特征向量进行concatenate,然后进行融合使用矩阵W0,所以我说是两个权重层。至于残差使用两个权重层的原因,是因为两个权重层能够模拟任何的函数,我认为。
然后仔细看下图中的BN和加法的关系,是先相加再做Normalize。
对于整个网络而言,残差过程如下图所示,两个encoder,两个decode,最后一个encoder#2的输出给了decoder#1,decoder#2,并且都给了Encoder-Deocder Attention这里。这是普通CNN网络没有的,注意看decoder#1的self-attetion哪里的虚线,这个对残差的用法倒是和encoder一致。
那这个Encoder-Decoder Attention的具体结构什么样,这里还没说

encoder decoder结合
下图在原博客是动图,可以去自己看。decoder阶段用到了encoder的K以及V的张量,也就是value和key.

图4 decoder利用 K,V张量
之后该博客展示了全部的过程,在decode阶段还是有顺序的,这个过程是动态的,decoder时,会用到上次decode的输出(该单词的embedding)以及time signal

decoder的self attention
decoder的与encoder的不一样。在decoder阶段由 je suis etudiant 德语的我是学生翻译成英语的 i am a student在生成a的时候需要am作为输入,那么是不考虑后续的student的,因为他还不知道后面有啥。所以在做attention的权重的时候,权重就是(4,6,-inf,-inf,-inf,....)设置为负无穷,然后再用softmax,这些值就会变成(0.4,0.6,0,0,0,....)了。
Encoder decodet attention
“The “Encoder-Decoder Attention” layer works just like multiheaded self-attention, except it creates its Queries matrix from the layer below it, and takes the Keys and Values matrix from the output of the encoder stack.”
也就是说,Encoder-Decoder Attention其实就是一个multiheaded self-sttention,只不过它必要的三个张量矩阵(不是权重矩阵,两个单词的话,大小是2*64)Q0,K0,V0他们的来源与encoder阶段不同,不是由权重矩阵(WQ,WK,WV)生成的,Q0,来源于前一层,K0,V0来源于encoder,如图4所示。下面回放一下encoder过程,注意图中画法,填充色灰色边缘是彩色的那个是WQ,填充是彩色的是输出Q0.
线性层和softmax层
注意到下图中网络最后会经过linear 和softmax:
linear层
是一个全连接层,可以将512的vector'映射到10000维度。主要是由于你翻译出来的东西也有一个词汇表。比如英文单词可能有10000个常用词汇,你总不能说,因为我就是 i am a student来什么德语我都用 i am a student 表示吧,那也太人工智障了。。。
所以,对于‘am’来讲,linear层出来后(0.1,2,66,3,7,...)总共10000维度,第三维是最高的。
softmax层
将(0.1,2,66,3,7,...)softmax,使其加起来为1,则得到(0,0.01,0.7,0.05,0.11,.......)
然后查找第三维对应的单词,可以得到 ‘am’,这就翻译出来了。图片也是这个意思,自己看吧。

损失函数
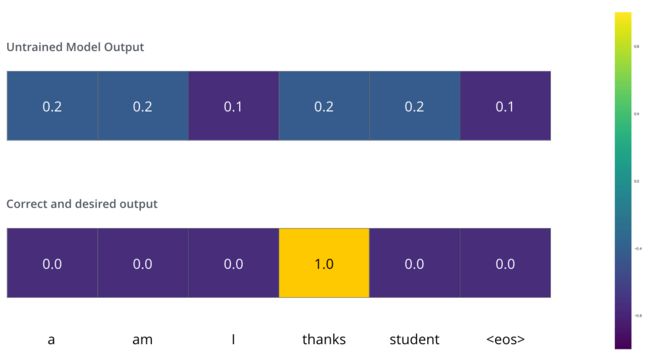
如果输出的单词错了,肯定是要计算损失然后梯度下降的。下图六个词,一般结束符号也算一个词,然后就可以将softmax后的vector argmax得到最大维度,和onehot进行对比。

比方说下图中第一行是真实地输出,第二行是Ground truth。:
“For example – input: “je suis étudiant” and expected output: “i am a student”. What this really means, is that we want our model to successively output probability distributions where:”
计算损失用的是交叉熵,是衡量分布的距离(cross-entropy and Kullback–Leibler divergence.),比如ground truth其实如下图所示是个分布:

那么如果训练好的模型输出的是:

单词选择测略
1.greedy decoding: 直接argmax比如position#1 argmax=2,于是确定这个位置是“I”。
2.beam search : 这个方法有个参数,beam_size,比如position #1,使用beam_size=2,最大第二维0.93,第二大在第四维0.03,原话是:
“hen in the next step, run the model twice: once assuming the first output position was the word ‘I’, and another time assuming the first output position was the word ‘a’, and whichever version produced less error considering both positions #1 and #2 is kept.”
也就是训练时分别对第四维,第二维算一次损失,选损失最小的那个维度。
这样的话我觉得训练速度会变慢,因为你要算两次,而且取第二大,不能将实际的损失递归回去:因为在测试时只能使用greedy