聊天机器人技术分析综述
研究背景及发展现状
1950年图灵(Alan M. Turing)在《Mind》上发表文章《Computing Machinery and Intelligence》,文章开篇提问“机器能思考吗?(Can machines think?)”,并且让机器参与一个模仿游戏(Imitation Game)来验证“机器能否思考”,进而提出了经典的图灵测试(Turing Test)。自此,人类进入了聊天机器人的研究时代。最早的聊天机器人ELIZA诞生于1966年的麻省理工学院的约瑟夫·维泽鲍姆(Joseph Weizenbaum)之手,主要用在临床医疗中模仿心理医生。尽管ELIZA的实现技术仅为关键词匹配和人工编写的回复规则,但为聊天机器人的发展奠定了不可磨灭的基础。
经过半个多世纪的研究与分析,聊天机器人取得了飞速发展。
近年来,聊天机器人系统层出不穷,大致分为开放领域的以娱乐,个人助理等为主的无目标驱动型聊天机器人,封闭领域的以技术支持,购物系统,在线客服等为主的目标驱动型聊天机器人。因为用户不一定有明确的目标或者意图,他们可以谈论任何方向的额话题,无数的话题和生成合理的反应所需要的知识规模,使得开放领域的聊天机器人实现起来更有难度。其中,最具代表意义的如个人助理苹果siri和jd的JIMI客服机器人。
聊天机器人系统结构
通常来说,聊天机器人的系统框架如下图所示,包括5个主要的功能模块,语音识别模块主要负责将用户语音输入转换成文字并交由系统进行下一步分析,自然语言理解模块主要用来进行词义,句义分析以充分理解用户意图,并将特定的语义表达式输入到对话管理模块中,对话管理模块负责协调各个模块的调用及维护当前对话状态,选择特定的回复方式并交由自然语言生成模块进行处理;自然语言生成模块生成回复文本再次经过转换成语音输出给用户。
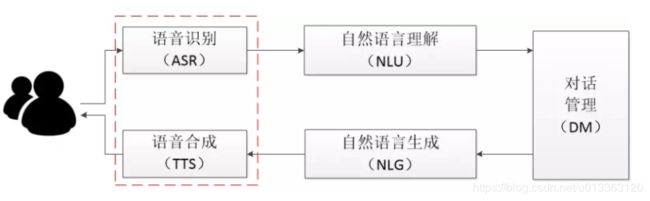
本文主要介绍基于文本输入的聊天机器人即智能客服,
聊天机器人关键技术
目前针对聊天机器人的研究主要采用基于检索(retrieval-based)的方法和基于生成(generational-based)的方法。
检索模型是使用预定义相应的数据库和各种启发式推理来根据输入和上下文选择适当的响应。其中启发式推理可以基于规则的表达式匹配,或机器学习中的分类器集合。在这种模式下,机器人回复的内容完全出于一个对话语料库中,该数据库不要求生成任何新的文本,只是从符合要求的集合中挑选一种回复,手工打造的数据库不会产生语法错误,但无法处理没有预定义响应的场景,出于同样的原因,这些模型不能应用上下文实体信息,且这种方式要求语料库的信息尽可能丰富完整,这样才能更加精确地匹配用户内容,并且输出也应该高质量。除此之外,人工完成规则和模式的指定也是十分耗时耗力的。
生成模型在接收到用户输入后,会采用相关技术生成一句回复,作为输出。该模式下的机器人采用学习的方法进行对话数据和规律的学习,很好地规避了基于规则模式下机器人的缺点,但这些模型很难训练,而且可能会有语法错误,需要合适的模型训练大量的数据。
当今的大部分生产系统采用检索的方式实现,或者采用检索和生成相结合的方式进行。我们将文本机器人系统进行拆解,如下图,不难看出,一个复杂的聊天机器人主要涉及到意图识别,Q&A匹配过程。其中,意图识别可看作多分类任务,进行词义分析,语义分析,上下文分析后,采用SVM。随机森林,决策树,以及神经网络等方法。当明确理解用户意图后,我们可以在相关分类中,通过关键词匹配获取相应回答.
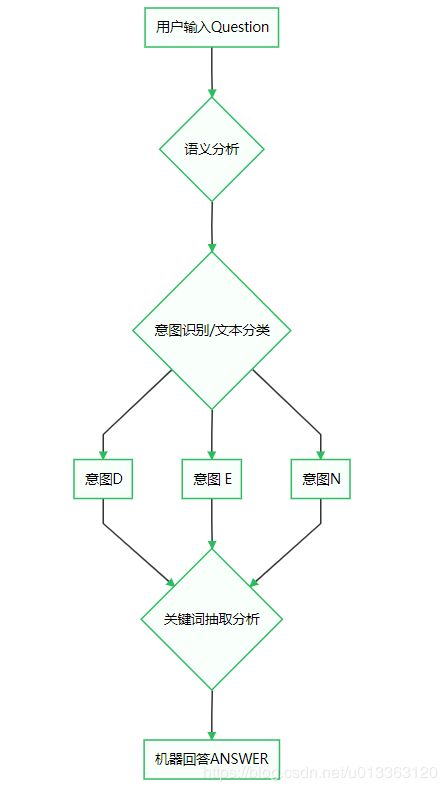
聊天机器人常见模型
1,encoder-decoder加密模型
encoder-decoder框架目前发展较为成熟,在文本处理领域已经成为一种研究模式,应用场景十分广泛。它除了在已有的文本摘要提取,机器翻译,句法分析方面有很大的贡献外,主要也被应用到人机对话和智能回答领域。
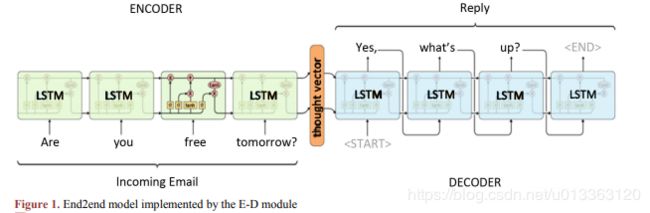
google利用该理念实现的神经翻译系统模型,结合LSTM神经网络结构,实现了端到端的语言模型,是目前十分主流的使用深度学习实现的智能对话系统,并提供了开源的参考框架。
2,Hierarchiaca recurrent encoder-decoder 分级卷积加解密模型
针对目前采用的seq2seq端到端方式的问答系统中出现的意义不明,表达不准确,回复毫无意义的问题,Bengio等人提出了一种更加复杂的模型结构--分级卷积加解密模型。该模型的上下文RNN会在用户之前使用一个分布式的向量来表达对话主题和内容;由于在序列传递过程中的计算步骤被减少,这使得与模型参数有关的目标函数的计算会更加稳定,并且有助于传播优化方法的训练信号。
3,双向分级卷积加解密模型
双向HRED模型的加密模块使用一个双向的RNN模型,一条前向传递语句序列,另一条通过导致输入序列反向传递。前向传递时n位置处的隐藏层状态包含了n位置处之前的信息,而方向传递时的隐藏层状态总结了n位置处之后的信息,为了仍然得到一个固定维度表示的上下文向量,我们可以将前后向传递的最后隐藏层状态通过直接前后相连或通过L2池化后相连。此中双向结构可以有效地解决短时依赖的问题。
4,word embedding
word embeddind 词嵌入,又被称为词表示,将单词数值话,用数值特征表示句子的含义,常用的词嵌入模型有word2vec,fasttext,doc2vec等。广泛应用表明这一系列模型在一个非常广泛的数据集上有非常强大的展现。
5,Attention注意力机制
Attention结构的核心优点是通过在模型“decoder"阶段对相关的源内容给予”关注“,从而可以在目标句子和源句子之间建立直接又简短的链接,解决机器人模型和用户之间的信息断层问题。注意力机制如今作为一种事实标准,已经被有效地应用到很多其他的领域中,比如图片铺货生成,语音识别以及文字摘要等。
在传统seq2seq模型的解码过程中,”encoder“加密器的源序列的最后状态会被作为输入,直接传递到”decoder"解码器。直接传递固定且单一维度的隐藏状态到解码器的方法,对于简短句或中句会有较为客观的效果,却会成为较长的序列的信息瓶颈。不过,不同于RNN模型中将计算出来的隐藏层状态全部丢弃,注意力机制为我们提供了一种方法,可以使解码器对于源序列中的信息选择重点后进行动态记忆。这样,通过注意力机制,长句子的翻译质量也可以得到大幅度的提升。
智能客服系统设计
目前一些聊天系统主要采用nltk文本语料处理,进行词义分析,语义分析,提取关键词,获取词向量或句子向量,结合随机森林,CNN,RNN等模型进行多分类,最后获取机器应答。
常见的开源聊天机器人有ChatterBot和基于tensorflow的chatbot,根据网友提供的实验数据,在进行闲聊型,任务型,知识型三种话题的交互进行时,chatbot机器人的表现更优,不过主要限制在训练语料上。
参考文献
1,[聊天机器人--NLP与Deep Learning 结合](%3Ca href="https://zjcqoo.github.io/-----https://chatbotslife.com/ultimate-guide-to-leveraging-nlp-machine-learning-for-you-chatbot-531ff2dd870c"%3Ehttps://zjcqoo.github.io/-----https://chatbotslife.com/ultimate-guide-to-leveraging-nlp-machine-learning-for-you-chatbot-531ff2dd870c%3C/a%3E)
2,[聊天机器人发展综述](%3Ca href="https://image.hanspub.org/pdf/CSA20180600000_56614827.pdf"%3Ehttps://image.hanspub.org/pdf/CSA20180600000_56614827.pdf%3C/a%3E)
3,chatterbot&chatbot