Laravel的核心概念
工欲善其事,必先利其器。在开发Xblog的过程中,稍微领悟了一点Laravel的思想。确实如此,这篇文章读完你可能并不能从无到有写出一个博客,但知道Laravel的核心概念之后,当你再次写起Laravel时,会变得一目了然胸有成竹。
PHP的生命周期
万物皆有他的生命周期。熟悉Android的同学一定熟悉Android最经典的Activity的生命周期,Laravel 也不例外,Laravel应用程序也有自己的生命周期。Laravel是什么?一个PHP框架。所以要想真正说清Laravel的生命周期,必须说清PHP的生命周期。原文参考这里,这里做个总结。
PHP有两种运行模式,WEB模式和CLI(命令行)模式。当我们在终端敲入php这个命令的时候,使用的是CLI模式;当使用Nginx或者别web服务器作为宿主处理一个到来的请求时,会调用PHP运行,此时使用的是WEB模式。当我们请求一个PHP文件时,比如Laravel 的public\index.php文件时,PHP为了完成这次请求,会发生5个阶段的生命周期切换:
- 模块初始化(MINIT),即调用
php.ini中指明的扩展的初始化函数进行初始化工作,如mysql扩展。 - 请求初始化(RINIT),即初始化为执行本次脚本所需要的变量名称和变量值内容的符号表,如
$_SESSION变量。 - 执行该PHP脚本。
- 请求处理完成(Request Shutdown),按顺序调用各个模块的
RSHUTDOWN方法,对每个变量调用unset函数,如unset $_SESSION变量。 - 关闭模块(Module Shutdown) , PHP调用每个扩展的
MSHUTDOWN方法,这是各个模块最后一次释放内存的机会。这意味着没有下一个请求了。
WEB模式和CLI(命令行)模式很相似,区别是:CLI 模式会在每次脚本执行经历完整的5个周期,因为你脚本执行完不会有下一个请求;而WEB模式为了应对并发,可能采用多线程,因此生命周期1和5有可能只执行一次,下次请求到来时重复2-4的生命周期,这样就节省了系统模块初始化所带来的开销。
可以看到,PHP生命周期是很对称的。说了这么多,就是为了定位Laravel运行在哪里,没错,Laravel仅仅运行再第三个阶段:
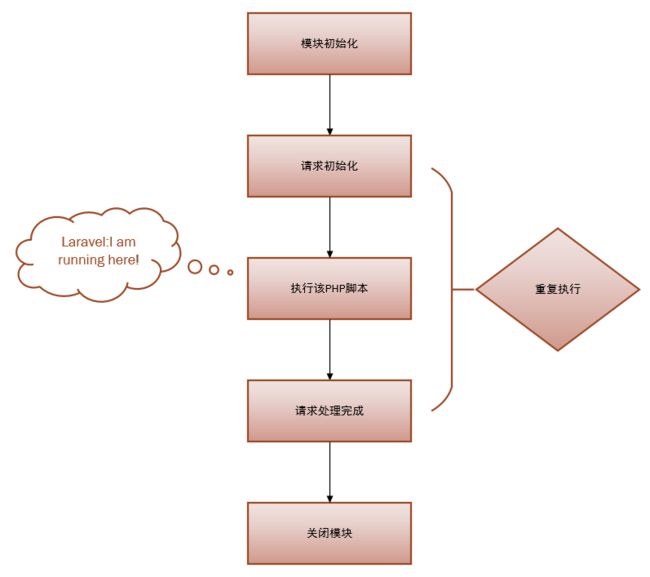
知道这些有什么用?你可以优化你的Laravel代码,可以更加深入的了解Larave的singleton(单例)。至少你知道了,每一次请求结束,Php的变量都会unset,Laravel的singleton只是在某一次请求过程中的singleton;你在Laravel 中的静态变量也不能在多个请求之间共享,因为每一次请求结束都会unset。理解这些概念,是写高质量代码的第一步,也是最关键的一步。因此记住,PHP是一种脚本语言,所有的变量只会在这一次请求中生效,下次请求之时已被重置,而不像Java静态变量拥有全局作用。
好了,开始Laravel的生命周期。
Laravel的生命周期
概述
Laravel 的生命周期从public\index.php开始,从public\index.php结束。
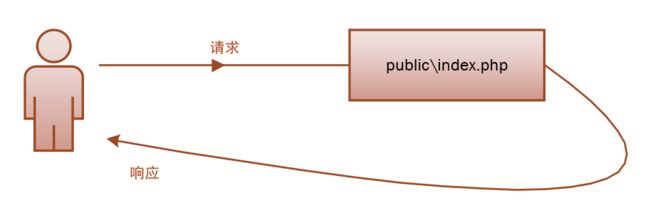
注意:以下几图箭头均代表Request流向
这么说有点草率,但事实确实如此。下面是public\index.php的全部源码(Laravel源码的注释是最好的Laravel文档),更具体来说可以分为四步:
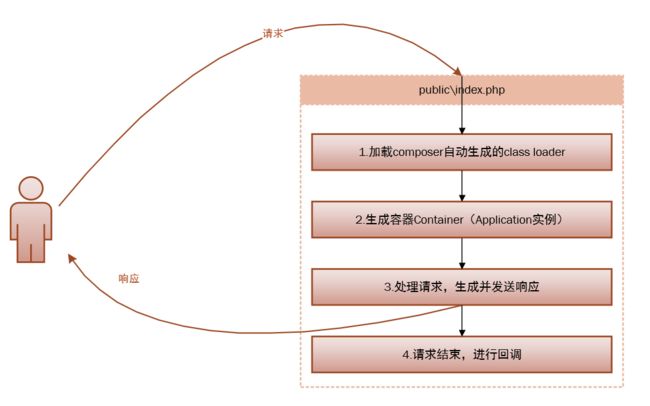
1. require __DIR__.'/../bootstrap/autoload.php';
2. $app = require_once __DIR__.'/../bootstrap/app.php';
$kernel = $app->make(Illuminate\Contracts\Http\Kernel::class);
3. $response = $kernel->handle(
$request = Illuminate\Http\Request::capture()
);
$response->send();
4. $kernel->terminate($request, $response);
这四步详细的解释是:
1.注册加载composer自动生成的class loader,包括所有你composer require的依赖(对应代码1).
2.生成容器Container,Application实例,并向容器注册核心组件(HttpKernel,ConsoleKernel,ExceptionHandler)(对应代码2,容器很重要,后面详细讲解)。
3.处理请求,生成并发送响应(对应代码3,毫不夸张的说,你99%的代码都运行在这个小小的handle方法里面)。
4.请求结束,进行回调(对应代码4,还记得可终止中间件吗?没错,就是在这里回调的)。
启动Laravel基础服务
我们不妨再详细一点:
第一步注册加载composer自动生成的class loader就是加载初始化第三方依赖,不属于Laravel核心,到此为止。
第二步生成容器Container,并向容器注册核心组件,这里牵涉到了容器Container和合同Contracts,这是Laravel的重点,下面将详细讲解。
重点是第三步处理请求,生成并发送响应。
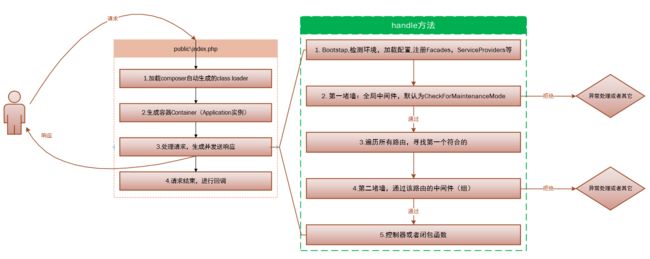
首先Laravel框架捕获到用户发到public\index.php的请求,生成Illuminate\Http\Request实例,传递给这个小小的handle方法。在方法内部,将该$request实例绑定到第二步生成的$app容器上。让后在该请求真正处理之前,调用bootstrap方法,进行必要的加载和注册,如检测环境,加载配置,注册Facades(假象),注册服务提供者,启动服务提供者等等。这是一个启动数组,具体在Illuminate\Foundation\Http\Kernel中,包括:
protected $bootstrappers = [
'Illuminate\Foundation\Bootstrap\DetectEnvironment',
'Illuminate\Foundation\Bootstrap\LoadConfiguration',
'Illuminate\Foundation\Bootstrap\ConfigureLogging',
'Illuminate\Foundation\Bootstrap\HandleExceptions',
'Illuminate\Foundation\Bootstrap\RegisterFacades',
'Illuminate\Foundation\Bootstrap\RegisterProviders',
'Illuminate\Foundation\Bootstrap\BootProviders',
];
看类名知意,Laravel是按顺序遍历执行注册这些基础服务的,注意顺序:Facades先于ServiceProviders,Facades也是重点,后面说,这里简单提一下,注册Facades就是注册config\app.php中的aliases 数组,你使用的很多类,如Auth,Cache,DB等等都是Facades;而ServiceProviders的register方法永远先于boot方法执行,以免产生boot方法依赖某个实例而该实例还未注册的现象。
所以,你可以在ServiceProviders的register方法中使用任何Facades,在ServiceProviders的boot方法中使用任何register方法中注册的实例或者Facades,这样绝不会产生依赖某个类而未注册的现象。
将请求传递给路由
注意到目前为止,Laravel 还没有执行到你所写的主要代码(ServiceProviders中的除外),因为还没有将请求传递给路由。
在Laravel基础的服务启动之后,就要把请求传递给路由了。传递给路由是通过Pipeline(另开篇章讲解)来传递的,但是Pipeline有一堵墙,在传递给路由之前所有请求都要经过,这堵墙定义在app\Http\Kernel.php中的$middleware数组中,没错就是中间件,默认只有一个CheckForMaintenanceMode中间件,用来检测你的网站是否暂时关闭。这是一个全局中间件,所有请求都要经过,你也可以添加自己的全局中间件。
然后遍历所有注册的路由,找到最先符合的第一个路由,经过它的路由中间件,进入到控制器或者闭包函数,执行你的具体逻辑代码。
所以,在请求到达你写的代码之前,Laravel已经做了大量工作,请求也经过了千难万险,那些不符合或者恶意的的请求已被Laravel隔离在外。
服务容器
服务容器就是一个普通的容器,用来装类的实例,然后在需要的时候再取出来。用更专业的术语来说是服务容器实现了控制反转(Inversion of Control,缩写为IoC),意思是正常情况下类A需要一个类B的时候,我们需要自己去new类B,意味着我们必须知道类B的更多细节,比如构造函数,随着项目的复杂性增大,这种依赖是毁灭性的。控制反转的意思就是,将类A主动获取类B的过程颠倒过来变成被动,类A只需要声明它需要什么,然后由容器提供。
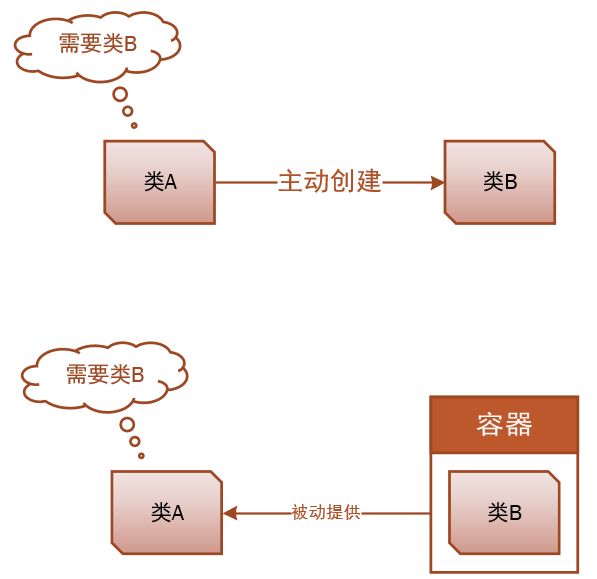
这样做的好处是,类A不依赖于类B的实现,这样在一定程度上解决了耦合问题。
在Laravel的服务容器中,为了实现控制反转,可以有以下两种:
- 依赖注入(Dependency Injection)。
- 绑定。
依赖注入
依赖注入是一种类型提示,举官网的例子:
class UserController extends Controller
{
/**
* The user repository implementation.
*
* @var UserRepository
*/
protected $users;
/**
* Create a new controller instance.
*
* @param UserRepository $users
* @return void
*/
public function __construct(UserRepository $users)
{
$this->users = $users;
}
/**
* Show the profile for the given user.
*
* @param int $id
* @return Response
*/
public function show($id)
{
$user = $this->users->find($id);
return view('user.profile', ['user' => $user]);
}
}
这里UserController需要一个UserRepository实例,我们只需在构造方法中声明我们需要的类型,容器在实例化UserController时会自动生成UserRepository的实例(或者实现类,因为UserRepository可以为接口),而不用主动去获取UserRepository的实例,这样也就避免了了解UserRepository的更多细节,也不用解决UserRepository所产生的依赖,我们所做的仅仅是声明我们所需要的类型,所有的依赖问题都交给容器去解决。(Xblog使用了Repository的是设计模式,大家可以参考)
绑定
绑定操作一般在ServiceProviders中的register方法中,最基本的绑定是容器的bind方法,它接受一个类的别名或者全名和一个闭包来获取实例:
$this->app->bind('XblogConfig', function ($app) {
return new MapRepository();
});
还有一个singleton方法,和bind写法没什么区别。你也可以绑定一个已经存在的对象到容器中,上文中提到的request实例就是通过这种方法绑定到容器的:$this->app->instance('request', $request);。绑定之后,我们可以通过一下几种方式来获取绑定实例:
1. app('XblogConfig');
2. app()->make('XblogConfig');
3. app()['XblogConfig'];
4. resolve('XblogConfig');
以上四种方法均会返回获得MapRepository的实例,唯一的区别是,在一次请求的生命周期中,bind方法的闭包会在每一次调用以上四种方法时执行,singleton方法的闭包只会执行一次。在使用中,如果每一个类要获的不同的实例,或者需要“个性化”的实例时,这时我们需要用bind方法以免这次的使用对下次的使用造成影响;如果实例化一个类比较耗时或者类的方法不依赖该生成的上下文,那么我们可以使用singleton方法绑定。singleton方法绑定的好处就是,如果在一次请求中我们多次使用某个类,那么只生成该类的一个实例将节省时间和空间。
你也可以绑定接口与实现,例如:
$app->singleton(
Illuminate\Contracts\Http\Kernel::class,
App\Http\Kernel::class
);
上文讲述的Laravel的生命周期的第二步,Laravel默认(在bootstrap\app.php文件中)绑定了Illuminate\Contracts\Http\Kernel,Illuminate\Contracts\Console\Kernel,Illuminate\Contracts\Debug\ExceptionHandler接口的实现类,这些是实现类框架的默认自带的。但是你仍然可以自己去实现。
还有一种上下文绑定,就是相同的接口,在不同的类中可以自动获取不同的实现,例如:
$this->app->when(PhotoController::class)
->needs(Filesystem::class)
->give(function () {
return Storage::disk('local');
});
$this->app->when(VideoController::class)
->needs(Filesystem::class)
->give(function () {
return Storage::disk('s3');
});
上述表明,同样的接口Filesystem,使用依赖注入时,在PhotoController中获取的是local存储而在VideoController中获取的是s3存储。
Contracts & Facades(契约&门面)
Laravel 还有一个强大之处是,比如你只需在配置文件中指明你需要的缓存驱动(redis,memcached,file…),Laravel 就自动办你切换到这种驱动,而不需要你针对某种驱动更改逻辑和代码。Why? 很简单,Laravel定义了一系列Contracts(翻译:契约),本质上是一系列PHP接口,一系列的标准,用来解耦具体需求对实现的依赖关系。其实真正强大的公司是制定标准的公司,程序也是如此,好的标准(接口)尤为重要。当程序变得越来大,这种通过合同或者接口来解耦所带来的可扩展性和可维护性是无可比拟的。
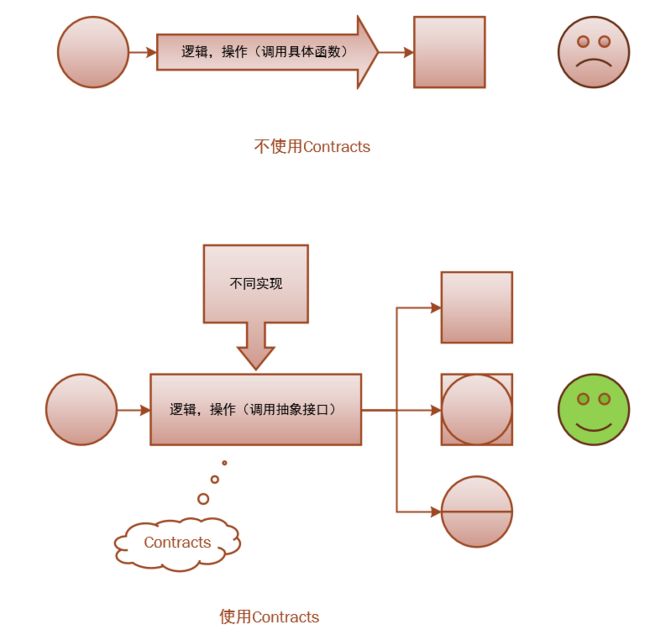
上图不使用Contracts的情况下,对于一种逻辑,我们只能得到一种结果(方块),如果变更需求,意味着我们必须重构代码和逻辑。但是在使用Contracts的情况下,我们只需要按照接口写好逻辑,然后提供不同的实现,就可以在不改动代码逻辑的情况下获得更加多态的结果。
这么说有点抽象,举一个真实的例子。在完成Xblog的初期,我使用了缓存,所以导致Repository中充满了和cache相关的方法:remember,flush,forget等等。后来国外网友反映,简单的博客并不一定需要缓存。所以我决定把它变成可选,但因为代码中充满和cache相关的方法,实现起来并不是很容易。于是想起Laravel的重要概念Contracts。于是,我把与缓存有关的方法抽象出来形成一个Contracts:XblogCache,实际操作只与Contracts有关,这样问题就得到了解决,而几乎没有改变原有的逻辑。XblogCache的代码如下(源码点击这里):
namespace App\Contracts;
use Closure;
interface XblogCache
{
public function setTag($tag);
public function setTime($time_in_minute);
public function remember($key, Closure $entity, $tag = null);
public function forget($key, $tag = null);
public function clearCache($tag = null);
public function clearAllCache();
}
然后,我又完成了两个实现类:Cacheable和NoCache:
- 实现具体缓存。
class Cacheable implements XblogCache
{
public $tag;
public $cacheTime;
public function setTag($tag)
{
$this->tag = $tag;
}
public function remember($key, Closure $entity, $tag = null)
{
return cache()->tags($tag == null ? $this->tag : $tag)->remember($key, $this->cacheTime, $entity);
}
public function forget($key, $tag = null)
{
cache()->tags($tag == null ? $this->tag : $tag)->forget($key);
}
public function clearCache($tag = null)
{
cache()->tags($tag == null ? $this->tag : $tag)->flush();
}
public function clearAllCache()
{
cache()->flush();
}
public function setTime($time_in_minute)
{
$this->cacheTime = $time_in_minute;
}
}
- 不缓存。
class NoCache implements XblogCache
{
public function setTag($tag)
{
// Do Nothing
}
public function setTime($time_in_minute)
{
// Do Nothing
}
public function remember($key, Closure $entity, $tag = null)
{
/**
* directly return
*/
return $entity();
}
public function forget($key, $tag = null)
{
// Do Nothing
}
public function clearCache($tag = null)
{
// Do Nothing
}
public function clearAllCache()
{
// Do Nothing
}
}
然后再利用容器的绑定,根据不同的配置,返回不同的实现(源码):
public function register()
{
$this->app->bind('XblogCache', function ($app) {
if (config('cache.enable') == 'true') {
return new Cacheable();
} else {
return new NoCache();
}
});
}
这样,就实现了缓存的切换而不需要更改你的具体逻辑代码。当然依靠接口而不依靠具体实现的好处不仅仅这些。实际上,Laravel所有的核心服务都是实现了某个Contracts接口(都在Illuminate\Contracts\文件夹下面),而不是依赖具体的实现,所以完全可以在不改动框架的前提下,使用自己的代码改变Laravel框架核心服务的实现方式。
说一说Facades。在我们学习了容器的概念后,Facades就变得十分简单了。在我们把类的实例绑定到容器的时候相当于给类起了个别名,然后覆盖Facade的静态方法getFacadeAccessor并返回你的别名,然后你就可以使用你自己的Facade的静态方法来调用你绑定类的动态方法了。其实Facade类利用了__callStatic() 这个魔术方法来延迟调用容器中的对象的方法,这里不过多讲解,你只需要知道Facade实现了将对它调用的静态方法映射到绑定类的动态方法上,这样你就可以使用简单类名调用而不需要记住长长的类名。这也是Facades的中文翻译为假象的原因。
总结
Laravel强大之处不仅仅在于它给你提供了一系列脚手架,比如超级好用的ORM,基于Carbon的时间处理,以及文件存储等等功能。但是Laravel的核心非常非常简单:利用容器和抽象解耦,实现高扩展性。容器和抽象是所有大型框架必须解决的问题,像Java的Spring,Android的Dagger2等等都是围绕这几个问题的。所以本质上讲,Laravel之所以强大出名,是因为它的设计,思想,可扩展性。而Laravel的好用功能只是官方基于这些核心提供的脚手架,你同样也可以很轻松的添加自己的脚手架。
所以不要觉得Laravel强大是因为他提供的很多功能,而是它的设计模式和思想。
- 理解Laravel生命周期和请求的生命周期概念。
- 所有的静态变量和单例,在下一个请求到来时都会重新初始化。
- 将耗时的类或者频繁使用的类用singleton绑定。
- 将变化选项的抽象为Contracts,依赖接口不依赖具体实现。