Yarn 资源管理
- 环境说明:HDP2.5 + Ambari 在linux centos6上搭建的集群
一、Yarn 资源管理简述:
yarn默认提供了两种调度规则,capacity scheduler和fair scheduler。
现在使用比较多的是capacity scheduler。具体的实现原理和调度源码可以google一下capacity scheduler。
Capacity调度器说的通俗点,可以理解成一个个的资源队列。这个资源队列是用户自己去分配的。
二、具体的配置详情说明
- 1、yarn 内存资源分配设置的参数(由于笔者用的Ambari所以可通过界面配置,Yarn–>configk中对应的Scheduler)
yarn.scheduler.capacity.root.queues=default,keyun_user,yunhong_user
yarn.scheduler.capacity.root.default.capacity=30
yarn.scheduler.capacity.root.keyun_user.capacity=40
yarn.scheduler.capacity.root.yunhong_user.capacity=30
yarn.scheduler.capacity.root.keyun_user.acl_submit_applications=keyun_user
yarn.scheduler.capacity.root.yunhong_user.acl_submit_applications=yunhong_user
yarn.scheduler.capacity.queue-mappings=u:hive:keyun_user,u:hbase:yunhong_user上述参数说明:
yarn.scheduler.capacity.root.queues=default,keyun_user,yunhong_user
创建三个队列,分别为default,keyun_user,yunhong_user
yarn.scheduler.capacity.root.default.capacity=30
yarn.scheduler.capacity.root.keyun_user.capacity=40
yarn.scheduler.capacity.root.yunhong_user.capacity=30
队列所占资源使用率分别为30%,40%,30%。
虽然有了这样的资源分配,但是并不是说提交任务到keyun_user里面,
它就只能使用40%的资源,即使剩下的60%都空闲着。
它也是能够实现(通过配置),只要资源实在空闲状态,那么keyun_user就可以使用100%的资源。
但是一旦其它队列提交了任务,keyun_user就需要在释放资源后,把资源还给其它队列,直到达到预设的配比值。
粗粒度上资源是按照上面的方式进行,在每个队列的内部,还是按照FIFO的原则来分配资源的。
yarn.scheduler.capacity.root.keyun_user.acl_submit_applications=keyun_user
yarn.scheduler.capacity.root.yunhong_user.acl_submit_applications=yunhong_user
表示哪些user/group可以往keyun_user或yunhong_user里面提作业
yarn.scheduler.capacity.queue-mappings=u:hive:keyun_user,u:hbase:yunhong_user
设定user/group和queue的映射关系,格式为[u|g]:[name]:[queue_name][,next mapping]*,
如上说明hive这个组件任务自动提交到keyun_user这个队列;
(目前发现这个配置只到hadoop中所对方的各个组件的级别,后期再研究如何到该平台的用户级别的控制)
2、刷新Yarn 对应的配置

这一步在对yarn配置文件进行重新修改后,刷新配置文件可能会出错,
那么可以先将配置文件还原回最先原的,重启然后再进行修改,刷新。。。3、重启需要重启的组件
笔者这里根据提示对需要重启的进行重启后依然报错,因而笔者将所有组件都停了再重新启动,事实证明这招还挺不错的。4、验证如下图所示
通过web 视图验证
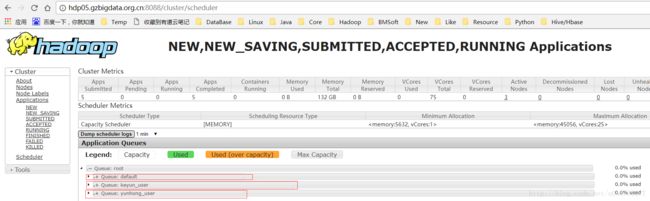
以hbase用户执行,因为笔者采用了kerberos的认证机制,因而需要先kinit 进入系统先
[root@hdp36 ~]# kinit -kt /etc/security/keytabs/hbase.service.keytab hbase/hdp36.gzdata.org.cn@org.cn命令(不指定提交的队列):
hadoop jar /usr/hdp/2.5.3.0-37/hadoop-mapreduce/hadoop-mapreduce-examples-2.7.3.2.5.3.0-37.jar randomtextwriter -D mapreduce.randomtextwriter.totalbytes=1000000000 /tmp/YCB/Wordcount/Input若输出目录已存在:
hdfs dfs -rm -r /tmp/YCB/Wordcount/Input
结果说明:不指定队列则默认提交至default队列。
往keyun_user
hadoop jar /usr/hdp/2.5.3.0-37/hadoop-mapreduce/hadoop-mapreduce-examples-2.7.3.2.5.3.0-37.jar randomtextwriter -D mapreduce.randomtextwriter.totalbytes=1000000000 -D mapreduce.job.queuename=keyun_user /tmp/YCB/Wordcount/Input2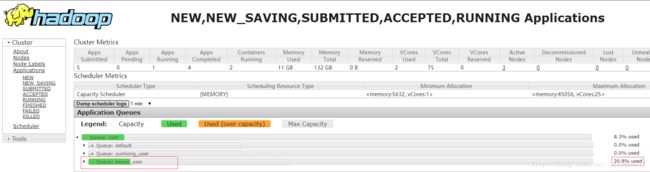
- 结果说明:指定队列则默认提交至指定队列队列,如果该队列被占用且其他资源也正在执行则需要等待。
通过Ambari 的hive_view提交任务,走mr (不走mr则不会被监控到),以admin用户执行
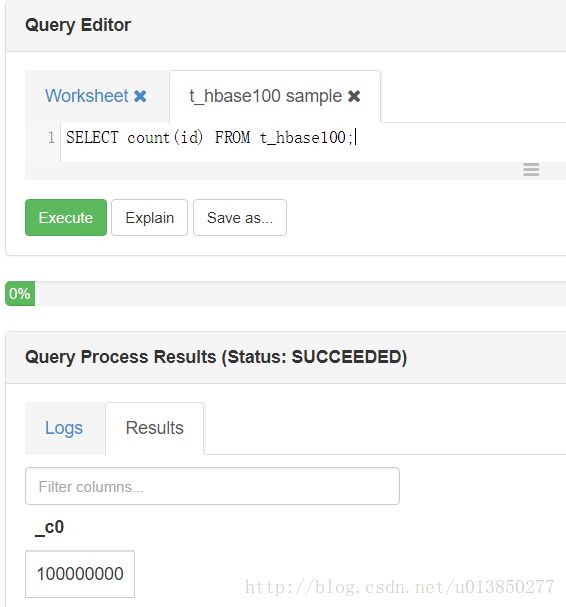
SELECT count(id) FROM t_hbase100; 
- 结果说明:该脚本是通过admin用户登录进入Ambari,然后再通过Ambari对应的Hive_view附件运行的sql。由于Hive_view运用的是Hive组件,且yarn.scheduler.capacity.queue-mappings=u:hive:keyun_user,u:hbase:yunhong_user的配置说明hive这个组件任务自动提交到keyun_user这个队列。
Hive_view 运行视图如下所示:
超过设定值:
SELECT count(id) FROM t_hbase100; 执行的过程中,发现对应的队列超过了设定的值
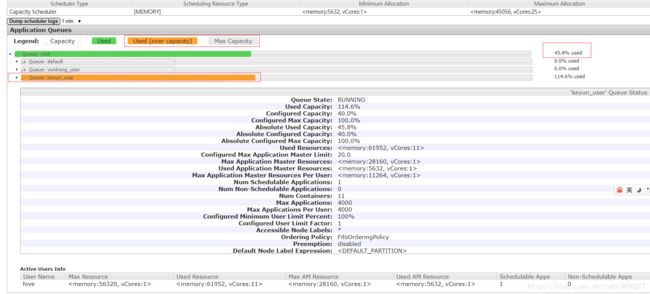
- 结果说明:虽然有了这样的资源分配,但是并不是说提交任务到keyun_user里面,它就只能使用40%的资源,即使剩下的60%都空闲着。它也是能够实现(通过配置),只要资源实在空闲状态,那么keyun_user就可以使用100%的资源。
附:测试过程中的一些简单测试详情如下:
1、hadoop jar xxx.jar 提交任务
[root@hdp39 ~]# hadoop jar /usr/hdp/2.5.3.0-37/hadoop-mapreduce/hadoop-mapreduce-examples-2.7.3.2.5.3.0-37.jar randomtextwriter -D mapreduce.randomtextwriter.totalbytes=1000000000 /tmp/YCB/Wordcount/Input通过字节换算这个大概是10G大小:totalbytes=10000000000
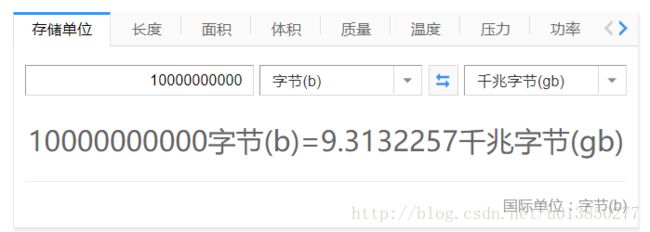
当然如果你集群内存比较小,可以适当修改这个输出值的大小,笔者在自己机器输出1G,执行时间20秒左右且发现使用的内存太小,为了方便观察,所以选择10G的输出
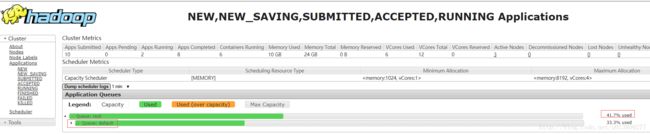
通过Yarn web Ui 观察最高可达到83%
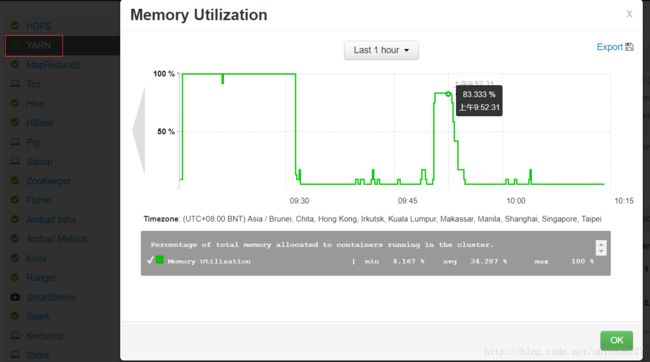
- 也可通过Ambari 监控界面取得内存的使用率,如下图所示:
若目录已存在则删除存在的目录
[root@hdp39 ~]# hdfs dfs -rm -r /tmp/YCB/Wordcount/Input如果想停止任务可见如下
1、查看所有job任务
[root@hdp39 ~]# hadoop job -list
DEPRECATED: Use of this script to execute mapred command is deprecated.
Instead use the mapred command for it.
17/09/30 09:29:52 INFO impl.TimelineClientImpl: Timeline service address: http://hdp40:8188/ws/v1/timeline/
17/09/30 09:29:52 INFO client.RMProxy: Connecting to ResourceManager at hdp40/10.194.186.40:8050
17/09/30 09:29:53 INFO client.AHSProxy: Connecting to Application History server at hdp40/10.194.186.40:10200
Total jobs:2
JobId State StartTime UserName Queue Priority UsedContainers RsvdContainers UsedMem RsvdMem NeededMem AM info
job_1506582742279_0002 RUNNING 1506734118925 hive default NORMAL 12 0 23552M 0M 23552M http://hdp40:8088/proxy/application_1506582742279_0002/
job_1506582742279_0003 PREP 1506734552285 hive default NORMAL 0 0 0M 0M 0M http://hdp40:8088/proxy/application_1506582742279_0003/
job_1506582742279_0013 PREP 1506737018883 hbase default NORMAL N/A N/A N/A N/A N/A N/A- 注:在整个集群中所有的任务都会归集到hdp40(ResourceManager安装在Hdp40),本集群是集成了Kerberos,因而在登录服务器所用的验证keytab对应的用户则是后面提交任务的用户人;如验证的keytab为hbase用户,那么后面执行hadoop jar任务的也将是hbase用户]
kinit -kt /etc/security/keytabs/hbase.service.keytab hbase/hdp42
job_1506582742279_0013 PREP 1506737018883 hbase default NORMAL N/A N/A N/A N/A N/A N/A2、删除指定的job任务
[root@hdp39 ~]# hadoop job -kill job_1506582742279_0002
DEPRECATED: Use of this script to execute mapred command is deprecated.
Instead use the mapred command for it.
17/09/30 09:31:03 INFO impl.TimelineClientImpl: Timeline service address: http://hdp40:8188/ws/v1/timeline/
17/09/30 09:31:03 INFO client.RMProxy: Connecting to ResourceManager at hdp40/10.194.186.40:8050
17/09/30 09:31:03 INFO client.AHSProxy: Connecting to Application History server at hdp40/10.194.186.40:10200
Killed job job_1506582742279_0002执行过程如下:
[root@hdp39 ~]# hadoop jar /usr/hdp/2.5.3.0-37/hadoop-mapreduce/hadoop-mapreduce-examples-2.7.3.2.5.3.0-37.jar randomtextwriter -D mapreduce.randomtextwriter.totalbytes=10000000000 /tmp/YCB/Wordcount/Input
17/09/30 09:50:17 INFO impl.TimelineClientImpl: Timeline service address: http://hdp40:8188/ws/v1/timeline/
17/09/30 09:50:17 INFO client.RMProxy: Connecting to ResourceManager at hdp40/10.194.186.40:8050
17/09/30 09:50:18 INFO client.AHSProxy: Connecting to Application History server at hdp40/10.194.186.40:10200
Running 9 maps.
Job started: Sat Sep 30 09:50:19 CST 2017
17/09/30 09:50:19 INFO impl.TimelineClientImpl: Timeline service address: http://hdp40:8188/ws/v1/timeline/
17/09/30 09:50:19 INFO client.RMProxy: Connecting to ResourceManager at hdp40/10.194.186.40:8050
17/09/30 09:50:19 INFO client.AHSProxy: Connecting to Application History server at hdp40/10.194.186.40:10200
17/09/30 09:50:19 INFO hdfs.DFSClient: Created HDFS_DELEGATION_TOKEN token 895 for hive on 10.194.186.39:8020
17/09/30 09:50:19 INFO security.TokenCache: Got dt for hdfs://hdp39:8020; Kind: HDFS_DELEGATION_TOKEN, Service: 10.194.186.39:8020, Ident: (HDFS_DELEGATION_TOKEN token 895 for hive)
17/09/30 09:50:20 INFO mapreduce.JobSubmitter: number of splits:9
17/09/30 09:50:20 INFO mapreduce.JobSubmitter: Submitting tokens for job: job_1506582742279_0010
17/09/30 09:50:20 INFO mapreduce.JobSubmitter: Kind: HDFS_DELEGATION_TOKEN, Service: 10.194.186.39:8020, Ident: (HDFS_DELEGATION_TOKEN token 895 for hive)
17/09/30 09:50:21 INFO impl.YarnClientImpl: Submitted application application_1506582742279_0010
17/09/30 09:50:21 INFO mapreduce.Job: The url to track the job: http://hdp40:8088/proxy/application_1506582742279_0010/
17/09/30 09:50:21 INFO mapreduce.Job: Running job: job_1506582742279_0010
17/09/30 09:50:30 INFO mapreduce.Job: Job job_1506582742279_0010 running in uber mode : false
17/09/30 09:50:30 INFO mapreduce.Job: map 0% reduce 0%
17/09/30 09:52:53 INFO mapreduce.Job: map 11% reduce 0%
17/09/30 09:53:09 INFO mapreduce.Job: map 33% reduce 0%
17/09/30 09:53:15 INFO mapreduce.Job: map 44% reduce 0%
17/09/30 09:53:16 INFO mapreduce.Job: map 56% reduce 0%
17/09/30 09:53:22 INFO mapreduce.Job: map 67% reduce 0%
17/09/30 09:53:35 INFO mapreduce.Job: map 78% reduce 0%
17/09/30 09:53:59 INFO mapreduce.Job: map 89% reduce 0%
17/09/30 09:54:36 INFO mapreduce.Job: map 100% reduce 0%
17/09/30 09:54:39 INFO mapreduce.Job: Job job_1506582742279_0010 completed successfully
17/09/30 09:54:39 INFO mapreduce.Job: Counters: 32
File System Counters
FILE: Number of bytes read=0
FILE: Number of bytes written=1324305
FILE: Number of read operations=0
FILE: Number of large read operations=0
FILE: Number of write operations=0
HDFS: Number of bytes read=1080
HDFS: Number of bytes written=9920096052
HDFS: Number of read operations=36
HDFS: Number of large read operations=0
HDFS: Number of write operations=18
Job Counters
Launched map tasks=9
Other local map tasks=9
Total time spent by all maps in occupied slots (ms)=3196786
Total time spent by all reduces in occupied slots (ms)=0
Total time spent by all map tasks (ms)=1598393
Total vcore-milliseconds taken by all map tasks=1598393
Total megabyte-milliseconds taken by all map tasks=2455131648
Map-Reduce Framework
Map input records=9
Map output records=14746901
Input split bytes=1080
Spilled Records=0
Failed Shuffles=0
Merged Map outputs=0
GC time elapsed (ms)=5540
CPU time spent (ms)=258730
Physical memory (bytes) snapshot=2548002816
Virtual memory (bytes) snapshot=29189140480
Total committed heap usage (bytes)=1590165504
org.apache.hadoop.examples.RandomTextWriter$Counters
BYTES_WRITTEN=9663678901
RECORDS_WRITTEN=14746901
File Input Format Counters
Bytes Read=0
File Output Format Counters
Bytes Written=9920096052
Job ended: Sat Sep 30 09:54:39 CST 2017
The job took 260 seconds.参考文档如下:
利用yarn capacity scheduler在EMR集群上实现大集群的多租户的集群资源隔离和quota限制
Hadoop作业提交与停止命令