java线程池ThreadPoolExecutor的原理及使用
示例代码:
https://gitee.com/constfafa/imooc-zookeeper-starter 下的threadpoolexecutor
看《阿里巴巴java编程手册》并发处理部分,讲了两个原则:
1. 线程资源必须通过线程池提供,不允许在应用中自行显式创建线程。
使用线程池的好处是减少在创建和销毁线程上所消耗的时间及系统资源,解决资源不足的问题。如果不使用线程池,有可能造成系统创建大量同类线程而导致消耗完内存或者“过度切换”的问题。
我们知道,有继承Thread,implements Runnable, implements Callable
2. 线程池不允许使用Executors创建,而是通过ThreadPoolExecutor的方式创建,这样的处理方式能让编写代码的工程师更加明确线程池的运行规则,规避资源耗尽的风险。
Executors返回的线程池对象的弊端如下:
1)FixedThreadPool和SingleThreadPool:允许的请求队列长度为Integer.MAX_VALUE,可能会堆积大量的请求,从而导致OOM(无参的LinkedBlockingQueue的长度默认是Integer.MAX_VALUE)
public static ExecutorService newFixedThreadPool(int nThreads) {
return new ThreadPoolExecutor(nThreads, nThreads,
0L, TimeUnit.MILLISECONDS,
new LinkedBlockingQueue());
}
public static ExecutorService newSingleThreadExecutor() {
return new FinalizableDelegatedExecutorService
(new ThreadPoolExecutor(1, 1,
0L, TimeUnit.MILLISECONDS,
new LinkedBlockingQueue()));
}
2)CachedThreadPool和ScheduledThreadPool:允许的创建线程数量为Integer.MAX_VALUE,可能会堆积大量的请求,从而导致OOM
public static ExecutorService newCachedThreadPool() {
return new ThreadPoolExecutor(0, Integer.MAX_VALUE,
60L, TimeUnit.SECONDS,
new SynchronousQueue());
}
public ScheduledThreadPoolExecutor(int corePoolSize) {
super(corePoolSize, Integer.MAX_VALUE, 0, NANOSECONDS,
new DelayedWorkQueue());
}
读了下源码加深对线程池运行规则的认识。
先看一下类图
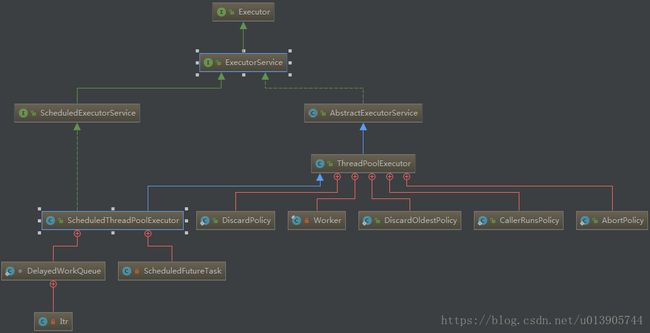
ExecutorService提供了两种基础线程池的选择,ScheduledThreadPoolExecutor(定时任务的)和ThreadPoolExecutor(普通的)
这里主要介绍ThreadPoolExecutor
讲一下关键的代码实现。
threadPoolExecutor.submit(()->LOGGER.info(j+"处理业务"));
其submit执行的是AbastractExecutorService中的submit方法,而这个方法里面调用的execute方法,就是Executor interface定义的execute方法,其是在ThreadPoolExecutor中定义的
public void execute(Runnable command) {
if (command == null)
throw new NullPointerException();
/*
* Proceed in 3 steps:
*
* 1. If fewer than corePoolSize threads are running, try to
* start a new thread with the given command as its first
* task. The call to addWorker atomically checks runState and
* workerCount, and so prevents false alarms that would add
* threads when it shouldn't, by returning false.
*
* 2. If a task can be successfully queued, then we still need
* to double-check whether we should have added a thread
* (because existing ones died since last checking) or that
* the pool shut down since entry into this method. So we
* recheck state and if necessary roll back the enqueuing if
* stopped, or start a new thread if there are none.
*
* 3. If we cannot queue task, then we try to add a new
* thread. If it fails, we know we are shut down or saturated
* and so reject the task.
*/
int c = ctl.get();
if (workerCountOf(c) < corePoolSize) {
if (addWorker(command, true))
return;
c = ctl.get();
}
if (isRunning(c) && workQueue.offer(command)) {
int recheck = ctl.get();
if (! isRunning(recheck) && remove(command))
reject(command);
else if (workerCountOf(recheck) == 0)
addWorker(null, false);
}
else if (!addWorker(command, false))
reject(command);
}
先看一下ThreadPoolExecutor的构造方法:
public ThreadPoolExecutor(int corePoolSize,
int maximumPoolSize,
long keepAliveTime,
TimeUnit unit,
BlockingQueue workQueue,
RejectedExecutionHandler handler) {
this(corePoolSize, maximumPoolSize, keepAliveTime, unit, workQueue,
Executors.defaultThreadFactory(), handler);
}
corePoolSize:池中的线程数,即使其处于IDLE状态
maximumPoolSize:池中允许的最大线程数
keepAliveTime:当线程数大于核心时,空闲线程在终止之前等待新任务的最长时间
unit:keepAliveTime的时间单位
workQueue:队列,用于在执行task之前保存task
handler:当达到了线程边界和队列容量,无法及时处理时,reject task使用的处理程序
上面的注释中Doug Lea详细说明了线程池的原理。
可以简单这样理解线程池:
1.如果正在运行少于corePoolSize的线程,尝试使用给定命令启动新线程。调用addWorker时会以原子方式检查runState和workerCount,通过返回false来防止在不应该添加线程时添加线程。(如果未达到maximumPoolSize,那么会扩容?)
2.如果任务可以成功进入队列,那么我们仍然需要仔细检查是否应该添加一个线程(因为自上次检查后现有的线程已经死亡),或者自从进入此方法后池关闭了。 所以我们重新检查状态,如果线程停止了那么将任务回滚进入其他线程,或者如果没有其他线程,则启动新的线程。
3.如果我们不能将任务入队,那么我们尝试添加一个新线程。 如果失败,我们知道我们已关闭或饱和,因此拒绝该任务。
workQueue是一个BlockingQueue,也就是说当前线程数小于corePoolSize,那么就启用新的线程,如果大于corePoolSize(如果有扩容机制,那么就是maximumPoolSize),那么就放到这个workQueue里面(workQueue.offer)
附上一个完整的测试案例
使用threadPoolExecutor.execute()方法
Test03方法
@Test
public void test03() {
LOGGER.info("begin test");
ThreadPoolExecutor threadPoolExecutor = new ThreadPoolExecutor(
5
, 5
, 0L
, TimeUnit.MILLISECONDS
, new ArrayBlockingQueue<>(3)
, ((r, executor) -> LOGGER.info("被拒绝任务为" + r.toString()))
){
@Override
protected void beforeExecute(Thread t, Runnable r) {
super.beforeExecute(t, r);
LOGGER.info(r.getClass().getName()+"线程执行之前");
}
@Override
protected void afterExecute(Runnable r, Throwable t) {
super.afterExecute(r, t);
Class rClass = r.getClass();
try {
LiftOff runnable = (LiftOff) rClass.newInstance();
LOGGER.info(runnable.getTag()+"这类线程执行之后");
} catch (InstantiationException e) {
e.printStackTrace();
} catch (IllegalAccessException e) {
e.printStackTrace();
}
}
};
for (int i = 0; i < 5; i++) {
final int j = 1;
threadPoolExecutor.execute(new LiftOff());
}
// threadPoolExecutor.shutdown();
}
}
LiftOff任务
class LiftOff implements Runnable {
Logger logger = LoggerFactory.getLogger(LiftOff.class);
protected int countDown = 10; // Default
private static int taskCount = 0;
private final String tag = "liftoff";
public String getTag() {
return tag;
}
private final int id = taskCount++;
public LiftOff() {}
public LiftOff(int countDown) {
this.countDown = countDown;
}
public String status() {
return "#" + id + "(" +
(countDown > 0 ? countDown : "Liftoff!") + "), ";
}
@Override
public void run() {
while(countDown-- > 0) {
logger.info(status());
Thread.yield();
}
}
}
执行结果为:
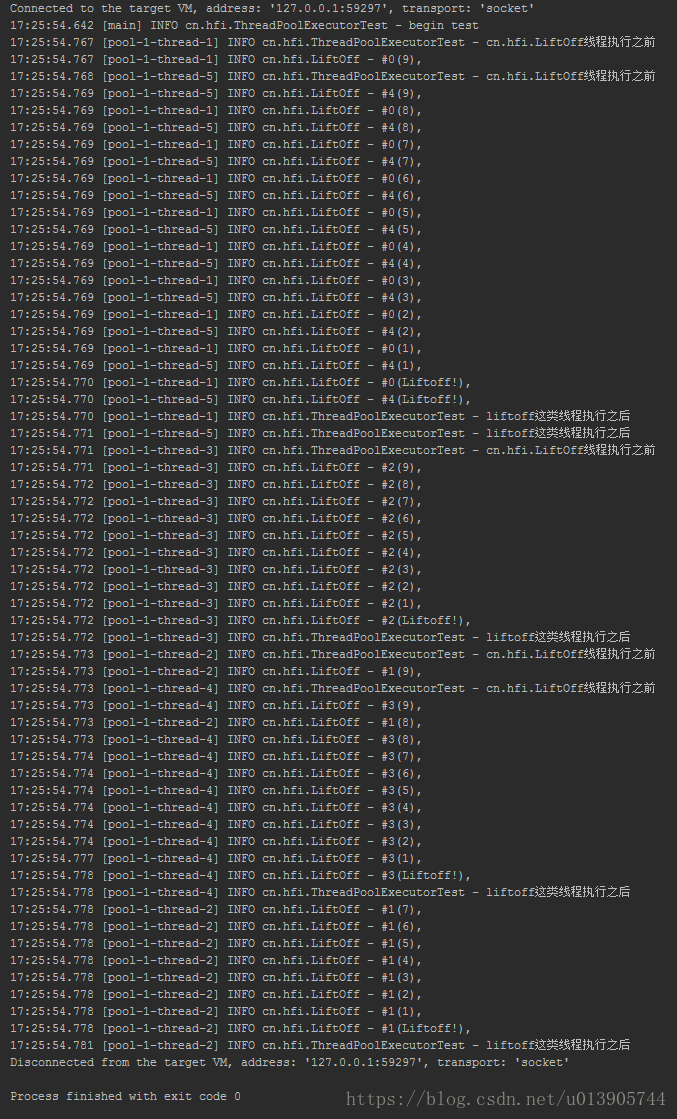
可以看到5个任务被分配到了5个线程来同步执行。
使用threadPoolExecutor.submit方法执行
@Test
public void test04() {
LOGGER.info("begin submit test");
ThreadPoolExecutor threadPoolExecutor = new ThreadPoolExecutor(
5
, 5
, 0L
, TimeUnit.MILLISECONDS
, new ArrayBlockingQueue<>(3)
, ((r, executor) -> LOGGER.info("被拒绝任务为" + r.toString()))
){
@Override
protected void beforeExecute(Thread t, Runnable r) {
super.beforeExecute(t, r);
LOGGER.info(r.getClass().getName()+"线程执行之前");
}
@Override
protected void afterExecute(Runnable r, Throwable t) {
super.afterExecute(r, t);
Class rClass = r.getClass();
/*try {
///Caused by: java.lang.NoSuchMethodException: java.util.concurrent.FutureTask.()
///可能没办法通过反射方式来创建FutureTask
*//*FutureTask runnable = (FutureTask) rClass.newInstance();
LOGGER.info(runnable.get()+"这类线程执行之后");*//*
} catch (InstantiationException e) {
e.printStackTrace();
} catch (IllegalAccessException e) {
e.printStackTrace();
} catch (InterruptedException e) {
e.printStackTrace();
} catch (ExecutionException e) {
e.printStackTrace();
}*/
}
};
for (int i = 0; i < 5; i++) {
final int j = 1;
Future submit = threadPoolExecutor.submit(new Thread02());
try {
LOGGER.info(submit.get());
} catch (InterruptedException e) {
e.printStackTrace();
} catch (ExecutionException e) {
e.printStackTrace();
}
// threadPoolExecutor.submit(new LiftOff());
}
// threadPoolExecutor.shutdown();
}
}
Thread02类为
public class Thread02 implements Callable {
@Override
public String call() throws Exception {
StringBuilder sb = new StringBuilder();
for(int i=0;i<4;i++){
sb.append(i);
}
return sb.toString();
}
}
执行结果为:

从中我们可以总结出threadPoolExecutor execute方法与submit方法的区别
1. 返回值不同,submit有返回值,而execute没有返回值
2. 使用submit,其执行的task是java.util.concurrent.FutureTask,可以从中获取返回值
使用execute,其执行的task就是我们自己的task,如果我们的task中带有某种标记tag,可以通过这种方式获得