ELFK日志平台入门1---架构设计
ELFK日志平台入门1---架构设计
ELFK日志平台入门2---Elasticseach集群搭建
ELFK日志平台入门3---Kibana搭建
ELFK日志平台入门4---Kafka集群搭建
ELFK日志平台入门5---Logstash+Filebeat集群搭建
1、什么是ELK
日志,对于任何系统来说都是及其重要的组成部分。在计算机系统里面,更是如此。但是由于现在的计算机系统大多比较复杂,很多系统都不是在一个地方,甚至都是跨国界的;即使是在一个地方的系统,也有不同的来源,比如,操作系统,应用服务,业务逻辑等等。他们都在不停产生各种各样的日志数据。根据不完全统计,我们全球每天大约要产生2EB的数据。1EB=1024PB 1PB=1024TB
面对如此海量的数据,又是分布在各个不同地方,如果我们需要去查找一些重要的信息,难道还是使用传统的方法,去登陆到一台台机器上查看?看来传统的工具和方法已经显得非常笨拙和低效了。于是,一些聪明人就提出了建立一套集中式的方法,把不同来源的数据集中整合到一个地方。
一个完整的集中式日志系统,是离不开以下几个主要特点的:
- 收集-能够采集多种来源的日志数据
- 传输-能够稳定的把日志数据传输到中央系统
- 存储-如何存储日志数据
- 分析-可以支持 UI 分析
- 警告-能够提供错误报告,监控机制
开源实时日志分析ELK平台能够完美的解决我们上述的问题,ELK由ElasticSearch、Logstash和Kibana三个开源工具组成。
ElasticSearch:是个开源分布式搜索引擎,它的特点有:分布式,零配置,自动发现,索引自动分片,索引副本机制,restful风格接口,多数据源,自动搜索负载等。
Logstash: 是一个完全开源的工具,他可以对你的日志进行收集、分析,并将其存储供以后使用。
Kibana:也是一个开源和免费的工具,Kibana可以为 Logstash和 ElasticSearch 提供的日志分析友好的 Web 界面,可以帮助汇总、分析和搜索重要数据日志。
ELK 其实并不是一款软件,而是一整套解决方案,是三个软件产品的首字母缩写,Elasticsearch,Logstash 和 Kibana。这三款软件都是开源软件,通常是配合使用,而且又先后归于 Elastic.co 公司名下,故被简称为ELK协议栈。
官网:https://www.elastic.co/cn/ ,中文文档:https://elkguide.elasticsearch.cn/
下载elk各组件的旧版本:https://www.elastic.co/downloads/past-releases
在需要收集日志的所有服务上部署logstash,Logstash收集AppServer产生的Log,将日志收集在一起交给全文搜索服务ElasticSearch,而Kibana则从ES集群中查询数据生成图表,再返回给客户端Browser。
2、整体架构设计
这边是传统ELK架构(下面皆以集群三个节点为例):
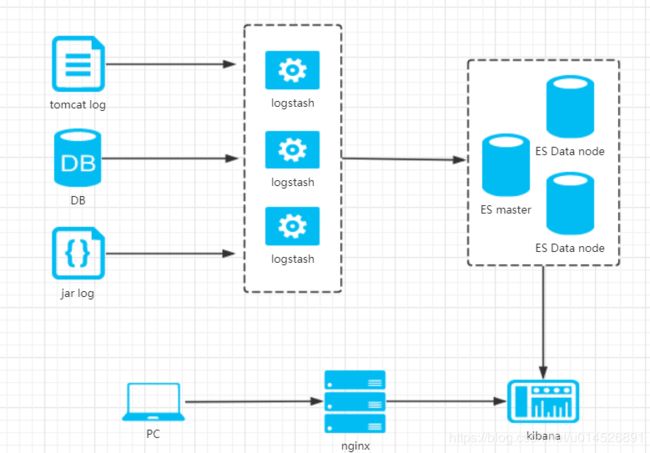
在传统ELK架构上,做了一些架构改造和优化。改造后整体架构如下:

以上架构图可以看到,在传统的ELK(elasticsearch+logstash+kibana)上,增加了两个组件(Filebeat+Kafka),传统的ELK存在如下问题:
问题1:Logstash如果直接收集日志,致命的缺点是它的性能以及资源消耗(默认的堆大小是 1GB),收集日志效率较低,尽管它的性能在近几年已经有很大提升,与它的替代者们相比还是要慢很多的。这里有 Logstash 与 Filebeat 的性能对比。它在大数据量的情况下会是个问题。
Filebeat:作为 Beats 家族的一员,Filebeat 是一个轻量级的日志传输工具,它的存在正弥补了 Logstash 的缺点:Filebeat 作为一个轻量级的日志传输工具可以将日志推送到中心 Logstash。在版本 5.x 中,Elasticsearch 具有解析的能力(像 Logstash 过滤器)— Ingest。这也就意味着可以将数据直接用 Filebeat 推送到 Elasticsearch,并让 Elasticsearch 既做解析的事情,又做存储的事情。也不需要使用缓冲,因为 Filebeat 也会和 Logstash 一样记住上次读取的偏移;
问题2:Logstash目前不支持缓存,日志收集未做任何缓冲直接推送Elasticsearch,当日志量大或者短时间端日志暴增的时候,可能出现Elasticsearch宕机的风险,目前的典型替代方案是将 Redis 或 Kafka 作为中心缓冲池。
Kafka:Kafka是最初由Linkedin公司开发,是一个分布式、支持分区的(partition)、多副本的(replica),基于zookeeper协调的分布式消息系统,它的最大的特性就是可以实时的处理大量数据以满足各种需求场景:比如基于hadoop的批处理系统、低延迟的实时系统、storm/Spark流式处理引擎,web/nginx日志、访问日志,消息服务等等,用scala语言编写,Linkedin于2010年贡献给了Apache基金会并成为顶级开源项目。
问题3:如何有效的收集容器日志?目前有效的方式有:1、把日志挂在到宿主机;2、Logpilot容器日志收集中间件收集
Logpilot:log-pilot 是阿里开源的容器日志收集方案,为您提供的日志收集镜像。可以在每台机器上部署一个 log-pilot 实例,就可以收集机器上所有 Docker 应用日志。
那如何在Redis和Kafka间做选择呢?
- 消息推送的可靠性:
Redis 消息推送(基于分布式 Pub/Sub)多用于实时性较高的消息推送,并不保证可靠。Redis-Pub/Sub 断电就会清空数据,而使用 Redis-List 作为消息推送虽然有持久化,也并非完全可靠不会丢失。
Kafka 虽然有一些延迟但保证可靠。
- 订阅功能的分组:
Redis 发布订阅除了表示不同的 topic 外,并不支持分组。
Kafka 中发布一个内容,多个订阅者可以分组,同一个组里只有一个订阅者会收到该消息,这样可以用作负载均衡。
- 集群资源的消耗:
Redis 3.0之后个有提供集群ha机制,但是要为每个节点都配置一个或者多个从节点,从节点从主节点上面拉取数据,主节点挂了,从节点顶替上去成为主节点,但是这样对资源比较浪费。
Kafka 作为消息队列,能充分的运用集群资源,每个应用相当于一个topic,一个topic可拥有多个partition,并且partition能轮询分配到每个节点上面,并且生产者生产的数据也会均匀的放到partition中,即使上层只有1个应用kafka集群的资源也会被充分的利用到,这样就避免了redis集群出现的数据倾斜问题,并且kafka有类似于hdfs的冗余机制,一个broker挂掉了不影响整个集群的运行。
- 吞吐量:
Kafka由于分片、稀疏索引等机制,Kafka可以承受亿级吞吐量。
综合以上考虑,选用Kafka作为数据缓冲。
架构设计后,整个日志平台的流程如下:
- 将Filebeat部署到需要采集日志的服务器上,Filebeat将采集到的日志数据传输到Kafka中。
- Kafka将获取到的日志信息存储起来,并且作为输入(input)传输给Logstash。
- Logstash将Kafka中的数据作为输入,并且把Kafka中的数据进行过滤等其他操作,然后把操作后得到的数据输入(output)到Elasticsearch中。
- Elasticsearch对Logstash中的数据进行处理,并且将数据作为输入传送给kibana进行显示。
下面几个小节将带大家介绍整体的搭建过程。