【论文阅读】POI2Vec: Geographical Latent Representation for Predicting Future Visitors
《POI2Vec: Geographical Latent Representation for Predicting Future Visitors》
Shanshan Feng, Gao Cong, Bo An, Yeow Meng Chee. 2017,AAAI
附件:论文
Abstract
随着位置感知型(location-aware)社交媒体应用的日益普及,兴趣点(POI)推荐得到了广泛的研究。然而现有的大部分研究是从用户的角度出发,为用户推荐POI。相比之下,我们考虑一个新的研究问题,即预测未来某个时期访问特定POI的用户。问题的难点在于难以有效地学习POI的序列转换以及用户偏好,并将其整合从而进行预测。我们提出了一个新的能够结合地理因素影响的潜在表示模型POI2Vec,在建模用户流动行为的过程中,这是非常重要的。我们注意到现有的表示模型没有包含地理因素的影响,我们进一步提出一种方法来联合建模用户偏好和POI顺序转换的影响,以预测给定POI的潜在访问者。我们在2个真实的数据集上进行实验,证明我们提出的方法优于最新的POI预测和未来用户预测方法。
Introduction
现有研究:
- 关于用户移动行为和POI推荐的建模问题,Cho, Myers, and Leskovec 2011; Ye et al. 2011
- 用户流动性受到其最近访问点及个人兴趣的高度影响,Cheng et al. 2013
- word2vec,Mikolov and Dean 2013; Mikolov et al. 2013
- 利用word2vec模拟用户的连续签到,Liu, Liu, and Li 2016
- hierarchical softmax,Morin and Bengio 2005
- 对于分层softmax的每一项,构造合适的二叉树,Mnih and Hinton 2009
在POI2Vec中,每个POI被表示为一个潜在的低维空间中的向量,两个向量之间的内积反映了两个POI之间的相关性,利用分层的softmax来学习潜在的向量。
我们提出了一种新的能够结合POI地理坐标的构建二叉树的方法,即将POI分到不同的区域中,在每个区域的POI上构建一个二叉树。由于一个POI可能会影响领近地区的POI,因此我们将一个POI分配给多个邻近区域。在生成的二叉树中,一个POI可能会出现多次,来描述其和其他POI的关系。此外,我们还对用户的偏好进行建模,即每个用户用一个潜在向量表示。
我们通过考虑用户偏好和顺序迁移来共同学习用户和POI的潜在表示。为了预测POI的潜在访问者,我们考虑最近位置的用户和最近位置未知的用户。对最近位置已知的用户,我们结合用户偏好和序列迁移进行预测,对于最近位置未知的用户,仅考虑用户偏好。主要工作:
- 结合POI的地理影响,预测未来几小时内的潜在访问者。
- 结合用户偏好和POI序列影响来预测POI的未来访问者。
Related Work
- 位置推荐,Lian et al. 2014; Li, Ge, and Zhu 2016
- 基于协同过滤方法的位置推荐,Yuan et al. 2013a; Ye et al. 2011
- 基于因子分解模型,Cheng et al. 2012; Li et al. 2015
- 对某个位置的用户推荐问题,Yuan et al. 2013b; Zhao et al. 2015
- 利用马尔科夫链对序列的影响建模,Zhang, Chow, and Li 2014
- 利用隐马尔科夫链模型对序列的影响建模,Ye, Zhu, and Cheng 2013
- 利用因式分解的个性化马尔科夫链(FPMC)模拟个性化的POI迁移,Rendle, Freudenthaler, and Schmidt-Thieme 2010
- 使用度量嵌入(Metric Embedding)来建模用户偏好和POI迁移进行建模,Feng et al。2015
- 考虑兴趣点推荐的时间影响,Zhang and Wang 2015; Zhao et al. 2016; Liu et al. 2016
- 合并类别转换模式,He et al. 2016
- 利用word2vec进行产品推荐,Wang et al. 2015
- 利用word2vec对签到序列进行建模,Liu, Liu, and Li 2016
Future Visitor Prediction Problem
我们用 U \mathcal{U} U来表示用户的集合,用 L \mathcal{L} L表示POI的集合,则每个POI l \mathcal{l} l都与其地理坐标 < l L a t , l L o n > <\mathcal{l}^{Lat},\mathcal{l}^{Lon}> <lLat,lLon>。 H \mathcal{H} H表示历史签到数据集。每一个签到元祖 ( u , l , t ) (\mathcal{u},\mathcal{l},\mathcal{t}) (u,l,t)表示用户 u \mathcal{u} u在时间 t \mathcal{t} t时访问地点 l \mathcal{l} l。给定POI,我们的目标是确定在几小时内将会访问POI的潜在访问者,定义如下:
定义1: 考虑用户集合 U \mathcal{U} U和POI集合 L \mathcal{L} L,给定POI l \mathcal{l} l,当前时间 t \mathcal{t} t和时间阈值 τ \mathcal{\tau} τ,问题目标是确定在时间内访问该POI的用户集合 [ t , t + τ ] [\mathcal{t}, \mathcal{t}+\mathcal{\tau}] [t,t+τ]。
POI2Vec Representation Model
POI2Vec序列转换模型
潜在的表示方法 神经网络语言模型(Mikolov and Dean 2013; Le and Mikolov 2014)的最新进展表明,潜在表示方法可以有效地捕捉到单词之间的顺序语义关系,我们通过对两个签到数据集的分析得出,POI频率分布也遵循幂律分布和词频分布。我们可以据此用word2vec对签到序列进行建模。
给定一个用户 u \mathcal{u} u以及其当前的位置 l c u \mathcal{l}_{\mathcal{c}}^{\mathcal{u}} lcu,上下文 C ( l c u ) C(\mathcal{l}_{\mathcal{c}}^{\mathcal{u}}) C(lcu)是用户 u \mathcal{u} u在访问 l c u \mathcal{l}_{\mathcal{c}}^{\mathcal{u}} lcu之前,在给定的时间域内访问的POI。我们定义 C ( l c u ) = { l c u , 0 < Δ ( l i u , l c u ) < τ } C(\mathcal{l}_{\mathcal{c}}^{\mathcal{u}})=\{\mathcal{l}_{\mathcal{c}}^{\mathcal{u}},0<\Delta(\mathcal{l}_{\mathcal{i}}^{\mathcal{u}},\mathcal{l}_{\mathcal{c}}^{\mathcal{u}})<\tau\} C(lcu)={lcu,0<Δ(liu,lcu)<τ},其中, Δ ( l i u , l c u ) \Delta(\mathcal{l}_{\mathcal{i}}^{\mathcal{u}},\mathcal{l}_{{c}}^{\mathcal{u}}) Δ(liu,lcu)是访问 l i u \mathcal{l}_{\mathcal{i}}^{\mathcal{u}} liu和 l c u \mathcal{l}_{\mathcal{c}}^{\mathcal{u}} lcu之间的时间间隔。POI序列建模的目标是给定POI的上下文,估计访问一个POI的概率。
对于每一个POI l l l,我们都用一个 D D D维潜在空间的向量 w ( l ) ∈ R D w(l)\in R^D w(l)∈RD表示,我们采用连续词袋模型(CBOW)(Mikolov and Dean 2013),即根据上下文预测某个词的概率。概率 P r ( l ∣ C ( l ) ) Pr(l|C(l)) Pr(l∣C(l))通过softmax定义如下:
P r ( l ∣ C ( l ) ) = e w ( l ) ⋅ Φ ( C ( l ) ) / Z ( C ( l ) ) Pr(l|C(l))=e^{w(l)\cdot \boldsymbol{\Phi}(C(l))}/Z(C(l)) Pr(l∣C(l))=ew(l)⋅Φ(C(l))/Z(C(l))
其中, Φ ( C ( l ) ) = ∑ l c ∈ C ( l ) w ( l c ) \boldsymbol{\Phi}(C(l))=\sum_{l_c\in C(l)} w(l_c) Φ(C(l))=∑lc∈C(l)w(lc)是上下文POI向量之和, Z ( C ( l ) ) = ∑ l i ∈ L e w ( l i ) ⋅ Φ ( C ( l ) ) Z(C(l))=\sum_{l_i\in\mathcal{L}}e^{w(l_i)\cdot \boldsymbol{\Phi}(C(l))} Z(C(l))=∑li∈Lew(li)⋅Φ(C(l))是正则项。
我们采用分层的softmax,利用二叉树进行计算。二叉树的节点对应于每一个POI项。
纳入地理影响 地理影响是建模序列迁移和用户偏好的一个非常重要的因素,而现有的基于频率的softmax结构不能捕捉到地理影响。因此我们为POI2Vec模型开发了一种地理二叉树结构,将空间信息合并到二叉树中。由于附近的POI具有较高的相关性,因此应将它们在二叉树中的位置也安排的更近。我们将POI划分为二元区域的层次结构,使得附近的POI更可能聚集到同一个区域来。为构建POI的二叉层次结构,我们将每个区域递归地分割成两个相同大小的子区域,知道区域至少有一边的长度小于 2 × θ 2\times\theta 2×θ,其中 θ \theta θ是区域边长大小的阈值。这样,区域就是一个面积大于 θ × θ \theta\times\theta θ×θ平方的矩形。这些地域也应该以二叉树的形式表示。如图所示,我们首先将POI分成两个相等的区域 R 0 R_0 R0和 R 1 R_1 R1。然后将 R 0 R_0 R0分成 R 00 R_{00} R00和 R 01 R_{01} R01,将 R 1 R_1 R1分成 R 10 R_{10} R10和 R 11 R_{11} R11。

为了将POI分配到其可能产生影响的多个区域,监狱用户的移动受到空间距离的影响,因此我们考虑了每个POI的影响区域。影响区域定义为以每个POI为中心的 θ × θ \theta\times\theta θ×θ大小的正方形。如果POI l l l的影响区域与二叉树中的区域 R R R重叠,则将 l l l分配给区域 R R R。例如,图中以POI l 1 l_1 l1为中心的正方形覆盖到了区域 R 01 R_{01} R01和 R 11 R_{11} R11,那么 l 1 l_1 l1就被分配到区域 R 01 R_{01} R01和 R 11 R_{11} R11中。
由于影响区域 θ × θ \theta\times\theta θ×θ的大小要小于区域,因此容易证明:
命题1: 在POI2Vec模型中,一个POI所属的区域数量为1,2或4
我们用 Ω l \Omega^l Ωl表示POI l l l的区域集合。如果一个POI被分配到多个区域买这些区域的概率分布计算方法如下: l l l属于区域 R i R_i Ri的概率是 P r ( R i ) = S R i l / ∑ R k ∈ Ω l S R k l Pr(R_i)=S_{R_i}^l/\sum_{R_k\in\Omega^l}S_{R_k}^l Pr(Ri)=SRil/∑Rk∈ΩlSRkl,其中 S R i l S_{R_i}^l SRil是 l l l的影响区域与区域 R i R_i Ri之间重叠部分的大小。
对于每个区域,我们根据POI的频率构建哈夫曼树(Mikolov and Dean 2013)。在生成的二叉树中,上层是空间区域,下层是每个区域的POI,如下图所示。一个POI可能会有多个路径,例如, l 1 l_1 l1在生成的二叉树中出现了两次,一次是在 R 01 R_{01} R01中,一次是在 R 11 R_{11} R11中。

POI2Vec的两个优点:
- 在构建二叉树的过程中,考虑了POI地理因素的影响,是的同一地区节点下的POI在地理上更加接近。
- 与传统每个POI只能出现一次相比,一个POI可以在二叉树中出现多次。
概率估计 分层的softmax模型通过估计从根节点到叶节点的路径概率来近似softmax。在二叉树中,叶子结点是POI,其他节点是内节点。每个内节点被视为一个二进制分类器,叶子结点 l l l的路径被定义为内节点的序列 p a t h = ( b 0 l , b 1 l , . . . , b n l ) path=(b_0^l,b_1^l,...,b_n^l) path=(b0l,b1l,...,bnl),则沿路径观察到 l l l的概率:
P r ( l ∣ C ( l ) ) p a t h = ∏ b i l ∈ p a t h P r ( b i l ∣ Φ ( C ( l ) ) ) Pr(l|C(l))^{path}=\prod_{b_i^l\in path}Pr(b_i^l|\Phi(C(l))) Pr(l∣C(l))path=bil∈path∏Pr(bil∣Φ(C(l)))
二叉树中每一个内节点 b b b都有一个潜在的向量 Ψ ( b i l ) ∈ R D \Psi(b_i^l)\in \mathcal{R}^D Ψ(bil)∈RD,可以看做是二元分类器的参数。这里的 P r ( b i l ∣ Φ ( C ( l ) ) ) Pr(b_i^l|\Phi(C(l))) Pr(bil∣Φ(C(l)))被定义为
P r ( b i l ∣ Φ ( C ( l ) ) ) = σ ( Ψ ( b i l ) ⋅ Φ ( C ( l ) ) ) Pr(b_i^l|\Phi(C(l)))=\sigma(\Psi(b_i^l)\cdot\Phi(C(l))) Pr(bil∣Φ(C(l)))=σ(Ψ(bil)⋅Φ(C(l)))
其中 σ ( x ) = 1 1 + e − x \sigma(x)=\cfrac{1}{1+e^{-x}} σ(x)=1+e−x1是sigmod函数。
例如,在图Figure2中, l 1 l_1 l1的一条路径是 p a t h 1 = ( b 0 , b 1 , b 4 , b i ) path_1=(b_0,b_1,b_4,b_i) path1=(b0,b1,b4,bi),对于二叉树中的分类器,我们将左边定义为"true",右边定义为"false"。则该路径的概率可以表示为 P r ( l 1 ∣ C ( l 1 ) ) p a t h 1 = σ ( Ψ ( b 0 ) ⋅ Φ ( C ( l 1 ) ) ) × ( 1 − σ ( Ψ ( b 1 ) ⋅ Φ ( C ( l 1 ) ) ) × σ ( Ψ ( b 4 ) ⋅ Φ ( C ( l 1 ) ) ) × σ ( Ψ ( b i ) ⋅ Φ ( C ( l 1 ) ) ) Pr(l_1|C(l_1))^{path1}=\sigma(\Psi(b_0)\cdot\Phi(C(l_1)))\times(1-\sigma(\Psi(b_1)\cdot\Phi(C(l_1)))\times\sigma(\Psi(b_4)\cdot\Phi(C(l_1)))\times\sigma(\Psi(b_i)\cdot\Phi(C(l_1))) Pr(l1∣C(l1))path1=σ(Ψ(b0)⋅Φ(C(l1)))×(1−σ(Ψ(b1)⋅Φ(C(l1)))×σ(Ψ(b4)⋅Φ(C(l1)))×σ(Ψ(bi)⋅Φ(C(l1)))
在POI2Vec模型中,由于每个POI都有多个所属区域,因此再生成树中一个POI可有多条路径。我们需要计算所有的概率。我们将 P ( l ) \mathcal{P}(l) P(l)定义为POI l l l的路径集合,每条路径 p a t h k path_k pathk与概率 P r ( p a t h k ) Pr(path_k) Pr(pathk)相关联,,其概率与区域概率 P r ( R k ) Pr (R_k) Pr(Rk)相同。则根据给定的上下文 C ( l ) C(l) C(l)计算观察到 l l l的概率为:
P r ( l ∣ C ( l ) ) = ∏ p a t h k ∈ P ( l ) P r ( p a t h k ) × P r ( l ∣ C ( l ) ) p a t h k Pr(l|C(l))=\prod_{path_k\in\mathcal{P}(l)}Pr(path_k)\times Pr(l|C(l))^{path_k} Pr(l∣C(l))=pathk∈P(l)∏Pr(pathk)×Pr(l∣C(l))pathk
参数学习: POI2Vec模型的目标是使得观察到的所有连续POI的后验概率最大化,假设观测值彼此独立:
Θ = a r g m a x Θ ∏ ( l , C ( l ) ) ∈ H P r ( l ∣ C ( l ) ) \Theta=arg max_{\Theta}\prod_{(l,C(l))\in\mathcal{H}}Pr(l|C(l)) Θ=argmaxΘ(l,C(l))∈H∏Pr(l∣C(l))
其中 Θ = { W ( L ) , Ψ ( B ) } \Theta=\{W(\mathcal{L}),\Psi(\mathcal{B})\} Θ={W(L),Ψ(B)}是参数集合。这里 W ( L ) W(\mathcal{L}) W(L)表示所有POI l ∈ L l\in\mathcal{L} l∈L的潜在表示, Ψ ( B ) \Psi(\mathcal{B}) Ψ(B)是内节点的参数集合。二叉树的叶子结点数是 ( a × ∣ L ∣ ) (a\times|\mathcal{L}|) (a×∣L∣),内节点数是 ( a × ∣ L − 1 ∣ ) (a\times|\mathcal{L}-1|) (a×∣L−1∣)。我们可以由Stochastic Gradient Descent (SGD)方法 (Rong 2014)获得所有的参数。
为用户偏好拓展POI2Vec模型
用户偏好是建模用户移动性和预测目标POI潜在用户的另一个重要因素。我们拓展了POI2Vec模型来共同学习POI的用户偏好和序列迁移。与POI类似,每个用户 u u u都由一个向量 x ( u ) ∈ R D x(u)\in\mathcal{R}^D x(u)∈RD来表示。
根据Feng et al. 2015可知,一些连续的POI之间时间间隔可能很大。我们规定对于在最近的时间间隔 τ \tau τ内没有上下文的签到,则该签到只与用户偏好有关。用户访问POI的概率估计为:
P r ( l ∣ u ) = e ( w ( l ) ⋅ x ( u ) ) / Z ( u ) Pr(l|u)=e^{(w(l)\cdot x(u))}/Z(u) Pr(l∣u)=e(w(l)⋅x(u))/Z(u)
其中, Z ( u ) = ∑ l i ∈ L e ( w ( l ) ⋅ x ( u ) ) Z(u)=\sum_{l_i\in\mathcal{L}}e^{(w(l)\cdot x(u))} Z(u)=∑li∈Le(w(l)⋅x(u))是正则项。与 P r ( l ∣ C ( l ) ) Pr(l|C(l)) Pr(l∣C(l))类似, P r ( l ∣ u ) Pr(l|u) Pr(l∣u)也可以由分层的softmax计算。
对于存在上下文的check-in,其受到用户偏好和上下文的共同影响,假设用户偏好与上下文相互独立,则给定用户 u u u和位置信息上下文 C ( l ) C(l) C(l), l l l的概率是:
P r ( l ∣ u , C ( l ) ) = P r ( l ∣ u ) × P r ( l ∣ C ( l ) ) Pr(l|u,C(l))=Pr(l|u)\times Pr(l|C(l)) Pr(l∣u,C(l))=Pr(l∣u)×Pr(l∣C(l))
根据上下文的存在与否,一个签到(check-in)的概率可计算为:
P r ( u , l , t ) = { P r ( l ∣ u , C ( l ) ) , i f C ( l ) e x i s t s P r ( l ∣ u ) , o t h e r w i s e Pr(u,l,t)=\left\{\begin{array}{cc} Pr(l|u,C(l)), & if\ C(l)\ exists\\ Pr(l|u), & otherwise \end{array}\right. Pr(u,l,t)={Pr(l∣u,C(l)),Pr(l∣u),if C(l) existsotherwise
模型的目标是最大化所有check-in的后验概率:
Θ = a r g m a x Θ ∏ ( u , l , t ) ∈ H P r ( u , l , t ) \Theta=arg\ max_\Theta \prod_{(u,l,t)\in\mathcal{H}}Pr(u,l,t) Θ=arg maxΘ∏(u,l,t)∈HPr(u,l,t)
其中, Θ = { W ( L ) , X ( U ) , Ψ ( B ) } \Theta=\{W(\mathcal{L}),X(\mathcal{U}),\Psi(\mathcal{B})\} Θ={W(L),X(U),Ψ(B)}是参数集合, X ( U ) X(\mathcal{U}) X(U)是所有用户的潜在表示。
预测未来的访问者
我们可以用学习到的用户 X ( U ) X(\mathcal{U}) X(U)的潜在表示和POI W ( L ) W(\mathcal{L}) W(L)的表示来找到将来访问POI的用户。
我们首先考虑最近几小时有签到记录的用户。给定时间点 t t t,如果一个用户在时间域 [ t − τ , t ] [t-\tau,t] [t−τ,t]内有签到记录,我们认为这个用户是一个具有近期位置的用户。对于这些用户,我们利用这些近期位置来确定他们访问特定POI的倾向。如果用户在 [ t − τ , t ] [t-\tau,t] [t−τ,t]期间访问了多个POI,我们只保留最新的POI l c l^c lc,这代表了他最新的位置。另外,我们也利用用户偏好。给定的目标POI l l l和用户 u u u以及其最新位置 l c l^c lc,未来 u u u访问 l l l的概率可定义为: F ( x ( u ) ⋅ w ( l ) , w ( l c ) ⋅ w ( l ) ) \mathcal{F}(x(u)\cdot w(l),w(l^c)\cdot w(l)) F(x(u)⋅w(l),w(lc)⋅w(l)),其中 x ( u ) ⋅ w ( l ) x(u)\cdot w(l) x(u)⋅w(l)反映了用户偏好, w ( l c ) ⋅ w ( l ) w(l^c)\cdot w(l) w(lc)⋅w(l)反应了序列影响。这里的 F ( ) \mathcal{F}() F()是一个结合用户偏好和序列影响的聚合函数。
聚合函数 F ( a , b ) = M a x ( a , b ) \mathcal{F}(a,b)=Max(a,b) F(a,b)=Max(a,b)通过取较大值来获得更重要的因素;而函数 F ( a , b ) = S u m ( a , b ) \mathcal{F}(a,b)=Sum(a,b) F(a,b)=Sum(a,b)是将两个因素进行线性组合。
对于过去几小时内没有签到记录的用户,我们只利用用户偏好来预测这些用户访问指定POI的可能性,由 x ( u ) ⋅ w ( l ) x(u)\cdot w(l) x(u)⋅w(l)计算获得。
对于每一个用户 u ∈ U u\in \mathcal{U} u∈U我们计算其分数:
s ( u , l ) = { F ( x ( u ) ⋅ w ( l ) , w ( l c ) ⋅ w ( l ) ) , w i t h r e c e n t p o s i t i o n s x ( u ) ⋅ w ( l ) , o t h e r w i s e s(u,l)=\left\{\begin{array}{cc} \mathcal{F}(x(u)\cdot w(l),w(l^c)\cdot w(l)), & with\ recent\ positions\\ x(u)\cdot w(l), & otherwise \end{array}\right. s(u,l)={F(x(u)⋅w(l),w(lc)⋅w(l)),x(u)⋅w(l),with recent positionsotherwise
我们按照分数对所有用户进行排名,并选择前K个用户作为目标位置的潜在访问者。
Experiments
数据集:
- the Foursquare check-ins within Singapore (Yuan et al. 2013a)
- the Gowalla check-ins within Houston (Liu et al. 2013)
预处理: 删除少于5个chenk-in纪录的用户和少于5个用户访问的POI。90%作为训练集,5%作为调整集,5%作为测试集。
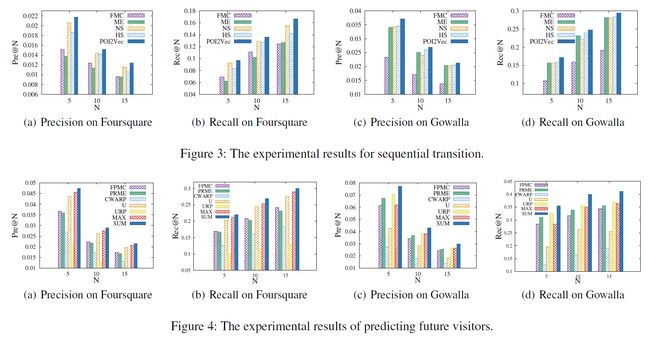
目标: - POI预测任务中评估序列迁移的潜在表示的质量。
- 评估未来游客预测的准确性。
参数设置:
时间域 τ = 6 h o u r s \tau=6\ hours τ=6 hours
维数 D = 200 D=200 D=200
区域大小阈值 θ = 0.1 \theta=0.1 θ=0.1
学习率0.005
序列转换的潜在表示
4个baseline的比较实验:
- FMC:分解的分解马尔可夫链模型(Rendle,Freudenthaler和Schmidt-Thieme 2010),它利用矩阵分解来模拟顺序转换。
- ME:矩阵嵌入模型(Feng et al。2015),
它将每个POI投射到一个潜在的欧几里得空间中的一个对象中。 - NS:word2vec的负采样(Mikolov and Dean 2013),用于建模POI序列(Liu,Liu,Li 2016)。
- HS:分层的softmax和哈夫曼树(Mikolov和Dean,2013)。
未来用户预测
3个baseline的比较试验:
- FPMC:分解个性化马尔可夫链,将用户偏好与马尔可夫转换线性结合(Cheng et al。2013)。
- PRME:个性化排名度量嵌入,它将用户偏好和马尔可夫过渡线性融合(Feng et al。,2015)。
- CWRAP:探索位置的上下文来建模用户偏好。
POI2Vec的4种方法:
- U:只利用用户的偏好来预测潜在的访问者。
- URP:我们只考虑有近期位置的用户。
- MAX:最大聚合函数。
- SUM:利用Sum聚合函数来整合用户偏好和序列影响。
实验结果
Conclusions and Future Work
一些研究问题存在进一步的探索方向。
首先,用户的运动受到多种因素的影响,我们可以考虑其他信息,如时间对访客预测问题的影响。
其次,我们构建二叉树的方法与空间上的各项没有关系,可以利用其他信息,如使用产品分类来进行产品推荐。