Flink 集群搭建(基于Standalone模式)
https://archive.apache.org/dist/flink/ flink各个稳定版本下载
本教程为flink-1.9.0版本
基于standalone的flink集群规划(基于standalone模式)【平时练习使用该模式,生产环境基本上都使用YARN模式】
| 主机名 |
IP |
说明 |
| centoshadoop1 |
192.168.227.140 |
StandaloneSessionClusterEntrypoint(主节点进程名称) |
| centoshadoop2 |
192.168.227.141 |
TaskManagerRunner(从节点进程名称) |
| centoshadoop3 |
192.168.227.142 |
TaskManagerRunner(从节点进程名称) |
| centoshadoop4 |
192.168.227.143 |
TaskManagerRunner(从节点进程名称) |
解压flink-1.9.0-bin-scala_2.11.tgz 到/home/hadoop/flink目录
tar -zxvf flink-1.9.0-bin-scala_2.11.tgz -C ~/flink
配置基本参数(结合机器情况调整)
cd /home/hadoop/flink/flink-1.9.0/conf
配置flink-conf.yaml,根据如下表格进行调整相应的参数
基础配置
| 参数 |
值 |
说明 |
| jobmanager.rpc.address |
centoshadoop1 |
jobmanager所在节点 |
| jobmanager.rpc.port |
6123 |
jobManager端口,默认为6123 |
| jobmanager.heap.size |
2048m |
jobmanager可用内存 |
| taskmanager.heap.size |
4096m |
每个TaskManager可用内存,根据集群情况指定 |
| taskmanager.numberOfTaskSlots |
3 |
每个taskmanager的并行度(5以内) |
| parallelism.default |
2 |
启动应用的默认并行度(该应用所使用总的CPU数) |
| rest.port |
8085 |
Flink web UI默认端口与spark的端口8081冲突,更改为8085 |
history server配置
| jobmanager.archive.fs.dir |
hdfs://mycluster/flink/log/hadoop-flink |
因为配置了hadoop的HA,所以hdfs nameservices 指定为mycluster |
| historyserver.web.address |
Centoshadoop1 |
historyserver web UI地址(需要在本地hosts文件中指定该映射关系) |
| historyserver.web.port |
18082 |
historyserver web UI端口 |
| historyserver.archive.fs.dir |
hdfs://mycluster/flink/log/hadoop-flink |
值与 jobmanager.archive.fs.dir 保持一致 |
| historyserver.archive.fs.refresh-interval |
10000 |
history server页面默认刷新时长 |
| 参数 |
值 |
说明 |
Flink配置文件——slaves
vi slaves
centoshadoop2
centoshadoop3
centoshadoop4
分发到其他节点
cd ~
scp -r flink/ hadoop@centoshadoop2:~/
scp -r flink/ hadoop@centoshadoop3:~/
scp -r flink/ hadoop@centoshadoop4:~/
cd /home/hadoop/flink/flink-1.9.0
bin/start-cluster.sh -- 启动集群
访问集群,界面如下(部分的参数配置)
http://centoshadoop1:8085/
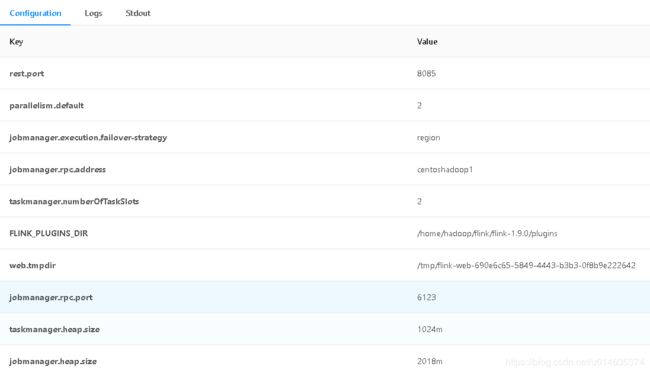
bin/stop-cluster.sh --停止集群
jps参考各个节点的进程
[hadoop@centoshadoop1 flink-1.9.0]$ jps
StandaloneSessionClusterEntrypoint
[hadoop@centoshadoop2 flink-1.9.0]$ jps
TaskManagerRunner
[hadoop@centoshadoop2 flink-1.9.0]$ jps
TaskManagerRunner
[hadoop@centoshadoop2 flink-1.9.0]$ jps
TaskManagerRunner
如果集群中Master节点的jobManager进程停止,或者机器重启导致进程停止,可以通过下面的命令启动或者停止
bin/jobmanager.sh start|stop
同理,如果想要手工停止TaskManager进程停止,或者想要向正在运行的集群中增加行的Slave节点,则可以使用如下命令
bin/taksmanager.sh start|stop
启动正常后,部分界面截图
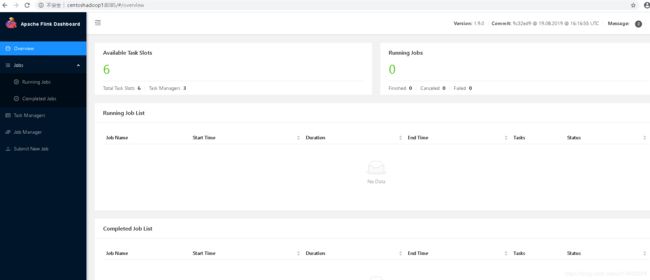
日志:
