【今日CS 视觉论文速览】8 Jan 2019
今日CS.CV计算机视觉论文速览
Tue, 8 Jan 2019
Totally 43 papers

Interesting:
附加:第二部分补充
-
Tencent ML-Images:腾讯发布大规模多标签数据集用于视觉表示学习。这一数据集包含了18M图片和11K的分类标签。用多标签的数据有助于提高视觉表现学习的效果。(from Tencent AI Lab)
数据集的统计信息:
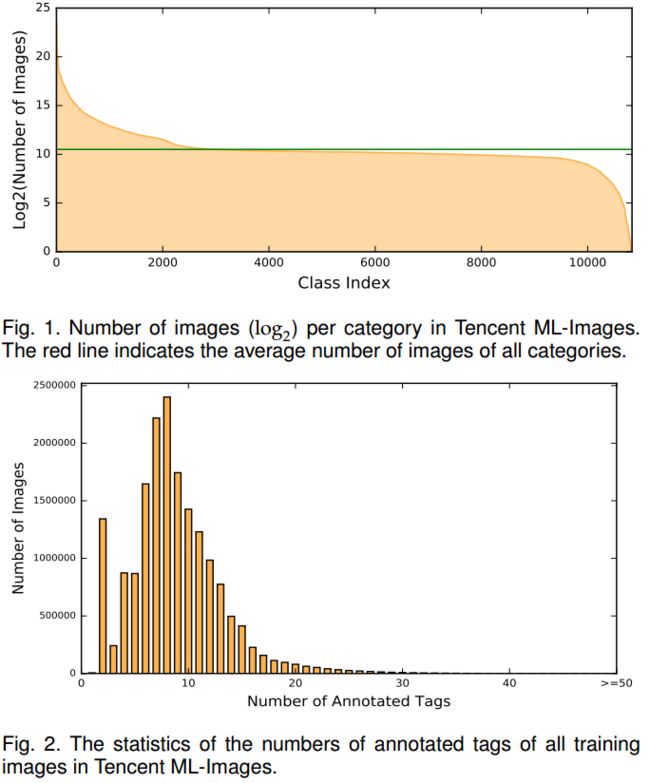
code and 数据集: https://github.com/Tencent/tencent-ml-images
分类标签:http://data.mxnet.io/models/imagenet-11k/
ref:ImageNet ,Caltech-256, object detection on PASCAL VOC 2007, semantic
segmentation on PASCAL VOC 2012.
tencent git:https://github.com/Tencent -
TridentNet,对于目标检测任务提出了一种控制感受野大小来实现多尺度检测的方法,使用共享参数来生成不同尺度的特征图,从而在不同的感受野大小上进行目标检测。具体实现通过改变最后一层卷积的膨胀比例来实现不同大小的感受野的。同时,研究人员还提出了基于不同尺度的训练方式,通过在不同尺度上提取合适的目标来训练不同尺度的检测分支,每个分支训练检测一定尺度范围内的样本。最终在COCO上达到了48.4的mAP。(from 中科院大学,图森等)


结果:
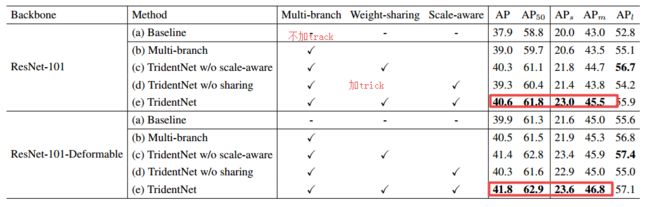
知乎:https://zhuanlan.zhihu.com/p/54334986
persons:https://www.zhihu.com/question/31168392/answer/50977180
Detectron: https://github.com/facebookresearch/ Detectron/blob/master/MODEL_ZOO.md
各种trick,包括sync BN,multi-scale training/testing,deformable conv,soft-nms -
基于图像超分辨来防御对抗样本攻击,利用图像超分辨将对抗样本从某一分类的流型外映射到对应标签的流型内,从而使得人眼无法察觉的对抗样本也能获得正确的结果,阻止对抗攻击。(from 智能感知研究所 阿布扎比)
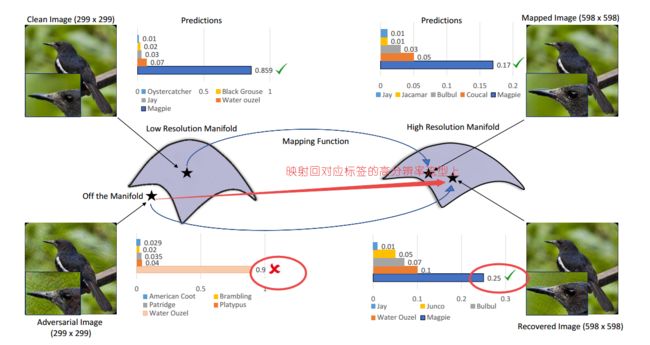
超分辨率恢复后频谱分布的有效性:
特征图:

code:https://github.com/aamir-mustafa/super-resolution-adversarial-defense
ref:
https://github.com/tensorflow/models/tree/master/research/slim
https://github.com/tensorflow/cleverhans
https://github.com/bethgelab/foolbox
https://github.com/dongyp13/Non-Targeted-AdversarialAttacks
https://github.com/cihangxie/DI-2-FGSM
https://github.com/poloclub/jpeg-defense
https://github.com/cihangxie/NIPS2017_adv_challenge_defense
https://github.com/facebookresearch/adversarial_image_defenses
https://github.com/iamaaditya/pixel-deflection
Foolbox :生成对抗样本的工具包 -
利用cycleGAN去除运动模糊,利用自编码器架构来实现去模糊,并利用新颖的训练策略恢复图像中的高频信号。(from 南京信息工程大学)

网络架构:
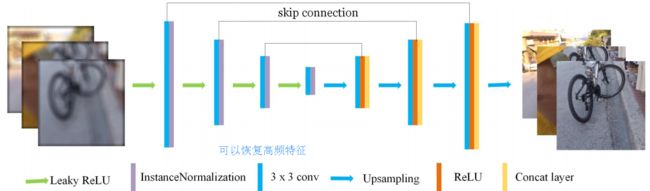
连续的训练策略,包括了从清晰图生成模糊图以及相反的过程:
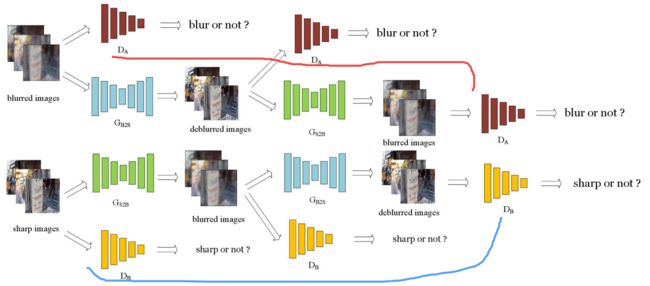
数据集样本:

数据集:GoPRO dataset:https://github.com/SeungjunNah/DeepDeblur_release
ref:
开源图像数据集总结:http://www.cnblogs.com/xiaojianliu/p/9446358.html
语义图像修复数据集总结:https://github.com/moodoki/semantic_image_inpainting--》Dataset (CelebA) [23], the Street View HouseNumbers (SVHN) [29] and the Stanford Cars Dataset [17].
GoPro-Gyro Dataset:http://www.cvl.isy.liu.se/research/datasets/gopro-gyro-dataset/ -
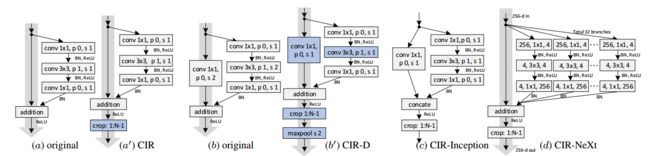
用于实时视觉追踪更深更宽的孪生网络,虽然孪生网络在视觉最终中具有很大的优势,但目前的基础网络相对较浅。为了研究网络深度和宽度对性能的影响,研究人员先将基础网络替换为ResNet和Inception等,但由于感受野变大使得特征图和定位精度下降,同时卷积补边造成了学习位置的偏移。随后研究人员提出了一种轻量级的实时残差模块,用于消除补边的影响,并利用新的架构控制感受野的大小。(from 中科院自动化所 微软)
文章中提出的内部裁剪残差单元:
dataset:OTB-15, VOT-16 and VOT-17 datasets
related Method:SiamFC,SiamRPN SRDCF SINT Staple ECO-HC PTAV DSiam CFNet StructSiam TriSiam
ref:https://www.cs.cmu.edu/~rsalakhu/papers/oneshot1.pdf
https://blog.csdn.net/shenziheng1/article/details/81290893 -
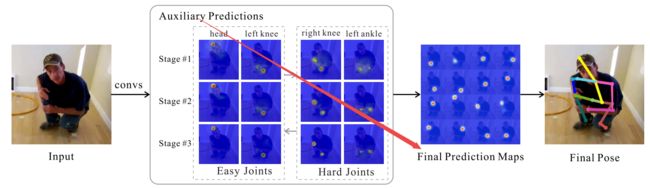
基于空间相关性的人体位姿估计,文章中提出了分层连续预测融合(Cascade Prediction Fusion ,CPF) 和 位姿图神经网络(Pose Graph Neural Network ,PGNN)来实现多级处理和潜在空间信息的利用。(from 百度等)
辅助预测到最终预测:
网络架构图:
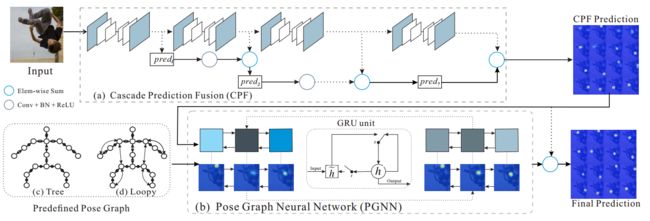
一些结果:
数据集:MPII](http://human-pose.mpi-inf.mpg.de/),LSP
ref:https://github.com/asanakoy/deeppose_tf -
少样本情况下“想象”出三维模型,通过学习出某个类别一个通用的mesh,随后旋转视角匹配目标图像的视角得到小样本下新目标的生成样本,(from SAP)

精炼的Self-paced结构:
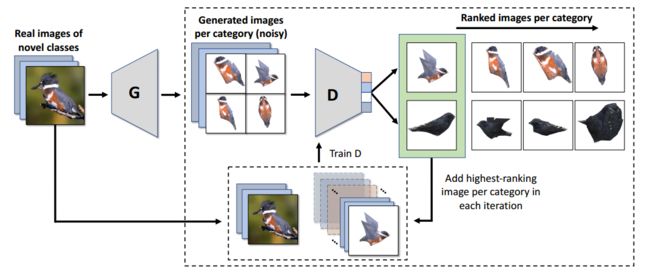
dataset: CUB-200-2011 -
DSConv,Distribution Shifting Convolution一种新的卷积操作,将通常的卷积操作分为了变化量化核Variable Quantized Kernel (VQK)与分布移动Distribution Shifts操作。通过VQK中的整数化操作减少内存提高速度,随后通过分布移动操作来保证输出的质量。(from Oxford)
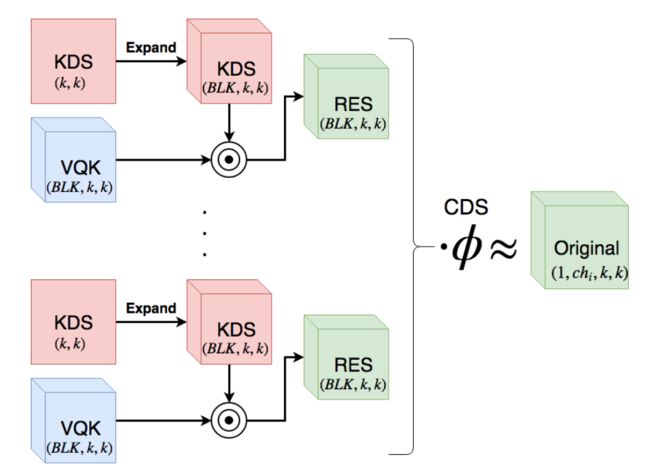
训练时DSC层的结构:

训练和推理的数据路径:
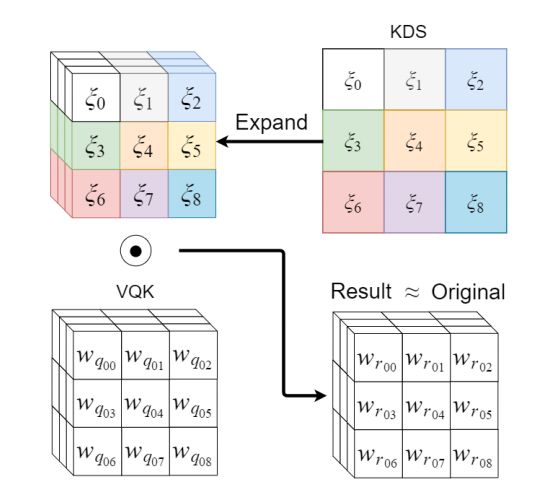
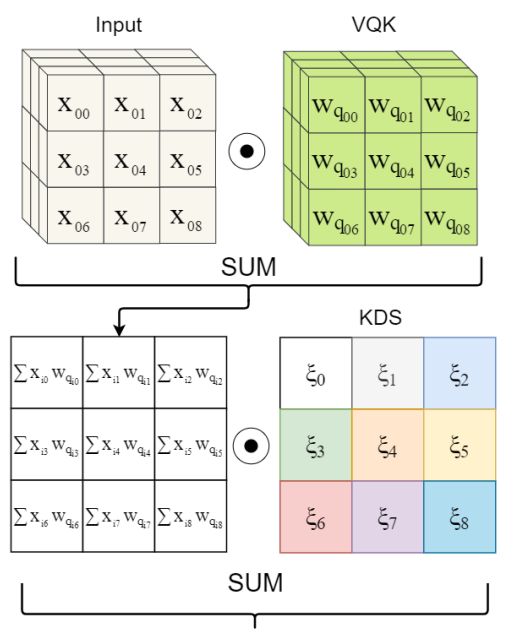
-
通过无标签的双目数据学习出独立个体的运动,可以通过双目数据预测出目标的运动和实例掩膜,并得到每个物体的运动方向和速度。(from 伯克利)
通过输入流预测出深图度和ROI区域的mask与流信息。
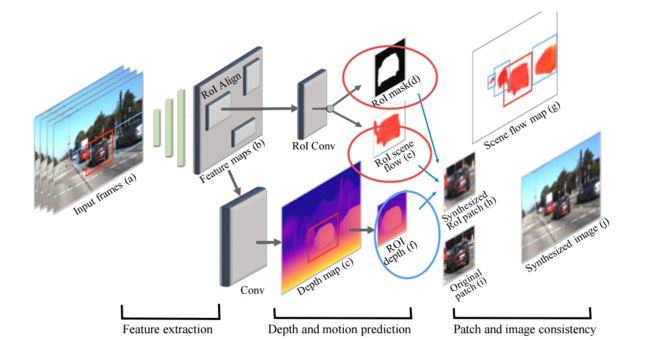
具体网络如下:
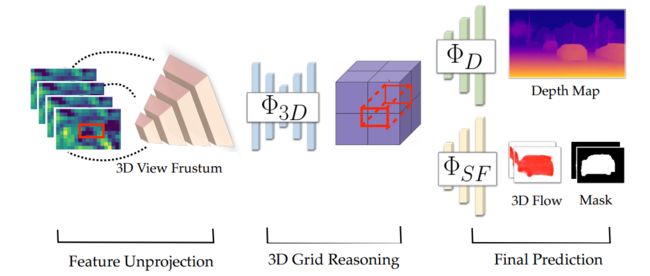
一些结果:


dataset:KITTI 2015,SYNTHIA dataset,Sintel dataset, FlyingChairsdataset, FlyingThings3D dataset
相关方法:Epicflow,FlowNET,GeoNET,DF-Net,UnFlowC -
基于帧间误差预测精确的下一帧图像,(from 杭州科技大学)
网络架构如下:
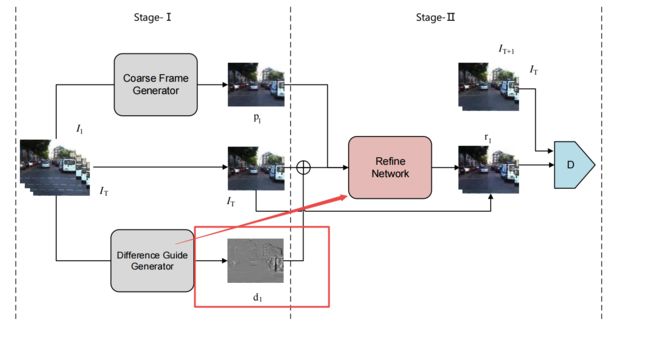
生成器具体架构:
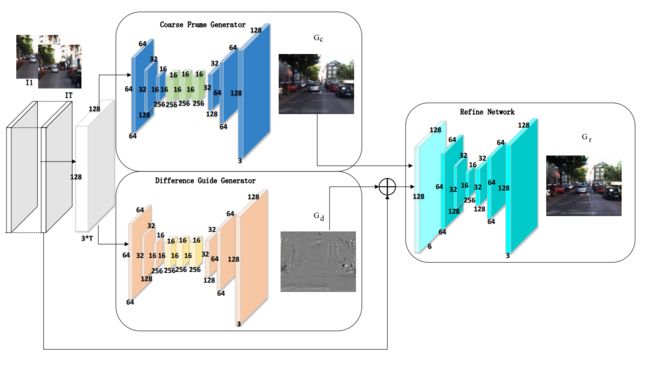
数据集: UCF-101,KITTI. -
预测虹膜以及分割
ref:http://zbum.ia.pw.edu.pl/EN/node/2
Daily Computer Vision Papers
[1] Title: Learning Independent Object Motion from Unlabelled Stereoscopic Videos
Authors:Zhe Cao, Abhishek Kar, Christian Haene, Jitendra Malik
[2] Title: Graph- and finite element-based total variation models for the inverse problem in diffuse optical tomography
Authors:Wenqi Lu, Jinming Duan, David Orive-Miguel, Lionel Herve, Iain B Styles
[3] Title: GASL: Guided Attention for Sparsity Learning in Deep Neural Networks
Authors:Amirsina Torfi, Rouzbeh A. Shirvani, Sobhan Soleymani, Naser M. Nasrabadi
[4] Title: DSConv: Efficient Convolution Operator
Authors:Marcelo Gennari, Roger Fawcett, Victor Adrian Prisacariu
[5] Title: On the Global Geometry of Sphere-Constrained Sparse Blind Deconvolution
Authors:Yuqian Zhang, Yenson Lau, Han-Wen Kuo, Sky Cheung, Abhay Pasupathy, John Wright
[6] Title: Scale-Aware Trident Networks for Object Detection
Authors:Yanghao Li, Yuntao Chen, Naiyan Wang, Zhaoxiang Zhang
[7] Title: NVS Machines: Learning Novel View Synthesis with Fine-grained View Control
Authors:Xu Chen, Jie Song, Otmar Hilliges
[8] Title: Mutual Context Network for Jointly Estimating Egocentric Gaze and Actions
Authors:Yifei Huang, Minjie Cai, Zhenqiang Li, Yoichi Sato
[9] Title: Low-Shot Learning from Imaginary 3D Model
Authors:Frederik Pahde, Mihai Puscas, Jannik Wolff, Tassilo Klein, Nicu Sebe, Moin Nabi
[10] Title: Fusing Body Posture with Facial Expressions for Joint Recognition of Affect in Child-Robot Interaction
Authors:Panagiotis P. Filntisis, Niki Efthymiou, Petros Koutras, Gerasimos Potamianos, Petros Maragos
[11] Title: Human Pose Estimation with Spatial Contextual Information
Authors:Hong Zhang, Hao Ouyang, Shu Liu, Xiaojuan Qi, Xiaoyong Shen, Ruigang Yang, Jiaya Jia
[12] Title: Double Weighted Truncated Nuclear Norm Regularization for Low-Rank Matrix Completion
Authors:Shengke Xue, Wenyuan Qiu, Fan Liu, Xinyu Jin
[13] Title: Post-mortem Iris Recognition with Deep-Learning-based Image Segmentation
Authors:Mateusz Trokielewicz, Adam Czajka, Piotr Maciejewicz
[14] Title: Universal Deep Beamformer for Variable Rate Ultrasound Imaging
Authors:Shujaat Khan, Jaeyoung Huh, Jong Chul Ye
[15] Title: Tencent ML-Images: A Large-Scale Multi-Label Image Database for Visual Representation Learning
Authors:Baoyuan Wu, Weidong Chen, Yanbo Fan, Yong Zhang, Jinlong Hou, Junzhou Huang, Wei Liu, Tong Zhang
[16] Title: Image Super-Resolution as a Defense Against Adversarial Attacks
Authors:Aamir Mustafa, Salman H. Khan, Munawar Hayat, Jianbing Shen, Ling Shao
[17] Title: Deeper and Wider Siamese Networks for Real-Time Visual Tracking
Authors:Zhang Zhipeng, Peng Houwen, Wang Qiang
[18] Title: Tooth morphometry using quasi-conformal theory
Authors:Gary P. T. Choi, Hei Long Chan, Robin Yong, Sarbin Ranjitkar, Alan Brook, Grant Townsend, Ke Chen, Lok Ming Lui
[19] Title: Better Guider Predicts Future Better: Difference Guided Generative Adversarial Networks
Authors:Guohao Ying, Yingtian Zou, Lin Wan, Yiming Hu, Jiashi Feng
[20] Title: Blind Motion Deblurring with Cycle Generative Adversarial Networks
Authors:Quan Yuan, Junxia Li, Lingwei Zhang, Zhefu Wu, Guangyu Liu
[21] Title: Healthy versus pathological learning transferability in shoulder muscle MRI segmentation using deep convolutional encoder-decoders
Authors:Pierre-Henri Conze, Sylvain Brochard, Valérie Burdin, Frances T. Sheehan, Christelle Pons
[22] Title: CC-Net: Image Complexity Guided Network Compression for Biomedical Image Segmentation
Authors:Suraj Mishra, Peixian Liang, Adam Czajka, Danny Z. Chen, X. Sharon Hu
[23] Title: Learning-Free Iris Segmentation Revisited: A First Step Toward Fast Volumetric Operation Over Video Samples
Authors:Jeffery Kinnison, Mateusz Trokielewicz, Camila Carballo, Adam Czajka, Walter Scheirer
[24] Title: Transductive Zero-Shot Learning with Visual Structure Constraint
Authors:Ziyu Wan, Dongdong Chen, Yan Li, Xingguang Yan, Junge Zhang, Yizhou Yu, Jing Liao
[25] Title: Segmentation Guided Image-to-Image Translation with Adversarial Networks
Authors:Songyao Jiang, Zhiqiang Tao, Yun Fu
[26] Title: Automated Multiscale 3D Feature Learning for Vessels Segmentation in Thorax CT Images
Authors:Tomasz Konopczyński, Thorben Kröger, Lei Zheng, Christoph S. Garbe, Jürgen Hesser
[27] Title: Unsupervised uncertainty estimation using spatiotemporal cues in video saliency detection
Authors:Tariq Alshawi, Zhiling Long, Ghassan AlRegib
[28] Title: RayNet: Learning Volumetric 3D Reconstruction with Ray Potentials
Authors:Despoina Paschalidou, Ali Osman Ulusoy, Carolin Schmitt, Luc van Gool, Andreas Geiger
[29] Title: What Should I Do Now? Marrying Reinforcement Learning and Symbolic Planning
Authors:Daniel Gordon, Dieter Fox, Ali Farhadi
[30] Title: Bilinear Supervised Hashing Based on 2D Image Features
Authors:Yujuan Ding, Wai Kueng Wong, Zhihui Lai, Zheng Zhang
[31] Title: Early Prediction of Alzheimer’s Disease Dementia Based on Baseline Hippocampal MRI and 1-Year Follow-Up Cognitive Measures Using Deep Recurrent Neural Networks
Authors:Hongming Li, Yong Fan
[32] Title: Deep Convolutional Neural Networks for Imaging Data Based Survival Analysis of Rectal Cancer
Authors:Hongming Li, Pamela Boimel, James Janopaul-Naylor, Haoyu Zhong, Ying Xiao, Edgar Ben-Josef, Yong Fan
[33] Title: Forensic Shoe-print Identification: A Brief Survey
Authors:Imad Rida, Sambit Bakshi, Xiaojun Chang, Hugo Proenca
[34] Title: Curriculum Model Adaptation with Synthetic and Real Data for Semantic Foggy Scene Understanding
Authors:Dengxin Dai, Christos Sakaridis, Simon Hecker, Luc Van Gool
[35] Title: Brain segmentation based on multi-atlas guided 3D fully convolutional network ensembles
Authors:Jiong Wu, Xiaoying Tang
[36] Title: Stereoscopic Dark Flash for Low-light Photography
Authors:Jian Wang, Tianfan Xue, Jonathan Barron, Jiawen Chen
[37] Title: Adaptive Fusion for RGB-D Salient Object Detection
Authors:Ningning Wang, Xiaojin Gong
[38] Title: AVA-ActiveSpeaker: An Audio-Visual Dataset for Active Speaker Detection
Authors:Joseph Roth, Sourish Chaudhuri, Ondrej Klejch, Radhika Marvin, Andrew Gallagher, Liat Kaver, Sharadh Ramaswamy, Arkadiusz Stopczynski, Cordelia Schmid, Zhonghua Xi, Caroline Pantofaru
[39] Title: Generic Primitive Detection in Point Clouds Using Novel Minimal Quadric Fits
Authors:Tolga Birdal, Benjamin Busam, Nassir Navab, Slobodan Ilic, Peter Sturm
[40] Title: Understanding the (un)interpretability of natural image distributions using generative models
Authors:Ryen Krusinga, Sohil Shah, Matthias Zwicker, Tom Goldstein, David Jacobs
[41] Title: MAE: Mutual Posterior-Divergence Regularization for Variational AutoEncoders
Authors:Xuezhe Ma, Chunting Zhou, Eduard Hovy
[42] Title: Channel Locality Block: A Variant of Squeeze-and-Excitation
Authors:Huayu Li
[43] Title: Projective Decomposition and Matrix Equivalence up to Scale
Authors:Max Robinson
Papers from arxiv.org
更多精彩请移步主页

pic from pixels.com