【今日CV 计算机视觉论文速览 第94期】 4 Apr 2019
今日CS.CV 计算机视觉论文速览
Thu, 4 Apr 2019
Totally 59 papers

Interesting:
?点云过分割直接到superpoints,研究人员将这一问题转为了如何计算局域几何特征和3D点的射线度量。利用轻量级网络在点云邻域计算出嵌入,并最终以图的方式表示出来。
首先计算每个点的嵌入,随后利用聚类实现过oversegmentation。

一些例子:
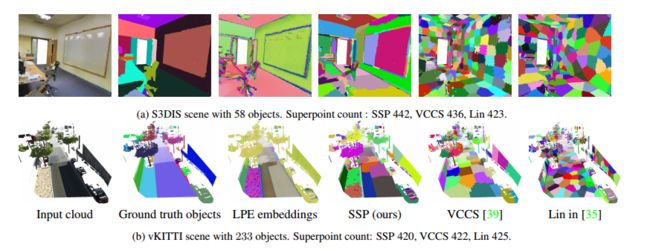
数据集:室外稠密(S3DIS) 室内稀疏(vKITTI)点云
ref:点云过分割,超体聚类
http://www.cnblogs.com/flyinggod/p/8473871.html
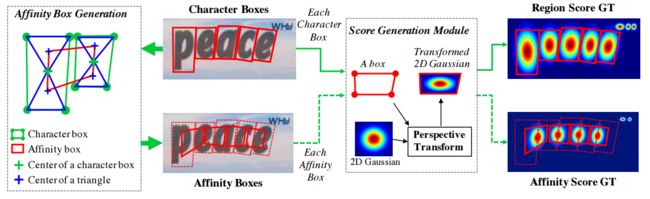
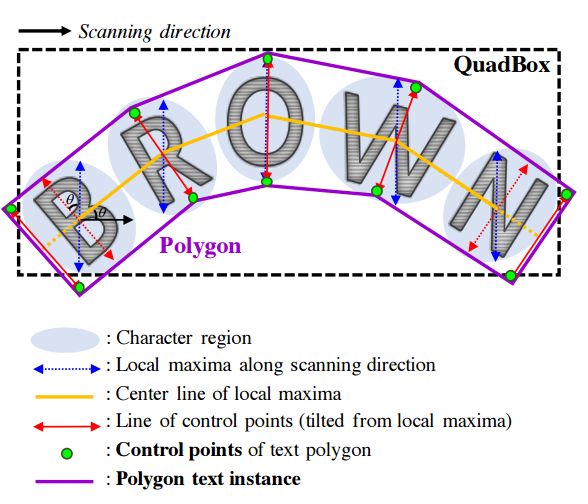
?CRAFT基于单个字符和字符间亲和力的场景文本检测, 与先前基于bbox、语义分割和字符检测的方法不同,这个文章提出了一种使用单个文字的标记和文件的亲和力来实现更好的目标检测。同时提出了一个从合成数据标记文字位置、从真实数据估计文章位置的框架。(from Clova AI Research, NAVER Corp.)
文章提出的标记如下,包含单个文字的标记和文字间的亲和力,利用变换的高斯函数来表示:
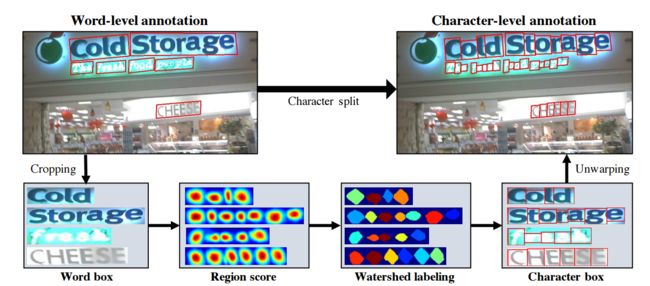
从词级别的标记到字符级别标记的过程:
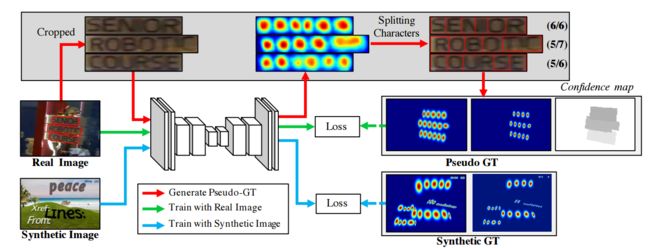
网络训练的流程如下图所示:
训练过程中分数的变化:
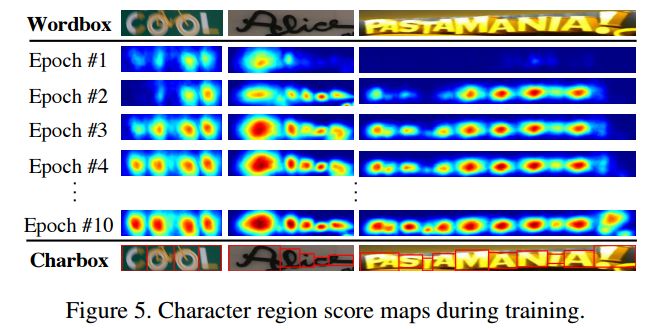
最终通过关键点生成多边形框的过程:
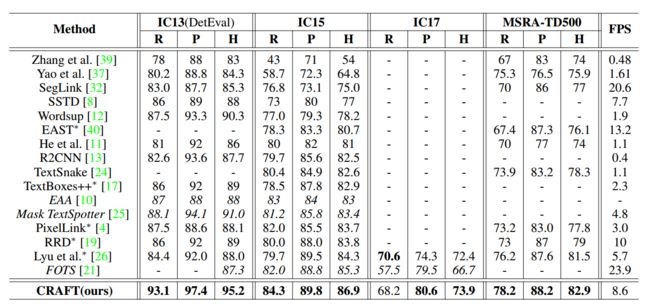
与一些方法的比较:
最终的而一些结果:

数据集:ICDAR2013,ICDAR2015,ICDAR2017,MSRA-TD500,TotalText,CTW-1500
?保边平滑基准数据集,数据集中每张图像包含了7种不同保边平滑算法的14中平滑结果。算法包括:SD filter [6], L0 smoothing [7], Fast Global Smoother (FGS) [8],Tree Filtering [9], Weighted Median Filter (WMF) [10], L1smoothing [12] and Local Laplacian filter (LLF) [11].首先选取每个算法的最优结果,再选取七个算法中的最优结果。

七种算法的计量和结果:
加权RMSE/MAE
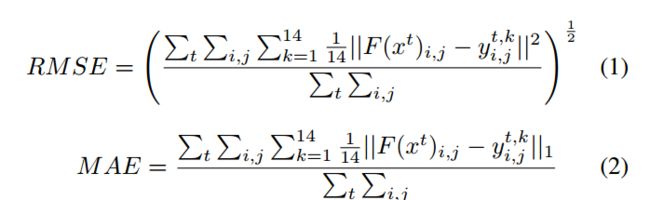
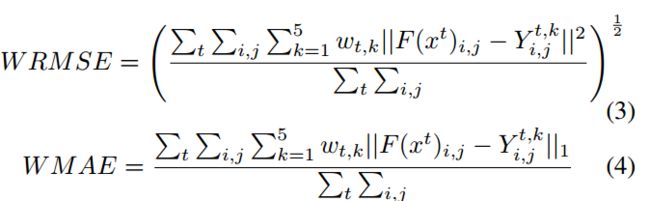

一些测评的网络架构:
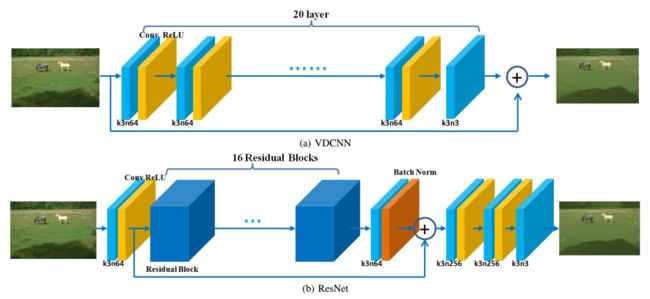
一些保边平滑的结果:


? D 2 D^2 D2-City, 滴滴平台行车记录仪数据集,包含多种路况下10000个视频片段,并为其中1000个片段提供了全帧的12类目标跟踪bbox(from 南加州大学)


?基于批量统计适应的小数据集(<100)图像生成,通过将预训练生成器进行迁移学习,在小数据集上微调,主要针对生成器隐含层的批量统计信息、尺度和偏移(from 东京大学 &RIKEN)
仅仅基于25个脸部图像的适应效果:

微调:
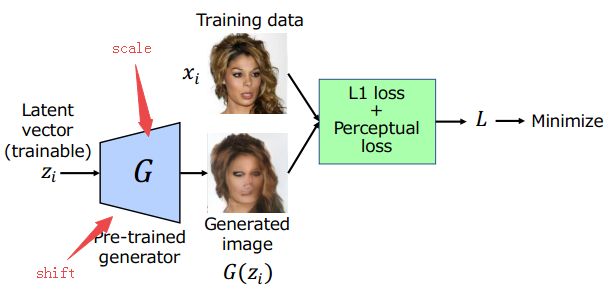
?基于嘴部图像和差分图像的视觉语音识别, (from 帝国理工)
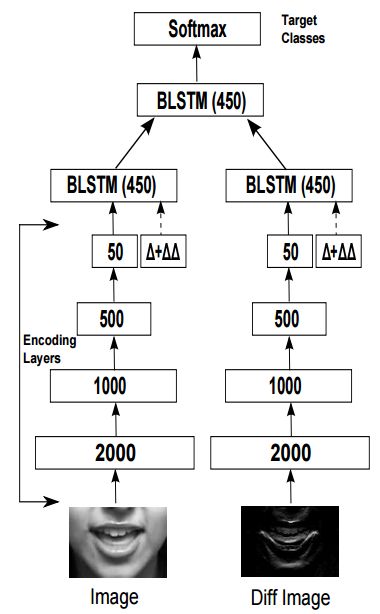
dataset:OuluVS2(Anina et al., 2015), AVLetters (Matthews et al., 2002),CUAVE (Patterson et al., 2002) and AVLetters2 (Cox et al.,2008).
?基于机器学习和高光谱数据集实现内陆水体叶绿素浓度的估计,基于分光计收集了与叶绿素2浓度对应的水体高光谱数据,并利用机器学习方法估计出叶绿素浓度。 (from Karlsruhe Institute of Technology)
分光计采集数据400 nm to 900 nm,并利用RF\SVM\ANN等机器学习方法来进行建模:

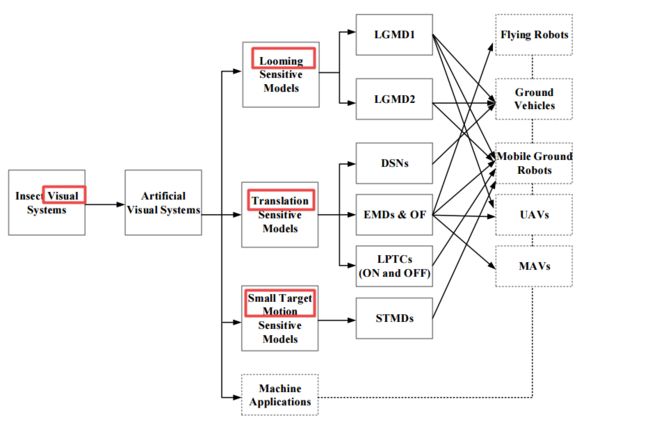
?昆虫视觉与运动感知review, (from 广州大学)
文章研究了几种模型及其应用:
Daily Computer Vision Papers
| Point Cloud Oversegmentation with Graph-Structured Deep Metric Learning Authors Loic Landrieu, Mohamed Boussaha 我们提出了一种新的超级学习框架,用于将3D点云划分为超级点。我们将此问题转化为学习局部几何的深嵌入和3D点的辐射测量,使得对象的边界呈现高对比度。使用在点局部邻域上操作的轻量级神经网络来计算嵌入。最后,我们将点云分割制定为关于学习嵌入的图分区问题。 |
| Exploring the Semantics for Visual Relationship Detection Authors Wentong Liao, Cuiling Lan, Wenjun Zeng, Michael Ying Yang, Bodo Rosenhahn 从图像中检测场景图构建视觉关系旨在给出对象节点及其关系边缘的精确结构描述。对象检测和关系检测的相互促进对于提高其个人表现很重要。在这项工作中,我们提出了一个新的框架,称为语义引导图关系神经网络SGRN,用于有效的视觉关系检测。首先,为了提高物体检测精度,我们引入了源目标类认知变换,该变换将共生对象的特征转换为目标对象域以细化视觉特征。类似地,源目标认知变换用于从关系的特征细化对象的特征,反之亦然。其次,为了提高关系检测的准确性,除了配对对象的视觉特征外,我们还分别嵌入了对象和主语的类概率,以提供高级语义信息。另外,为了减少关系的搜索空间,我们设计了一个语义感知关系过滤器来排除那些没有关系的对象。我们评估我们在Visual Genome数据集上的方法,它实现了视觉关系检测的最先进性能。此外,我们的方法还显着改善了物体检测性能,即mAP精度为4.2。 |
| FatSegNet : A Fully Automated Deep Learning Pipeline for Adipose Tissue Segmentation on Abdominal Dixon MRI Authors Santiago Estrada, Ran Lu, Sailesh Conjeti, Ximena Orozco Ruiz, Joana Panos Willuhn, Monique M.B Breteler, Martin Reuter 目的开发一种快速,全自动的深度学习管道FatSegNet,用于准确识别,分割和量化来自莱茵兰的Dixon MRI上的腹部脂肪组织研究一项基于人口的大型研究。方法FatSegNet由三个阶段组成:使用两个2D竞争密集完全卷积网络CDFNet对腹部区域进行一致定位,ii通过独立CDFNets在三个视图上分割脂肪组织,以及iii视图聚合。 FatSegNet使用33个手动注释的受试者进行训练,并通过1个比较分割准确性与覆盖范围广泛的体重指数BMI,2个测试再测试可靠性和3个健壮性的测试集进行验证。结果与传统的深度学习网络相比,CDFNet表现出更强的稳健性。 FatSegNet骰子评分优于腹部内脏脂肪组织VAT的手动评分,0.828对0.788,并且在皮下脂肪组织SAT上产生可比较的结果,0.973对0.982。该管道具有非常小的测试再测试绝对百分比差异和扫描会话之间的良好协议VAT APD 2.957,ICC 0.998和SAT APD 3.254,ICC 0.996。结论FatSegNet可以在1分钟内可靠地分析3D Dixon MRI。它广泛适用于不同的体形,在大型队列研究中敏感地复制已知的VAT和SAT体积效应,并允许对脂肪隔室进行局部分析。 |
| Learning for Multi-Type Subspace Clustering Authors Xun Xu, Loong Fah Cheong, Zhuwen Li 从假设和测试,代数和基于谱聚类的角度对子空间聚类进行了广泛的研究。大多数人假设只存在单个类型的子空间。对多种类型的推广是非常重要的,受到诸如模型类型和数量的选择,采样不平衡和参数调整等挑战的困扰。在这项工作中,我们将多类型子空间聚类问题表达为通过深层多层感知器mlps学习非线性子空间滤波器之一。对所学习的子空间滤波器的响应用作聚类友好的特征嵌入,即,相同聚类的点将通过网络更紧密地嵌入在一起。对于推理,我们将K均值应用于网络输出以对数据进行聚类。在合成和现实世界多类型拟合问题上进行实验,产生最先进的结果。 |
| A Visual Neural Network for Robust Collision Perception in Vehicle Driving Scenarios Authors Qinbing Fu, Nicola Bellotto, Huatian Wang, F. Claire Rind, Hongxin Wang, Shigang Yue 该研究解决了非常复杂和动态的真实物理场景中视觉碰撞检测的挑战性问题,特别是车辆驾驶场景。这项研究的灵感来自一个大型隐约敏感神经元,即蝗虫视觉通路中的小叶巨型运动探测器LGMD,它代表快速接近物体的高尖峰频率。基于我们以前的模型,在本文中,我们提出了一种新的抑制机制,能够适应不同水平的背景复杂性。该自适应机制有效地介导局部抑制强度并调节到达LGMD神经元的局部激发的时间延迟。因此,所提出的模型可以有效地从复杂的动态视觉场景中提取碰撞线索。我们使用一系列刺激测试了所提出的方法,包括光栅背景中的模拟运动和自然全景场景的移动,以及车辆碰撞视频序列。实验结果表明,该方法对于现实世界中的快速碰撞感知是可行的,具有在未来自动驾驶汽车中的潜在应用。 |
| Interpreting Adversarial Examples by Activation Promotion and Suppression Authors Kaidi Xu, Sijia Liu, Gaoyuan Zhang, Mengshu Sun, Pu Zhao, Quanfu Fan, Chuang Gan, Xue Lin 众所周知,卷积神经网络CNN易受具有难以察觉的扰动的对抗实例制作的图像的攻击。然而,文献中较少探讨这些扰动的可解释性。这项工作旨在更好地理解对抗性扰动的作用,并提供从像素,图像和网络角度的视觉解释。我们证明了对手对神经元激活有促进和抑制作用PSE,可以主要分为三种类型1抑制主导扰动,主要是降低真实标签的分类得分,2促进主导的扰动,侧重于提高目标的置信度标签和3个均衡的扰动,在抑制和促进中发挥双重作用。此外,我们提供了对抗性示例的图像级解释性,其将像素级扰动的PSE与通过类激活映射定位的类特定判别图像区域链接。最后,我们通过网络剖析分析对抗性例子的影响,这提供了隐藏单位的概念层次可解释性。我们表明,对单位内部反应的攻击敏感性与对语义概念的可解释性之间存在着紧密的联系。 |
| Estimating Chlorophyll a Concentrations of Several Inland Waters with Hyperspectral Data and Machine Learning Models Authors Philipp M. Maier, Sina Keller 水是生命,自然环境和人类健康的重要组成部分。为了监测水体的状况,叶绿素a浓度可以作为营养物和氧气供应的代表。水质参数的现场测量通常是耗时的,昂贵的并且在区域有效性方面受到限制。因此,我们应用遥感技术。在野外活动期间,我们用光谱仪收集了高光谱数据,并在原位测量了13种具有不同光谱特征的内陆水体的叶绿素a浓度。本研究的一个目的是通过应用三种机器学习回归模型随机森林,支持向量机和人工神经网络来估算这些内陆水域的叶绿素a浓度。此外,我们模拟光谱仪数据的四种不同高光谱分辨率,以研究对估计性能的影响。此外,依次评估光谱的一阶导数的应用以回归性能。该研究揭示了将机器学习方法与遥感数据结合用于内陆水域的潜力。对于叶绿素a浓度的回归,每个机器学习模型实现了在20到90之间的R2得分。随机森林模型从应用的光谱衍生物中明显受益。在进一步的研究中,我们将重点关注机器学习模型在光谱卫星数据上的应用,以加强对内陆水域叶绿素a浓度的区域广泛估计。 |
| Towards Computational Models and Applications of Insect Visual Systems for Motion Perception: A Review Authors Qinbing Fu, Hongxin Wang, Cheng Hu, Shigang Yue 运动感知是决定昆虫生活的各个方面的关键能力,包括避免掠食者,觅食等。已经在昆虫视觉通路中鉴定了许多运动检测器。这些运动检测器的计算建模不仅为人工智能提供了有效的解决方案,而且有助于理解复杂的生物视觉系统。通过数百万年的演化发展,这些生物机制将形成用于构建未来智能机器的动态视觉系统的可靠模块。本文回顾了文献中昆虫视觉系统生物学研究的计算运动感知模型。这些运动感知模型或神经网络包括蝗虫中小叶巨型运动探测器LGMD的隐约敏感神经元模型,果蝇,蜜蜂和蝗虫中方向选择性神经元DSN的平移敏感神经系统,以及小目标运动探测器STMDs蜻蜓和悬停苍蝇。我们还审查了这些模型在机器人和车辆上的应用。通过这些建模研究,我们总结了在运动感知中产生不同方向和尺寸选择性的方法。最后,我们讨论了这些生物启发运动感知模型的多系统集成和硬件实现。 |
| CAM-Convs: Camera-Aware Multi-Scale Convolutions for Single-View Depth Authors Jose M. Facil, Benjamin Ummenhofer, Huizhong Zhou, Luis Montesano, Thomas Brox, Javier Civera 单视图深度估计的问题在于,对来自一个摄像机的图像进行训练的网络不会推广到使用不同摄像机模型拍摄的图像。因此,更改相机模型需要收集全新的训练数据集。在这项工作中,我们提出了一种新的卷积方法,可以考虑相机参数,从而允许神经网络学习校准感知模式。实验证实,这显着改善了深度预测网络的泛化能力,并且当用不同的相机获取列车和测试图像时明显优于现有技术。 |
| Super accurate low latency object detection on a surveillance UAV Authors Maarten Vandersteegen, Kristof Vanbeeck, Toon goedeme 无人机已被证明在许多工业领域都很有用,例如安全和监视,例如,实时物体跟踪是自主飞行护卫的必需品。因此,在有限的硬件上实时跟踪和跟踪可疑对象。通过环路中的物体检测器,低延迟变得极为重要。在本文中,我们提出了一种解决方案,使无人机的物体检测既快速又超精确。我们提出了一种多数据集学习策略,产生顶部天空目标检测精度。我们的模型很好地概括了看不见的数据,可以应对不同的飞行高度,光学放大的镜头和不同的视角。我们应用优化步骤,通过融合层,将计算量化为16位浮点数和8位整数,实现嵌入式板载硬件的最小延迟,精度损失可忽略不计。我们在NVIDIA的Jetson TX2和Jetson Xavier平台上进行了验证,我们实现了超过10倍的速度性能提升。 |
| Invariance Matters: Exemplar Memory for Domain Adaptive Person Re-identification Authors Zhun Zhong, Liang Zheng, Zhiming Luo, Shaozi Li, Yi Yang 本文考虑从标记的源域和未标记的目标域学习重新ID模型的域自适应人识别重新ID问题。传统方法主要是减少源域和目标域之间的特征分布差距。然而,这些研究在很大程度上忽略了目标域中的域内变异,其包含影响目标域上的测试性能的关键因素。在这项工作中,我们全面研究目标域的域内变化,并建议概括重新ID模型w.r.t三种类型的基础不变性,即样本不变性,相机不变性和邻域不变性。为了实现这一目标,引入了示例性存储器来存储目标域的特征并适应三个不变性属性。内存允许我们在全局训练批处理上强制执行不变性约束,而不会显着增加计算成本。实验证明,三个不变性和提出的记忆对于有效的域适应系统是必不可少的。三个重新ID域的结果表明,我们的域适应精度大大超过了现有技术水平。代码可在 |
| Hybrid Cosine Based Convolutional Neural Networks Authors Adri Ciurana, Albert Mosella Montoro, Javier Ruiz Hidalgo 卷积神经网络CNN已经证明了它们能够在非常多的应用中解决不同类型的问题。然而,CNN因其计算和存储要求而受到限制。这些限制使得难以在诸如移动电话,智能相机或高级驾驶辅助系统的嵌入式设备上实现这种神经网络。在本文中,我们提出了一个名为Hybrid Cosine Based Convolution的新层,它使用余弦基替换标准卷积层来生成滤波器权重。所提出的层提供了在训练中更快收敛的若干优点,可以免费增加感受野并且显着减少参数的数量。我们在三个竞争性分类任务上评估我们提出的层,其中我们提出的层可以实现与VGG和ResNet架构类似且在某些情况下更好的性能。 |
| Stacked Semantic-Guided Network for Zero-Shot Sketch-Based Image Retrieval Authors Hao Wang, Cheng Deng, Xinxu Xu, Wei Liu, Xinbo Gao, Dacheng Tao 基于零拍摄草图的图像检索ZS SBIR是一个从自然图像库中检索跨域图像的任务,在零拍摄场景下具有自由手绘草图。以前的作品主要集中在一种生成方法,它将高度抽象和稀疏的草图作为输入,然后合成相应的自然图像。然而,草图的固有视觉稀疏性和大的类内方差使得条件解码器的学习更加困难,因此实现了不令人满意的检索性能。在本文中,我们提出了一种新的叠加语义引导网络,以解决ZS SBIR中草图的独特特征。具体来说,我们设计了多层特征融合网络,在深度神经网络中结合了不同的中间特征表示信息,以减轻草图的内在稀疏性。为了改善从可见类到看不见类的视觉知识转移,我们详细说明了粗到细条件解码器,它首先将辅助语义信息作为条件输入生成粗粒度类别特定对应特征,然后生成细粒度实例特定对应特征,将草图表示为条件输入。此外,利用回归损失和分类损失来分别保留合成特征的语义和判别信息。对大规模Sketchy数据集和TU Berlin数据集的大量实验表明,我们提出的方法在检索性能方面优于现有技术方法20多种。 |
| End-to-End Visual Speech Recognition for Small-Scale Datasets Authors Stavros Petridis, Yujiang Wang, Pingchuan Ma, Zuwei Li, Maja Pantic 传统的视觉语音识别系统包括两个阶段,即特征提取和分类。最近,已经提出了几种深度学习方法,其自动从嘴图像中提取特征并且旨在替换特征提取阶段。然而,关于特征和分类的联合学习的研究仍然有限。另外,大多数现有方法需要大量数据才能实现最先进的性能,否则它们将被执行。在这项工作中,我们提出了一个基于完全连接层和长短存储器LSTM网络的端到端视觉语音识别系统,适用于小规模数据集。该模型由两个流组成,这两个流分别直接从嘴和差异图像中提取特征。每个流中的时间动态由双向LSTM BLSTM建模,并且两个流的融合通过另一个BLSTM进行。 OuluVS2,CUAVE,AVLetters和AVLetters2数据库分别报告了超过现有技术的0.6,3.4,3.9,11.4的绝对改进。 |
| Character Region Awareness for Text Detection Authors Youngmin Baek, Bado Lee, Dongyoon Han, Sangdoo Yun, Hwalsuk Lee 最近出现了基于神经网络的场景文本检测方法,并且已经显示出有希望的结果使用刚性字级边界框训练的先前方法在以任意形状表示文本区域方面表现出限制。在本文中,我们提出了一种新的场景文本检测方法,通过探索每个字符和字符之间的亲和力来有效地检测文本区域。为了克服个别字符级别注释的缺乏,我们提出的框架利用合成图像的给定字符级注释和由学习的中间模型获取的真实图像的估计字符级别基础事实。为了估计字符之间的亲和性,使用新提出的关联性表示来训练网络。六个基准测试的广泛实验,包括TotalText和CTW 1500数据集,其中包含自然图像中的高度弯曲文本,表明我们的字符级文本检测明显优于现有技术的检测器。根据结果,我们提出的方法保证了检测复杂场景文本图像的高度灵活性,例如任意定向,弯曲或变形文本。 |
| CubiCasa5K: A Dataset and an Improved Multi-Task Model for Floorplan Image Analysis Authors Ahti Kalervo, Juha Ylioinas, Markus H iki , Antti Karhu, Juho Kannala 对建筑内部的更好理解和建模以及更令人印象深刻的AR VR技术的出现提出了对平面图图像的自动解析的需求。但是,显然缺乏有代表性的数据集来进一步调查问题。为了解决这个缺点,本文提出了一种名为CubiCasa5K的新型图像数据集,这是一个大型平面图图像数据集,包含5000个样本,注释到80多个平面图对象类别。通过使用多边形分离不同对象,以密集和通用的方式执行数据集注释。从基于强启发式和低级别像素操作的经典方法出发,我们提出了一种依赖于改进的多任务卷积神经网络的方法。通过发布新的数据集和我们的实施,这项研究显着推动了自动平面图图像分析的研究,因为它提供了更丰富的工具,以更全面的方式调查问题。 |
| ICface: Interpretable and Controllable Face Reenactment Using GANs Authors Soumya Tripathy, Juho Kannala, Esa Rahtu 本文介绍了一种能够控制给定面部图像的姿势和表情的通用面部动画师。动画由人类可解释的控制信号驱动,该控制信号包括头部姿势角度和动作单元AU值。控制信息可以从多个来源获得,包括外部驾驶视频和手动控制。由于驱动信号的可解释性质,人们可以容易地在多个源之间混合信息,例如从一个图像和另一个图像表达姿势,并应用选择性后期制作编辑。所提出的面部动画制作者被实现为两阶段神经网络模型,其使用大视频集合以自我监督的方式学习。将所提出的可解释和可控的面部再现网络ICface与基于多个任务的基于面部动画技术的现有神经网络进行比较。结果表明,ICface产生更好的视觉质量,同时比大多数比较方法更通用。引入的模型可以为大量高级图像和视频编辑任务提供轻量级且易于使用的工具。 |
| Multi-layered Spiking Neural Network with Target Timestamp Threshold Adaptation and STDP Authors Pierre Falez, Pierre Tirilly, Ioan Marius Bilasco, Philippe Devienne, Pierre Boulet 尖峰神经网络SNN是生产超高能效硬件的理想选择。然而,这些模型的性能目前落后于传统方法。引入多层SNN是减少这种差距的有希望的方法。我们在本文中提出了一种新的阈值适应系统,该系统使用了一个时间戳目标,在该目标下神经元应该触发我们展示了我们的方法导致MNIST数据集98.60和Faces Motorbikes数据集99.46的最新分类率,其中无监督SNN后跟线性SVM。我们还通过测试不同的抑制策略和STDP规则来研究网络的稀疏程度。 |
| What is wrong with scene text recognition model comparisons? dataset and model analysis Authors Jeonghun Baek, Geewook Kim, Junyeop Lee, Sungrae Park, Dongyoon Han, Sangdoo Yun, Seong Joon Oh, Hwalsuk Lee 近年来已经引入了许多关于场景文本识别STR模型的新提议。虽然每个声明都推动了技术的边界,但由于培训和评估数据集的选择不一致,在整个领域中已经大量缺乏整体和公平的比较。本文通过三个主要贡献来解决这一难题。首先,我们检查培训和评估数据集的不一致性,并且不一致导致性能差距。其次,我们引入了大多数现有STR模型适用的统一的四阶段STR框架。使用此框架可以对以前提出的STR模块进行广泛评估,并发现以前未开发的模块组合。第三,我们在一组一致的培训和评估数据集下分析模块在准确性,速度和内存需求方面对性能的贡献。这些分析消除了当前比较的障碍,以了解现有模块的性能增益。 |
| Semantic Bilinear Pooling for Fine-Grained Recognition Authors Xinjie Li, Chun Yang, Songlu Chen, Chao Zhu, Xucheng Yin 细粒度识别(例如,车辆识别或鸟类分类)自然具有特定的分层标签,其中精细水平总是比粗略水平更难分类。然而,大多数最近基于深度学习的方法忽略了细粒度对象的语义结构,并且没有利用传统的细粒度识别技术,例如,粗到细分类。在本文中,我们提出了一种新的框架,即语义双线性池,用于具有分层多标签学习的细粒度识别。该框架可以自适应地从分层标签中学习语义信息。具体而言,广义softmax损失被设计用于训练所提出的框架,以便通过考虑相邻级别之间的相关性来充分利用语义先验。在几个公共数据集上的各种实验表明,与其他最先进的方法相比,我们提出的方法具有非常令人印象深刻的性能和低特征尺寸。 |
| Beyond Tracking: Selecting Memory and Refining Poses for Deep Visual Odometry Authors Fei Xue, Xin Wang, Shunkai Li, Qiuyuan Wang, Junqiu Wang, Hongbin Zha 大多数先前基于学习的视觉测距VO方法将VO视为纯跟踪问题。相比之下,我们通过合并两个名为Memory和Refining的附加组件来呈现VO框架。存储器组件通过采用自适应和有效的选择策略来保留全局信息。精炼组件通过采用用于特征提取的空间时间关注机制来改善存储在存储器中的上下文的先前结果。对KITTI和TUM RGBD基准数据集的实验表明,我们的方法大大优于基于现有技术的学习方法,并且与经典的单眼VO方法产生竞争结果。特别是,我们的模型在具有挑战性的场景中实现了出色的性能,例如纹理较少的区域和突然的运动,其中经典的VO算法往往会失败。 |
| DADA: Depth-aware Domain Adaptation in Semantic Segmentation Authors Tuan Hung Vu, Himalaya Jain, Maxime Bucher, Matthieu Cord, Patrick P rez 无监督域适配UDA对于代表性数据的大规模注释具有挑战性的应用非常重要。特别是对于语义分段,它有助于部署在来自不同源域(特别是虚拟环境)的带注释图像上训练的真实目标域数据模型上。为此,大多数先前的工作认为语义分割是源域数据的唯一监督模式,而忽略了其他可能可用的信息,如深度。在这项工作中,我们的目标是在培训UDA模型的同时充分利用这样的特权信息。我们提出了一个统一的深度感知UDA框架,它以几种互补的方式利用源域中密集深度的知识。结果,提升了训练的语义分割模型在目标域上的性能。我们的新方法确实在不同的具有挑战性的合成2真实基准上实现了最先进的性能。 |
| Geometry-Aware Symmetric Domain Adaptation for Monocular Depth Estimation Authors Shanshan Zhao, Huan Fu, Mingming Gong, Dacheng Tao 由于先进的深度网络架构,监督深度估计已经实现了高精度。由于很难获得地面深度标签,最近的方法试图通过探索无监督的线索以无监督的方式学习深度估计网络,这些线索有效但不如真实标签可靠。解决这一难题的一种新兴方法是通过领域适应技术从具有地面真实深度的合成图像中传递知识。然而,这些方法忽略了目标域中的自然图像的特定几何结构,即真实数据,这对于高性能深度预测是重要的。在观察的推动下,我们提出了一种几何感知的对称域自适应框架GASDA,以共同探索实际数据中合成数据和极线几何中的标签。此外,通过在端到端网络中对称地训练两个图像样式转换器和深度估计器,我们的模型实现了更好的图像样式转换并生成高质量的深度图。实验结果证明了我们提出的方法的有效性和与现有技术相当的性能。代码将公开发布于 |
| A Comprehensive Overhaul of Feature Distillation Authors Byeongho Heo, Jeesoo Kim, Sangdoo Yun, Hyojin Park, Nojun Kwak, Jin Young Choi 我们研究了特征蒸馏方法实现网络压缩的设计方面,并提出了一种新的特征蒸馏方法,其中蒸馏损失旨在使教师变换,学生变换,蒸馏特征位置和距离函数等各方面协同作用。我们提出的蒸馏损失包括具有新设计的余量ReLU的特征变换,新的蒸馏特征位置和部分L2距离函数以跳过冗余信息,从而对学生的压缩产生不利影响。在ImageNet中,我们提出的方法使用ResNet50实现了21.65的前1个错误,其优于教师网络ResNet152的性能。我们提出的方法在各种任务上进行评估,例如图像分类,对象检测和语义分割,并在所有任务中实现显着的性能提升。 |
| Learning Context Graph for Person Search Authors Yichao Yan, Qiang Zhang, Bingbing Ni, Wendong Zhang, Minghao Xu, Xiaokang Yang 通过深度卷积神经网络,人员识别已取得很大进展。然而,大多数以前的方法都侧重于学习单个外观特征嵌入,并且模型很难处理具有不同照明,大的姿势变化和遮挡的困难情况。在这项工作中,我们更进一步,考虑使用上下文信息进行人员搜索。对于探测图库对,我们首先提出一个上下文实例扩展模块,该模块使用相对注意模块来搜索和过滤场景中的有用上下文信息。我们还构建了一个图学习框架,以有效地使用上下文对来更新目标相似性。这两个模块建立在联合检测和实例特征学习框架之上,这提高了学习特征的辨别力。所提出的框架在两个广泛使用的人物搜索数据集上实现了最先进的性能。 |
| Unsupervised Deep Tracking Authors Ning Wang, Yibing Song, Chao Ma, Wengang Zhou, Wei Liu, Houqiang Li 我们在本文中提出了一种无监督的视觉跟踪方法。与使用广泛注释数据进行监督学习的现有方法不同,我们的CNN模型以无人监督的方式在大规模未标记视频上进行训练。我们的动机是强健的跟踪器在前向和后向预测中应该是有效的,即,跟踪器可以在连续帧中向前定位目标对象并且回溯到第一帧中的初始位置。我们在Siamese相关滤波器网络上构建我们的框架,该网络使用未标记的原始视频进行训练。同时,我们提出了一种多帧验证方法和成本敏感性损失,以促进无监督学习。在没有花里胡哨的情况下,所提出的无监督跟踪器实现了全监督跟踪器的基线精度,这需要在训练期间完整且准确的标签。此外,无监督框架显示出利用未标记或弱标记数据的潜力,以进一步提高跟踪精度。 |
| SFNet: Learning Object-aware Semantic Correspondence Authors Junghyup Lee, Dohyung Kim, Jean Ponce, Bumsub Ham 我们解决了语义对应的问题,即在描绘相同对象或场景类别的不同实例的图像之间建立密集流场。我们建议使用带有二进制前景蒙版的注释图像并进行合成几何变形来训练卷积神经网络CNN以完成此任务。使用这些掩模作为监控信号的一部分,在语义流方法之间提供了良好的折衷,其中训练数据的数量受到手动选择点对应的成本的限制,以及语义对齐的方法,其中单个全局几何变换的回归图像可能对图像特定细节敏感,例如背景杂乱。我们提出了一个新的CNN架构,称为SFNet,它实现了这个想法。它利用argmax功能的新型和可区分版本进行端到端培训,并将掩模和流量一致性与平滑度相结合。实验结果证明了我们的方法的有效性,它在标准基准测试中明显优于现有技术水平。 |
| GFF: Gated Fully Fusion for Semantic Segmentation Authors Xiangtai Li, Houlong Zhao, Lei Han, Yunhai Tong, Kuiyuan Yang 语义分割通过密集预测每个像素的类别,在语义层面上生成对场景的全面理解。深度卷积神经网络的高级特征已经证明了它们在语义分割任务中的有效性,但是高级特征的粗分辨率通常会导致细小信息很重要但缺失的小型对象的结果较差。考虑导入低级功能以补偿高级表示中丢失的详细信息是很自然的。不幸的是,由于它们之间存在语义鸿沟,简单地组合多级特征的效果较差。在本文中,我们提出了一种名为Gated Fully Fusion GFF的新架构,以完全连接的方式使用门选择性地融合多个级别的特征。具体而言,每个级别的特征通过具有更强语义的更高级别特征和具有更多细节的更低级别特征来增强,并且门用于控制有用信息的传播,这显着降低了融合期间的噪声。我们在两个具有挑战性的场景理解数据集上实现了最先进的结果,即Cityscapes测试集上的82.3 mIoU和ADE20K验证集上的45.3 mIoU。代码和训练有素的模型将公开发布。 |
| Correlation Congruence for Knowledge Distillation Authors Baoyun Peng, Xiao Jin, Jiaheng Liu, Shunfeng Zhou, Yichao Wu, Yu Liu, Dongsheng Li, Zhaoning Zhang 基于知识蒸馏KD的大多数教师学生框架依赖于对实例级别的强烈一致性约束。但是,它们通常忽略多个实例之间的相关性,这对知识转移也很有价值。在这项工作中,我们提出了一个名为相关同余的新框架,用于知识蒸馏CCKD,它不仅传输实例级信息,还传输实例之间的相关性。此外,提出了一种基于泰勒级数展开的广义核方法,以更好地捕获实例之间的相关性。包括CIFAR 100,ImageNet 1K和包括ReID和人脸识别在内的度量学习任务的图像分类任务的经验实验和消融研究表明,与其他基于SOTA KD的方法相比,所提出的CCKD基本上优于原始KD并且达到了最先进的精度。 CCKD可以轻松部署在大多数教师学生框架中,例如KD和基于提示的学习方法。 |
| MAVNet: an Effective Semantic Segmentation Micro-Network for MAV-based Tasks Authors Ty Nguyen, Tolga Ozaslan, Ian D. Miller, James Keller, Shreyas Shivakumar, Giuseppe Loianno, Camillo J. Taylor, Vijay Kumar, Joseph H. Harwood, Jennifer Wozencraft 实时图像语义分割是增强机器人自主性和提高人类态势感知的基本能力。在本文中,我们提出了MAVNet,一种适用于小型微型飞行器MAV的语义分割的新型深度神经网络方法。我们的方法与小型MAV的典型尺寸,重量和功率SWaP约束兼容,小型MAV只能使用小型处理单元和GPU。这些单元通常具有有限的计算能力,其必须与其他实时性能任务(例如视觉测距和路径规划)同时共享。我们提出的解决方案MAVNet是一个受ERFNet启发的快速而紧凑的网络,相比之下,参数减少了约400倍。多个数据集的实验结果验证了我们提出的方法。此外,与其他最先进的方法进行比较表明,我们的解决方案在速度和准确度方面优于他们的解决方案,在处理高分辨率图像时,NVIDIA 1080Ti和NVIDIA Jetson Xavier上的FPS高达48 FPS。我们的算法和数据集是公开的。 |
| Soft Rasterizer: A Differentiable Renderer for Image-based 3D Reasoning Authors Shichen Liu, Tianye Li, Weikai Chen, Hao Li 渲染通过模拟图像形成的物理过程来弥合2D视觉和3D场景之间的差距。通过反转这样的渲染器,可以想到用于从2D图像推断3D信息的学习方法。然而,标准图形渲染器涉及称为光栅化的基本离散化步骤,其阻止渲染过程可区分,因此能够被学习。与现有技术的可微分渲染器不同,后者只接近反向传播中的渲染梯度,我们提出了一个真正可微分的渲染框架,它能够使用可微函数直接渲染彩色网格,并且将有效的监视信号传播到网格顶点和它们的属性来自各种形式的图像表示,包括轮廓,阴影和彩色图像。我们框架的关键是一种新颖的公式,它将渲染视为一种聚合函数,它融合了所有网格三角形相对于渲染像素的概率贡献。这样的公式使得我们的框架能够将梯度流到被遮挡的和远距离的顶点,这是先前的技术状态所不能实现的。我们表明,通过使用所提出的渲染器,可以在定性和定量上实现3D无监督单视图重建的显着改进。实验还表明,我们的方法能够处理基于图像的形状拟合中的具有挑战性的任务,这对于现有的可微分渲染器来说仍然是非常重要的。 |
| Patchwork: A Patch-wise Attention Network for Efficient Object Detection and Segmentation in Video Streams Authors Yuning Chai 单帧对象检测和分割技术的最新进展推动了广泛的工作以扩展这些方法以处理视频流。在本文中,我们探讨了针对延迟敏感应用程序的强烈关注的想法。我们的方法不是单独推理每个帧,而是选择并仅处理帧的一个小子窗口。然后,我们的技术基于来自先前帧的子窗口和来自当前子窗口的更新来对全帧进行预测。这种强硬注意机制的延迟减少是以降低精度为代价的。我们做了两件事来解决这个问题。首先,我们提出了一种专用存储单元,可以在处理子窗口时恢复丢失的上下文。其次,我们采用基于Q学习的策略培训策略,使我们的方法能够智能地选择子窗口,使得记忆中的陈旧性对性能的影响最小。我们的实验表明,我们的方法可以将延迟减少大约四倍,而不会显着牺牲ImageNet VID视频对象检测数据集和DAVIS视频对象分割数据集的准确性。我们进一步证明我们可以将所保存的计算再投资到网络的其他部分,从而导致以与原始系统相当的计算成本的准确度增加并且在低等待时间范围内击败其他最近提出的现有技术方法。 |
| Conditional Adversarial Generative Flow for Controllable Image Synthesis Authors Rui Liu, Yu Liu, Xinyu Gong, Xiaogang Wang, Hongsheng Li 基于流的生成模型由于其可逆的流水线和精确的对数似然目标而在图像合成中显示出巨大的潜力,但是其具有弱的条件图像合成能力,尤其是对于多标签或未知的条件。这是因为图像条件的潜在分布难以从其潜变量z精确测量。在本文中,基于对图像的联合概率密度及其条件的建模,我们提出了一种新的基于流动的生成模型,称为条件对抗生成流CAGlow。我们没有从潜在空间中解开属性,而是开辟了一条新的路径,用于学习编码器,以对抗方式估计从条件空间到潜在空间的映射。给定特定条件c,CAGlow可以将其编码为采样的z,然后在复杂情况下启用稳健的条件图像合成,例如将人物身份与多个属性相结合。所提出的CAGlow可以以有监督和无监督的方式实现,因此可以合成具有条件信息的图像,例如类别,属性,甚至一些未知属性。大量实验表明,CAGlow可确保不同条件的独立性,并在很大程度上优于常规Glow。 |
| Image Generation from Small Datasets via Batch Statistics Adaptation Authors Atsuhiro Noguchi, Tatsuya Harada 由于最近发展了深度生成模型,因此可以生成具有保真度和多样性的高质量图像。然而,对这种生成模型的培训需要大量数据集。为了减少所需的数据量,我们提出了一种新方法,用于将使用大型数据集训练的预训练发生器的先验知识传递到不同域中的小数据集。使用这样的先验知识,模型可以生成利用无法从小数据集获取的一些常识的图像。在这项工作中,我们提出了一种新方法,重点关注发电机中隐藏层的批量统计,比例和移位的参数。通过仅以受监督的方式训练这些参数,我们实现了对发生器的稳定训练,并且与先前的方法相比,我们的方法可以生成更高质量的图像,即使在数据集小的情况下也不会崩溃100。我们的结果表明,在预训练的发生器中获得的滤波器的多样性对于目标域上的性能是重要的。通过我们的方法,可以将新的类或域添加到预先训练的生成器而不会干扰原始域上的性能。 |
| Target-Aware Deep Tracking Authors Xin Li, Chao Ma, Baoyuan Wu, Zhenyu He, Ming Hsuan Yang 现有的深度跟踪器主要使用预训练用于表示的通用对象识别任务的卷积神经网络。尽管已经证明了许多视觉任务的成功,但使用预训练的深度特征进行视觉跟踪的贡献并不像对象识别那样重要。关键问题是在视觉跟踪中,感兴趣的目标可以是任意形式的任意对象类。因此,预先训练的深度特征在对这些任意形式的目标进行建模时不太有效,以将它们与背景区分开来。在本文中,我们提出了一种新的方案来学习目标感知特征,这可以更好地识别经历重大外观变化的目标而不是预先训练的深度特征。为此,我们开发回归损失和排名损失,以指导目标活动和规模敏感特征的生成。我们根据反向传播的梯度识别每个卷积滤波器的重要性,并基于用于表示目标的激活来选择目标识别特征。目标识别功能与Siamese匹配网络集成,用于视觉跟踪。大量实验结果表明,该算法在精度和速度方面均优于现有技术方法。 |
| M2KD: Multi-model and Multi-level Knowledge Distillation for Incremental Learning Authors Peng Zhou, Long Mai, Jianming Zhang, Ning Xu, Zuxuan Wu, Larry S. Davis 增量学习目标是在不忘记旧类别的情况下实现新类别的良好表现。知识蒸馏在保持旧班级表现方面显得至关重要。然而,传统方法仅从最后的模型中顺序地提取知识,导致在后续的增量学习步骤中对旧类的性能降级。在本文中,我们提出了一个多模型和多层次的知识蒸馏策略。我们不是直接从最后一个模型中提取知识,而是直接利用所有以前的模型快照。此外,我们采用辅助蒸馏来进一步保存在中间特征级别编码的知识。为了使模型更具内存效率,我们采用基于掩模的修剪来重建所有以前具有较小内存占用的模型。标准增量学习基准测试的实验表明,我们的方法可以更好地保留旧类的知识,并提高标准蒸馏技术的整体性能。 |
| VideoBERT: A Joint Model for Video and Language Representation Learning Authors Chen Sun, Austin Myers, Carl Vondrick, Kevin Murphy, Cordelia Schmid 自我监督学习对于利用YouTube等平台上丰富的无标签数据变得越来越重要。尽管大多数现有方法都学习低级表示,但我们提出了一种联合视觉语言模型,以便在没有任何明确监督的情况下学习高级特征。特别是,受其最近在语言建模方面取得的成功的启发,我们建立了BERT模型,以学习视觉和语言标记序列的双向关节分布,分别来自视频数据的矢量量化和现成的语音识别输出。我们在许多任务中使用此模型,包括动作分类和视频字幕。我们证明它可以直接应用于开放词汇分类,并确认大量的训练数据和交叉模态信息对性能至关重要。此外,我们在视频字幕方面优于现有技术,定量结果验证了该模型学习高级语义特征。 |
| Do not Omit Local Minimizer: a Complete Solution for Pose Estimation from 3D Correspondences Authors Lipu Zhou, Shengze Wang, Jiamin Ye, Michael Kaess 从给定的3D对应中估计姿势,包括点对点,点到线和点到平面的对应关系,是计算机视觉中具有许多应用的基本任务。我们为此任务提供了完整的解决方案,包括针对此问题的最小问题和最小二乘问题的解决方案。以前的工作主要集中在寻找全局最小化器来解决最小二乘问题。然而,显示实现全局最小化器的能力的现有工作仍然不适合于实时应用。此外,作为本文的贡献之一,我们证明了对于任意数量的线和平面存在模糊的配置。这些配置在理论上有几种解决方案,这使得正确的解决方案可能来自局部最小化器。我们的算法是有效的,能够揭示局部最小化。我们采用Cayley Gibbs Rodriguez CGR旋转参数化来得出三种3D对应情形的一般理性成本。本文的主要贡献是求解最小问题的最终方程系统和最小二乘问题的一阶最优性条件,两者都是复杂的有理形式。我们算法的核心思想是引入中间未知数来简化问题。大量的实验结果表明,当对应的数量很少时,我们的算法明显优于以前的算法。此外,当全局最小化器是解决方案时,我们的算法实现了与保证全局最优性的先前算法相同的精度,但是我们的算法适用于实时应用。 |
| Cross-Entropy Adversarial View Adaptation for Person Re-identification Authors Lin Wu, Richang Hong, Yang Wang, Meng Wang 人员识别ID是在不相交的摄像机视图下匹配行人的任务。要识别配对的快照,它必须处理由摄像机视图移位引起的大的交叉视图变化。监督的深度神经网络在产生一组非线性投影方面是有效的,这些投影可以将交叉视图图像转换成共同的特征空间。然而,它们通常会强制采用对称架构,从而使网络生成以其优化为条件。在本文中,我们使用对抗视图自适应方法学习人员重新ID的视图不变子空间及其相应的相似性度量。主要贡献是学习关于视图特征的耦合非对称映射,这些映射特征是通过优化交叉熵视图混淆目标而进行对抗训练以解决视图差异。为了确定相似性值,网络被赋予相似性鉴别器,以促进在区分正对和负对时高度判别的特征。另一个贡献包括对最困难的样本进行自适应权衡,以解决身份对之间的不平衡问题。与基准数据集的现有技术相比,我们的方法实现了显着的改进性能。 |
| Fully Using Classifiers for Weakly Supervised Semantic Segmentation with Modified Cues Authors Ting Sun, Lei Tai, Zhihan Gao, Ming Liu, Dit Yan Yeung 本文提出了一种仅使用图像级标签的弱监督语义分割方法。来自训练有素的分类器的类特定激活图被用作训练分割网络的线索。这些线索的众所周知的缺陷是粗糙和不完整。我们使用超级像素来细化它们,并融合从彩色图像训练分类器和灰度图像训练分类器提取的提示以补偿它们的不完整性。条件随机字段适于调节训练过程并进一步细化输出。除了初始化分段网络之外,先前训练的分类器还用于测试阶段以抑制不存在的类。 PASCAL VOC 2012数据集的实验结果说明了我们方法的有效性。 |
| Evaluation of the Spatio-Temporal features and GAN for Micro-expression Recognition System Authors Sze Teng Liong, Y.S. Gan, Danna Zheng, Shu Meng Lic, Hao Xuan Xua, Han Zhe Zhang, Ran Ke Lyu, Kun Hong Liu 由于人工智能的发展和进步,在人类面部表情识别系统中建立了许多工作。同时,微观表达的检测和分类近年来受到各研究界的关注。在本文中,我们首先回顾了传统光流识别系统的过程,包括面部标志注释,光流引导图像计算,特征提取和情感类分类。其次,已经提出了一些方法来改进特征提取部分,例如利用GAN来生成更多图像样本。特别地,计算光流的若干变化以便产生最佳图像以产生高识别精度。接下来,GAN(Generator和Discriminator的组合)用于生成新的假图像以增加样本大小。第三,提出了一种改进的现有卷积神经网络。为了验证所提出方法的有效性,在自发微表达数据库(即SMIC,CASME II和SAMM)上评估结果。本文报告了F1得分和准确性绩效指标。 |
| FaceQnet: Quality Assessment for Face Recognition based on Deep Learning Authors Javier Hernandez Ortega, Javier Galbally, Julian Fierrez, Rudolf Haraksim, Laurent Beslay 在本文中,我们开发了一种基于深度学习的人脸识别质量评估方法。该方法由卷积神经网络FaceQnet组成,该网络用于预测特定输入图像对于面部识别目的的适合性。 FaceQnet的培训使用VGGFace2数据库完成。我们使用BioLab ICAO框架标记VGGFace2图像,其中包含与其ICAO合规水平相关的质量信息。使用FaceNet获得地面质量标签以生成比较分数。我们使用groundtruth数据来微调基于ResNet的CNN,使其能够为每个输入图像返回数字质量测量。最后,我们验证FaceQnet分数是否适合预测使用特定图像进行面部识别时使用COTS人脸识别系统的预期性能。从这项工作中可以得出几个结论,最值得注意的是1我们设法采用现有的ICAO合规框架和预训练的CNN来自动标记数据和质量信息,2我们通过微调预先训练的人脸识别网络训练FaceQnet进行质量评估ResNet在图50和图3中,我们已经表明来自FaceQnet的预测与在开发期间未使用的现有技术系统的面部识别准确度高度相关。 FaceQnet在GitHub上公开发布。 |
| SADIH: Semantic-Aware DIscrete Hashing Authors Zheng Zhang, Guo sen Xie, Yang Li, Sheng Li, Zi Huang 由于其低存储成本和快速查询速度,已经认识到散列在大规模多媒体检索应用中实现相似性搜索。通过利用标签信息来保持汉明空间中数据点的成对相似性,特别受监督的哈希最近得到了相当多的研究关注。然而,仍然存在两个关键瓶颈1完全成对相似性保存的学习过程在计算上难以承受并且不可扩展以处理大数据2未充分研究数据的可用类别信息以学习判别性散列函数。为了克服这些挑战,我们提出了一种统一的语义感知DIscrete Hashing SADIH框架,旨在将转换后的语义信息直接嵌入到非对称相似性近似和判别性哈希函数学习中。具体地,引入语义意识潜在嵌入以不对称地保持完全成对相似性,同时巧妙地处理麻烦的n次n次成对相似性矩阵。同时,开发了语义感知自动编码器,以共同保留判别潜在语义空间中的数据结构并执行数据重建。此外,提出了一种有效的交替优化算法来解决由此产生的离散优化问题。在多个大规模数据集上的广泛实验结果表明,我们的SADIH可以明显优于现有技术基线,并具有较低的计算成本。 |
| Deep Policy Hashing Network with Listwise Supervision Authors Shaoying Wang, Haijiang Lai, Yifan Yang, Jian Yin 基于深度网络的散列已成为大规模图像检索的主要方法,其学习相似性保持网络以将类似图像映射到附近的哈希码。成对和三重损失是深度散列的两种广泛使用的相似性保持方式。这些方式忽略了散列是二进制代码列表上的预测任务这一事实。然而,在深度网络的批量大小总是很小的情况下如何获得整个训练集的等级列表以及如何利用列表监督,在列表监督中学习深度哈希是具有挑战性的。在本文中,我们提出了一种新颖的深度策略哈希体系结构,其中两个系统并行学习查询网络和共享且缓慢变化的数据库网络。重复以下三个步骤直到收敛1数据库网络将所有训练样本编码为二进制代码以获得整个秩列表,2基于策略学习训练查询网络以最大化表示整个排名列表的表现的奖励。二进制代码,例如,平均精度MAP,以及数据库网络被更新为查询网络。对几个基准数据集的广泛评估表明,所提出的方法对现有技术的散列方法带来了实质性的改进。 |
| 3DRegNet: A Deep Neural Network for 3D Point Registration Authors G. Dias Pais, Pedro Miraldo, Srikumar Ramalingam, Venu Madhav Govindu, Jacinto C. Nascimento, Rama Chellappa 我们提出3DRegNet,一种用于3D扫描注册的深度学习算法。随着最近廉价的3D商品传感器的出现,开发基于学习的3D配准算法将是有益的。给定一组3D点对应,我们使用深度残差层和卷积层构建深度神经网络,以实现两个任务:将点对应分类为正确的不正确的,以及可以将扫描对齐到的运动参数的2个回归共同参考框架。 3DRegNet与传统方法相比具有几个优势。首先,由于3DRegNet处理点对应而不是原始扫描,因此我们的方法比许多传统方法快得多。其次,我们表明该算法可以扩展到多视图场景,即同时处理两次以上扫描的注册。与使用四元数表示旋转的姿势回归网络相比,我们使用李代数仅使用三个变量来表示旋转。对两个具有挑战性的数据集(即ICL NUIM和SUN3D)进行了大量实验,证明我们的表现优于其他方法,并取得了最新成果。代码将可用。 |
| Multigrid Predictive Filter Flow for Unsupervised Learning on Videos Authors Shu Kong, Charless Fowlkes 我们介绍了多重网格预测滤波器流程mgPFF,一个用于视频无监督学习的框架。 mgPFF将每个像素滤波器的一对帧和输出作为输入,以将一帧与另一帧相交。与用于翘曲帧的光流相比,mgPFF在建模子像素移动和处理例如运动模糊的损坏方面更有效。我们开发了一种多重网格从粗到精的建模策略,避免了学习大型过滤器来捕获大位移的要求。这使我们能够训练一个非常紧凑的4.6MB型号,它以多种分辨率和共享权重逐步运行。我们在无监督的自由形式视频上训练mgPFF,并表明mgPFF不仅能够估计帧重建的长距离流量并检测视频镜头过渡,而且还可以轻松修改视频对象分割和姿势跟踪,其中它大大优于已发布的状态没有花里胡哨的艺术品。此外,由于每像素滤波器预测的mgPFF性质,我们有独特的机会可视化每个像素在解决这些任务期间如何演变,从而获得更好的可解释性。 |
| Monocular 3D Object Detection Leveraging Accurate Proposals and Shape Reconstruction Authors Jason Ku, Alex D. Pon, Steven L. Waslander 我们提出MonoPSR,一种利用提议和形状重建的单目3D物体检测方法。首先,使用针孔相机模型的基本关系,来自成熟2D对象检测器的检测用于在场景中为每个对象生成3D提议。这些提议的3D位置证明是非常准确的,这大大降低了回归最终3D边界框检测的难度。同时,在物体中心坐标系中预测点云以学习局部尺度和形状信息。然而,关键的挑战是如何利用形状信息来指导3D本地化。因此,我们设计总损失,包括新颖的投影对准损失,以共同优化神经网络中的这些任务,以提高3D定位精度。我们在KITTI基准测试中验证了我们的方法,我们在已发布的单眼方法中设置了新的最先进的结果,包括更难的行人和骑车者类,同时保持有效的运行时间。 |
| Activity Driven Weakly Supervised Object Detection Authors Zhenheng Yang, Dhruv Mahajan, Deepti Ghadiyaram, Ram Nevatia, Vignesh Ramanathan 弱监督物体检测旨在减少训练检测模型所需的监督量。传统上,这些模型是从仅用对象类标记的图像视频而不是对象边界框中学习的。在我们的工作中,我们不仅尝试利用对象类标签,还尝试利用与数据关联的操作标签。我们展示了图像视频中描绘的动作可以提供关于相关对象的位置的强烈提示。我们根据动作学习对象的空间先验。球在踢球时更靠近人的腿,并且在同时训练关节物体检测和动作分类模型之前将其结合。我们对视频数据集和图像数据集进行了实验,以评估我们的弱监督对象检测模型的性能。在Charades视频数据集中,我们的方法在mAP中超过当前最先进的SOTA方法超过6。 |
| Identifying disease-free chest X-ray images with deep transfer learning Authors Ken C. L. Wong, Mehdi Moradi, Joy Wu, Tanveer Syeda Mahmood 胸部X射线CXR是最常用的医学图像模式之一。它们主要用于筛查,并且疾病的指征通常导致随后的测试。由于这主要是用于排除胸部异常的筛查测试,因此请求的临床医生通常对CXR是否正常感兴趣。机器学习算法能够准确地筛选出所有请求的CXR中的一小部分真实正常检查,这将极大地有利于减少放射科医师的工作量。在这项工作中,我们报告了一个深度神经网络,该网络经过培训,可以对CXR进行分类,目的是识别大量正常无疾病图像,而不会冒病人患病。我们使用ImageNet预训练的Inception ResNet v2模型来提供图像特征,这些特征进一步用于训练专家放射科医师标记的CXR上的模型。分类的概率阈值针对正常类别优化为100精度,确保不释放病人。在此阈值,我们报告平均召回50。这意味着所提出的解决方案有可能减少放射科医师检查的无疾病CXR数量的一半,而不会冒病人患病的风险。 |
| MVX-Net: Multimodal VoxelNet for 3D Object Detection Authors Vishwanath A. Sindagi, Yin Zhou, Oncel Tuzel 最近关于3D对象检测的许多工作都集中在设计可以消耗点云数据的神经网络架构上。虽然这些方法表现出令人鼓舞的表现,但它们通常基于单一模态,并且无法利用来自其他模态的信息,例如相机。虽然一些方法融合了来自不同模态的数据,但这些方法要么使用复杂的流水线来顺序处理模态,要么进行后期融合,并且无法在早期阶段学习不同模态之间的相互作用。在这项工作中,我们通过利用最近推出的VoxelNet架构,为PointFusion和VoxelFusion提供了两种简单而有效的早期融合方法,以结合RGB和点云模式。对KITTI数据集的评估表明,与仅使用点云数据的方法相比,性能有了显着提高。此外,所提出的方法提供了与现有技术多模式算法竞争的结果,通过使用简单的单级网络,在KITTI基准上的六个鸟瞰图和3D检测类别中的五个中实现前2排名。 |
| Sparse Bounded Degree Sum of Squares Optimization for Certifiably Globally Optimal Rotation Averaging Authors Matthew Giamou, Filip Maric, Valentin Peretroukhin, Jonathan Kelly 估计噪声测量中的未知旋转是SfM和其他3D视觉任务中的重要步骤。通常,易于返回次优局部最小值的局部优化方法用于解决旋转平均问题。利用凸松弛的新一波方法为涉及SO 3的状态估计技术提供了全局最优性的第一种形式保证。但是,大多数这些保证仅适用于噪声引入的测量误差在某个范围内,该范围取决于问题实例的结构。在本文中,我们将旋转平均作为多项式优化问题转换为单位四元数,以产生第一个旋转平均方法,该方法正式保证为textit任何问题实例提供可认证的全局最优解。这是通过制定和求解问题的稀疏凸平方和SOS松弛来实现的。我们提供了算法和实验的开源实现,展示了我们全局最优方法的优势。 |
| A Strong Baseline for Domain Adaptation and Generalization in Medical Imaging Authors Li Yao, Jordan Prosky, Ben Covington, Kevin Lyman 这项工作为多源多目标域适应和医学成像的推广问题提供了强有力的基线。我们使用十个胸部X射线数据集的多样化集合,凭经验证明了在不同的患者群体上训练医学成像深度学习模型的优势,可以推广到样本范围之外。 |
| Boosting segmentation with weak supervision from image-to-image translation Authors Eugene Vorontsov, Pavlo Molchanov, Wonmin Byeon, Shalini De Mello, Varun Jampani, Ming Yu Liu, Samuel Kadoury, Jan Kautz 在许多情况下,特别是对于医学图像,产生足够大的像素级注释训练样本以训练深度神经网络用于语义图像分割是极其困难的。另一方面,一些关于图像内容的信息通常是已知的。我们利用有关图像是否呈现分割目标的信息,或者是否图像不存在以通过增加可用于模型训练的数据量来提高分割性能的信息。具体地,我们提出了一种半监督框架,其除了在一些示例上的完全监督分割之外,还采用弱标签之间的图像到图像转换,例如,存在与不存在癌症。我们推测这个翻译目标与分割目标很好地对齐,因为两者都需要相同的图像变化解开。在先前的图像到图像转换工作的基础上,我们使用编码器和解码器在两个域之间的任一方向上进行平移,采用选择性地解码域特定变化的策略。对于存在与缺席域,编码器产生对于存在域和存在域唯一的变体。此外,我们成功地重新使用了翻译中用于分割的解码器之一。我们验证了所提出的方法对不同难度的合成任务以及磁共振图像中脑肿瘤分割的实际任务,其中我们显示出比使用自动编码的标准半监督训练的显着改进。 |
| Towards Human Body-Part Learning for Model-Free Gait Recognition Authors Imad Rida 基于步态的生物识别旨在通过他们行走的方式或方式区分人。它代表了距离生物特征,与其他生物特征模式相比具有许多优势。最先进的方法需要个人的有限合作。因此,与其他方式相反,步态是一种非侵入性方法。作为一种行为分析,步态很难规避。此外,可以在没有受试者意识到的情况下执行步态。因此,尝试篡改自己的生物识别签名更加困难。在本文中,我们回顾了步态识别中使用的不同特征和方法。将介绍一种能够学习辨别人体部位以提高识别精度的新方法。将对CASIA步态基准数据库进行广泛的实验,并将结果与现有技术方法进行比较。 |
| A Benchmark for Edge-Preserving Image Smoothing Authors Feida Zhu, Zhetong Liang, Xixi Jia, Lei Zhang, Yizhou Yu 边缘保持图像平滑是许多低级视觉问题的重要步骤。尽管已经提出了许多算法,但是存在阻碍其进一步发展的若干困难。首先,大多数现有算法使用单个参数设置在大范围的图像内容上不能很好地执行。其次,边缘保持图像平滑的性能评估仍然是主观的,并且缺乏广泛接受的数据集来客观地比较不同的算法。为了解决这些问题并进一步推进现有技术,在这项工作中,我们提出了边缘保持图像平滑的基准。该基准测试包括具有groundtruth图像平滑结果的图像数据集以及可以为各种图像内容生成竞争边缘保持平滑结果的基线算法。已建立的数据集包含500个具有多个代表性视觉对象类别的训练和测试图像,而我们基准测试中的基线方法建立在代表性的深度卷积网络架构之上,在此基础上我们设计了非常适合边缘保持图像平滑的新型损失函数。 。经过训练的深度网络比大多数最先进的平滑算法运行得更快,并且在质量和数量上都具有领先的平滑结果。该基准可通过公开访问 |
| A Comparative Study on Hierarchical Navigable Small World Graphs Authors Peng Cheng Lin, Wan Lei Zhao 自两年前发布源代码以来,分层可导航的小世界HNSW图在大规模最近邻搜索任务中越来越受欢迎。这种方法的吸引力在于其优于大多数最近邻搜索方法的性能以及其对各种距离测量的通用性。在本文中,对这种搜索方法进行了几项比较研究。研究了层次结构在HNSW中的作用以及HNSW图本身的作用。我们发现HNSW中的层次结构无法实现比文中所声称的更好的对数复杂度缩放,特别是在高维数据上。此外,我们发现在图形多样化之后,在平面k NN图的支持下,可以实现与HNSW类似的高搜索速度效率。最后,我们指出大多数基于图的搜索方法所面临的困难与维度的诅咒直接相关。与其他基于图表的方法一样,HNSW无法解决这种困难。 |
| Deep Landscape Features for Improving Vector-borne Disease Prediction Authors Nabeel Abdur Rehman, Umar Saif, Rumi Chunara 全球有登革热,黄热病,基孔肯雅热带和寨卡病等蚊子传播疾病的人口正在扩大。传染病模型通常包括温度和降水等环境措施。鉴于高分辨率卫星图像的可用性越来越高,我们在此考虑将卫星图像的景观特征纳入传染病预测模型。为此,我们实施了一个卷积神经网络CNN模型,该模型在Imagenet数据上进行了训练,并在伦敦的卫星数据中标记了景观特征。然后,我们将来自巴基斯坦的卫星图像数据(使用CNN标记)与众所周知的易感传染恢复流行病模型以及2012年巴基斯坦的登革热病例数据相结合。我们研究了每个单独景观特征的预测模型的改进,并评估了使用来自不同地方的图像标签的可行性。我们发现,结合卫星衍生的景观特征可以改善对爆发的预测,这对于主动和战略监视和控制计划非常重要。 |
| D$^2$-City: A Large-Scale Dashcam Video Dataset of Diverse Traffic Scenarios Authors Zhengping Che, Guangyu Li, Tracy Li, Bo Jiang, Xuefeng Shi, Xinsheng Zhang, Ying Lu, Guobin Wu, Yan Liu, Jieping Ye 驾驶数据集加速了智能驾驶和相关计算机视觉技术的发展,而实质和详细的注释作为燃料和动力来提高这些数据集的功效,以改进基于学习的模型。我们提出D 2 City,这是DiDi平台上由车辆收集的大型综合收集的dashcam视频。 D 2 City包含10000多个视频片段,深刻反映了中国现实交通场景的多样性和复杂性。我们还在1000个视频的所有帧中提供边界框和跟踪12类对象的注释,并在关键帧的其余视频上检测注释。与现有数据集相比,D 2 City在不同的天气,道路和交通状况下提供数据,并提供大量精细的检测和跟踪注释。通过为社区带来各种具有挑战性的案例,我们预计D 2 City数据集将推动智能驾驶的感知和相关领域。 |
| Sequential Adaptive Design for Jump Regression Estimation Authors Chiwoo Park, Peihua Qiu 选择统计模型的输入数据或设计点对顺序设计和主动学习非常感兴趣。在本文中,当基础回归函数不连续时,我们提出了一种选择回归模型设计点的新策略。两个主要的激励示例是1个压缩材料成像,目的是加速成像速度,2个设计用于化学相图的回归分析。在这两个示例中,基础回归函数具有不连续性,因此许多现有设计优化方法不能应用于这两个示例,因为它们主要假设连续回归函数。有一些研究用于从噪声观察中估计不连续回归函数,但所有噪声观测通常都是在这些研究中提前提供的。在本文中,我们开发了一种设计策略,用于选择具有不连续性的回归分析的设计点。我们首先回顾与回归分析的设计优化和主动学习相关的现有方法,并讨论它们在处理不连续回归函数时的局限性。然后,我们提出了用于具有不连续性的回归分析的新颖设计策略,首先将呈现具有固定设计的一些统计特性,然后这些特性将用于提出选择回归分析的设计点的新标准。将使用数值示例呈现具有新标准的实验的顺序设计。 |
| Chinese Abs From Machine Translation |
Papers from arxiv.org
更多精彩请移步主页

pic from pixels.com