【今日CV 计算机视觉论文速览 第101期】Wed, 17 Apr 2019
今日CS.CV 计算机视觉论文速览
Wed, 17 Apr 2019
Totally 65 papers
?上期速览✈更多精彩请移步主页

Interesting:
?Pyramid-context ENcoder Network (PEN-Net)基于金字塔编码器的高质量图像修复, 利用Unet结构通过编码图像内容信息并解码,训练了具有高层级语义特征图注意力的编码器,并可将这些注意力转移到低层级特征图上,可以将缺失的部分特征从深层向浅层转移,并在视觉和语义上修复缺失部分。最后通过金字塔损失和对抗损失训练解码器实现快速训练和有效infer。(from 中山大学 微软亚研)

一些结果:
code:https://github.com/researchmm/PEN-Net-for-Inpainting
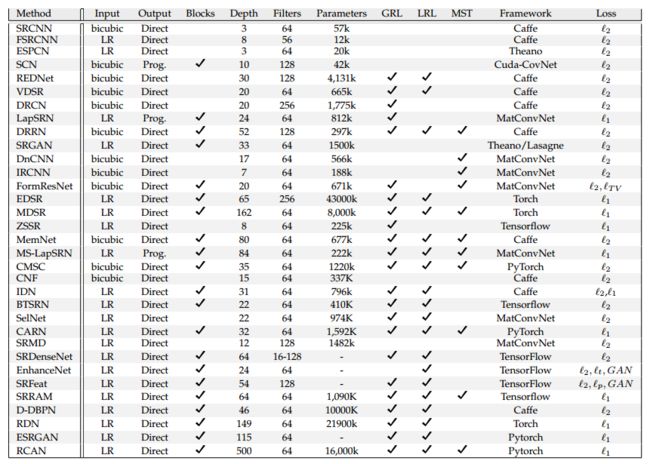
?超分辨综述,基于结构不同来进行算法解构,并基于参数量、算法设置和训练细节、结构创新等来分析了模型的各方面能力。并在6个公开数据集上进行了公开评测。未来可能的研究方向:与先验(场景、传感器、拍摄条件等)结合、目标函数和度量、通用解决方案、非监督、高/任意SR比例,真实/仿真的退化过程。 (from CSIRO, Australia)

各种模型架构:

六个公开数据集:

计算量参数量的影响:

各种属性总结:
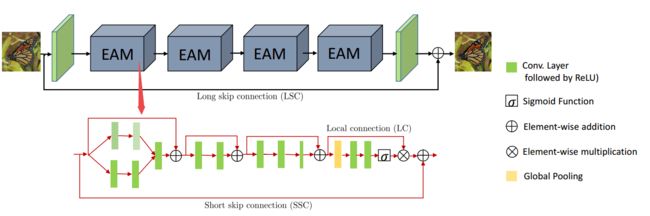
?RIDNet基于特征注意力的真实图像去噪, 深度图像去噪在真实非均匀噪声上表现不佳,需要多级神经网络处理。研究人员利用残差单元促进了低频信息的流动,并应用特征注意力来探索了通道依赖性,实现了单阶段的真实图像去噪模型。(from 澳大利亚国立)


相关方法:NLM [11] and BM3D [16], SADCT [24], SAPCA [18], NLB [34], and INLM [26]
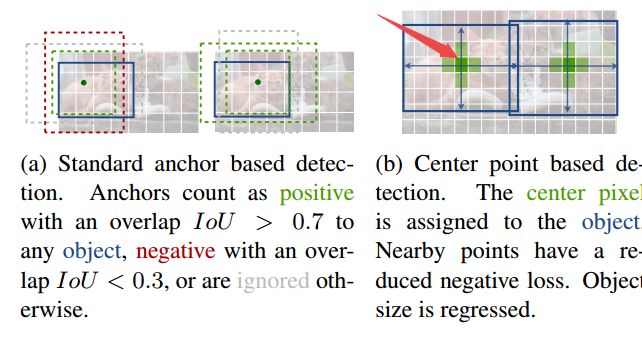
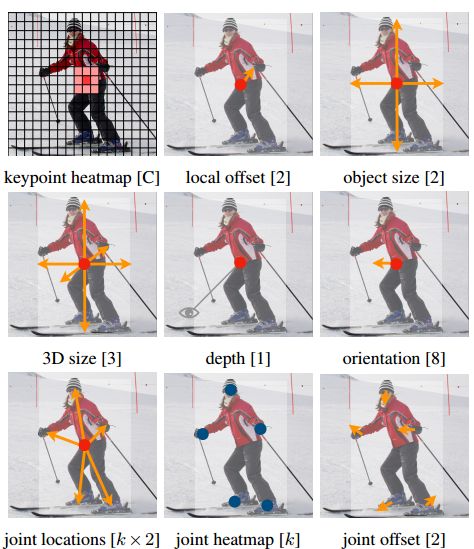
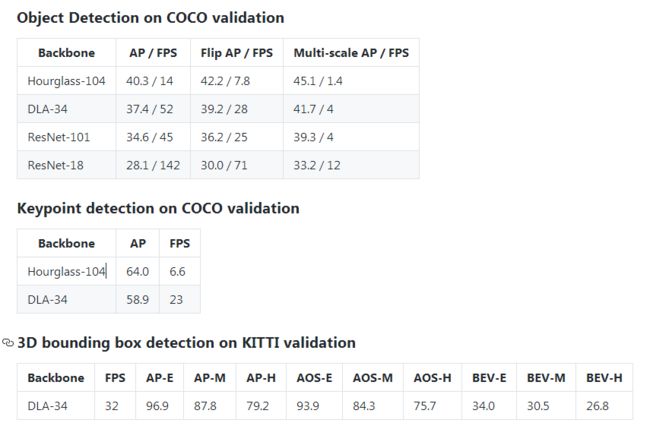
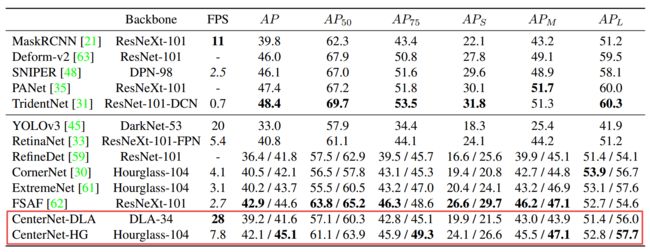
?Objects as Points基于中心点检测的高效CenterNet, 在先前的目标检测工作中模型几乎会遍历每个可能的位置给出边界框并分类,浪费了大量的算力。CenterNet则使用了单个点为物体建模,基于关键点估计来获取中心点,并基于中心点回归出框大小、3D位置和位姿以及方向等属性。研究人员还基于相同的方法估计了3Dbbox和人体位姿。实现了很高的mAP(from 德克萨斯奥斯丁)
基于中心的检测方法和一些结果:

不同检测任务:
速度和表现:
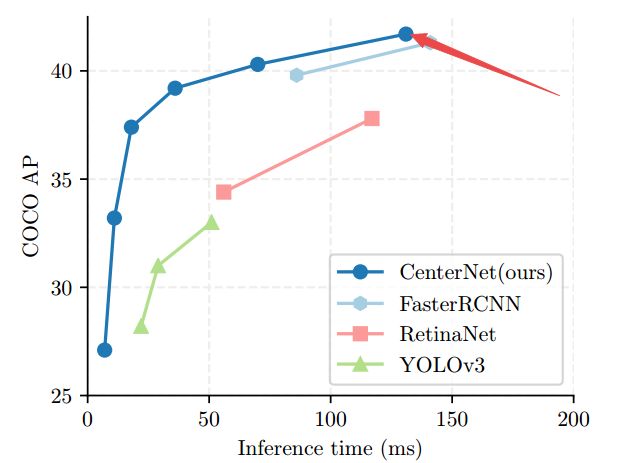
与其他方法比较:
位姿估计和3Dbbox:

code:https://github.com/xingyizhou/CenterNet
?音视频分离,通过从视频中分离相似物体的声音,同时为每一个训练对产生精确的视频级音频,解耦了视频和音频间的关系,并最终实现了视觉引导的音频分离和去噪。(from 德克萨斯奥斯丁)
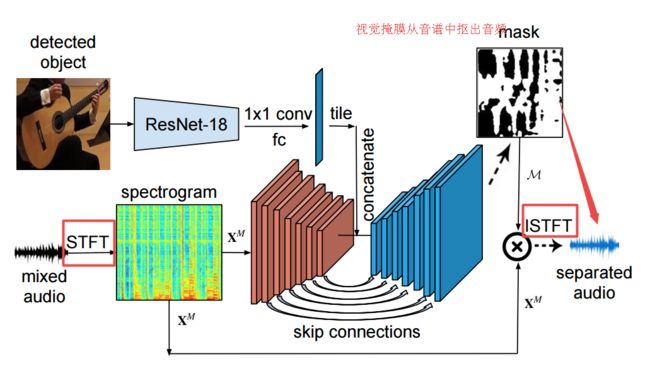
训练过程:

dataset:MUSIC, AudioSet, and AV-Bench datasets
?低功耗视觉综述, Low-Power Image Recognition Challenge (LPIRC) 挑战赛,综述。基于TFlite在移动端实现、coffe2在tx2上实现、线上实现。(from 普渡)
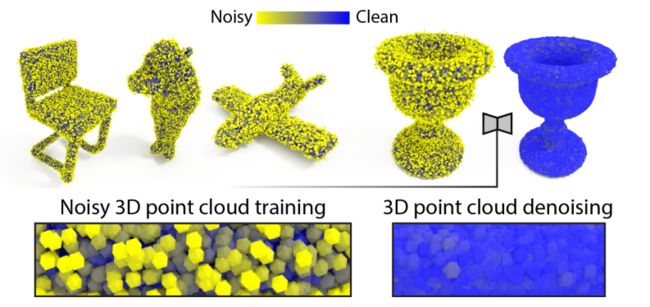
?Total Denoising无监督三维点云去噪, 在流型空间上进行去噪,将不合符随机分布的点云噪声进行整体考虑。(from 德国乌尔姆大学)
点云流型和点云非结构化编解码:

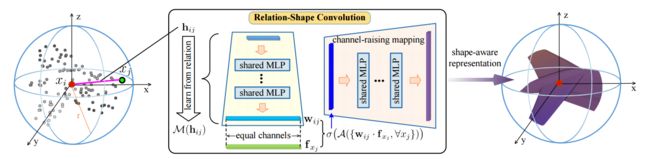
?RS-CNN相关形状CNN用于点云分析, 主要集中于学习点之间的几何拓扑相关性,并基于几何先验学习出高层级的相关性。局部准确的空间布局可以被精确表示。(from 中科院自动化所)
用于分类和分割的不同配置,分割包含了长程链接:

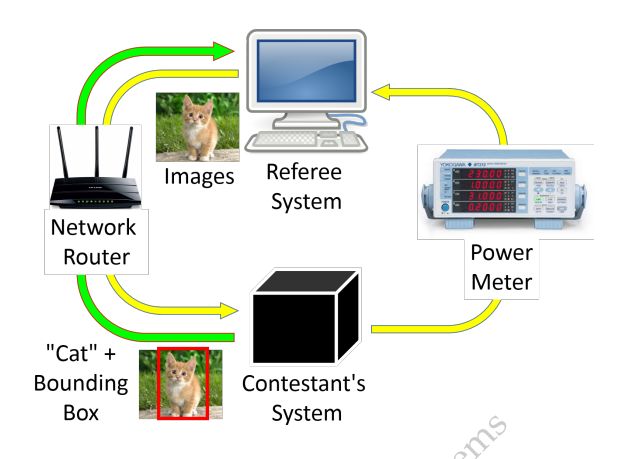
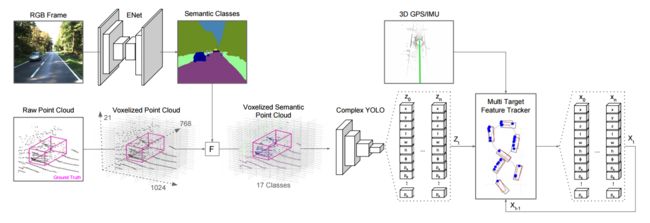
?Complexer-YOLO语义点云实时3D识别追踪, 提出了结合三维检测和语义分割的联合模型,利用语义分割辅助了三维点云检测和追踪。并利用规模化旋转变化SRTs提高了推理速度。(from valeo.com )
架构图和效果图:

?Fashion-AttGAN基于多主体GAN的时尚元素编辑, AttGAN可以用于时尚元素的编辑和生成,通过隐空间编辑可保持其他属性不变的情况下改变服饰的样式,并提出了包含22属性的14221个图像的数据集。(from VIPSHOP US Inc唯品会美国)
重建的一些结果,3-6列改变袖子,后面改变颜色:
code and dataset:https://github.com/ChanningPing/Fashion_Attribute_Editing
?基于贝叶斯的图像先验, 在先前深度图像先验Deep Image prior的基础上研究人员将高斯过程引入了图像修复、重建和去噪的任务中,研究发现深度图像先验在每一层通道趋于无穷时将渐近高斯过程,并能得到对应的高斯核。研究人员在infer过程中引入了贝叶斯方法,通过随机梯度郎之万动力学实现后验推理避免了过早停止,并改善了重建和去噪的结果。(from 麻省大学)
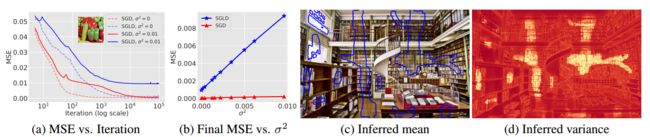
一些实验结果及不确定性图:
project:https://people.cs.umass.edu/~zezhoucheng/gp-dip/
code:https://github.com/ZezhouCheng/GP-DIP
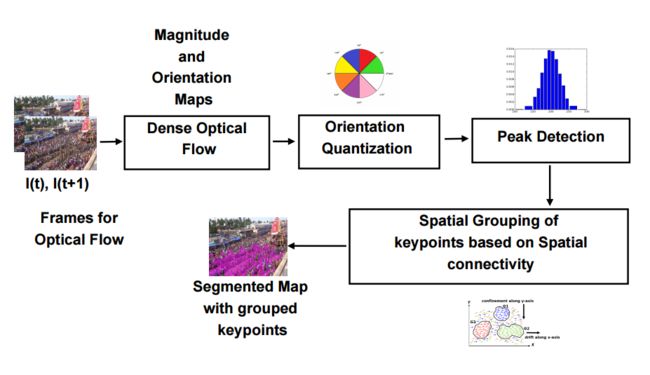
?人群运动估计, 通过监控信息估计人群的流动方向,将有效避免群体拥堵和事故的发生。(from Indian Institute of Technology Bhubaneswar)
人群建模和提出的网络结构:


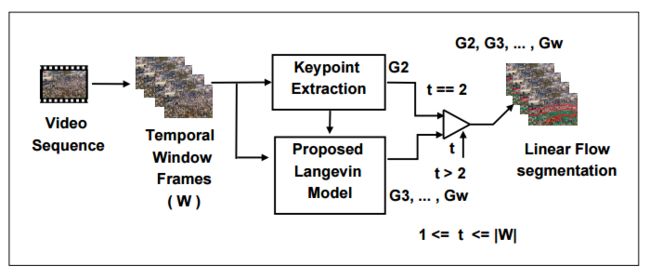
分割与抽取:

?防瞌睡数据集和方法, 用于检测瞌睡早期迹象,给出了数据集和基于层级多尺度长短时神经网络HM-LSTM的方法。 (from 德克萨斯阿灵顿)
数据集/判断指标和提出的HM-LSTM方法:


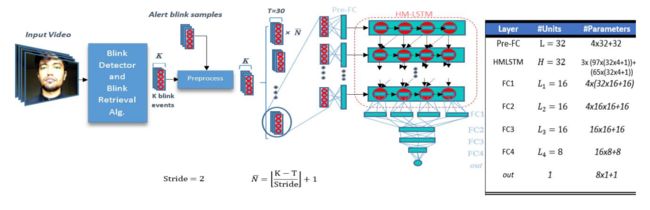
RLDD dataset: sites.google.com/view/utarldd/home
code:https://github.com/rezaghoddoosian
?Focus Is All You Need事件相机的损失函数,用一系列运动补偿函数为事件相机更好的应用。提出了聚焦损失函数用于事件对齐,可用于旋转移动、深度和光流估计。 (from 苏黎世大学)
Daily Computer Vision Papers
| Matrix and tensor decompositions for training binary neural networks Authors Adrian Bulat, Jean Kossaifi, Georgios Tzimiropoulos, Maja Pantic 本文是关于改进二元神经网络的训练,其中激活和权重都是二元的。虽然用于神经网络二值化的现有方法独立地对每个滤波器进行二值化,但是我们建议使用矩阵或张量分解来参数化每个层的权重张量。然后通过量化函数,例如量化函数,使用这种潜在的参数化来执行二值化处理。符号函数应用于重建的权重。我们的方法的一个关键特征是,当重建被二值化时,潜在分解空间中的计算在真实域中完成。这具有若干优点,潜在因子分解在二值化之前强制执行滤波器的耦合,这显着提高了训练模型的准确性。 ii,在训练时,使用实值矩阵或张量分解对每个卷积层的二进制权值进行参数化,在推理期间,我们仅使用重构的二进制权重。因此,我们的方法在模型压缩和加速推理方面不会牺牲二进制网络的任何优势。作为进一步的贡献,不是像在先前的工作中那样分析地计算二元权重缩放因子,而是建议通过反向传播来区别地学习它们。最后,我们表明,当对人体姿态估计的挑战性任务进行测试时,我们的方法明显优于现有方法,超过4项改进,而ImageNet分类最多可达5项性能提升。 |
| Objects as Points Authors Xingyi Zhou, Dequan Wang, Philipp Kr henb hl 检测将对象标识为图像中的轴对齐框。大多数成功的物体探测器列举了潜在物体位置的几乎详尽的列表并对每个物体进行分类。这是浪费,低效,并且需要额外的后期处理。在本文中,我们采取了不同的方法。我们将对象建模为其边界框中心点的单个点。我们的探测器使用关键点估计来查找中心点并回归到所有其他对象属性,例如大小,3D位置,方向甚至姿势。我们的基于中心点的方法CenterNet比相应的基于边界框的检测器端到端可微,更简单,更快速,更准确。 CenterNet实现了MS COCO数据集的最佳速度准确性折衷,其中28.1 AP为142 FPS,37.4 AP为52 FPS,45.1 AP为1.4 FPS多尺度测试。我们使用相同的方法来估计KITTI基准中的3D边界框和COCO关键点数据集上的人体姿势。我们的方法与复杂的多阶段方法竞争性地实时运行。 |
| Active Adversarial Domain Adaptation Authors Jong Chyi Su, Yi Hsuan Tsai, Kihyuk Sohn, Buyu Liu, Subhransu Maji, Manmohan Chandraker 我们提出了一种主动学习方法,用于跨域转移表示。我们的方法,主动对抗域适应AADA,探讨了两个相关问题之间的对偶性,对抗域对齐和重要性抽样,以适应跨域的模型。前者使用域判别模型来对齐域,而后者使用它来权衡样本以考虑分布变化。具体而言,我们的重要性权重促进了分类和多样性与标记示例具有较大不确定性的样本,因此可用作主动学习的样本选择方案。我们表明,当源域有许多标记的示例而目标域没有时,这两个视图可以在一个框架中统一用于域自适应和转移学习。当两个领域密切相关时,AADA对基于微调的方法和其他抽样方法提供了重大改进。在具有挑战性的域适应任务(例如,对象检测)上的结果表明,即使在数百个示例被主动注释之后,也保留了优于基线方法的优点。 |
| Temporal Cycle-Consistency Learning Authors Debidatta Dwibedi, Yusuf Aytar, Jonathan Tompson, Pierre Sermanet, Andrew Zisserman 我们介绍了一种基于视频之间时间对齐任务的自我监督表示学习方法。该方法使用时间周期一致性TCC训练网络,TCC是可区分的周期一致性损失,可用于在多个视频中查找跨时间的对应关系。通过使用学习的嵌入空间中的最近邻居简单地匹配帧,可以使用所得到的每帧嵌入来对齐视频。 |
| Double Transfer Learning for Breast Cancer Histopathologic Image Classification Authors Jonathan de Matos, Alceu de S. Britto Jr., Luiz E. S. Oliveira, Alessandro L. Koerich 这项工作提出了一种乳腺癌组织病理学图像HI的分类方法,该方法使用转移学习从使用ImageNet数据集预训练的Inception v3 CNN提取HI的特征。我们还使用转移学习在组织标记的结肠直肠癌数据集上训练支持向量机SVM分类器,目的是过滤来自乳腺癌HI的斑块并去除不相关的斑块。我们显示在训练第二个SVM分类器之前去除不相关的补丁,提高了对乳腺癌图像上的恶性和良性肿瘤进行分类的准确性。我们能够使用特征提取转移学习提高3.7中的分类准确度,使用不相关的补丁消除提高0.7。所提出的方法在乳腺癌数据集的四个放大因子中的三个中优于现有技术。 |
| Visual Relationship Detection with Language prior and Softmax Authors Jaewon Jung, Jongyoul Park 视觉关系检测是一种中间图像理解任务,它检测两个对象并对解释图像中两个对象之间关系的谓词进行分类。这三个组成部分在语言和视觉上相关,例如磨损与人和衬衫有关,而笔记本电脑与桌子有关,因此,解决方案空间很大,因为它们之间有很多可能的情况。利用语言和视觉模块,提出复杂的空间矢量。这项工作中的模型优于艺术状态,没有昂贵的语言知识从大型文本语料库中升级并构建复杂的损失函数。所有实验仅在视觉关系检测和视觉基因组数据集上进行评估。 |
| AT-GAN: A Generative Attack Model for Adversarial Transferring on Generative Adversarial Nets Authors Xiaosen Wang, Kun He, Chuan Guo, Kilian Q. Weinberger, John E. Hopcroft 最近的研究发现了深度神经网络DNN对于对抗性例子的脆弱性,这些例子对人类来说是不可察觉的,但很容易欺骗DNN。用于制作对抗性示例的现有方法主要基于向原始图像添加小幅度扰动,使得所生成的对抗性示例受到小矩阵范数内的良性示例的约束。在这项工作中,我们提出了一种名为AT GAN的新攻击方法,该方法使用生成对抗网络GAN直接从随机噪声中生成对抗性示例。关键的想法是转移预先训练的GAN以生成要攻击的目标分类器的对抗性示例。一旦模型转移进行攻击,AT GAN可以有效地生成各种对抗性示例,这有助于潜在地加速防御的对抗性训练。我们在MNIST手写数字数据库的典型防御方法下,在半白盒和黑盒设置中评估AT GAN。与现有攻击基线的经验比较表明,AT GAN可以实现更高的攻击成功率。 |
| The ALOS Dataset for Advert Localization in Outdoor Scenes Authors Soumyabrata Dev, Murhaf Hossari, Matthew Nicholson, Killian McCabe, Atul Nautiyal, Clare Conran, Jian Tang, Wei Xu, Fran ois Piti 在线视频数量的快速增长为营销和广告代理商提供了充分的机会来接触他们的观众。最广泛使用的策略之一是产品放置或嵌入式营销,其中新广告无缝地集成到视频中的现有广告中。这样的策略涉及在视频编辑阶段手动地或通过使用机器学习框架准确地在图像帧中定位广告的位置。然而,这些机器学习技术和深度神经网络需要大量的数据用于训练。在本文中,我们提出并发布了第一个在室外场景中捕获的广告牌的大型数据集。我们还在我们提出的数据集上对几种最先进的语义分割算法进行了基准测试。 |
| Weakly Supervised Gaussian Networks for Action Detection Authors Basura Fernando, Cheston Tan Yin Chet, Hakan Bilen 检测视频中人类行为的时间范围是一个具有挑战性的计算机视觉问题,需要详细的手动监督,包括帧级标签。这种昂贵的注释过程限制了在有限数量的类别上部署动作检测器。我们提出了一种新的动作识别方法,称为WSGN,可以学习检测来自弱监督,视频级标签的动作。 WSGN学习利用视频特定和数据集范围的统计数据来预测每个帧与动作类别的相关性。我们表明,本地和全球渠道的结合可以在THUMOS14和Charades两个标准基准测试中取得显着进步。我们的方法在弱监督基线上提高了超过12 mAP,优于其他弱监督的现有技术方法,仅落后于THUMOS14数据集中用于动作检测的现有技术监督方法。类似地,我们的方法仅仅是在挑战Charades数据集进行动作定位的现有技术监督方法背后0.3 mAP。 |
| Cryo-Electron Microscopy Image Analysis Using Multi-Frequency Vector Diffusion Maps Authors Yifeng Fan, Zhizhen Zhao 冷冻电子显微镜EM单粒子重建是用于大分子复合物的3D结构测定的完全通用技术。然而,因为图像是以低电子剂量拍摄的,所以很难以低对比度和高噪声水平观察单个粒子。在本文中,我们提出了一种称为多频率矢量扩散图MFVDM的新方法,以提高低温EM 2D图像分类和去噪的效率和准确性。该框架结合了相似图像之间估计对准的不同不可缩减表示。此外,我们提出了一种图形滤波方案,使用MFVDM矩阵的特征值和特征向量对图像进行去噪。通过模拟和公开可用的实际数据,我们证明了与现有技术的低温EM 2D类平均和图像恢复算法相比,我们提出的方法对噪声有效且鲁棒。 |
| Co-Separating Sounds of Visual Objects Authors Ruohan Gao, Kristen Grauman 了解物体如何从视频中发出声音具有挑战性,因为它们通常在单个音频通道中重叠。目前用于视觉引导音频源分离的方法通过使用人工混合视频剪辑进行训练来回避该问题,但是这对训练数据收集提出了笨拙的限制,甚至可能妨碍学习真正混合声音的属性。我们引入了一种共同分离训练范例,该范例允许从未标记的多源视频中学习对象级声音。我们的新颖训练目标要求深度神经网络为相似的观察对象分离音频,使其始终可识别,同时为每个源训练对再现精确的视频级音频轨道。我们的方法在真实的测试视频中解开声音,即使在训练期间没有单独观察物体的情况下也是如此。我们获得了MUSIC,AudioSet和AV Bench数据集的视觉引导音频源分离和音频去噪的最新结果。我们的视频结果 |
| Low-Power Computer Vision: Status, Challenges, Opportunities Authors Sergei Alyamkin, Matthew Ardi, Alexander C. Berg, Achille Brighton, Bo Chen, Yiran Chen, Hsin Pai Cheng, Zichen Fan, Chen Feng, Bo Fu, Kent Gauen, Abhinav Goel, Alexander Goncharenko, Xuyang Guo, Soonhoi Ha, Andrew Howard, Xiao Hu, Yuanjun Huang, Donghyun Kang, Jaeyoun Kim, Jong Gook Ko, Alexander Kondratyev, Junhyeok Lee, Seungjae Lee, Suwoong Lee, Zichao Li, Zhiyu Liang, Juzheng Liu, Xin Liu, Yang Lu, Yung Hsiang Lu, Deeptanshu Malik, Hong Hanh Nguyen, Eunbyung Park, Denis Repin, Liang Shen, Tao Sheng, Fei Sun, David Svitov, George K. Thiruvathukal, Baiwu Zhang, Jingchi Zhang, Xiaopeng Zhang, Shaojie Zhuo 计算机视觉近年来取得了令人瞩目的进展。同时,手机已成为数百万人的主要计算平台。除了移动电话之外,许多自治系统依赖于可视数据来做出决策,并且这些系统中的一些具有有限的能量,例如也称为无人机和移动机器人的无人驾驶飞行器。这些系统依赖电池和能效是至关重要的。本文有两个主要目的1检查低功率解决方案的最新技术,以检测图像中的对象。自2015年以来,IEEE年度国际低功耗图像识别挑战LPIRC一直致力于识别最节能的计算机视觉解决方案。本文总结了2018年的获奖者解决方案。 2建议研究方向以及低功耗计算机视觉的机会。 |
| Semantically Aligned Bias Reducing Zero Shot Learning Authors Akanksha Paul, Narayanan C. Krishnan, Prateek Munjal 零镜头学习ZSL旨在通过利用已见和未见过的类之间的语义关系来识别看不见的类。 ZSL算法面临的两个主要问题是枢纽问题和对所见类的偏见。现有的ZSL方法仅关注常规和通用ZSL设置中的这些问题之一。在这项工作中,我们提出了一种新颖的方法,即语义对齐偏置减少SABR ZSL,它专注于解决这两个问题。它通过学习潜在空间来克服集线器问题,该潜在空间在编码关于类的区分信息的同时保留标签之间的语义关系。此外,我们还提出了通过归纳设置中的简单交叉验证过程和转换设置中的新的弱传递约束来减少所看到的类的偏差的方法。对三个基准数据集的大量实验表明,在传统的ZSL设置中,所提出的模型明显优于现有技术算法1.59,在广义ZSL中,对于归纳和转换设置,显着优于现有技术。 |
| LBVCNN: Local Binary Volume Convolutional Neural Network for Facial Expression Recognition from Image Sequences Authors Sudhakar Kumawat, Manisha Verma, Shanmuganathan Raman 识别面部表情是计算机视觉中的核心问题之一。时间图像序列具有用于识别表达的有用的时空特征。在本文中,我们提出了一种新的3D卷积神经网络CNN,可以在不使用面部标志的情况下,对时间图像序列上的面部表情识别进行端到端训练。更具体地,提出了一种新的3D卷积层,我们称之为局部二进制卷LBV层。当LBV层与我们新提出的LBVCNN网络一起使用时,与基于CK或OBC CASIA和UNBC McMaster肩部疼痛数据集的图像序列的基于地标的模型相比,获得了可比较的结果。此外,与传统的3D卷积层相比,我们的LBV层将可训练参数的数量减少了很多。事实上,与3x3x3传统3D卷积层相比,LBV层使用的可训练参数少27倍。 |
| SparseMask: Differentiable Connectivity Learning for Dense Image Prediction Authors Huikai Wu, Junge Zhang, Kaiqi Huang 在本文中,我们的目标是自动搜索有效的网络架构进行密集图像预测。特别是,我们遵循编码器解码器风格,专注于自动设计解码器的连接结构。为实现这一目标,我们首先设计一个密集连接的网络,其中包含名为Fully Dense Network的可学习连接,其中包含大量可能的最终连接结构。然后,我们采用梯度下降来搜索密集连接的最佳连接。搜索过程由新的损失函数引导,该函数将每个连接的权重推动为二进制并且连接是稀疏的。发现的连通性在两个分割数据集上实现了竞争结果,与现有技术方法相比,运行速度提高了三倍以上,所需参数不到一半。大量实验表明,所发现的连通性与各种骨干兼容,并且可以很好地推广到其他密集图像预测任务。 |
| Total Denoising: Unsupervised Learning of 3D Point Cloud Cleaning Authors Pedro Hermosilla, Tobias Ritschel, Timo Ropinski 我们表明,3D点云的去噪可以无人监督地学习,直接来自嘈杂的3D点云数据。这是通过将最近的想法从学习无监督图像去噪器扩展到非结构化3D点云来实现的。无监督图像去噪器在假设噪声像素观察是围绕干净像素值的分布的随机实现的假设下操作,这允许对该分布的适当学习最终收敛到正确值。遗憾的是,这种假设对于非结构化点是无效的.3D点云受到总噪声的影响,即。例如,所有坐标的偏差,没有可靠的像素网格。因此,观察可以是实现整个清洁3D点的流形,这使得无监督图像去噪器对3D点云的延伸是不切实际的。克服这个问题,我们引入了一个空间先验项,它将转向收敛到歧管上许多可能模式中唯一最接近的项。我们的结果证明了无监督的去噪性能类似于带有干净数据的监督学习,当给出足够的训练样例时,我们不需要任何一对嘈杂和干净的训练数据。 |
| Relation-Shape Convolutional Neural Network for Point Cloud Analysis Authors Yongcheng Liu, Bin Fan, Shiming Xiang, Chunhong Pan 点云分析非常具有挑战性,因为不规则点中隐含的形状难以捕捉。在本文中,我们提出了RS CNN,即关系形状卷积神经网络,它将规则网格CNN扩展到不规则配置以进行点云分析。 RS CNN的关键是从关系中学习,即点之间的几何拓扑约束。具体地,局部点集的卷积权重被迫从预定义的几何先验中学习来自该点集的采样点与其他点之间的高级关系表达式。通过这种方式,可以获得具有关于点的空间布局的明确推理的归纳局部表示,这导致了很多形状感知和鲁棒性。通过这种卷积作为基本运算符RS CNN,可以开发分层架构以实现用于点云分析的上下文形状感知学习。针对三个任务的挑战性基准测试的广泛实验验证了RS CNN实现了现有技术水平。 |
| Detecting the Unexpected via Image Resynthesis Authors Krzysztof Lis, Krishna Nakka, Mathieu Salzmann, Pascal Fua 经典的语义分割方法,包括最近的深度学习方法,假设在训练期间已经看到在测试时观察到的所有类。在本文中,我们将解决更加真实的场景,即未知类的意外对象可以在测试时出现。该领域的主要趋势是利用预测不确定性的概念来标记低信度区域未知,或者依赖自动编码器并突出显示解码不良的区域。观察到,在这两种情况下,检测到的区域通常不对应于意外的对象,在本文中,我们引入了一种截然不同的策略。它依赖于网络将在描绘意外对象的区域中产生虚假标签的直觉。因此,从得到的语义图重新合成图像将产生相对于输入图像的显着外观差异。换句话说,我们将检测未知类的问题转化为识别不良再合成图像区域的问题。我们表明,它优于不确定性和基于自动编码器的方法。 |
| Patch alignment manifold matting Authors Xuelong Li, Kang Liu, Yongsheng Dong, Dacheng Tao 图像消光通常被建模为从颜色空间到α空间的空间变换。通过估计模型的α因子,可以提取图像的前景。但是,在alpha空间中存在一些尺寸信息冗余。它通常导致前景和背景之间边界附近的一些像素的误判。在本文中,提出了一种称为Patch Alignment Manifold Matting的流形消光框架用于图像消光。特别地,我们首先提出局部图像块中的颜色空间的部分建模。然后,我们使用子空间重建误差执行整个对齐优化以近似α结果。此外,我们利用Nesterov算法来解决优化问题。最后,我们在框架中应用了一些流形学习方法,并获得了几种图像匹配方法,如命名为ISOMAP matting及其派生的Cascade ISOMAP matting。实验结果表明,与几种有代表性的消光方法相比,歧管消光框架及其两个实例是有效的。 |
| Long-Term Video Generation of Multiple FuturesUsing Human Poses Authors Naoya Fushishita, Antonio Tejero de Pablos, Yusuke Mukuta, Tatsuya Harada 从输入视频预测近期是自动驾驶和机器人等应用的有用任务。虽然大多数先前的作品预测单个未来,但可能会出现具有不同行为的多个未来。此外,如果预测的未来太短,则人类或其他系统可能无法完全使用。在本文中,我们提出了一种新的未来视频预测方法,能够产生多个长期期货。这使得预测更适合于实际应用。首先,从输入的人类视频中,我们通过对抗性学习生成未来人体姿势的序列作为其身体关节的图像坐标。我们通过输入潜在代码的生成器组合来反映各种行为以及反映各种轨迹的吸引点来生成多个未来。此外,我们使用基于一维卷积神经网络的新方法生成长期未来人类姿势。最后,我们根据生成的可视化姿势生成输出视频。我们使用三个标准评估生成的未来姿势和视频,即真实性,多样性和准确性,并表明我们提出的方法优于其他最先进的工作。 |
| Complexer-YOLO: Real-Time 3D Object Detection and Tracking on Semantic Point Clouds Authors Martin Simon, Karl Amende, Andrea Kraus, Jens Honer, Timo S mann, Hauke Kaulbersch, Stefan Milz, Horst Michael Gross 准确检测3D物体是计算机视觉中的基本问题,并且对自动驾驶汽车,增强的虚拟现实和机器人技术中的许多应用具有巨大影响。在这项工作中,我们提出了基于神经网络的最先进的3D检测器和自动驾驶环境中的视觉语义分割的新颖融合。此外,我们还引入了比例旋转平移分数SRT,这是一种快速且可高度参数化的评估指标,用于比较对象检测,从而将我们的推理时间加速到20,并将训练时间减半。最重要的是,我们在对象测量上应用最先进的在线多目标特征跟踪,以利用时间信息进一步提高准确性和鲁棒性。我们在KITTI上的实验表明,我们在所有相关类别中获得与现有技术相同的结果,同时保持性能和准确性权衡,并且仍然实时运行。此外,我们的模型是第一个融合视觉语义与3D对象检测的模型。 |
| Disentangling Pose from Appearance in Monochrome Hand Images Authors Yikang Li, Chris Twigg, Yuting Ye, Lingling Tao, Xiaogang Wang 由于光照,外观和背景的变化,来自单眼2D图像的手姿势估计具有挑战性。虽然使用深度神经网络已经取得了一些成功,但它们通常需要收集大量数据集,以充分采样手部图像的所有变化轴。因此,找到手姿势的表示将是有用的,该表姿独立于图像外观,如手纹理,光照,背景,以便我们可以通过混合姿势外观组合来合成看不见的图像。在本文中,我们提出了一种新技术,在2D单色图像中解开姿势表示与互补外观因子。我们使用一个网络监督这个解开过程,该网络学习使用指定的姿势外观特征生成手的图像。与以前的工作不同,我们不需要具有匹配姿势的图像对,我们使用已经可用的姿势注释并引入循环一致性的新颖用途以确保因子之间的正交性。实验结果表明,我们的自解法方案成功地将手部图像分解为姿势及其与使用配对数据的方法相当的质量的互补外观特征。另外,通过重新混合来自不同图像的姿势和外观因素,利用具有看不见的手部外观组合的额外合成图像训练模型可以改善2D姿势估计性能。 |
| A Deep Journey into Super-resolution: A survey Authors Saeed Anwar, Salman Khan, Nick Barnes 基于超分辨率的深度卷积网络是一个快速增长的领域,具有许多实际应用。在本次博览会上,我们广泛地比较了30个最先进的超分辨率卷积神经网络CNN,超过三个经典和三个最近引入的挑战性数据集,以基准单图像超分辨率。我们引入了基于深度学习的超分辨率网络的分类法,将现有方法分为九类,包括线性,残差,多分支,递归,渐进,基于注意力和对抗性设计。我们还在网络复杂性,内存占用,模型输入和输出,学习细节,网络损耗类型和重要架构差异(例如深度,跳过连接,过滤器)方面提供模型之间的比较。进行了广泛的评估,显示了过去几年中准确性的一致和快速增长,以及模型复杂性和大规模数据集的可用性的相应提升。还观察到,被确定为基准的开创性方法已经明显优于当前的竞争者。尽管近年来取得了进展,但我们发现了现有技术的一些缺点,并为解决这些开放性问题提供了未来的研究方向。 |
| A Deep Optimization Approach for Image Deconvolution Authors Zhijian Luo, Siyu Chen, Yuntao Qian 在盲图像去卷积中,通常利用先验来约束解空间,从而减轻不确定性。与解卷积任务分开训练的引物往往不稳定或无效。我们提出了高尔夫优化器,这是一种新颖但简单的网络形式,可以从具有更好传播行为的数据中学习深层原理。就像打高尔夫球一样,我们的方法首先使用一个网络估计积极的传播朝向最优,并且反复应用残余CNN来学习先前的梯度,以便在恢复时进行精细校正。实验表明,我们的网络在GoPro数据集上实现了竞争性能,与现有技术相比,我们的模型非常轻巧。 |
| Shared Predictive Cross-Modal Deep Quantization Authors Erkun Yang, Cheng Deng, Chao Li, Wei Liu, Jie Li, Dacheng Tao 随着数据量的爆炸性增长和数据模态的不断增加的多样性,跨模态相似性搜索(其在不同模态中进行最近邻搜索)已经引起越来越多的关注。本文提出了一种深度紧凑的代码学习解决方案,用于高效的跨模态相似性搜索最近的许多研究已经证明,基于量化的方法通常比基于哈希的方法在单模态相似性搜索上表现更好。在本文中,我们提出了一种深度量化方法,这是利用深度神经网络进行基于量化的交叉模态相似性搜索的早期尝试之一。我们的方法,称为共享预测深度量化SPDQ,明确地为不同的模态和两个私有子空间制定共享子空间用于单个模态,并且通过将它们嵌入到再生核Hilbert空间中来同时学习共享子空间和私有子空间中的表示。可以明确地比较不同模态分布的平均嵌入。另外,在共享子空间中,学习量化器以借助于标签对齐产生保留紧凑代码的语义。由于这种新颖的网络架构与监督量化训练相结合,SPDQ可以尽可能地保持模内和模间的相似性,并大大减少量化误差。两个流行基准测试的实验证实,我们的方法优于最先进的方法。 |
| End-to-End Denoising of Dark Burst Images Using Recurrent Fully Convolutional Networks Authors Di Zhao, Lan Ma, Songnan Li, Dahai Yu 在昏暗的光线环境下拍摄照片时,由于光线进入量很小,拍摄的图像通常非常暗,噪点很大,而且颜色无法反映真实世界的颜色。在这种情况下,用于单图像去噪的传统方法总是不能有效。一个常见的想法是采用相同场景的多个帧来增强信噪比。本文提出了一种经常性的完全卷积网络RFCN,用于处理在极低光照条件下拍摄的突发照片,并获得具有改善亮度的去噪图像。我们的模型将原始突发图像直接映射到sRGB输出,以产生最佳图像或生成多帧去噪图像序列。事实证明,这个过程能够完成低级别的去噪任务,以及色彩校正和增强的高级任务,所有这些都是通过我们的网络进行端到端处理。我们的方法取得了比现有技术方法更好的结果。此外,我们已经应用了由一种类型的相机训练的模型,而不对由不同相机捕获的照片进行微调,并且已经获得了类似的端到端增强。 |
| GradMask: Reduce Overfitting by Regularizing Saliency Authors Becks Simpson, Francis Dutil, Yoshua Bengio, Joseph Paul Cohen 由于样本太少或模型参数太多,过度拟合会抑制将预测推广到新数据的能力。在医学成像中,当特征被错误地指定为重要性(例如,不同的医院特定工件)时,这可能发生,导致来自不具有这些特征的不同机构的新数据集的不良性能,这是不期望的。大多数正则化方法没有明确地惩罚这些特征与目标类的错误关联,因此无法解决此问题。我们提出了一种正则化方法GradMask,当它们与病变分割不一致时,它惩罚从分类器梯度推断的显着性图。这可以防止非肿瘤相关特征有助于不健康样本的分类。我们证明,与没有GradMask的基线相比,这种方法可以将测试精度提高到1 3之间,表明它对减少过度拟合有影响。 |
| Learning Pyramid-Context Encoder Network for High-Quality Image Inpainting Authors Yanhong Zeng, Jianlong Fu, Hongyang Chao, Baining Guo 高质量的图像修复需要填充具有合理内容的损坏图像中的缺失区域。现有作品要么通过复制图像块来填充区域,要么从区域上下文生成语义连贯的块,而忽略了视觉和语义合理性都是高度需求的事实。在本文中,我们提出了一个金字塔上下文编码器网络PEN网络,用于深度生成模型的图像修复。 PEN Net建立在U Net结构之上,它可以通过从全分辨率输入编码上下文语义来恢复图像,并将学习的语义特征解码回图像。具体地,我们提出了金字塔上下文编码器,其通过关注从高级语义特征映射逐步学习区域亲和性,并将学习的注意力转移到先前的低级特征映射。由于缺失的内容可以通过金字塔方式从深度到浅度的注意力转移来填充,因此可以确保用于图像修复的视觉和语义一致性。我们进一步提出了一种多尺度解码器,其具有深度监督的金字塔损失和对抗性损失。这样的设计不仅导致训练中的快速收敛,而且在测试中产生更真实的结果。对各种数据集的广泛实验表明,所提出的网络具有优越的性能 |
| Super Resolution Convolutional Neural Network Models for Enhancing Resolution of Rock Micro-CT Images Authors Ying Da Wang, Ryan Armstrong, Peyman Mostaghimi 基于超分辨率卷积神经网络的单图像超分辨率SISR技术SRCNN应用于砂岩和碳酸盐岩的微观计算机断层扫描μCT图像。数字岩石成像受到扫描装置的能力的限制,导致分辨率和视野之间的折衷,并且在该研究中测试的超分辨率方法旨在补偿这些限制。 SRCNN型号SR Resnet,增强型深度SR EDSR和宽激活深度SR WDSR用于4x下采样图像的数字岩石超分辨率1 DRSRD1数据集,包括2000个高分辨率800x800 Bentheimer砂岩和Estaillades碳酸盐的原始微CT图像。经过训练的模型应用于数据集内的验证和测试数据,与双三次插值相比,图像质量提高了3.5 dB,所有测试模型的性能均在0.1 dB范围内。差异图表示在训练模型范围内的图像中完全恢复边缘清晰度,仅有高频噪声相关的细节损失。我们发现除了生成高分辨率图像之外,应用于合成降级图像的超分辨率方法的有益副作用是去除图像噪声,同时恢复有利于分割过程的边缘锐度。该模型还针对Bentheimer岩石的真实低分辨率图像进行了测试,并通过图像增强来解释自然噪声和模糊。 SRCNN方法被证明在这些情况下充当图像分割的预处理器,这自然导致将来进一步开发和训练直接分割图像的模型。 SRCNN在岩石图像上的图像恢复具有比传统方法更高的质量,并且表明SRCNN方法是数字岩石工作流程中可行的处理步骤。 |
| Deep Neural Network Based Hyperspectral Pixel Classification With Factorized Spectral-Spatial Feature Representation Authors Jingzhou Chen, Siyu Chen, Peilin Zhou, Yuntao Qian 深度学习由于其产生深度特征表示的能力而被广泛用于高光谱像素分类。然而,如何构建适用于高光谱数据的高效强大的网络仍在探索中。本文设计了一种新的神经网络模型,充分利用高光谱数据的光谱空间结构。首先,我们通过具有监督预训练方案的子网从丰富但冗余的光谱带中提取基于像素的固有特征。其次,为了利用像素之间的局部空间相关性,我们将先前的子网共享为图像块中每个像素的光谱特征提取器,之后将片中所有像素的光谱特征组合并馈入随后的分类子网。最后,整个网络进一步微调,以提高其分类性能。特别地,谱空间分解方案应用于我们的模型架构中,使得网络大小和参数的数量远小于用于高光谱图像分类的现有光谱空间深度网络。对高光谱数据集的实验表明,与一些现有的深度学习方法相比,我们的方法在网络尺寸更小,参数更少的情况下实现了更好的分类结果。 |
| Fashion-AttGAN: Attribute-Aware Fashion Editing with Multi-Objective GAN Authors Qing Ping, Jiangbo Yuan, Bing Wu, Wanying Ding 在本文中,我们将属性感知时尚编辑(一种新颖的任务)引入时尚领域。我们重新定义了AttGAN的总体目标,并为这项新任务提出了Fashion AttGAN模型。为此任务构建了一个数据集,其中包含14,221和22个属性,这些属性已公开可用。实验结果表明我们的Fashion AttGAN对原始AttGAN的时尚编辑有效。 |
| A Bayesian Perspective on the Deep Image Prior Authors Zezhou Cheng, Matheus Gadelha, Subhransu Maji, Daniel Sheldon 最近将深度图像先验作为自然图像的先验介绍。它将图像表示为具有随机输入的卷积网络的输出。对于推理,执行梯度下降以调整网络参数以使输出匹配观察。该方法在一系列图像重建任务中产生良好性能。我们证明了深度图像先验渐近地等于先前的静态高斯过程,因为网络的每一层中的信道数量变为无穷大,并导出相应的内核。这通知贝叶斯方法进行推理。我们表明,通过使用随机梯度Langevin进行后验推断,我们避免了早期停止的需要,这是当前方法的缺点,并且改善了去噪和重绘任务的结果。我们在许多一维和二维信号重建任务中说明了这些直觉。 |
| Point cloud registration: matching a maximal common subset on pointclouds with noise (with 2D implementation) Authors Jorge Arce Garro, David Jim nez L pez 我们分析了确定2D中的2个给定点云(具有任何不同的基数和任意数量的异常值)是否具有可通过刚性运动匹配的相同大小的子集的问题。这个问题很重要,例如,在使用不完整数据的指纹匹配时。我们提出了一种算法,在对噪声容限的假设下,允许找到最大可能大小的相应子云。我们的程序优化了这样做的潜在能量函数,这首先受到静电中点电荷之间发生的潜在能量相互作用的启发。 |
| Decoupling Localization and Classification in Single Shot Temporal Action Detection Authors Yupan Huang, Qi Dai, Yutong Lu 视频时间动作检测旨在临时定位和识别未修剪视频中的动作。现有的一阶段方法主要集中于统一两个子任务,即行动建议的本地化和通过完全共享的主干对每个提议的分类。然而,在一个网络中封装两个子任务的所有组件的这种设计可能通过忽略每个子任务的专用特性来限制训练。在本文中,我们提出了一种新的解耦单次射击时间动作检测解耦SSAD方法,通过在一级方案中解耦定位和分类来缓解这种问题。特别地,两个单独的分支被并行设计以使每个组件能够私下拥有表示以进行精确定位或分类。每个分支通过将解卷积应用于主流的特征映射来生成一组动作锚点层。每个分支通过将解卷积应用于主流的特征映射来生成一组特征映射。因此,结合来自较深层的高级语义信息以增强特征表示。我们对THUMOS14数据集进行了大量实验,并展示了优于现有技术方法的卓越性能。我们的代码可在线获取。 |
| Photofeeler-D3: A Neural Network with Voter Modeling for Dating Photo Rating Authors Agastya Kalra, Ben Peterson 在过去的二十年中,在线约会已经获得了极大的欢迎,因此选择最好的约会档案照片比以往任何时候都更加重要。为此,我们建议Photofeeler D3成为第一个卷积神经网络,对照片的评分进行评分,以确定该主题的智能性,可信度和吸引力。我们将此任务命名为约会照片评级DPR。 Photofeeler D3利用Photofeeler的约会数据集PDD拥有超过100万张图像和数千万张选票,与现有的DPR在线AI平台相比,人工投票的相关性高出28倍。我们介绍了选民建模的新概念,并用它来实现这个基准。我们模型的吸引力输出也可用于面部美容预测FBP并实现最先进的结果。如果不对HotOrNot数据集中的单个图像进行训练,我们可以获得比文献中任何模型高10的相关性。最后,我们证明了Photofeeler D3与10个非标准化和未加权的人类投票达到了大致相同的相关性,使其成为DPR和FBP这两项任务的最新技术。 |
| Shortest Paths in HSI Space for Color Texture Classification Authors Mingxin Jin, Yongsheng Dong, Lintao Zheng, Lingfei Liang, Tianyu Wang, Hongyan zhang 颜色纹理表示是纹理分类任务中的重要步骤。最短路径用于从RGB和HSV颜色空间中提取颜色纹理特征。在本文中,我们建议在HSI空间中使用最短路径来构建用于分类的纹理表示。特别地,两个无向图分别用于模拟H通道和S和I通道,以便表示颜色纹理图像。此外,根据纹理图像的不同比例和方向,通过使用四对像素来构造最短路径。彩色Brodatz和USPTex数据库的实验结果表明,我们提出的方法是有效的,Brodatz数据库中的最高分类准确率为96.93。 |
| Single Pixel Reconstruction for One-stage Instance Segmentation Authors Jinghan Yao, Zhou Yu, Jun Yu, Dacheng Tao 对象实例分割是计算机视觉中最基本但具有挑战性的任务之一,它需要像素级图像理解。大多数现有方法通过将掩模预测分支添加到具有区域提议网络RPN的两级对象检测器来解决该问题。虽然产生了良好的分割结果,但这两种方法的效率远远不能令人满意,限制了它们在实践中的适用性。在本文中,我们提出了一个单阶段框架SPRNet,它通过将单个像素重建SPR分支引入现成的一级检测器来执行有效的实例分割。添加的SPR分支直接从卷积特征图中的每个单个像素重建像素级掩模。使用相同的ResNet 50骨干网,SPRNet以更高的推理速度实现了与掩模R CNN相当的掩模AP,并且与RetinaNet相比,在每个尺度上都获得了盒AP的全面改进。 |
| What I See Is What You See: Joint Attention Learning for First and Third Person Video Co-analysis Authors Huangyue Yu, Minjie Cai, Yunfei Liu, Feng Lu 近年来,通过可穿戴式相机从第一人称视角捕获越来越多的视频。除了传统的第三人称视频之外,这种第一人称视频提供了附加信息,因此具有广泛的应用。然而,用于分析第一人称视频的技术可以与第三人视频的技术根本不同,并且从两个视点探索共享信息甚至更加困难。在本文中,我们提出了一种新的第一和第三人称视频合作分析方法。我们方法的核心是联合关注的概念,指示在不同视点中对应于共享关注区域的可学习表示,从而链接两个视点。为此,我们开发了一个具有三重损失的多分支深度网络,通过自我监督学习从第一和第三人视频中提取共同关注。我们使用交叉视点视频匹配任务评估公共数据集上的方法。我们的方法在质量和数量上都优于现有技术。我们还通过一系列额外的实验证明了学习的联合注意力如何使各种应用受益。 |
| Adaptive Wing Loss for Robust Face Alignment via Heatmap Regression Authors Xinyao Wang, Liefeng Bo, Li Fuxin 热图回归已成为局部化面部标志的主流方法之一。随着卷积神经网络CNN和递归神经网络RNN在解决计算机视觉任务中变得越来越流行,已经对这些架构进行了广泛的研究。然而,很少研究热图回归的损失函数。在本文中,我们分析了面部对齐问题中热图回归的理想损失函数属性。然后我们提出一种新的损失函数,称为自适应翼损失,它能够使其形状适应不同类型的地面真实热图像素。这种适应性将前景像素上的损失减少到零,同时在背景像素上留下一些损失。为了解决前景像素和背景像素之间的不平衡问题,我们还提出了加权损失图,它在前景和难以处理的背景像素上分配高权重,以帮助训练过程更多地关注对地标定位至关重要的像素。为了进一步提高面部对准精度,我们引入边界预测和CoordConv与边界坐标。包括COFW,300W和WFLW在内的不同基准测试的广泛实验表明,我们的方法在各种评估指标上的表现优于现有技术水平。此外,自适应翼损也有助于其他热图回归任务。代码将公开发布。 |
| Real Image Denoising with Feature Attention Authors Saeed Anwar, Nick Barnes 深度卷积神经网络在包含空间不变噪声合成噪声的图像上表现更好,但是它们的性能受限于真实的噪声照片并且需要多级网络建模。为了提高去噪算法的实用性,本文提出了一种采用模块化结构的新型单级盲实时图像去噪网络RIDNet。我们在残差结构上使用残差来减轻低频信息的流动,并应用特征注意来利用信道依赖性。此外,针对19个最先进算法的三个合成和四个真实噪声数据集的定量度量和视觉质量方面的评估证明了我们的RIDNet的优越性。 |
| NAS-FPN: Learning Scalable Feature Pyramid Architecture for Object Detection Authors Golnaz Ghiasi, Tsung Yi Lin, Ruoming Pang, Quoc V. Le 用于物体检测的现有技术卷积架构是手动设计的。在这里,我们的目标是为对象检测学习更好的特征金字塔网络架构。我们采用神经架构搜索,在一个涵盖所有跨尺度连接的新型可扩展搜索空间中发现新的特征金字塔架构。这个被发现的架构名为NAS FPN,由自上而下和自下而上连接组合而成,可以跨越秤进行融合。与现有技术的对象检测模型相比,NAS FPN与RetinaNet框架中的各种骨干模型相结合,实现了更好的准确性和延迟权衡。与具有32的MobileNetV2模型的最先进的SSDLite相比,NAS FPN将移动检测精度提高了2 AP,并且实现了48.3 AP,其超过了掩模R CNN 10检测精度,并且计算时间更短。 |
| Custom Video-Oculography Device and Its Application to Fourth Purkinje Image Detection during Saccades Authors Evgeniy Abdulin, Lee Friedman, Oleg Komogortsev 我们构建了一个基于自定义视频的眼动仪,将每个视频帧保存为全分辨率图像MJPEG。可以离线处理图像以检测眼部特征,包括瞳孔和角膜反射第一浦肯野图像,P1位置。可以进行用于检测瞳孔和角膜反射的多种算法的比较。该系统提供高度灵活的刺激创建,混合图形,图像和视频刺激。我们可以根据所需的图像质量和帧速率更换相机和红外照明器。使用该系统,我们检测到第四浦肯野图像P4在帧中的位置。我们表明,当我们通过计算P1 P4来估计凝视时,信号与用DPI眼动仪估计的凝视很好地比较,DPI眼动仪本地检测并跟踪P1和P4。 |
| Polarimetric Thermal to Visible Face Verification via Self-Attention Guided Synthesis Authors Xing Di, Benjamin S. Riggan, Shuowen Hu, Nathaniel J. Short, Vishal M. Patel 极化热到可见面验证需要匹配包含显着域差异的两个图像。最近的几种方法试图从热图像合成可见面以进行交叉模态匹配。在本文中,我们采用不同的方法,而不是只关注从热面合成可见面,我们还建议从可见面合成热面。我们的直觉是基于这样一个事实,即热图像还包含一些关于验证人的判别信息。来自预训练的卷积神经网络CNN的深度特征从原始图像和合成图像中提取。然后融合这些特征以生成模板,然后将其用于验证。所提出的合成网络基于自我关注生成对抗网络SAGAN,其基本上允许有效的注意力引导图像合成。对ARL极化热面数据集的大量实验表明,所提出的方法实现了最先进的性能。 |
| Characterizing the Variability in Face Recognition Accuracy Relative to Race Authors Krishnapriya K. S, Kushal Vangara, Michael C. King, Vitor Albiero, Kevin Bowyer 最近的许多新闻标题都将人脸识别技术称为偏见或种族主义。我们报告了对MORPH数据集的非洲裔美国人和高加索人图像群组之间人脸识别准确度差异的系统调查。我们发现,对于所考虑的所有四个匹配者,冒名顶替者和真实分布在群组之间在统计上显着不同。对于固定的决策阈值,非裔美国人图像群组具有较高的错误匹配率和较低的错误非匹配率。 ROC曲线以相同的错误匹配率比较验证速率,但不同的群组在不同的阈值处实现相同的错误匹配率。这意味着ROC比较与使用固定决策阈值的操作方案无关。我们证明,对于ResNet匹配器,这两个队列的冒充者和真实分布大致相等。使用ICAO合规性作为图像质量的标准,我们发现初始图像群组具有不等的高质量图像率。符合ICAO标准的原始图像群组子集显示出改进的准确性,主要效果是降低真实分布的低相似性尾部。 |
| A Realistic Dataset and Baseline Temporal Model for Early Drowsiness Detection Authors Reza Ghoddoosian, Marnim Galib, Vassilis Athitsos 嗜睡会使许多司机和工人的生命处于危险之中。设计实用且易于部署的真实世界系统以检测困倦的发生是非常重要的。在本文中,我们解决了早期困倦检测,它可以提供早期警报并为受试者提供充足的反应时间。我们提供了一个包含60个主题的大型公共真实数据集,其视频片段标记为警报,低警惕或昏昏欲睡。该数据集包含大约30小时的视频,内容范围从嗜睡的微妙迹象到更明显的。我们还对数据集的时间模型进行基准测试,该模型具有较低的计算和存储需求。我们提出的方法的核心是分层多尺度长短期记忆HM LSTM网络,其由依次检测到的闪烁特征馈送。我们的实验证明了连续眨眼特征和困倦之间的关系。在实验结果中,我们的基线方法比人类判断产生更高的准确性。 |
| Automatic adaptation of object detectors to new domains using self-training Authors Aruni RoyChowdhury, Prithvijit Chakrabarty, Ashish Singh, SouYoung Jin, Huaizu Jiang, Liangliang Cao, Erik Learned Miller 该工作解决了现有对象检测器对新目标域的无监督调整问题。我们假设此域中的大量未标记视频随时可用。我们通过使用来自现有检测器的高置信度检测自动获得目标数据上的标签,并通过使用跟踪器利用时间线索获得的硬错误分类示例进行扩充。然后,这些自动获得的标签用于重新训练原始模型。提出了修改后的知识蒸馏损失,并且我们研究了从目标域向训练样本分配软标签的几种方法。我们的方法是根据挑战性的面部和行人检测任务进行经验评估,面部检测器在WIDER Face上进行训练,该面部检测器由从网络爬行的高质量图像组成,适用于大型监视数据集,行人检测器使用清晰的白天图像进行训练。 BDD 100K驾驶数据集适用于所有其他场景,如下雨,有雾,夜间。我们的结果证明了结合从跟踪获得的硬实例,通过蒸馏损失与硬标签使用软标签的优点的有用性,并且显示出有希望的性能作为对象检测器的无监督域自适应的简单方法,对超参数的依赖性最小。 |
| Fast Inference in Capsule Networks Using Accumulated Routing Coefficients Authors Zhen Zhao, Ashley Kleinhans, Gursharan Sandhu, Ishan Patel, K. P. Unnikrishnan 我们通过利用关于链接相邻网络层之间的胶囊的路由系数的关键洞察,提出了一种用于胶囊网络封装网络中的快速推理的方法。由于路由系数负责将对象部分分配给整体,并且整个对象通常包含类似的类内和不同的类间部分,因此路由系数倾向于为每个对象类形成唯一的签名。为了快速推理,首先使用来自训练数据集的示例以通常的方式训练网络。之后,与训练样本相关联的路由系数被离线累积并用于创建一组主路由系数。在推理期间,使用这些主路由系数代替动态计算的路由系数。我们的方法通过单个矩阵乘法运算有效地替换了动态路由过程中的for循环迭代,从而显着提高了推理速度。与动态路由过程相比,快速推理降低了MNIST,背景MNIST,时尚MNIST和旋转MNIST数据集的测试精度,小于0.5,CIFAR10大约为5。 |
| Automatic alignment of surgical videos using kinematic data Authors H. Ismail Fawaz, G. Forestier, J. Weber, F. Petitjean, L. Idoumghar, P. Muller 在过去的一百年中,经典的教学方法是看一个,做一个,教一个已经统治了全世界的外科教育系统。随着手术室2.0的出现,在手术期间记录视频,运动学和许多其他类型的数据变得容易,因此允许人工智能系统被部署并用于外科和医疗实践。最近,外科视频已被证明可提供同伴辅导的结构,使新手学员能够通过重播这些视频向有经验的外科医生学习。然而,外科手术持续时间和执行中的高操作员间可变性使得从比较新手到专家外科手术视频的学习成为非常困难的任务。在本文中,我们提出了一种新技术,可以根据相应的运动多变量时间序列数据的对齐来对齐多个视频。通过利用动态时间扭曲测量,我们的算法同步一组视频,以显示以不同速度执行的相同手势。我们相信所提议的方法是对现有的手术学习工具的有价值的补充。 |
| Brain Tumor Segmentation on MRI with Missing Modalities Authors Yan Shen, Mingchen Gao 来自磁共振成像的脑肿瘤分割MRI是早期诊断的关键技术。然而,不像BraTS数据集中那样具有完整的四种模态,在临床情景中通常缺少模态。我们设计了一种脑肿瘤分割算法,该算法对于没有任何形态是稳健的。我们的网络包括信道独立编码路径和特征融合解码路径。我们通过信道丢失使用自我监督训练,并在特征地图上提出一种新的域自适应方法,以从丢失的信道中恢复信息。我们的结果表明,分割的质量取决于缺少哪种形态。此外,我们还讨论并可视化每种模态对分割结果的贡献。他们的贡献与专家筛选程序一致。 |
| A deep learning model for early prediction of Alzheimer's disease dementia based on hippocampal MRI Authors Hongming Li, Mohamad Habes, David A. Wolk, Yong Fan 引言在基线时,预测何时以及符合轻度认知障碍MCI标准的个体将最终发展为阿尔茨海默病AD痴呆症具有挑战性。方法基于2146名受试者的MRI扫描开发和验证深度学习方法803用于训练,1343用于验证以预测MCI受试者在事件分析设置中进展为AD痴呆。结果深度学习时间事件模型预测个体受试者进展为AD痴呆,其中一致性指数C指数为0.762,对439例ADNI测试MCI受试者,随访时间为6至78个月四分位数24,42,54,C指数为0.781在40名AIBL测试MCI受试者,随访时间从18 54个月四分之一18,36,54。预测的进展风险还将个体受试者聚集成亚组,其与AD痴呆的进展时间显着不同p 0.0002。当基于深度学习的进展风险与基线临床测量相结合时,获得了用于预测AD痴呆进展C指数0.864的改进性能。结论我们的方法提供了一种具有成本效益和准确的预后手段,并可能促进临床试验中与可能在特定时间段内进展的个体的登记。 |
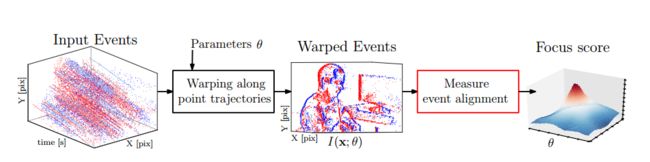
| Focus Is All You Need: Loss Functions For Event-based Vision Authors Guillermo Gallego, Mathias Gehrig, Davide Scaramuzza 事件相机是新颖的视觉传感器,输出像素级亮度变化事件而不是传统视频帧。这些异步传感器提供了优于传统相机的若干优点,例如高时间分辨率,非常高的动态范围和无运动模糊。为了解锁这种传感器的潜力,最近提出了运动补偿方法。我们提出了二十二个目标函数的集合和分类,以分析运动补偿方法中的事件对齐图1。我们将它们称为焦点丢失功能,因为它们与焦点应用中传统形状中使用的功能有很强的联系。建议的损失功能允许将成熟的计算机视觉工具带到事件相机领域。我们比较了公开数据集上所有损失函数的准确性和运行时性能,并得出结论:方差,梯度和拉普拉斯量值是最佳损失函数之一。损失函数的适用性显示在多个任务旋转运动,深度和光流估计上。建议的焦点丢失功能可以解锁事件相机的突出特性。 |
| Estimation of Linear Motion in Dense Crowd Videos using Langevin Model Authors Shreetam Behera, Debi Prosad Dogra, Malay Kumar Bandyopadhyay, Partha Pratim Roy 社会和文化活动中的人群聚会随着人口的增加而突飞猛进。通过计算机视觉和专家决策系统进行监控有助于了解大型聚会中的人群现象。了解人群现象有助于及早识别不需要的事件及其预防。运动流是重要的人群现象之一,可以有助于描述人群行为。流可以用于理解人群中的不稳定性。然而,由于人群移动中的随机性和传感设备的限制,提取运动流是一项具有挑战性的任务。此外,如果随机性很高,诸如光流的低级特征可能会产生误导。在本文中,我们提出了一个基于Langevin方程的新模型来分析密集拥挤场景的视频中的线性主导流。我们假设一个力模型有三个组成部分,即外力,约束漂移力和扰动力。发现这些力足以描述密集人群视频中的线性或近线性运动。与现有的流行人群分割方法相比,该方法明显更快。已经在公开可用的数据集上以及使用我们的数据集对所提出的模型进行了评估。已经观察到,与现有技术相比,所提出的方法能够以更高的精度估计和分割密集人群中的线性流,并且计算开销显着降低。 |
| End-to-End Robotic Reinforcement Learning without Reward Engineering Authors Avi Singh, Larry Yang, Kristian Hartikainen, Chelsea Finn, Sergey Levine 深度神经网络模型和强化学习算法的结合使得有可能学习直接读取原始感觉输入的机器人行为的策略,例如相机图像,有效地将估计和控制都包含在一个模型中。然而,强化学习的现实世界应用必须通过手动编程的奖励函数来指定任务的目标,这在实践中需要设计相同的感知管道,端到端强化学习有望避免,或者检测环境使用其他传感器来确定任务是否已成功执行。在本文中,我们提出了一种方法,通过使机器人从少量成功结果的示例中学习,然后主动请求查询,机器人向用户显示状态并询问,从而消除对奖励规范的手动工程的需要。用于标签以确定该状态是否表示任务的成功完成。虽然为每个州申请标签等于要求用户手动提供奖励信号,但我们的方法只需要在培训期间看到的一小部分状态的标签,使其成为学习技能的有效和实用的方法,而无需手动设计奖励。我们在现实世界的机器人操作任务上评估我们的方法,其中观察包括由机器人的相机观察的图像。在我们的实验中,我们的方法有效地学习直接从图像中排列对象,放置书籍和悬垂布料,而无需任何手动指定的奖励功能,并且与现实世界仅进行了1 4小时的交互。 |
| Unsupervised Discovery of Multimodal Links in Multi-Image, Multi-Sentence Documents Authors Jack Hessel, Lillian Lee, David Mimno 图像和文本在网络上的任何地方都会出现,但图像和句子或其他文档内文本单元之间的显式链接通常不会被用户注释。我们提出了成功发现图像句子关系的算法,而不依赖于任何显式的多模态注释。我们在七个不同难度的数据集上探索了我们的方法的几种变体,范围从人群工作者事后标题的图像到自然发生的用户生成的多模式文档,其中插图和单个文本单元之间的对应关系可能不是一对一的。我们发现基于识别图像和句子组合是否出现在文档中的结构化训练目标足以在测试时预测特定句子与同一文档内的特定图像之间的链接。 |
| Persistence Curves: A canonical framework for summarizing persistence diagrams Authors Yu Min Chung, Austin Lawson 持久性图是拓扑数据分析TDA领域的主要工具。它们包含有关数据形状的丰富信息。由于空间复杂,在持久性图空间中使用机器学习算法证明是具有挑战性的。因此,总结和矢量化这些图表是目前在TDA中研究的一个重要主题。在这项工作中,我们提供了一个总结框架的总体框架,我们称之为Persistence Curves PC。主要观点是所谓的持久同源的基本引理,它源于经典的老年统治。在这个框架下,某些众所周知的摘要,例如持久性Betti数和持久性格局,都是PC的特例。此外,我们证明了对一般家庭PC的严格约束。特别是,某些PC系列在额外的假设下承认稳定性。最后,我们将PC应用于四个众所周知的纹理数据集上的纹理分类。结果优于现有的几种TDA方法。 |
| Three scenarios for continual learning Authors Gido M. van de Ven, Andreas S. Tolias 标准的人工神经网络遭受众所周知的灾难性遗忘问题,使机器学习难以持续或终身学习。近年来,已经提出了许多用于连续学习的方法,但是由于评估协议的差异,难以直接比较它们的性能。为了实现更有条理的比较,我们根据是否在测试时提供了任务标识以及是否必须推断出任务标识来描述三种持续学习方案。可以根据每个场景执行任何明确定义的任务序列。使用拆分和置换的MNIST任务协议,对于每个场景,我们对最近提出的连续学习方法进行了广泛的比较。我们在难度和不同方法的效率方面证明了三种情景之间的实质性差异。特别是,当必须推断出任务标识,即类增量学习时,我们发现基于正则化的方法,例如弹性权重合并失败,并且似乎需要重现先前经验的表示来解决该场景。 |
| RES-PCA: A Scalable Approach to Recovering Low-rank Matrices Authors Chong Peng, Chenglizhao Chen, Zhao Kang, Jianbo Li, Qiang Cheng 强大的主成分分析RPCA因其在恢复低秩矩阵方面的强大功能以及各种现实问题中的成功应用而备受关注。当前现有技术的算法通常需要求解大矩阵的奇异值分解,其通常至少具有二次或甚至三次复杂度。这个缺点限制了RPCA在解决现实世界问题中的应用。为了克服这个缺点,在本文中,我们提出了一种新型的RPCA方法RES PCA,它在数据大小和维度上都具有线性效率和可扩展性。为了进行比较,AltProj是RPCA的现有可扩展方法,需要精确知道真正的等级,否则可能无法恢复低等级矩阵。相比之下,即使两种方法都有效,我们的方法也可以使用或不知道真正的等级,我们的方法更快。已经进行了大量的实验,并且证明了所提出的方法在定量和视觉质量方面的有效性,这表明我们的方法适合在任何应用管道中用作RPCA的轻量级,可扩展的组件。 |
| Discriminative Regression Machine: A Classifier for High-Dimensional Data or Imbalanced Data Authors Chong Peng, Qiang Cheng 我们在本文中引入了一种监督分类的判别回归方法。它在考虑类之间的判别性的同时估计表示模型,从而能够准确地推导出分类信息。这种新型的回归模型通过明确地结合判别信息来扩展现有模型,例如岭,套索和组套索。作为一个特例,我们专注于一个允许封闭形式分析解决方案的二次模型。相应的分类器称为判别回归机DRM。进一步为DRM建立了三种迭代算法,以提高实际应用的效率和可扩展性。我们的方法和算法适用于一般类型的数据,包括图像,高维数据和不平衡数据。我们将DRM与当前最先进的分类器进行比较。我们广泛的实验结果表明DRM具有优越的性能,并证实了该方法的有效性。 |
| Object-Oriented Dynamics Learning through Multi-Level Abstraction Authors Guangxiang Zhu, Jianhao Wang, Zhizhou Ren, Chongjie Zhang 用于学习动作条件动力学的基于对象的方法已经证明了泛化和可解释性的前景。然而,现有方法遭受具有多个动态对象的常见环境的结构限制和优化困难。在本文中,我们提出了一种新颖的自监督学习框架,称为多级抽象面向对象预测器MAOP,它采用三级学习架构,能够从原始视觉观察中进行有效的基于对象的动态学习。我们还为MAOP设计了一种空间时间关系推理机制,以支持实例级动态学习并处理部分可观察性。我们的研究结果表明,MAOP在样本效率方面明显优于以前的方法,并且在学习环境模型的新环境中具有广泛性。我们还证明,学习动力学模型能够在看不见的环境中进行有效规划,与真实环境模型相比。此外,MAOP学习语义和视觉上可解释的解开的表示。 |
| Counterfactual Visual Explanations Authors Yash Goyal, Ziyan Wu, Jan Ernst, Dhruv Batra, Devi Parikh, Stefan Lee 反事实查询通常具有形式对于情况X,为什么结果是Y而不是Z.对这种查询的反事实解释或回应的形式如果X是X,则结果将是Z而不是Y. |
| Suction Grasp Region Prediction using Self-supervised Learning for Object Picking in Dense Clutter Authors Quanquan Shao, Jie Hu, Weiming Wang, Yi Fang, Wenhai Liu, Jin Qi, Jin Ma 本文重点介绍杂乱场景中的机器人拾取任务。由于姿势,堆垛类型和拣选情况下复杂背景的多样性,在抓住它们之前很难识别和估计它们的姿势。在这里,本文结合Resnet和U网结构,一个卷积神经网络CNN的特殊框架,预测采摘区域无需识别和姿态估计。它使机器人拣选系统从头开始学习拣选技巧。与此同时,我们通过在线样本对端到端的网络进行培训。在本文的最后,进行了几个实验来证明我们的方法的性能。 |
| Combining RGB and Points to Predict Grasping Region for Robotic Bin-Picking Authors Quanquan Shao, Jie Hu 本文重点介绍杂乱场景中的机器人拾取任务。由于物体的多样性和放置的杂乱,在抓握之前很难识别和估计它们的姿势。在这里,我们使用U net,一种特殊的卷积神经网络CNN,将RGB图像和深度信息结合起来预测拾取区域,而无需识别和姿态估计。比较了网络的各种视觉输入的效率,包括RGB,RGB D和RGB点。我们发现RGB点输入可以获得95.74的精度。 |
| Predicting Fluid Intelligence of Children using T1-weighted MR Images and a StackNet Authors Po Yu Kao, Angela Zhang, Michael Goebel, Jefferson W. Chen, B.S. Manjunath 在这项工作中,我们利用T1加权MR图像和StackNet来预测青少年的流体智力。我们的框架包括特征提取,特征标准化,特征去噪,特征选择,训练StackNet和预测流体智能。提取的特征是不同脑分割区域中不同脑组织的分布。拟议的StackNet由三层和11个模型组成。每个图层都使用包含输入图层在内的所有先前图层的预测。建议的StackNet在公共基准青少年脑认知发展神经认知预测挑战2019上进行测试,并在组合训练和验证集上实现了82.42的平均绝对误差,具有10倍交叉验证。 |
| Exploiting Computation Power of Blockchain for Biomedical Image Segmentation Authors Boyang Li, Changhao Chenli, Xiaowei Xu, Taeho Jung, Yiyu Shi 基于深度神经网络的生物医学图像分割DNN是一种有助于临床诊断的有前景的方法。这种方法需要巨大的计算能力,因为这些DNN模型是复杂的,并且训练数据的大小通常非常大。随着基于工作证明PoW的区块链技术被广泛使用,维持了大量的计算能力PoW共识。在本文中,我们提出了一种设计,利用区块链矿工的计算能力进行生物医学图像分割,让矿工进行图像分割作为有用工作PoUW的证明,而不是计算使用较少的哈希值。这项工作通过解决相关其他方面的各种限制而与其他产品区别开来。如第5节所示的开销评估表明,对于U net和FCN,数字信号特性的平均开销分别为1.25秒和0.98秒,以及平均开销。网络分别为3.77秒和3.01秒。这些定量实验结果证明,数字签名和网络的开销很小,可与其他现有的PoUW设计相媲美。 |
| Natural Language Semantics With Pictures: Some Language & Vision Datasets and Potential Uses for Computational Semantics Authors David Schlangen 在深度学习革命的推动和推动下,近年来已经看到引入了更大的用自然语言表达注释的图像语料库。我们通过将图像视为自然语言表达的语义标注,采用一种反映通常方向性的视角,对这些语料库进行了调查。我们讨论可以从语料库中导出的数据集,以及可以在那些上定义的计算语义学家可能感兴趣的任务。在这里,我们利用语料库提供的关系,即表达和图像之间的联系,以及链接到同一图像和关系的两个表达之间的关系,我们可以在表达之间或图像之间添加相似关系。具体来说,我们通过这种方式表明,我们可以创建可用于学习和评估词汇和构成基础语义的数据,并且我们表明链接到相同的图像关系会跟踪注释器即使在没有注释器时也能识别的语义蕴涵关系。链接图像作为证据。最后,作为这种方法可能带来的好处的一个例子,我们表明基于示例模型的暗示方法胜过一个基于某些派生数据集的简单分布空间,同时有助于解释。 |
| Chinese Abs From Machine Translation |
Papers from arxiv.org
更多精彩请移步主页

pic from pixels.com