决策树相关算法——Bagging之基于CART的随机森林详细说明与实现
1 前言
1.1 本篇博客主要记录的是基于CART决策树实现的随机森林算法,主要是从以下四个方面介绍: CART决策树的构建思想;集成学习中的Bagging思想;基于CART决策树的随机森林代码实现;随机森林不易过拟合的分析。(其中不易过拟合并不是说随机森林不会过拟合)
1.2 本篇博客之前的一篇博客决策树相关算法——ID3、C4.5的详细说明及实现详细的记录了决策树的思想,概念及相关公式的详解,此篇博客便不做雷同叙述。
2 CART决策树的构建思想
2.1 CART与ID3和C4.5的一些小差异
1.CART决策树构建的是二叉树,而通过ID3和C4.5算法构建的是多叉树。
2.CART可用于回归预测和分类问题, ID3和C4.5的决策树一般来说用于分类问题。
3.CART与ID3和C4.5都是不断特征空间进行划分,构建成一颗划分特征空间的树。构造决策树方式有两点不同:
第一点,特征选择的方式不一样。ID3和C4.5分别是根据信息增益和信息增益比选择特征,再根据特征的所有特征值划分为多个子树。CART分类问题中是根据Gini系数在某个特征取某个值时候得大小进行特征选择和特征值选择。CART回归问题是根据最小化预测误差(平方误差)来进行进行特征选择和特征值选择。
第二点,特征空间划分的方式不一样。ID3和C4.5选择某个特征划分后,该特征便不再参与接下来的子树的特征选择划分,最后生成的决策树是局部最优的,采取的贪心的思想。CART是根据某个指标(预测误差或Gini系数)最优寻找最优特征划分点和最优特征划分值,来不断二分特征空间。
2.2 Sklearn中CART的实现解读
1.from sklearn.tree import DecisionTreeClassifier 二叉分类树
2.from sklearn.tree import DecisionTreeRegressor 二叉回归树
2.2.1 类结构上分析
1.DecisionTreeClassifier与DecisionTreeRegressor都继承BaseDecisionTree
2.BaseDecisionTree中定义好决策树实现的结构:包括生成决策树、使用决策树预测数据、决策树中的成员变量设置。#而具体如何实现交由子类决定。
#子类通过代码来决定是构建回归树还是分类树
super(DecisionTreeClassifier, self).__init__/.fit
super(DecisionTreeRegressor, self).__init__/.fit
3.DecisionTreeClassifier除继承BaseDecisionTree外还继承了ClassifierMixin。
DecisionTreeRegressor除继承BaseDecisionTree外还继承了RegressorMixin。
ClassifierMixin和RegressorMixin除设置决策树的类型外,还有计算决策树模型的性能Score的作用。
#_estimator_type = "classifier"
#_estimator_type = "regressor"
2.2.2 CART的生成详解
CART的生成主要分为回归树的生成和分类树的生成。对一个多维特征空间(即由各个特征为维度组成的特征空间,每一个样本即为特征空间中的点)的划分——寻找特征空间的最优特征(维)和该特征的取值进行二分,回归树采用的是最小化平方误差准则,而分类树采用的是基尼系数最小化准则。
经过划分好的特征空间对应着R1,R2,…,RM个不同的空间区域,每一个空间区域对应着相应的预测值c1,c2,…,cm——类别或者要预测的回归值
如何在一个特征空间不断的划分空间区域,即不断的寻找各自的划分点???及何时停止对特征空间的划分???
回归树的方式——最小化平方误差准则
平方误差的公式为:
每经过一次划分后形成的区域为两块,类似于切蛋糕似的划分,其中j表示选择划分的特征,在空间中即为j轴,s为j轴上的取值点:
于是对于划分的结果就会产生一个回归误差,目标就是寻找最优切分特征j和最优切分点s使得下面式子最小:
划分步骤:
1.遍历特征空间中的特征轴j,对固定的切分特征j扫描切分点s,使上式最小。得到一个值(j,s)。
2.选定(j,s)后切分空间为R1和R2并设定响应的取值Ci取值为该区间所有yi的平均值。
3.继续对两个区域进行相应的切分,直至满足停止条件(设定区间的样本数小于设定的阈值或者均分误差小于设定的阈值或没有特征可供选择了)
4.最后生成决策回归树
分类树的方式——最小化基尼系数准则
分类树用基尼系数选择特征,同时决定该特征对应的最优二值切分点。
基尼系数的计算 上一篇博客已经给出。遍历特征A,找出使Gini(D,A)最小的特征及在特征A上响应的取值a.作为最优划分点。分别对左右子树再进行查找,直达达到停止条件(设定区间的样本数小于设定的阈值或者均分误差小于设定的阈值或没有特征可供选择了)。
其中A=a的查找方法是将离散型的特征取值按顺序排列,分别求出两两间的中值,在特征A的基础上遍历中值看看那个取值a能使Gini(D,A)最小。
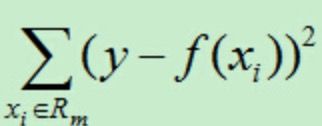

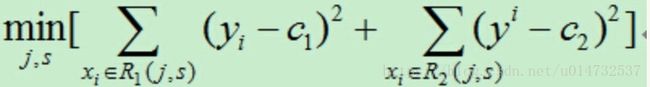
2.2.3 Sklearn中的CART的生成代码分析
#1.设置搜索切分点J,s的最小化标准是CRITERIA_CLF/CRITERIA_REG
criterion = self.criterion
if not isinstance(criterion, Criterion):
#是二叉分类树,CRITERIA_CLF包括gini系数
if is_classification:
criterion = CRITERIA_CLF[self.criterion](self.n_outputs_,self.n_classes_)
else:
#二叉回归树,CRITERIA_REG包括mse回归预测误差
criterion = CRITERIA_REG[self.criterion](self.n_outputs_,n_samples)
#2.从代码中可以看出寻找划分点的代码被抽象出成为一个类Splitters,包含多种寻找切分点的方式 。
#Splitters are called by tree builders to find the best splits on both
splitter = self.splitter
if not isinstance(self.splitter, Splitter):
splitter = SPLITTERS[self.splitter](criterion,
self.max_features_,
min_samples_leaf,
min_weight_leaf,
random_state,
self.presort)
#3.build二叉决策树,根据是否设置max_leaf_nodes决策树的最大叶节点数,有两种构建二叉决策树的方法DepthFirstTreeBuilder深度优先树和BestFirstTreeBuilder最佳优先树
if max_leaf_nodes < 0:
builder = DepthFirstTreeBuilder(splitter, min_samples_split,
min_samples_leaf,
min_weight_leaf,
max_depth,
self.min_impurity_decrease,
min_impurity_split)
else:
builder = BestFirstTreeBuilder(splitter, min_samples_split,
min_samples_leaf,
min_weight_leaf,
max_depth,
max_leaf_nodes,
self.min_impurity_decrease,
min_impurity_split)
#具体构建的过程在C代码中实现的。python中只是调用了
#from /Users/jian/anaconda2/envs/python36/lib/python3.6/site-packages/sklearn/tree/_tree.cpython-36m-darwin.so这个动态库中
builder.build(self.tree_, X, y, sample_weight, X_idx_sorted)
具体的构建树的C代码地址为_tree.pyx和具体切分代码为_splitter.pyx
#1.build树代码的重要代码
while not stack.is_empty():
{
if not is_leaf:
#寻找切分点
splitter.node_split(impurity, &split, &n_constant_features)
# If EPSILON=0 in the below comparison, float precision
# issues stop splitting, producing trees that are
# dissimilar to v0.18
is_leaf = (is_leaf or split.pos >= end or
(split.improvement + EPSILON <
min_impurity_decrease))
#记录下切分点
node_id = tree._add_node(parent, is_left, is_leaf, split.feature,
split.threshold, impurity, n_node_samples,
weighted_n_node_samples)
#将左右节点入栈,以继续进行切分
if not is_leaf:
# Push right child on stack
rc = stack.push(split.pos, end, depth + 1, node_id, 0,
split.impurity_right, n_constant_features)
if rc == -1:
break
# Push left child on stack
rc = stack.push(start, split.pos, depth + 1, node_id, 1,
split.impurity_left, n_constant_features)
if rc == -1:
break
}
创建CART的树过程可以自行详细了解。
2.2.4 CART的预测
#验证X数据集
X = self._validate_X_predict(X, check_input)
#调用C中的预测函数
proba = self.tree_.predict(X)
n_samples = X.shape[0]
#判断时分类问题还是回归预测
# Classification
if is_classifier(self):
#self.n_outputs是要预测的label维数
if self.n_outputs_ == 1:
return self.classes_.take(np.argmax(proba, axis=1), axis=0)
else:
predictions = np.zeros((n_samples, self.n_outputs_))
for k in range(self.n_outputs_):
predictions[:, k] = self.classes_[k].take(
np.argmax(proba[:, k], axis=1),
axis=0)
return predictions
# Regression
else:
if self.n_outputs_ == 1:
return proba[:, 0]
else:
return proba[:, :, 0]
3 集成学习中的Bagging思想
3.1集成学习概述
1.简单的说是集成学习是由多个弱分类器进行学习,将学习的结果经过某种组合策略并最终输出要预测的值的一个过程。主要有两点要求:弱分类器有一定的学习能力;弱分类器之间有一定的差异。
2.集成学习主要有2种组合策略:Bagging,Boosting.其中也可以了解下Stacking.
本篇博客主要是使用CART作为基础分类器,按照一定的组合策略进行集成学习实践。
3.2 Bagging(Bootstrap aggregating)再采样
其中Bootstrap为有放回的采样方法。
Bootstrap aggregatinga的一般方式为:
1.从样本集D中选出一定数量的样本N,选完后再将这N个样本放回,重复该取样操作M次,得到M个数据集D1,D2,…,DM。
2.在所有特征属性上利用M个数据集训练出M个弱分类器。
3.组合这M个分类器预测的结果。投票法或平均法。
其中随机森林Random forest便属于Bagging方式中的一种。接一下着重实现随机森林的算法。
3.3 Boosting提升方法
Boosting也是学习一系列弱分类器,并将其组合为一个强分类器。
Boosting的一般方式为:
1.根据初始训练数据集训练出基分类器。
2.根据基分类器上的表现上(误差)上,调整训练集的样本权重——使之前分错的样本更受分类器关注,然后再对调整后的训练集样本和前几个分类器加权累加组合进行训练得到下一个分类器。
3.如此重复学习出M个分类器,最后的组合分类器便是由这M个分类器加权累加组成。
接下来几篇博客将详细记录实现Boosting的过程,此篇不再叙述。
4 基于CART决策树的随机森林的实现
随机森林主要体现两个随机性:随机采样+随机选取特征
主要步骤:
1.从样本集通过BootStrap方式采取n个样本构成数据集D。
2.从所有特征中随机选择K个特征,在数据集D上训练CART决策树。
3.重复步骤1,2,M次,得到M个CART决策树,于此便建立了含M个CART的决策树的随机森林。
4.根据这M个CART决策树预测的结果,进行一定策略(可以是投票或者平均)的组合,得到最终结果。
说明:其中随机采取的样本个数n和随机选择的特征数,需要根据经验来设定。
随机森林代码实现示例:
代码地址
# 1 导入相关包,定义分类还是回归枚举类型
from sklearn.tree import DecisionTreeRegressor
from sklearn.tree import DecisionTreeClassifier
from enum import Enum
class TypeClass(Enum):
DecisionTreeClassifier_type = 1
DecisionTreeRegressor_type = 2
# 2 创建基于CART的随机森林,主要两个随机采样函数
# random.sample和dataframe.sample
def randomforst(D,N,M,K,type_class):
"""
:param D: 数据集D,格式为[Feature,label],类型为np.ndarray
:param N: 一次随机选取出的样本数
:param M: M个基分类器
:param k: 所有特征中选取K个属性
"""
D_df = pd.DataFrame(D)
D_df.as_matrix()
trees = []
for count in M:
# 随机采样N个样本
D_df_i = D_df.sample(N)
# 随机选取K个特征
#包含label所以需要减1
feature_length = D_df.shape[0] - 1
feature_list = range(feature_length)
choice_features = random.sample(feature_list,K)
#最终的Di数据集
D_df_i_data = D_df_i[choice_features]
if isinstance(type_class,TypeClass):
if type_class == TypeClass.DecisionTreeClassifier_type:
cart_t = DecisionTreeClassifier(criterion='gini')
else:
cart_t = DecisionTreeRegressor(criterion='mse')
y = D_df_i_data[-1].as_matrix()
X = D_df_i_data.drop([-1], axis=1).as_matrix()
tree = cart_t.fit(X, y)
trees.append(tree)
else:
raise Exception('input param error')
return trees
#3 预测
def randomforst_predict(trees,test_x, type_class):
if isinstance(type_class, TypeClass):
results = []
for tree in trees:
result = tree.predict(test_x)
results.append(result)
results_np = np.array(results)
if type_class == TypeClass.DecisionTreeClassifier_type:
return get_max_count_array(results_np)
else:
return np.mean(results_np)
else:
raise Exception('input param error')
def get_max_count_array(arr):
count = np.bincount(arr)
max_value = np.argmax(count)
return max_value
5 随机森林不易过拟合的分析
前提:此处说的不易过拟合是相对于单个决策树而言的.
过拟合:表示算法模型在训练数据上拟合的非常好,但是在测试的新数据上泛化能力弱。
一般来说训练数据上的模型复杂度和误差关系如下:

1.Bias表示偏差,可理解为模型拟合训练数据的程度。Bias越小表示模型更拟合训练数据。
2.Variance表示方差,可理解为模型拟合测试的新数据集的程度。Variace越大表示泛化能力越差。
3.可以看出训练的模型越复杂,越容易发生过拟合的情况。
随机森林有两个随机选择过程:
1.所有特征中随机选择部分特征,一定程度上降低了模型分类器的复杂程度。可能又会有疑问,随机选择的特征会把对label重要的特征给漏选了,对这一点上,重复进行了M次随机特征选择的构成一个由M个弱分类器的组合,这将不会使得重要的特征给遗漏掉。
2.从总数据集上随机选取一定数量的样本数据,我们都知道数据集上是存在数据噪音的,这也是造成模型容易过拟合的原因,从总数据集上随机选取一定数量的样本数据,将在一定程度上降低数据噪音的数量。
6 参考说明
6.1《统计学习方法》——李航
6.2 决策树相关算法——ID3、C4.5的详细说明及实现