Spark各种模式的环境搭建及相关工作流程介绍
1前言
本篇博客主要记录的是Spark的3种运行模式及对应的模式环境搭建过程和流程介绍。3种模式都是经过实践记录详细的操作过程和注意事项。
在进行环境的配置过程中,建议先理解每个模式下的工作流程,然后再进行环境搭建,这样容易加深理解。由于Spark on YARN是搭建在HDFS分布式环境下的,所以此处可以参考一下Hadoop环境搭建及相关组件的工作流程介绍进行环境搭建,对应的软件下载地址密码: k9ir
2Spark一些核心概念
Application: 用户编写的Spark应用程序,同等于MapReduce需要处理的一个或多个任务job。由Driver程序和Executor程序组成。
**Driver:**运行Application的main函数并创建SparkContext,SparkContext的目的是为了准备Spark应用程序的运行环境。SparkContext负责资源的申请、任务分配和监控等。
**Exector:**为某Application而在Worker Node上运行的一个进程,负责运行Task。每个Application都有各自独立的一批Executor。 在Spark on Yarn模式下,Exector的进程名称为CoarseGrainedExecuor Backend,一个CoarseGrainedExecuor Backend进程有且只有一个Exector对象,负责将Task包装成taskRunner,并从线程池中抽取出一个空闲线程运行Task.
Cluster Manager:集群管理器,指的是集群上获取资源的外部服务,主要要3种类型。
a.Standalone:spark原生的资源管理,由Master负责资源的分配。
b.Apache Mesos
c.Hadoop Yarn:主要指的是Yarn中的ResourceManager和NodeManager的资源管理调度框架。
Worker:集群中可以运行Application代码的节点,类似于Yarn中的NodeManager节点。
Task:Application的运行基本单位,Executor上的工作单元,类似于MapReduce中的MapTask和ReduceTask。多个Task组成一个Stage,而Task的调度和管理由TaskSchedule负责。
Job:包含多个Task组成的并行计算由Spark Action原子操作触发产生,一个Application可以包含多个Job。每个Job包含多个Stage。
State:每个Job会拆分为多组Task,作为一个TaskSet,称为Stage。Stage的划分和调度有DAGScheduler负责。有Shuffle Map Stage和Result Stage两种。
RDD:Spark基本计算单元,是Spark最核心的东西。主要有Transformation和Action操作。它是能够被并行操作的数据集合。其存储级别可以是内存,磁盘,可通过spark.storage.StorageLevel设置。
DAGScheduler:根据job构建基于Staged的DAG,并提交Stage给TaskSchedule。其划分Stage的依据是RDD之间的依赖关系。
TaskScheduler:将TaskSet提交给Worder集群运行,每个Exector运行上面Task就在此分配。
3Spark各个模式运行配置及详细介绍
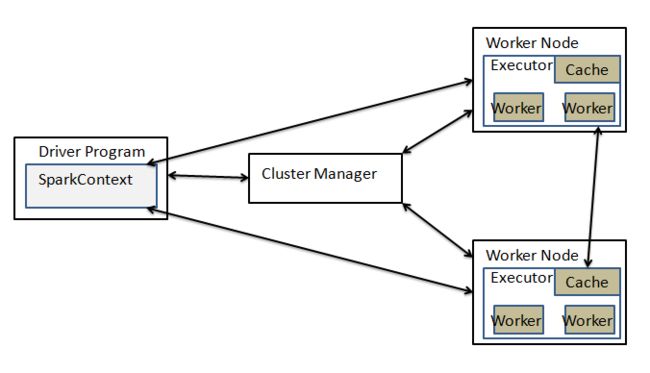
图说明:上图为Spark的基本运行流程图,不管是Spark什么模式运行,基本运行流程图如上所示,可能发生变化的就是各个组件的存放的节点位置和称呼不一样,但基本功能和运行流程不变。涉及到的核心概念如上。
a.各个模式涉及到的变化
local: 上图所有组件的运行都是在本地机上,且用线程的形式来完成分布式的任务。
Standalone: 需要将Spark部署到相关节点,需要指定master机器和Worder机器。此时的资源分配由master节点完成。
Yarn-Cluster: Driver和Exector都运行在Yarn集群,此时Spark运行流程图中的称呼master和执行任务的Worder不在使用,而是NodeManager,资源分布调度的是ResourceManager,且YARN中的运用程序管理ApplicationMaster管理Spark中的Driver,其中Driver在该ApplicationMaster的节点中。
**Yarn-client:**只有Exector运行在Yarn集群上。此时Spark运行流程图中的称呼master和执行任务的Worder不在使用,而是NodeManager,资源分布调度的是ResourceManager。此时YARN中的运行程序管理ApplicationMaster管理Spark中的Driver。其中Driver在Client的机器上。
b.spark各个模式下的应用程序的提交
两种方式:spark-shell和spark-submit
说明:总的来说,最后提交方式都是通过spark-submit的方式来提交,spark-shell运行的时候先进行了一些初始化的配置,然后再通过spark-submit的方式来进行提交应用程序。不过spark-shell是交互式的方式来进行应用的提交。接下来对各个模式下的部署和验证的实例使用spark-submit的方式进行。
参考:各个模式下的提交具体参数说明查看地址
c.总的来说,Spark运行模式取决于传递个SparkContext的deplyMode和master 参数的设置。
--master+ 参数:local、yarn-client、yarn-cluster
--deploy-mode+参数:cluster、client
spark-submit提交示例:
在$SPARK_HOME目录下:
命令:./bin/spark-submit \
--class \
--master \
--deploy-mode \
--conf = \
... # other options
\
[application-arguments]
命令参数说明:
application-jar:为应用程序的jar包
application-arguments:为应用程序中的调用参数
3.1Spark 本地模式介绍
说明: 所有程序都运行在一个JVM中,启动提交应用程序后,会产生一个SparkSubmit进程,既是客户提交任务的Client进程、又是Spark的driver程序、还充当着Spark执行Task的Executor角色。
软件准备: jdk-8u171-linux-x64.tar.gz,scala-2.11.8.tgz,spark-2.2.0-bin-2.6.0-cdh5.7.0.tgz(这块是自己编译好的spark包)
**情景说明:**VM1(master)192.168.1.77上运行的和进行如下配置
步骤1:分别解压到/home/zkpk/app/文件下
步骤2:gedit /home/zkpk/.bash_profile
#java
export JAVA_HOME=/usr/java/jdk1.8.0_171
export PATH=$JAVA_HOME/bin:$PATH
#spark
export SPARK_HOME=/home/zkpk/app/spark-2.2.0-bin-2.6.0-cdh5.7.0
export PATH=$SPARK_HOME/bin:$PATH
#scala
export SCALA_PATH=/home/zkpk/app/scala-2.11.8
export PATH=$SCALA_PATH/bin:$PATH
本地应用程序提交示例:终端的当前目录是$SPARK_HOME
命令:./bin/spark-submit --class org.apache.spark.examples.JavaWordCount --master local /home/zkpk/app/spark-2.2.0-bin-2.6.0-cdh5.7.0/examples/jars/spark-examples_2.11-2.2.0.jar file:///home/zkpk/app/data/words.txt
结果:spark: 972
hadoop: 1834
li: 972
welcome: 1836
jian: 1944
或者命令:./bin/spark-shell --master local
接下来使用scala语言进行交互式的运行。
验证查看:http://localhost:4040
3.2Spark standalone模式介绍
说明:集群模式为1 master + n worker。
前提:集群的网络主机名,hosts都已经设置好了。
情景:3台VM虚拟机
VM1主机名master,ip:192.168.1.77,充当standalon集群中的master,worker
VM2主机名slave1,ip:192.168.1.103,充当standalon集群中的worker.
VM3主机名slave2,ip:192.168.1.102,充当standalon集群中的worker.
各个VM的java版本是:jdk1.8.0_171
Scala版本是:scala-2.11.8
Spark版本是:spark-2.2.0-bin-2.6.0-cdh5.7.0
方法是:先配置好Master上的再复制到其他的主机上
1.配置$SPARK_HOME/conf/spark-env.sh(master)
命令:cp /home/zkpk/app/spark-2.2.0-bin-2.6.0-cdh5.7.0/conf/spark-env.sh.template /home/zkpk/app/spark-2.2.0-bin-2.6.0-cdh5.7.0/conf/spark-env.sh
命令:gedit /home/zkpk/app/spark-2.2.0-bin-2.6.0-cdh5.7.0/conf/spark-env.sh
JAVA_HOME=/usr/java/jdk1.8.0_171
SCALA_HOME=/home/zkpk/app/scala-2.11.8
SPARK_MASTER_HOST=master #设置spark的master主机,重要
SPARK_WORKER_CORES=2 #设置每个worker的核数
SPARK_WORKER_MEMORY=2g
SPARK_WORKER_INSTANCES=1 #每个节点的worker 进程数量
2.设置$SPARK_HOME/conf/spark-env.sh/slaves(master)
主要是设置sparkd的从节点主机名
命令:cp /home/zkpk/app/spark-2.2.0-bin-2.6.0-cdh5.7.0/conf/slaves.template /home/zkpk/app/spark-2.2.0-bin-2.6.0-cdh5.7.0/conf/slaves
命令:gedit /home/zkpk/app/spark-2.2.0-bin-2.6.0-cdh5.7.0/conf/slaves
master
slave1
slave2
3.将Master的集群配置复制到其他节点
命令:scp -r /home/zkpk/app/spark-2.2.0-bin-2.6.0-cdh5.7.0 zkpk@slave1:/home/zkpk/app/
命令:scp -r /home/zkpk/app/spark-2.2.0-bin-2.6.0-cdh5.7.0 zkpk@slave2:/home/zkpk/app/
命令:scp -r /home/zkpk/app/scala-2.11.8 zkpk@slave1:/home/zkpk/app/
命令:scp -r /home/zkpk/app/scala-2.11.8 zkpk@slave2:/home/zkpk/app/
复制配置文件:
命令:scp /home/zkpk/.bash_profile zkpk@slave1:/home/zkpk/.bash_profile
命令:scp /home/zkpk/.bash_profile zkpk@slave2:/home/zkpk/.bash_profile
再到各个主机slave1和slave2的主机下的终端分别运行:
命令:source /home/zkpk/.bash_profile
4.启动spark集群
命令:/home/zkpk/app/spark-2.2.0-bin-2.6.0-cdh5.7.0/sbin/start-all.sh
start-all.sh该脚本的工作:会在master机器上启动master进程,在$SPARK_HOME/conf/slaves文件配置的所有hostname的机器上启动worker进程。
浏览器查看:master:8080
或者命令查看:jps
或者启动方式:
命令:/home/zkpk/app/spark-2.2.0-bin-2.6.0-cdh5.7.0/sbin/start-master.sh
命令:/home/zkpk/app/spark-2.2.0-bin-2.6.0-cdh5.7.0/sbin/start-slaves.sh
5.应用程序提交示例
命令:spark-submit --class org.apache.spark.examples.JavaWordCount --master spark://master:7077 /home/zkpk/app/spark-2.2.0-bin-2.6.0-cdh5.7.0/examples/jars/spark-examples_2.11-2.2.0.jar file:///home/zkpk/app/data/words.txt
结果:
spark: 972
hadoop: 1834
li: 972
welcome: 1836
jian: 1944
注意:这里的file:///home/zkpk/app/data/words.txt文件存放在master节点上,需要复复制存放到各个节点的相同目录文件下,不过由于master VM 本身也是worker所以如果只放在master上也是能运行出结果的。所以这时候需要使用到hadoop HDFS文件系统,将更好。
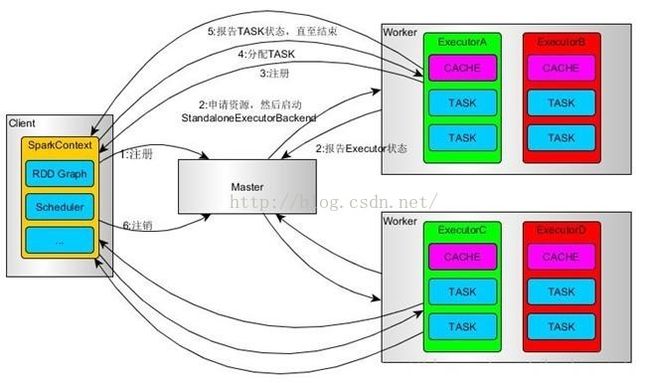
6.standalone模式下的运行流程图
3.3Spark YARN模式介绍
说明: 此模式需要建立在Hadoop集群上,文件存储于HDFS上,资源调度YARN,并行计算框架Spark.
此时Spark集群并不在是master和n个worker的形式,资源调度上是1个ResourceManager和n个NodeManager,文件系统是NameNode和DataNode的形式。Spark YARN模式有两种形式Client和集群模式。
前提: 集群的网络主机名,hosts都已经设置好了,Window有3个VM和Mac同处一个局域网下,VM采用桥接模式。
情景:3台VM虚拟机(Windows上)。
VM1主机名master,ip:192.168.1.77,HDFS中的NameNode和DataNode,YARN中的ResourceManager和NodeManager。
VM2主机名slave1,ip:192.168.1.103,HDFS中的DataNode,YARN中的NodeManager。
VM3主机名slave2,ip:192.168.1.102,HDFS中的DataNode,YARN中的NodeManager。
各个VMjava版本是:jdk1.8.0_171
Scala版本是:scala-2.11.8
Spark版本是:spark-2.2.0-bin-2.6.0-cdh5.7.0
1.设置spark-env.sh,各个节点下都需要设置好
命令:cp /home/zkpk/app/spark-2.2.0-bin-2.6.0-cdh5.7.0/conf/spark-env.sh.template /home/zkpk/app/spark-2.2.0-bin-2.6.0-cdh5.7.0/conf/spark-env.sh
命令:gedit /home/zkpk/app/spark-2.2.0-bin-2.6.0-cdh5.7.0/conf/spark-env.sh
HADOOP_HOME=/home/zkpk/app/hadoop
HADOOP_CONF_DIR=/home/zkpk/app/hadoop/etc/hadoop
2.HDFS上述要求的分布式环境搭建
参考上篇博客Hadoop环境搭建及相关组件的工作流程介绍
,其中需要注意的是java环境已经换成1.8了,相应的地方需要更改 H A D O O P H O M E / e t c / h a d o o p / h a d o o p − e n v . s h 中 的 j a v a 环 境 地 址 。 需 要 注 意 修 改 的 地 方 是 HADOOP_HOME/etc/hadoop/hadoop-env.sh中的java环境地址。 需要注意修改的地方是 HADOOPHOME/etc/hadoop/hadoop−env.sh中的java环境地址。需要注意修改的地方是HADOOP_HOME/etc/hadoop/yarn-site.xml(每个节点都需要修改)
命令:gedit $HADOOP_HOME/etc/hadoop/yarn-site.xml
yarn.nodemanager.aux-services
mapreduce_shuffle,spark_shuffle
yarn.nodemanager.aux-services.spark_shuffle.class
org.apache.spark.network.yarn.YarnShuffleService
spark.shuffle.service.port
7338
yarn.resourcemanager.hostname
master
注意:为避免NodeManger启动不了,各个节点需要拷贝${SPARK_HOME}/yarn/spark-2.2.0-yarn-shuffle.jar”到“${HADOOP_HOME}/share/hadoop/yarn/lib/”目录下
3.启动Spark on Yarn(master节点下)
1,首先启动Hadoop分布式。
命令:$HADOOP_HOME/sbin/start-all.sh
此时查看运行的进程命令:jps
有:NodeManager,NameNode,Jps,DataNode,ResourceManager
浏览器端查看:http://master:50070 ->HDFS文件
http://master:8088 ->运行调度
2.关闭任务:$HADOOP_HOME/sbin/stop-all.sh
4.应用程序提交示例,Spark on Yarn运行模式有两种运行情况。
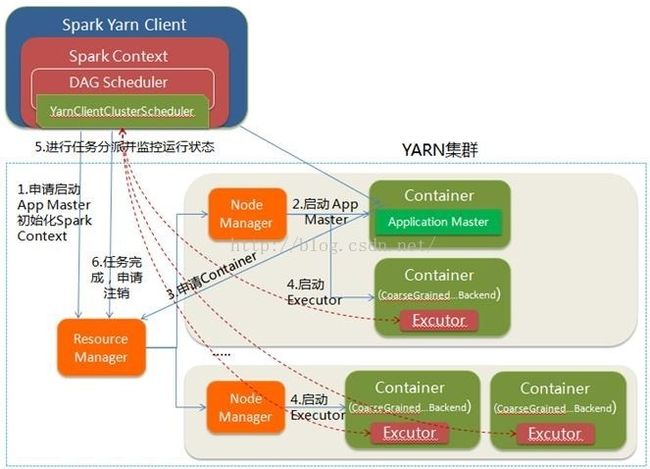
a.spark on yarn-client模式
driver运行在提交作业的机器上(可以看到程序打印日志)
命令:spark-submit --class org.apache.spark.examples.JavaWordCount --master yarn --deploy-mode client /home/zkpk/app/spark-2.2.0-bin-2.6.0-cdh5.7.0/examples/jars/spark-examples_2.11-2.2.0.jar hdfs://192.168.1.77:8020/words.txt
运行流程如下(摘自网上):
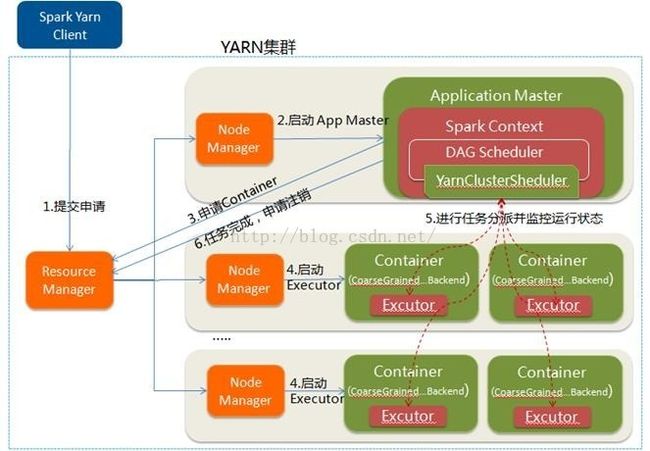
b.spark on yarn-cluster模式
driver运行在集群上某个机器上(看不到日志,只可以看到running状态),Driver在AppMaster执行.
命令:spark-submit --class org.apache.spark.examples.JavaWordCount --master yarn --deploy-mode cluster /home/zkpk/app/spark-2.2.0-bin-2.6.0-cdh5.7.0/examples/jars/spark-examples_2.11-2.2.0.jar hdfs://192.168.1.77:8020/words.txt
运行流程如下(摘自网上):
4问题
描述: HDFS分布式启动问题,有时候DataNode能启动,NameNode不能启动,有时候刚好相反。
解决: 清空hadoop HDFS设置的tmp文件夹,清空logs文件夹。再格式化HDFS,最后启动,问题能解决。
脚本:
#我的Hadoop home目录为/home/zkpk/app/hadoop
cd /home/zkpk/app
rm -r ./hadoop_tmp/
echo 'delete tmp ~'
rm -r ./hadoop/logs/
echo 'delete logs ~'
mkdir -p ./hadoop_tmp/dfs/data
mkdir -p ./hadoop_tmp/dfs/name
hdfs namenode -format
/home/zkpk/app/hadoop/sbin/start-dfs.sh