Java 工程师快速入门深度学习,就从 Deeplearning4j 开始
作者:万宫玺
随着机器学习、深度学习为主要代表的人工智能技术的逐渐成熟,越来越多的 AI 产品得到了真正的落地。无论是以语音识别和自然语言处理为基础的个人助理软件,还是以人脸识别为基础的刷脸付费系统,这些都是 AI 技术在现实生活中的实际应用。应当说 AI 正在走进千家万户,来到你我的身边。
另一方面,从研发角度来讲,AI 产品的落地并不是一件容易的事情:
- AI 技术数学理论要求高,数理统计、神经理论与脑科学、优化理论、矩阵论……
- AI 硬件层面要求非常高,GPU、TPU、FPGA……
如何基于目前的主流研究成果和硬件,对 AI 产品进行一站式的开发?这正是当前企业工程师面临的实际痛点。
对此,多家企业及研究机构推出了自己的解决方案,如 Google 推出并开源了 TensorFlow,Facebook 主导 PyTorch 和 Caffe 2,Amazon 选择 MXNet 并打算投资围绕 MXNet 的系统,微软开发并大力推广 CNTK…
这些都是以 Python 和 C/C++ 语言为主,而在目前企业项目中,无论是 Web 应用、Andriod 开发还是大数据应用,Java 语言都占有很大的比例。此外,我们必须看到,越来越多的从事传统 Java 应用开发的工程师尝试将 AI 技术融入到项目中,或者自身在尝试转型 AI 领域。因此如果有类似 TensorFlow、Caffe 这些 AI 解决方案而又同时基于 Java 的,那么无疑会为项目的推进及个人的发展带来很多便利。
Deeplearning4j 正是这类解决方案中的佼佼者。
Deeplearning4j 是什么
Deeplearning4j 是由美国 AI 创业公司 Skymind 开源并维护的一个基于 Java/JVM 的深度学习框架。同时也是在 Apache Spark 平台上为数不多的,可以原生态支持分布式模型训练的框架之一。此外,Deeplearning4j 还支持多 CPU/GPU 集群,可以与高性能异构计算框架无缝衔接,从而进一步提升运算性能。在 2017 年下半年,Deeplearning4j 正式被 Eclipse 社区接收,同 Java EE 一道成为 Eclipse 社区的一员。
为什么选择 Deeplearning4j
1.基于 Java,专为企业应用而生
Deeplearning4j 是基于 Java 的深度学习开源框架。从实际开发的角度上,它是面向 Layer 编程的神经网络开发框架,对很多常见的神经网络结构做了高度的封装,熟悉 Keras 的朋友可以认为 Deeplearning4j 是 Java 版本的 Keras。同时 Deeplearning4j 也完美兼容 Scala 和 Clojure。
2.丰富的开源生态圈,遵循 Apache 2.0
Deeplearning4j 也拥有自己的生态。在 Deeplearning4j 的相关开源项目中,就有专门为张量运算而开发的 ND4J 和数据处理的 DataVec。它们的作用相当于 Python 中的 NumPy 和 Pandas。当然,除了这些项目以外,Arbiter、RL4J 等项目也大大丰富了 Deeplearning4j 的生态圈。
3.与 Hadoop 和 Spark 集成,支持分布式 CPU 和 GPU
Deeplearning4j 是原生支持在 Apache Spark 上构建分布式深度学习解决方案的框架。由于在企业的实际应用场景中,大数据的统计和存储往往会依赖 Hive/HDFS 等存储介质。而算法模型的构建必须依赖庞大的数据,因此如果可以完成一站式的数据存储、数据提取和清洗、训练数据的构建、模型训练和调优的所有开发环节,无疑是非常理想的解决方案。Deeplearning4j 以数据并行化为理论基础构建了分布式神经网络建模的解决方案,为大数据 + 算法的开发提供了直接的支持。
Deepleanring4j 支持多 CPU/GPU 集群的建模。就像在上文中提到的,GPU 等硬件的成熟大大加速了 AI 的发展。Deeplearning4j 通过 JavaCPP 技术调用 cuBLAS 来实现在 GPU 上的加速建模。对于 GPU 集群的支持则需要依赖 Spark。
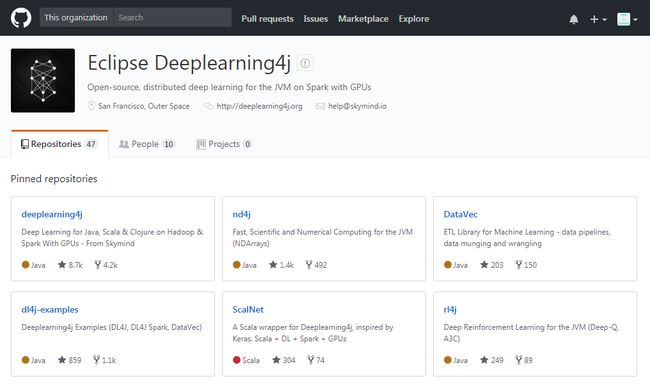
4.越来越受开发人员欢迎
自 Deeplearning4j 从 2016 年左右开源以来,功能优化与新特性的丰富使得项目本身不断得到完善,在 GitHub 上的 Commiter 活跃度与 Star 数量也不断增加,使得该开源框架越来越得到国内外企业的关注。就目前 Skymind 官网提供的信息来看,就有数十家明星企业和研发机构在部署使用 Deeplearning4j,其中就不乏有 Oracle、Cisco、IBM、软银、亚马逊、阿里巴巴等知名企业。
而随着 Deeplearning4j 在工业界的使用逐渐增多,更多的研发人员希望有一套教程可以用来辅助开发和作为参考,因此我在 GitChat 平台编写了这门《Deepleraning4j 快速入门》,希望可以帮助读者尽可能轻松与快速地掌握 Deeplearning4j 的使用。
Deeplearning4j 的最新进展
目前 Deeplearning4j 已经来到了 1.0.0-beta3 的阶段,马上也要发布正式的 1.0.0 版本。本课程我们主要围绕 0.8.0 和 1.0.0-alpha 展开(1.0.0-beta3 核心功能部分升级不大),这里罗列下从 0.7.0 版本到 1.0.0-alpha 版本主要新增的几个功能点:
- Spark 2.x 的支持(>0.8.0)
- 支持迁移学习(>0.8.0)
- 内存优化策略 Workspace 的引入(>0.9.0)
- 增加基于梯度共享(Gradients Sharing)策略的并行化训练方式(>0.9.0)
- LSTM 结构增加 cuDNN 的支持(>0.9.0)
- 自动微分机制的支持,并支持导入 TensorFlow 模型(>1.0.0-alpha)
- YOLO9000 模型的支持(>1.0.0-aplpha)
- CUDA 9.0 的支持(>1.0.0-aplpha)
- Keras 2.x 模型导入的支持(>1.0.0-alpha)
- 增加卷积、池化等操作的 3D 版本(>1.0.0-beta)
除此之外,在已经提及的 Issue 上,已经考虑在 1.0.0 正式版本中增加对 YOLO v3、GAN、MobileNet、ShiftNet 等成果的支持,进一步丰富 Model Zoo 的直接支持范围,满足更多开发者的需求。
你能从课程学到什么
本课程主要面向:
- 对 Deeplearning4j 入门感兴趣的初学者
- 希望转型人工智能领域的 Java 工程师
- 有科学计算背景的高校/企业工作人员
我将结合 Deeplearning4j 的特性来介绍目前主流深度学习研究成果,通过大量的实际案例来讲解 Deeplearning4j 在结构化数据、自然语言处理、机器视觉领域的应用,具体内容涉及:
- 多层感知机在分类和回归问题上的应用
- 深度信念网络在数据压缩问题上的应用
- 卷积神经网络在图像分类和目标检测问题上的应用
- 循环神经网络在文本分类/文本生成/序列标注等问题上的应用
- ……
课程还将结合 Deeplearning4j 支持的特性,从本地单 CPU/多 CPU 建模开始介绍,循序渐进,逐步将单 GPU/多 GPU 并行以及 Spark 集群建模的详细内容介绍给大家,从而在宏观层面尽可能对 Deeplearning4j 的内容介绍得详尽且实用。
由于 Deeplearning4j 生态圈的内容丰富,我将着重就最常用的 ND4J、DataVec、RL4J 做详细介绍。
作者简介
万宫玺,苏宁易购高级算法工程师。现任职于苏宁易购搜索研发中心,对机器学习/深度学习在自然语言处理、机器视觉等领域的应用开发有着丰富的经验,先后参与部门反作弊系统、智能问答机器人、Query 语义挖掘与分析系统等机器学习项目的开发。
学习建议
由于 AI 是一项跨多学科且对理论和工程开发都有着一定要求的技术,因此实际动手操作非常重要。只有自己动手做过一两个项目或者参加过一些算法比赛,研发人员才会对如何做好算法项目和产品有感性的认识,而不会仅仅停留在理论层面。踩坑虽然痛苦,但其实也是加深对理论理解的必需过程,在这个方面并没有太多捷径可走。
在学习本课程前,希望读者有一定的 Java 工程基础,以及对机器学习/深度学习理论的简单了解。对优化理论、微分学、概率统计有一定的认识,对理解神经网络的基础理论(如 BP 算法)将大有裨益。
最后需要说明的是,机器学习、深度学习领域发展迅速,我个人虽然专注机器学习领域的开发与应用多年,但是经验依然处于初窥门径的阶段,因此课程中难免存在错误和疏漏。希望大家在学习过程中发现任何问题及时帮忙指出,我会尽可能在第一时间修正。同时,我自己也希望和所有喜欢 AI 技术和本课程的朋友多些交流,不断完善和提高课程的质量。
课程目录
识别二维码或点此试读
