Mac安装Flume
一:简介
Flume 是Cloudera提供的一个高可用的,高可靠的,分布式的海量日志采集、聚合和传输的系统,Flume支持在日志系统中定制各类数据发送方,用于收集数据;同时,Flume提供对数据进行简单处理,并写到各种数据接受方(可定制)的能力。
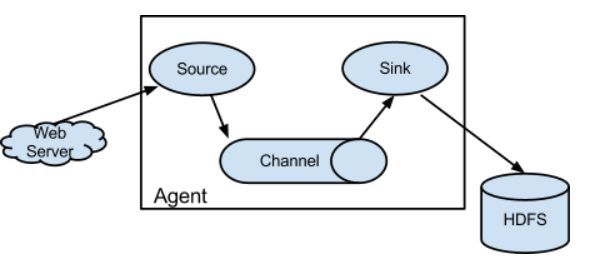
Agent主要由:source,channel,sink三个组件组成:
-
Source
从数据发生器接收数据,并将接收的数据以Flume的event格式传递给一个或者多个通道channel,Flume提供多种数据接收的方式,比如Avro,Thrift等 -
Channel
channel是一种短暂的存储容器,它将从source处接收到的event格式的数据缓存起来,直到它们被sinks消费掉,它在source和sink间起着桥梁的作用,channel是一个完整的事务,这一点保证了数据在收发的时候的一致性. 并且它可以和任意数量的source和sink链接. 支持的类型有: JDBC channel , File System channel , Memory channel等. -
sink
sink将数据存储到集中存储器比如Hbase和HDFS,它从channels消费数据(events)并将其传递给目标地. 目标地可能是另一个sink,也可能HDFS,HBase.
二:安装
1. 安装
brew install flume
2. 配置环境变量
vi ~/.bash_profile
export FLUME_HOME=/usr/local/Cellar/flume/1.9.0_1/libexec
export FLUME_CONF_DIR=$FLUME_HOME/conf
export PATH=$FLUME_HOME/bin:$PATH
source ~/.bash_profile
3. 配置flume-env.sh
cp flume-env.sh.template flume-env.sh
export JAVA_HOME=/Library/Java/JavaVirtualMachines/jdk1.8.0_141.jdk/Contents/Home
export JAVA_OPTS="-Xms100m -Xmx2000m -Dcom.sun.management.jmxremote"
如果不配置JAVA_OPTS会报错Exception in thread “main” java.lang.OutOfMemoryError: Java heap space
4. 查看版本号
cd $FLUME_HOME/conf
flume-ng version
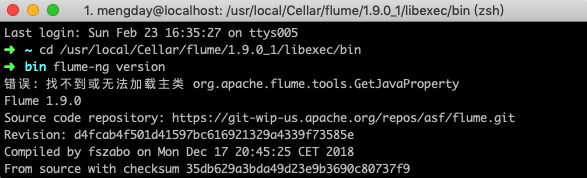
错误: 找不到或无法加载主类 org.apache.flume.tools.GetJavaProperty
解决办法一:可能是机器上安装HBase了,将libexec/conf/hbase-env.sh配置文件中的HBASE_CLASSPATH注释掉。
# export HBASE_CLASSPATH=/usr/local/Cellar/hadoop/3.2.1/libexec/etc/hadoop
解决办法二:HBASE_CLASSPATH改为JAVA_CLASSPATH
export JAVA_CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar
5. 启动
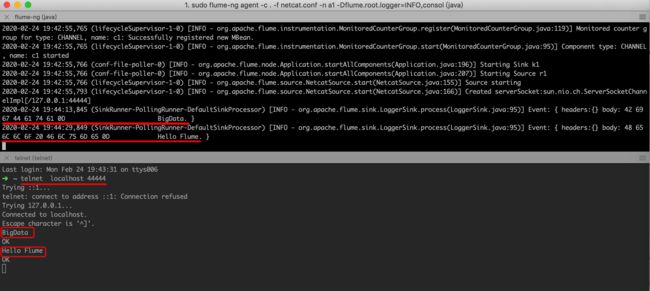
1. netcat
libexec/conf/netcat.conf
# Name the components on this agent
a1.sources = r1
a1.sinks = k1
a1.channels = c1
# Describe/configure the source
a1.sources.r1.type = netcat
a1.sources.r1.bind = localhost
a1.sources.r1.port = 44444
#同上,记住该端口名
# Describe the sink
a1.sinks.k1.type = logger
# Use a channel which buffers events in memory
a1.channels.c1.type = memory
a1.channels.c1.capacity = 1000
a1.channels.c1.transactionCapacity = 100
# Bind the source and sink to the channel
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1
sudo flume-ng agent -c . -f netcat.conf -n a1 -Dflume.root.logger=INFO,console
# telnet后输入一些英文(不要输入中文)回车
telnet localhost 44444
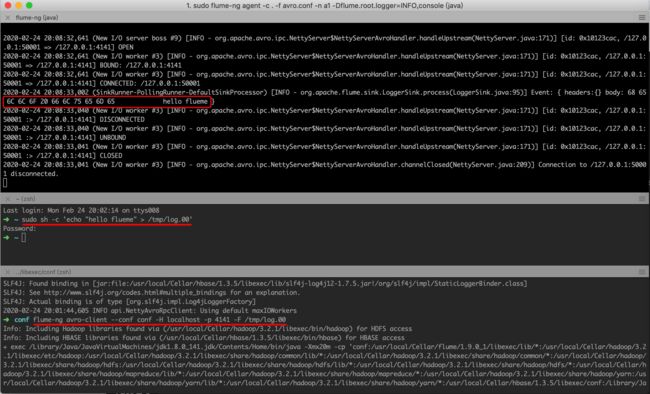
2. Avro
libexec/conf/avro.conf
a1.sources = r1
a1.sinks = k1
a1.channels = c1
# Describe/configure the source
a1.sources.r1.type = avro
a1.sources.r1.channels = c1
a1.sources.r1.bind = 0.0.0.0
a1.sources.r1.port = 4141
#注意这个端口名,在后面的教程中会用得到
# Describe the sink
a1.sinks.k1.type = logger
# Use a channel which buffers events in memory
a1.channels.c1.type = memory
a1.channels.c1.capacity = 1000
a1.channels.c1.transactionCapacity = 100
# Bind the source and sink to the channel
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1
cd $FLUME_HOME/conf
sudo flume-ng agent -c . -f avro.conf -n a1 -Dflume.root.logger=INFO,console
sudo sh -c 'echo "hello flueme" > /tmp/log.00'
# 读取/tmp/log.00文件中的内容
cd $FLUME_HOME/conf
flume-ng avro-client --conf conf -H localhost -p 4141 -F /tmp/log.00
3. spooldir
libexec/conf/flume.conf 文件需要手动创建。a1.sources.r1.spoolDir对应的目录也需要预先创建好mkdir -p /opt/logs/flume
vim flume.conf
# 指定Agent的组件名称
a1.sources = r1
a1.sinks = k1
a1.channels = c1
# 指定Flume source(要监听的路径)
a1.sources.r1.type = spooldir
a1.sources.r1.spoolDir = /opt/logs/flume
# 指定Flume sink
a1.sinks.k1.type = logger
# 指定Flume channel
a1.channels.c1.type = memory
a1.channels.c1.capacity = 1000
a1.channels.c1.transactionCapacity = 100
# 绑定source和sink到channel上
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1
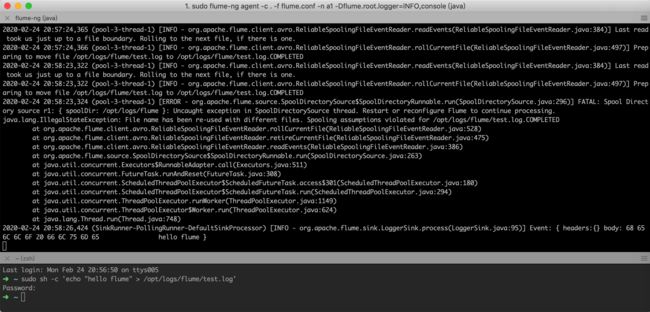
sudo flume-ng agent -c . -f flume.conf -n a1 -Dflume.root.logger=INFO,console
sudo sh -c 'echo "hello flume" > /opt/logs/flume/test.log'
三:Avro简介
Avro是Hadoop的一个数据序列化系统, 由Hadoop的创始人Doug Cutting(也是Lucene,Nutch等项目的创始人)开发,设计用于支持大批量数据交换的应用。也作为RPC框架。
1. User.avsc
{
"namespace": "com.example.avro",
"type": "record",
"name": "User",
"fields": [
{"name": "id", "type": "int"},
{"name": "name", "type": "string"},
{"name": "salary", "type": "int"},
{"name": "age", "type": "int"},
{"name": "address", "type": "string"}
]
}
2. 生成Java类
进入mvnrepository下载对应的Jar
# 根据User.avsc生成.java文件,保存的目录为src
java -jar avro-tools-1.9.2.jar compile schema User.avsc src

3. 引入依赖
<dependency>
<groupId>org.apache.avrogroupId>
<artifactId>avroartifactId>
<version>1.9.2version>
dependency>
4 .将生成的User.java文件放入到项目中
public class AvroTest {
public static void main(String[] args) throws Exception {
User user1 = new User();
user1.setId(1);
user1.setName("mengday");
user1.setSalary(1000);
user1.setAge(20);
user1.setAddress("beijing");
User user2 = new User(2, "vbirdbest", 1000, 19, "shanghai");
User user3 = User.newBuilder()
.setId(3)
.setName("bin")
.setAge(21)
.setSalary(2000)
.setAddress("shenzhen")
.build();
// 序列化
String path = "/Users/mengday/Desktop/avro/User.avsc";
DatumWriter<User> userDatumWriter = new SpecificDatumWriter<User>(User.class);
DataFileWriter<User> dataFileWriter = new DataFileWriter<User>(userDatumWriter);
dataFileWriter.create(user1.getSchema(), new File(path));
dataFileWriter.append(user1);
dataFileWriter.append(user2);
dataFileWriter.append(user3);
dataFileWriter.close();
// 反序列化
DatumReader<User> reader = new SpecificDatumReader<User>(User.class);
DataFileReader<User> dataFileReader = new DataFileReader<User>(new File("/Users/mengday/Desktop/avro/User.avsc"), reader);
User user = null;
while (dataFileReader.hasNext()) {
user = dataFileReader.next();
System.out.println(user);
}
}
}
