基于Nginx的媒体服务器技术

国内应用比较多的开源流媒体服务器nginx-rtmp-module一直存在功能少、集群化难度大等问题。在LiveVideoStack线上分享中,PingOS 开源项目组开发工程师、UCloud RTC研发工程师朱建平详细介绍了基于nginx-rtmp-module的PingOS流媒体服务器在http-flv、http-ts、hls+、多进程、转推、回源以及集群化部署方面的技术实现细节。
文 / 朱建平
整理 / LiveVideoStack
直播回放
https://www2.tutormeetplus.com/v2/render/playback?mode=playback&token=006643cdea15499d96f19ab676924e88

1. Nginx流媒体扩展:http-flv、http-ts、hls+

最初始的nginx-rtmp-module相关模型与包括SRS在内的多数流媒体服务器实际上是一样的(1个生产者,n个消费者)。Nginx存一个问题:它仅仅做了RTMP的消费模型,如果想扩展 http-flv或http-ts的形式会较为困难。由于rtmp-session仅供RTMP协议使用,如果想扩展http-flv,首先我们需要了解其基础分发模型(如上图所示):所有的生产者与消费者都会被挂载到同一个stream中,生产者负责从网络端接收数据,消费者从buffer中获取数据对外发送。

如果是发送flv数据,那么可以保留原有rtmp-session,当服务器收到一个HTTP请求时,创建一个rtmp-session,此session与网络不相关,仅仅是逻辑上的session。然后将这个session注入stream当中,如果是以消费者的角色注入进stream当中,则可以实现获取数据并往外分发。
假如此时服务器收到的是http-flv的请求,就可以创建一个逻辑上的session,并把它注入stream中,此时理论上我们可以获得的是rtmp的数据。但我们需要的是flv的数据,由于flv数据与rtmp数据相似,我们可以通过tag-header的方式非常简单的将rtmp数据还原成flv数据。
根据上述思路,在生产者和消费者模型中,消费者可以通过创建http-fake-session的形式来复用以前的分发流程并实现http-flv协议。我们对其进行扩展,创建一个http-fake-session作为生产者,并让http-fake-session与一个http client进行关联,关联之后http client负责从远程服务器端下载数据传递给生产者,生产者就可以把这些数据通过分发模型分发给下面的rtmp-session。这样也就间接实现了一个http回源的功能。通过上述思路我们就能够快速地实现http-flv的播放与拉流。
同样,我们可以根据上述思路继续扩展协议。假如我们在收到一个http请求之后,创建一个同样的rtmp-fake-session(逻辑上的session,与网络不相关),我们把它以消费者的角色插入到 stream当中。这样就可以从stream当中获取到需要向下分发的数据。需要注意的是:stream中最初保存的是rtmp数据而不是ts数据,无法直接获取ts数据。
1.1 http-flv在Nginx中的实现

基于Nginx实现http-flv需要注意以下几点细节:首先该实现复用了Nginx的分发模型以及http功能模块。(Nginx对http协议栈的支持更加完善,包括http1.0、http1.1协议)
在部分线上业务中,客户可能需要在下载http-flv时添加后缀,按照以往的实践逻辑我们会在代码当中过滤后缀。如果遇见更为复杂,如修改是否需要开启http chunked编码的需求,我们就只能修改代码。而如果是基于Nginx通过复用http的现有模块来实现http-flv,我们就可以通过nginx-http-rewrite功能来实现这些操作。因此使用nginx-http的原生功能来开发http-flv可以带来更多好处,如显著降低代码量。
在这里我曾经看到过一种情况:即复用了http模块,但没有复用rtmp的分发流程。这样就会导致我们需要将分发流程在http-flv中重新再做一遍,对业务的控制就会变得非常复杂。举个例子,假如此时有人请求播放,需要将消息通知给业务服务器。此时,如果rtmp与http-flv两种协议的实现是分开的,那么意味着如果两者都被触发,就需要分别向业务服务器进行汇报。于是我们就需要付出双倍的代码与逻辑维护工作,这无疑会显著增加开发与维护成本。
因此,最简单的实现方案就是flv不做任何与业务相关的处理,仅在下发的时候进行格式转换,相当于rtmp分发时只发 rtmp格式的数据,而flv分发时只需要将rtmp的数据打上flv的tag-header,然后再进行下发,这样就省去了业务层的开发。
http-flv播放实现

图中展示的是rtmp的缓存对于rtmp和http-flv这两个协议的支持。http-flv和rtmp二者共用一套缓存,其实rtmp本身传输的就是flv的数据,只不过是把tag-header给抛掉了。http-flv的下发与rtmp的下发唯一的区别点在于send函数不同:http-flv调用的是http的send函数,rtmp下发时调用的是原生的send函数,在下发前需要添加各自的协议头。二者共用一块内存可以达到节省内存的效果,并且实现业务统一,降低开发成本。
http-flv回源的实现
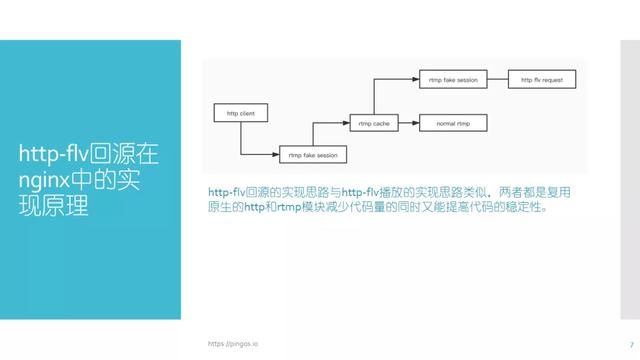
图中展示的是http-flv回源在nginx中的实现。http-flv回源实现的思路与http-flv的播放实现思路类似:即在需要回源的时候创建一个http client,http client所做的事情就是把http数据下载到本地。在下载数据到本地之前http client需要先创建一个rtmp fake session并将其作为生产者注入stream当中。而后http client开始从网络上下载数据并且将下载到的fIv数据拆成rtmp数据。
为什么要拆成rtmp数据?这是因为rtmp的推流过来的缓存数据类型是rtmp,因此从网上下载到的flv数据需要做一次拆分,拆成rtmp的数据,然后放入缓存。最终根据实际要求将数据转成rtmp或flv的格式。这样按照http-flv播放中rtmp fake session的逻辑,也就能够快速的实现http-flv的回源操作。
1.2 http-ts在Nginx中的实现

图中展示的是http-ts在Nginx中的实现。其实现思想与http-flv的实现基本一致,仅仅是在操作上有所不同,不同点在于http-ts需要一个独立的buffer进行缓存。由于http-ts与http-flv的数据格式相差较大,对于flv数据到rtmp来说,只需要将数据拆成一个个小块,并在前面添加一个header。即使flv数据的最一帧或者一个分块缺少也不用补齐。
但是ts数据不同,它的要求比较严格,每一分块必须为188字节,其中包括ts header以及有效载荷部分。并且如果数据库大小不足188个字节,则需要补齐。而rtmp的数据块没有严格固定要求其长度大小。对于ts数据来说,要想将flv数据转成ts数据,这个过程是需要消耗一些计算量的。
由于ts数据和flv的数据格式相差太大,因此在这里我们将ts的buffer与rtmp的buffer完全独立开。但此操作并不是默认开启的,需要在服务器中进行配置。开启配置后,才会将rtmp的buffer生成一份镜像的ts数据,这一部分的ts数据仅会供http-ts和hls两个协议使用。服务器中还涉及到一个原生的hls服务,在这里我们没有做任何的改动,而是加入了hls+的服务来使用这个buffer。
无论是ts还是hls+,它们都注册了自己的fake session,这样做的目的是为了统一业务。例如在有播放请求进入时,我们需要让业务服务器知道当前有请求产生。类似这种网络通知、事件通知的接口,在开发的过程中大家都希望只需要编写一份业务数据,而不是说做hls协议要针对hls播放写一个通知,做ts协议还要针对ts再写一份通知,这样业务代码会越来越庞大,最后导致服务几乎就很难维护。因此fakesession的作用是非常大的,其会把网络层与业务层完全隔离开。即使服务器本身的下发协议不是rtmp,创建一个rtmp-session并挂载到业务服务器中即可。
总的来说,http-ts与http-flv唯一实现区别就是获取buffer的位置不同。http-flv需要从rtmp buffer获取,http-ts则是从ts buffer中获取。
如果能理解http-flv的协议流程,那么也就不难理解http-ts的实现流程。
1.3 hls+在Nginx中的实现

图中展示的是hls+在nginx中的实现。hls+与传统hls不同,传统hls在服务端没有状态,服务端包含大量碎数据,客户端在不断执行下载,而hls+则会记录每一个客户端的状态。
对于如何记录每个客户端的状态,之前我曾尝试通过对hls+的连接创建一个虚拟连接用来记录状态。但是发现业务会比较复杂,并且后期会存在很多问题,包括代码量、bug以及维护成本等。于是更换另外一种思路,还是用fake session的方式来实现。利用fake session作为消费者放入,根据每次进入的http,连接,通过session ID进行绑定。由于第1次发送hls请求时客户端是不知道sessionID的,如果服务器获取到一个没有session ID的连接,则认为此客户端为第1次进入。客户端会接收到一个302的回复,302回复中会告诉客户端一个新的地址,其中包含一个session ID。客户端得到session ID之后,再次请求m3u8时,会加入session ID,服务器就可获取相应session ID并对客户端进行身份区分。这样就能够通过session ID记录每一个客户端的播放状态。
为什么要记录这个状态?这主要是因为服务器不是将数据直接写入硬盘而是放进内存,它需要知道每一个用户、每一个客户端的下载进度,并根据不同的进度从内存中定位ts数据。hls+和http-ts它们共用了一个 ts buffer,并且hls+是实时的从buffer中定位ts内容。所以对于hls+来说,并没有真正的ts数据产生,只是记录每一个文件在内存里面的偏移量。因此hls+不存在读写的问题,在做hls服务时,以前可能会遇到过一个问题——读写硬盘的瓶颈。机械硬盘的读写速度比较慢,普遍的解决思路就是挂载一个虚拟硬盘,将内存映射到目录中进行读写。如果采用的是hls+的方案,就可以省去挂载的操作,对于内存也并没有太多的消耗。而且如果同时有hls+以及 http-ts的需求,此时对于内存的利用率是非常高的。
2. 静态推拉流

静态推拉流主要是为了满足集群化的需求。如果单台服务器不足以支撑服务的高并发量,那么我们就需要考虑服务器的扩展性。除此之外如果用户分散在全国各地,还需要进行服务器之间的打通。但是如果业务没有那么复杂就可以选择使用静态推拉流。

静态推拉流服务配置如上图所示,首先看静态拉流:首先存在一个目标源站,如果使用静态回源,那么目标地址会被配置在配置文件当中,目标源站能随意更改。
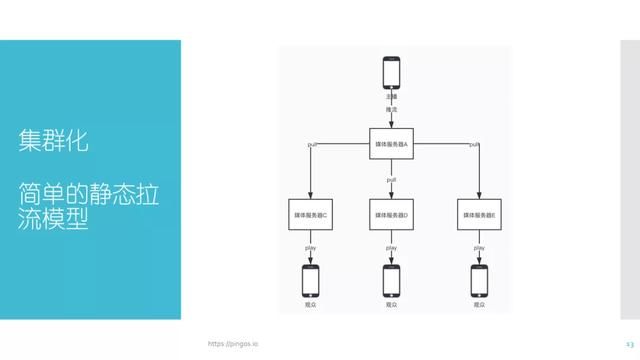
图中展示的是一个简单的静态拉流模型:如果来自主播的数据被推流到源站A,那么我们需要保证服务器A的地址不会改变。

除此之外,如果想要构建一套完善的流媒体系统,则需要包含静态拉流与静态推流。假如有观众向服务器C请求播放,那么服务器C就会向服务器A拉流,无论服务器A是否存在视频流,服务器C都会拉取。因此该模型只适用于较为简单的业务场景。
3. 动态控制:动态回源、动态转推、鉴权
相对于静态推拉流的“无脑”推拉流,更适用于多数人需求的则是动态推拉流。

Nginx的RTMP服务针对每一项功能都做了不同的触发阶段。以oclp_play为例,当有人启动播放时会触发play消息,play消息会携带一项start参数。在播放过程中,play消息依旧会被触发,只不过此时还会携带update参数。在play结束时也会触发一个play消息,所携带的参数是down。借助这些参数,我们可以实现向业务服务器通知请求播放以及播放的具体阶段。

3.1 动态回源
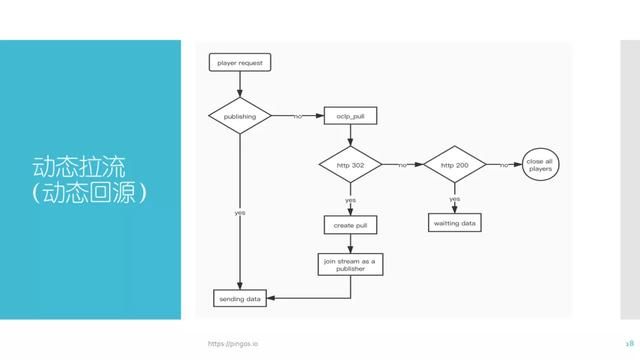
推流过程也存在类似操作,推流中存在publish,同样分为三个阶段,play和publish主要应用在鉴权操作中。如果在start阶段,业务服务器返回了一个404或者非200的结果,服务器就会中断当前的play请求,publish亦是如此。除此之外, pull与push主要应用于动态拉流阶段。当服务器接收到play请求,并且发现当前服务器里面没有目标流,也就是说publish的流不存在,就会触发pull的start阶段。在发送start请求之后如果业务服务器返回结果为302,并且在location中又写了一个新的rtmp地址或http-flv地址,这台服务器就会向标记的那一台目标服务器拉取rtmp流或fIv流,这个过程就被称为动态拉流。
3.2 动态转推
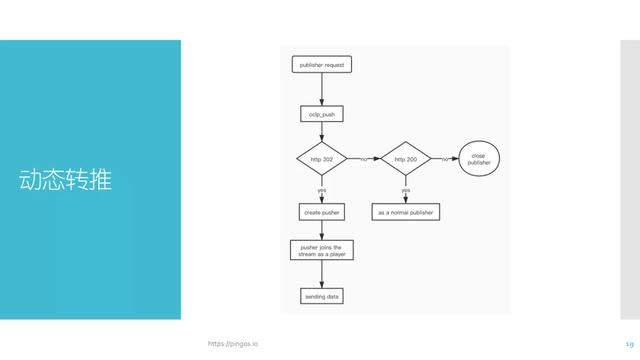
与动态拉流相对应的是动态推流,其理解方式与动态拉流大致相同。如果你向服务器推流,服务器会向配置好的目标地址发送start请求。如果在返回结果当中加入一个新的rtmp地址,这一台媒体服务器就会向新的rtmp地址推流,这也就是动态推流的操作。
这一切的前提是返回302的结果,如果不想将流推出,那么反馈给服务器400或其他非200,该流就会被中断。Oclp_stream用的比较少,仅仅在这路流创建与消失时被触发。不管是play还是publish,如果只有play或publish存在,都会认为这路流的生命周期还没有结束,只有当二者全部消失时才会被认定该路流生命周期已结束。同样的,如果一路流没有被发布过而是仅仅第一次有人请求,此时也会触发start并认为是该路流被创建,只不过没有生产者而已。这种场景的应用比较少,只有对业务要求比较高的系统可能会用到这一条消息。
上图展示了一个配置事例,主要包括查询服务器的IP、查询服务器play操作希望支持哪些阶段等。

集群化部署依赖业务(调度)服务器,如果有回源需求则让边缘服务器B在oclp_hold阶段向业务服务器查询,此时业务服务器会告诉边缘服务器B一个302地址,其中包含源地址。边缘服务器B就会从标记出来的这一台(媒体服务器A)拉流,从而实现动态回源。

动态转推主要是为了把本地的流推出去。在CDN的服务中,不同集群负责不同的职能。例如有些集群负责录制,有些则仅负责转码,此时我们希望核心机器能够把这些需要转码或需要录制的流按照需求转接到相应集群。动态转推非常重要,如果业务中包含这些不同的类型,就需要添加配置oclp_push去实现动态转推。
3.3 鉴权

鉴权操作中,我们只会对publish或play进行鉴权。
如果play的时候反馈200就是允许播放,如果反馈403就是不允许播放,publish也是如此,通过业务服务器控制客户某一次服务请求是否能被允许。
前端进行play或者是进行publish时,如何把鉴权的token带过来?

主要通过变量:args=k=v&pargs=$pargs
在向外发送play查询时,如果加入args=k=v&pargs=$pargs ,发请求时会带上这些参数,这样就可以将rtmp的全部自定义参数传递过来。
4. 多进程:进程间回源

多进程问题在原生的nginx rtmp中有很多bug,现在的做法是通过共享内存记录下每个进程上的stream列表。如果play的进程没有流,则查询stream列表,并通过unix socket向目标进程回源拉流。除此之外,进程间的回源不会触发ocl_playoclp_publish oclp_pull消息。
5. 更多操作说明
PingOS:https://github.com/im-pingo/pingos