如何利用深度学习实现单通道语音分离?
一直以来,语音分离在音视频领域都是一个重要的课题,近年来深度学习的快速发展为解决单通道语音分离提供了一个新的思路。在LiveVideoStackCon 2019上海 音视频技术大会上,大象声科高级音频算法工程师闫永杰以降噪场景为例,详细介绍了深度学习在单通道语音分离中的应用。
文 / 闫永杰
整理 / LiveVideoStack
大家好,我是来自大象声科的闫永杰,接下来我会从以下六个方面为大家介绍深度学习在单通道语音分离中的应用:
1、 单通道语音分离问题的引入
2、 借助深度学习来解决单通道语音分离
3、 工程实践中的挑战及解决方案
4、 思考
5、 总结
一、单通道语音分离问题的引入
在第一部分,我会简单介绍单通道语音分离问题的引入。首先,存在一个问题就是到底什么是单通道语音分离呢?对于做与语音相关工作的工作者来说,单通道语音分离是大家比较熟悉的一个问题,那么我就先从音频采集的方式开始来为大家介绍。
1)音频采集的方式
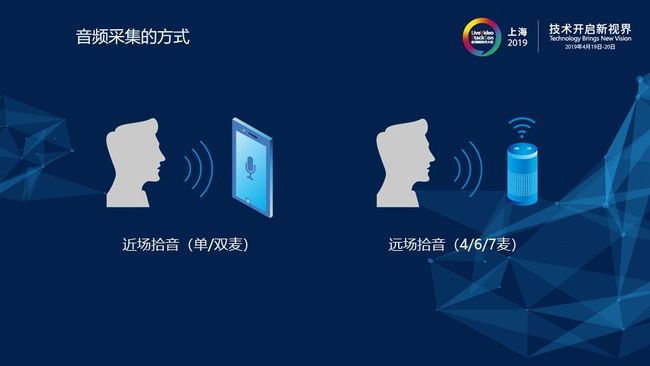
目前主流的音频采集方式主要包括两种场景:近场拾音和远场拾音。对于近场拾音,在我们生活中是很常见的,例如我们在使用手机打电话时手持或者开启免提。对于远场拾音,我们同样也不会陌生,像现在非常火的 麦克风阵列技术就是采用的远程拾音,例如小爱同学、天猫精灵等,它们都可以做到在相隔三到五米的情况下实现远距离拾音。那么,就近场拾音和远场拾音的区别所在,首先是使用场景的不同,再就是麦克风数量的不同。远场拾音采用的麦克风数量通常为多个,有两麦、四麦、六麦、七麦,甚至还包括更加非常复杂的情况。而对于近场拾音,以手机通话来举例,通常情况下使用的是单麦或者双麦。当我们手持手机时,如果仔细观察手机可以发现手机实际上是有两个麦克风的,其中位于底部的是主麦,位于顶部的是副麦,在业界副麦也常会被叫做降噪麦克风。本次为大家介绍的单通道语音,主要讨论的是单麦克风近场拾音的场景。
2)语音分离
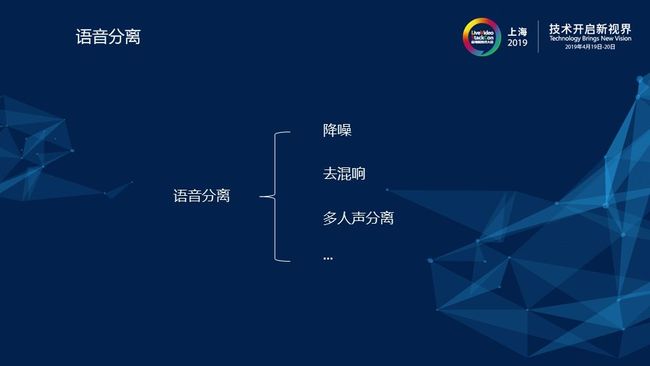
首先,我们需要来界定一下,到底什么是语音分离?实际上,我们经常所讲的降噪、去混响、多人声分离等等的过程都属于语音分离的过程。其中,降噪指的就是语音与噪音的分离,去混响指的就是语音与混响的分离,而多人声分离的场景则相对复杂一些,在这里包含有目标人声和其它的干扰人声。其实对于以上几种语音分离的场景,它们的最终目标是相同的,即将目标人声与其它非目标人声的语音进行分离。下面就以降噪为例,为大家介绍语音分离的过程。
3)降噪

在我们的现实生活中,噪音的种类是形形色色的。如上图所示,例如在车水马龙的街道、吵闹的酒吧和KTV、人来人往的车站以及各种加工工厂,这些场景都是典型的充满嘈杂的噪音的地方。形形色色的噪音对通话质量来说是一个非常大的挑战,特别是当下所流行的视频通话,视频通话双方所处的环境各有可能,那么在嘈杂的环境中对于视频通话的良好体验就会产生巨大的挑战。因此,在语音通话中实现更好的降噪已经成为了一个必不可少的课题。
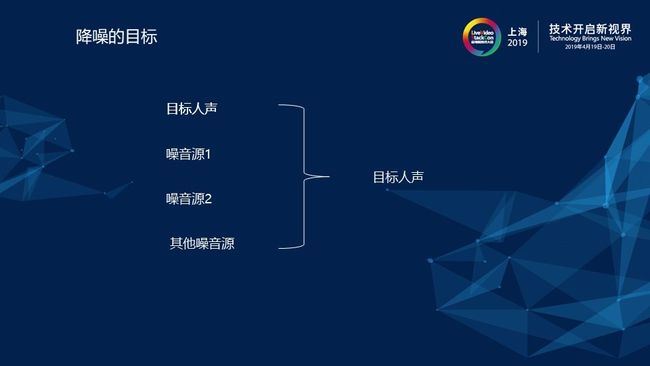
那么,降噪的最终目标是什么呢?直白的说就是将目标人声从多种噪音源中分离出来。如上图所示,在通话的过程中,实际输入的语音是包含目标人声、噪音源1、噪音源2以及其他噪音源的,其中噪音源的数量是一般都是多种,而降噪的目标就是将目标人声从中提取出来。

现在已经有了降噪的目标,那么该如何实现这个目标,解决目标人声和噪音源分离的问题呢?
二、借助深度学习来解决单通道语音分离
在第二部分,我将为大家详细介绍解决单通道语音分离的方法,首先是传统的单通道语音增强方法。
1)传统的单通道语音增强

要想实现单通道语音分离可能存在以下难点:单通道语音一般只包含一个麦克风,这很大程度上也限制了算法的能力。如果存在有多个麦克风的话,通过一些空间信息将与主讲人方向不同的噪音去除掉即可达到语音分离的目的。而单通道语音只有一个麦克风,因此就只存在一路信号,没有方位信息,这也就为实现语音分离带来了挑战。传统的语音增强算法包括有谱减法、维纳滤波、卡尔曼滤波以及其他算法。对于谱减法,其前提是先假设噪音是稳定的,稳态噪音在我们生活中也是很常见的,例如冰箱发出的声音或者是航空发动机发出的规律性噪音。谱减法先假设噪音是稳定的,然后估计噪音,估计噪音的方法是将人不说话的时间段的噪音取平均值,估出噪音以后,当人说话的时候减去对应噪音就可以认为剩余的为纯净的语音。但是这种方法存在很明显的弊端,它的前提是假设噪音都是稳态的,而实际上在日常生活中,瞬态的噪音也是非常多的,例如敲击声、咳嗽声、其他人播放音乐的声音、汽笛声等等。对于这些非稳态的噪音,谱减法基本上是无能为力的。此外,还有一点缺陷就是谱减法假设的稳态噪音实际上取的是平均值,这就有可能导致在做减法时出现负值。而当出现负值时,谱减法只是将负数直接用0替代了,这种做法实际上会在降噪的过程中额外带来新的噪音。
最后,总结一下传统语音增强算法的特点:1)传统方法是基于对信号的理解,采用人工编制的一些规则;2)由于规则是人工编制的,这就导致存在规则很难编制详尽的问题;3)存在很多需要估计的算法,通过对噪音调参得到适配的参数的调参过程十分考验人对于信号的理解以及自身经验的丰富程度;4)最后一个也是最重要的问题就是瞬态噪音,瞬态噪音不符合算法假设,传统方法对它的处理结果基本上都是不尽如人意的。
下面将为大家介绍我们解决单通道语音分离的方法。
2)计算听觉场景分析

对于这一部分,首先为大家分享一个概念——计算听觉场景分析,这套理论的主要贡献者之一是我们的首席科学家汪德亮教授,他于2001年提出理想二值掩膜(Ideal Binary Mask,IBM),并将预测IBM作为计算听觉场景分析解决语音分离问题的计算目标。上图是IBM的相关计算公式,为了方便讲解,我们先抛开公式,看下面的四张语音的图。
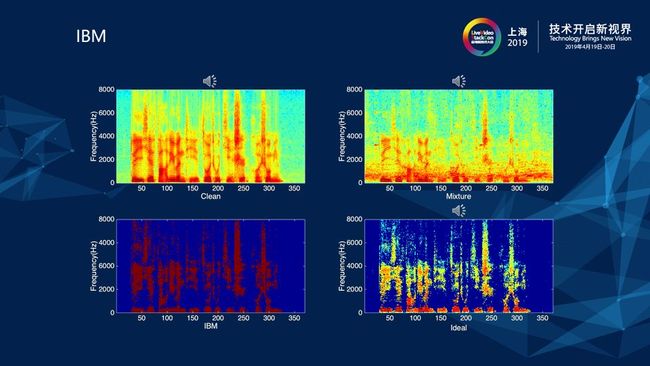
如图所示,可以看出与图像信号不同的是语音信号是一维的信号,而图像信号是二维的信号。对于语音信号利用一维的信息直接处理的难度是非常大的,因此我们将原始语音信号经过时频变换,如:短时傅里叶变换(STFT),就会得到左上的这张图——原始信号的幅度谱。幅度谱的颜色越深代表着能量越大,其中左上图中的红色部分就是语音的部分,看起来有一道一道的梳状条纹,是语音的谐波结构,这就是语音的元音成分。左上图是纯净语音对应的幅度谱,而右上图则是对应带噪语音的幅度谱,看起来有一些杂乱,语音成分被破话。右下图就是我刚才提到的IBM,IBM的含义是理想二值掩膜。右下图对应的是将IBM(左下图)覆盖到带噪语音谱(右上图),形成了降噪后的语音谱。而从图中可以看出,降噪后的语音谱(右下图)比噪声语音谱干净(右上图)了许多,但与纯净语音谱相比,存在部分过压的现象,听起来实际效果就是噪音基本消除,但是会有些许失真。

接下来,我们再来看IBM的计算公式,公式里面的IBM其实就是深度学习最终预测的目标,IBM计算所得的值为0和1,即可认为把最终结果分类成0和1,那么如何去界定0和1呢?界定条件如下:如果语音的能量s减去噪音的能量n大于一个θ值,θ一般取值为0,此时IBM的值为1,即我们认为语音比噪音大的地方,IBM是1;同样地,我们认为语音比噪音小的地方,IBM是0,即认为是噪音。这解释了为何将在之前图中第二层从左到右的第一张图谱覆盖到第一层从左到右的第二张图谱上所得的信号与纯净语音是有差距的。而这样做的好处就是成功将一个回归问题改变为分类问题,只需要预测它是0或者1就可以了,这就使得学习难度变小,更容易预测。但不好的地方就是听上去语音会有些许失真。但在2013年,当时这个方法所取得的效果已经算是非常好的。在此之后,陆续又有人提出了其他的一些计算目标,如TBM、IRM等,而这些目标其实都与IBM是相似的,只是进行了一些修正改进,例如IRM的值不仅仅只是0和1了,当我们认为它有一半的部分是语音,那么我们的目标值就是0.5。当前我们所采用的计算目标大多数是IRM。
3)深度学习

首先,大家可能也曾思考过深度学习方法到底是什么或者深度学习方法到底要做什么事情。简单来讲,深度学习方法的本质就是通过构建模型,来拟合一个函数映射,即我们提供一个输入并告诉应该输出什么,然后通过输入大量数据,不断学习数据之间的潜在对应关系,找到一个模型去模拟这个函数映射关系。构建模型有很多方法,例如高斯混合模型、支持向量机、多层感知机以及深度神经网络(DNN),它们的目的就是去找到一个模型能够通过输入来预测出一个目标值。在上面的函数中,刚才讲到的IBM就是对应里面的y,也就是说我们要预测的目标就是IBM,而我们输入就是前面所讲的右上图——带噪语音的幅度谱。这是因为我们在部署的时候,实际上只能拿到这个信息。输入是带噪语音的幅度谱,目标是IBM,那么这样函数映射就建立好了。接下来就是网络的构建了,网络的构建可以用简单一些的,例如全连接,卷积或者是后面发展比较好的RNN、LSTM一类的结构去构建模型。

下面,总结一下深度学习方法实现语音分离:1)首先要确定目标——IBM,当然我们在这里是以IBM为例来讲的,如果你采用IRM;2)特征输入—— 短时傅里叶变换后的幅度谱;3)训练工具现在都已经十分成熟了,Tensorflow、Pytorch都很好用;4)数据驱动,最后就是需要不断喂数据,这个喂的数据就是语音。在这里,需要讲一下的就是大部分环境中的噪音都是加性噪声,因此我们可以仿真得到混合后的声音,只需将裁好的噪音与语音加在一起即可。这样一来,我们有了训练的目标,纯净语音、噪声都是已知的,只需要把这些数据喂给网络,让它不断的调整参数,就会得到一个比较不错的效果。
下面将为大家介绍在工程实践中部署时的挑战和解决方案。
三、工程实践中的挑战及解决方案
在这一部分,我将为大家介绍工程实践中遇到的问题以及我们提出的解决方案。
1)工程实践中的挑战

前面所讲的原理其实都是非常简单的,但仅仅只是学术的,而深度学习讲究的是落地,而在落地的时候,深度学习所面临的最大挑战就是部署。对于ASR或者NLP来说都是可以部署在云端上的,因此可以对模型有一些容忍度,可发挥的空间也更大一点。但是,对于实现降噪效果的,如果运行在服务器上,它的延时、实时性都是不切实际地,所以部署的终端大多数是移动设备,例如手机、iPad,甚至是在耳机中非常弱的M4芯片上。因此,对于这些设备来说,1)功耗必须得控制好,那么计算量就不能太大;2)由于这些芯片的内存非常小,例如M4可能只有几百K的空间,因此模型参数不能太大,否则无法部署。此外,给大家讲一下我们公司最初是如何演示最终效果的,别人提供给我们一个带噪的语音,我们在服务器上跑一下再发给人家,这样一来的体验效果是很差的,后来感觉太复杂了就写了一个MATLAB的,但效果也不是实时的,这是我们当时遇到的最大的挑战。
为了解决这些问题,我们做了一些相关的优化。
2)模型优化
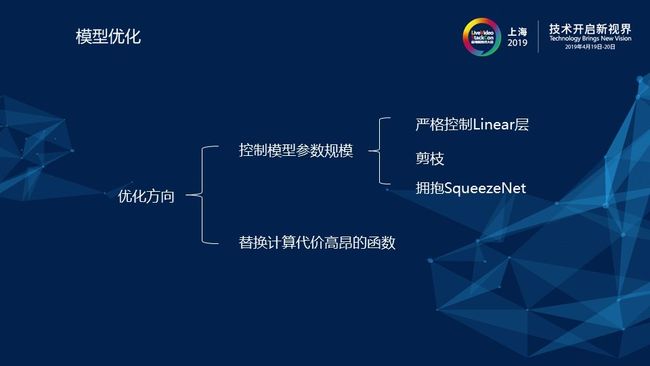
针对上述问题,我们对模型进行了优化,优化的方向包括控制模型参数规模和替换计算代价高昂的激活函数。首先,模型参数规模一定要降下来,模型参数最先影响的是带宽。如果模型参数大于所要部署的嵌入式设备的内存,则不可能实现部署,这是一个裁模性的考量。其次,要减少计算量,参数减少以后,乘加指令自然会减少。控制模型的大小是一个非常重要的方向,例如全连接层的经典模型,我们输入1024个节点,则输出1024个节点,仅仅一层网络就已经占用了4M的空间,然而设备却只有几百K的内存。因此,对于全连接层的使用一定要慎重,尽量选用其他结构如RNN或CNN来替代,尤其是CNN的参数共享可以带来非常大的提升。
我们在设计网络的时候,一定要考量DNN的输入与输出的大小规模,这是一个非常重要的点,尽量使用CNN或者RNN的结构去替代DNN。然后,还有最重要的一点就是选取一个好的Feature,刚才前面讲的我们用的Feature选择的是Mix语音、经过STFT后的幅度图,这虽然是最直观、最简单的,但是学起来难度较大。我们也在这方面做了很多的尝试和工作,例如将输入Feature从幅度谱改为mel谱就可以将输入规模大大减小。就像我在前面所讲的深度学习要学的是个函数映射,可能大家会有疑问,为什么在输入特征时不直接把时域的信号送进去,然后目标就是纯净语音的信号?其实如果这么做能成功的话,那肯定是最好的,但是如果你告诉网络的是一个完整、没有丢失的信息,这在它学习规律的过程中,对于深度学习来说,学习难度太大,参数量是降不下来的。因此,我们折中选取了频域的信号,选取频域信号以后,学习难度就会下降很多,不仅可以比较容易的能学到它的模式,而且参数量也会大大下降。所以,在裁模型的时候,一定要注意选取一个好的Feature。
最后一点也是来自工程实践中的一个问题,例如当我们训练好模型交给同事部署时,同事会反馈说,你用的ELU函数,一个EXP指令直接占用了600个cycle。后来我们发现问题,工程师在训练模型的时候,一定要与最终部署的同事沟通好,要了解到哪些函数对他们来说是很有挑战的。例如将ELU换成一个简单一些的RELU,部署所需指令可能就只有一个两个cycle,而如果用ELU,在性能上对实验结果来说差距是不大的,但是在部署时差距就会放大几百倍,所以一些代价高的函数一定要慎重使用。
3)算法优化
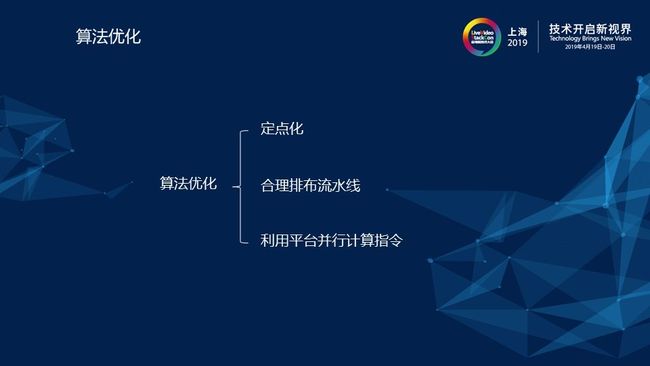
在做好模型优化后,一个比较小且合理的模型给到工程团队,工程团队在落地的时候还要做一些算法优化。1)定点化。大家都知道,如果做图像的话,一般会用int8去量化,这样带来的好处就是学习时用的float32,部署时用int8可以节省4倍的内存,这是一个很好的优化。但是,对于语音还不能用int8,我们尝试过,使用int8最终会导致精度太差,部署的模型预测出来的值与float32的值差距太大。这主要是因为对于语音,我们一般采样的是16bit,在后面量化时会使用Int16去替代float32,会带来1倍的内存带宽的下降。2)合理排布流水线,注意不要因为频繁地数据访存缺页,导致打断了流水线使cycle数急剧增加,一定要在汇编层流程上排布好流水线。3)利用平台并行计算指令。大多数平台都是有这个并行指令计算的,例如ARM上的NEON或者是SIMD,在可用的情况下一定要用起来,一般会有2到4倍的加速。经过这些优化以后,基本上就可以得到一个部署在手机上的模型。
四、思考

在这一部分,我想带着大家一起思考,为什么深度学习会有这么好的效果呢?因为深度学习具有以下优势:
1)数据驱动,一定条件下,数据越多性能越好。我们只需要采集足够多的噪音、足够多的语音,源源不断地喂给网络 ,就能够从中学习到语音的模式,所得的模型更加精确。为什么在这里要说一定条件下呢?一方面如果是同类噪音,采集的再多也没什么用,这就要求我们要保证数据的丰富性。另一方面,大家可能有一个疑虑,既然说是数据驱动的,如果某种噪音并未采集过或见过,那该怎么办呢?此时就要考量算法的泛化能力。深度学习中有一个概念就是过拟合,如果见过的数据都能拟合的非常好,而没见过的数据就会突然表现非常差,说明模型过拟合了,这是不可接受的。所以,在做音频降噪的时候,一定要考虑模型的泛化能力,同等条件下,如果模型越小,学习过程中最后的loss值跟大模型基本一致,那就说明模型泛化能力强。也就是说参数越少,泛化能力一定程度上越好,所以前面所讲的我们做的裁减模型的工作对泛化能力也是有很大的提高的。这样一来,在部署的时候,对于没见过噪声,预测的结果也不会太差。
2)相比传统算法手工统计的模式,深度学习可以学到更加鲁棒的模式。对于传统算法的调参是十分麻烦的,例如我们看过的有一些竞品算法公司调参,参数大概有几百个,在对接厂商的时候需要将参数逐一调整,以实现不错的效果,这中间的工作量非常大。但是,这几百个参数跟深度学习相比就太少了,深度学习的参数量基本上是百万规模的,甚至是千万规模的。因此,手工统计的那些参数所包含的信息,它所拟合的模型的建模能力跟深度学习是不可比拟的,因此深度学习相比于传统算法,它学到的模式更加鲁棒。3)深度学习有记忆的能力。对于深度学习来说,一定程度上,见过的数据越丰富,效果越好。

在这里,说一个我们的首席科学家汪老师给我们讲的故事,他在俄亥俄州作教授,有一个老同事得了海默森综合症,记忆力会减退。有一天,这个老同事回到学校去看望汪老师,他知道汪老师是做人工智能研究,根据自己的亲身感受,当时就说了一句话,No Intelligence Without Memory!这句话的意思是没有记忆就没有智能。所以说,记忆对于智能来说非常重要,深度学习有非常多的参数,它会通过记忆非常多的模式来记住语音的分布以及噪音是长什么样子的。当然,对于降噪来说,更多记忆的是语音的一种模式,因为噪音实在是太复杂了,记录噪音的难度太大了。
五、总结

最后,就是本次的总结部分了。本次演讲内容首先是介绍了单通道语音分离的定义,其中语音分离方法我们介绍了三种,主要是以降噪为例去讲的,因为降噪是比较关键的,再就是介绍了在单通道语音分离里面遇到的一些挑战,以及我们是如何去解决所遇到的困难的。
LiveVideoStack 招募
LiveVideoStack正在招募编辑/记者/运营,与全球顶尖多媒体及技术专家和LiveVideoStack年轻的伙伴一起,推动多媒体技术生态发展。了解岗位信息请在BOSS直聘上搜索“LiveVideoStack”,或通过微信“Tony_Bao_”与主编包研交流。

点击【阅读原文】或扫描图中二维码,即刻了解更多大会讲师及分享内容信息!