Deep Learning based Recommender System: A Survey and New Perspectives (1)
感想
1 介绍
互联网信息的爆炸性增长使用户迷失,推荐系统(Recommender system,RS)是一个有用的信息过滤工具,以个性化的方式来发现产品和服务,为用户提供向导,这些服务和产品是在一个很大的可供选择空间中可能感兴趣的。在各种信息访问系统中,推荐系统扮演者一个至关重要且本质的角色,用以促进商业联系(boost business)和辅助决策过程(facilitatedecision-making process)。
通常,推荐列表是基于用户偏好产生的,物品特征(item features),用户-物品过去的交互,和一些其他额外的信息,例如时序和空间数据(temporal and spatial data)。推荐模型主要分为协同过滤,基于内容的推荐系统,基于不同输入数据类型的混合推荐系统。可是,这些模型在处理数据稀疏性和冷启动问题上,以及在不同的评价尺度(evaluation metrics)上权衡推荐质量上,有着自身的局限性。
过去几年见证了深度学习的在许多领域的巨大成功,例如计算机视觉和语音识别。因其在处理复杂任务上能得到最好效果的能力,学术界和工业界都争相把深度学习广泛应用到应用中。最近,深度学习正在变革推荐结构,在重塑用户体验(in reinventing the user experiences)得到更高的客户满意度(customer satisfaction)方面带来了更多的机会。最近基于深度学习的推荐系统的研究得到了很多关注,深度学习主要用来克服传统模型的缺点且得到高推荐的质量。深度学习可以有效的捕获非线性和非平凡的用户-物品(non-linear and non-trivial user-item)关系,使得更复杂的编码作为更高层的数据表示。另外,它抓住了数据本身的复杂联系,例如上下文,文本和视觉信息等丰富的容易获得的数据源。
1.1 为什么我们要关心基于深度学习的推荐系统?
推荐系统在工业领域的重要组成部分,它是许多网站和手机应用促进销售和服务的关键所在。例如,Netflix上80%的电影观看来自于推荐,YouTube上60%的视频点击来自于主页的推荐。最近,许多公司利用深度学习来进一步提升他们的推荐质量。Covington等人提出了一个基于深度神经网络的推荐算法,这个算法用于YouTube上的视频推荐。Cheng等人用wide & deep模型提出了一个Google Play的App推荐系统。所有这些模型都经受住了上线测试,取得了比传统模型更好的效果。因此,我们可以看出深度学习已经在工业推荐应用中驱动着巨大的变革。
另一个显著的变化是在研究领域上,最近几年,关于基于深度学习推荐方法的研究发表的数量成指数性的增长,在推荐系统顶级的国际会议,RecSys, 从2016年开始组织定期的深度学习推荐系统的研讨会。
基于深度学习的推荐在学术界和工业界的成功需要一个完整的回顾和总结,以便于后来的研究者和参与者能更好的理解其优势和弱势以及这些模型的应用场景。
1.2 本次的综述和前面的综述有什么不一样?
····在基于深度学习的推荐领域已经有了大量的研究,可是,据我们所知,很少有系统的回顾能很好地塑造这个领域,定位现有的工作和当前的进展。即使有些工作已经吊样了建立在深度学习技术上的推荐应用,也已经尝试正式化这个研究领域,但是很少有工作能够对当前的研究提供一个深度总结,使得在这个领域的公开问题详细化。这个调查旨在提供这样一个对现在基于深度学习的推荐系统研究的总结,识别当前限制真实世界实现的公开问题,指出这个维度的未来的方向。
在过去的几年里,有很多在传统推荐系统的调查,例如,Su等人对协同过滤技术做了一个系统的回顾,Fernandez-Tobias等人和Khan等人回顾了交叉域推荐模型;举几个例子来说,缺乏基于深度学习的推荐系统的回顾的拓展,据我们了解,只有两个相关的短调查被正式发表。Betru等人介绍了3个基于深度学习的推荐模型,即使这三个工作在这个研究领域有影响力,这个调查丢失了其它出现的高质量工作。Liu等人回顾了深度学习推荐的12篇文章,然后根据输入*(使用内容信息和不使用内容信息的方法)和输出(打分和排序)的不同来划分这些模型。可是,随着新的工作的不断出现,这些分类框架不再合适,需要一个新的框架来更好的理解这个研究领域。考虑到深度学习应用在推荐系统中的正在上涨的流行度和潜力,在这方面系统的调查将会有很高的科学和使用价值。我们从不同的角度分析现在的工作,提出了对这个领域的一些新的见解。为此,在这次调查中,超过100个研究被列举和分类。
1.3 本次调查的贡献
1. 在深度学习技术的推荐模型方面,我们进行了系统的回顾。提出了一个新的方法用来定位和组织现在的工作;
2. 我们概述了最新的研究成果,并总结了它们的优点和局限性。专业人员可以很容易的找到模型对应的问题或者找到未解决的问题。
3. 我们讨论了挑战和公开的问题,认出在这个领域的新的趋势和未来的发展方向,分享基于深度学习的推荐系统的远景以及拓展其视野。
2 术语和背景概念
推荐模型通常分为三类:协同过滤,基于内容和混合推荐系统。协同过滤是学习用户物品的交互历史来做推荐的,要么是显式的反馈,如用户先前的评分,要么是隐式的反馈,如浏览历史。基于内容的推荐主要是基于用户和物品的辅助信息的比较。各种各样的辅助信息,例如文本,图片和视频可以考虑在内。推荐系统的混合模型是集成两种或者更多类型的推荐策略。
假设我们有M个用户,N个物品,R代表评分矩阵。同时,我们使用一个部分观察的向量r^((u))={r^u1,…,r^uN}来代表每个用户u,部分观察向量r^((i))={r^1i,…,r^Mi}来代表每个物品i.
2.2 深度学习技术
多层感知机(MLP):是一个前馈神经网络,在输入和输出层之间有多个隐藏层。这里,感知机可以随意的利用激活函数,不局限与严格表示二分类。
Autoencoder(AE):是一个无监督模型,它试图在输出层重构输入数据。通常,bottleneck层(最中间的一层)用于输入数据的突出的特征表达。Autoencoders有很多的变体,例如denoising autoencoder,marginalized denoising autoencoder,sparse autoencoder,contractive autoencoder和variational autoencoder(VAE)。
卷积神经网络(CNN):是一个特别种类的前馈神经网络,有卷积核池化操作,他可以有效的捕捉全局和局部特征,以增强效率和精度。它在处理网格状拓扑结构(grid-like topology)的数据上表现良好。
循环神经网络(RNN):对序列化数据建模比较合适,不像前馈神经网络,RNN有循环和记忆,能够记住前面的计算,其变体经常被用于克服梯度消失问题,如LSTM,GRU。
深度语义相似度模型(Deep Semantic Similarity Model,DSSM):特别是Deep Structured Semantic Model,是一个深度神经网络,用于在连续的语义空间中学习条目的语义表示(semantic representations of entities),衡量他们的语义相似度。
受限的玻尔兹曼机(RBM):是一个两层的神经网络,由一个可见层和一个隐藏层组成。它可以很容易的被堆叠成深度网络,受限这里的意思是隐藏层和可见层的内部是没有交流的。
神经自回归分布(Neural Autoregressive Distribution Estimation, NADE)是一个无监督神经网络,建立在自回归模型和前馈神经网络之上。它是一个易处理的且高效的估计器(tractable and efficient estimator),用来对数据分布和密度进行建模。
生成对抗网络(GAN, Generative Adversarial Network):是一个生成式神经网络,由一个判别器和一个生成器组成。这两个网络可以同时训练,在一个最大最小游戏框架(minimax game framework)下相互竞争进行训练。
3 分类方案和分析
3.1 二维分类方案
3.1.1 神经网络模型
使用单个深度学习技术的模型
深度复合模型(Deep Composite Model)
3.1.2 整合模型(Integration Model)
将深度学习与传统推荐模型相结合
一些研究尝试将深度学习方法和传统的推荐技术以一种方式或者另一种方式相结合,传统的技术有矩阵分解,概率矩阵分解,分解机(factorization machine, FM),或者最近邻算法等等。基于两种方法整合的紧密度,这些模型进一步分为松耦合模型(Loosely Coupled Model)和紧耦合模型(Tightly CoupledModel)。例如,当把autoencoder学习到的特征表示作为隐语义模型(latent factor model)的特征,如果autoencoder的参数和隐语义模型(latent factor model)的参数是同时优化的,这个模型就是紧耦合的。这样,隐语义模型和特征学习过程就相互影响。如果参数的学习是分开的,这个模型就是松耦合的。
推荐只靠深度学习
在这种情况下,推荐系统的训练和预测步骤仅依赖于深度学习技术,没有其它形式的传统推荐模型的帮助。
注意,对于新出现的模型,例如基于GAN的推荐,目前的研究工作很少,这可以作为一个研究课题来研究。
3.2 定性分析
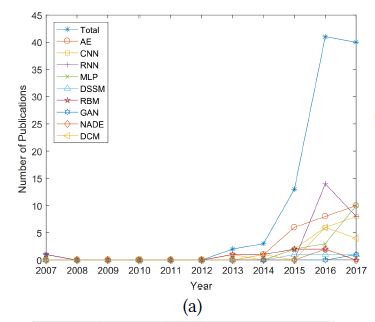
上图是从2007年开始,每年发表的量。在过去5年的时间里呈现爆炸性的增长。基于AE, RNN, CNN和MLP的推荐系统研究已经很广泛了,紧接着的是深度复合模型(deep compositemodels),基于RBM和DSSM的模型。最近的研究尝试把GAN和NADE用于推荐任务上。
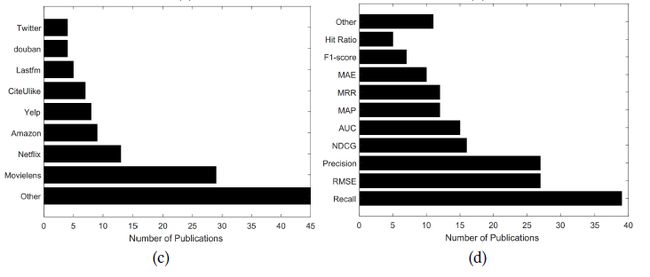
上图显示的是前面工作所用的数据集和评估尺度。两个电影推荐数据集:Movielens,Netflix是最常用的数据集。其它数据集,例如Amazon,Yelp和 CiteUlike也频繁的用到。至于评估尺度,均方根误差(Root Mean Square Error,RMSE)和均方平均误差(Mean Average Error,MAE)经常用于评分预测评估。而Recall, Precision,Normalized DiscountedCumulative Gain(NDCG)和AreaUnder the Curve(AUC)经常用于评估排序分数。Precision,Recall和F1-score被广泛用于分类结果评估。
另一个是在不同推荐任务上的研究工作的比例,排序预测是最流行的(66%),接着的是流行范式(the prevailing paradigm),打分预测为28%,只有6%的工作会把推荐任务转换为分类问题。
3.3 应用领域
4 基于深度学习的推荐系统
4.1 基于多层感知机的推荐系统
4.1.1 仅依赖于MLP的推荐
神经协同过滤(Neural Collaborative Filtering.)
在大多数情况,推荐是用户偏好和物品特征这两种方式的交互。例如,矩阵分解把评分矩阵分为一个低维的隐式用户空间和一个低维的隐式物品空间。基于内容的推荐系统产生了基于用户画像和物品特征的相似度的推荐列表。因此,很自然的我们就可以建立一个对偶网络,对用户和物品两种交互方式进行建模。神经协同过滤(Neural Collaborative Filtering, NCF)就是这样一个框架,它旨在捕获用户和物品的非线性关系。
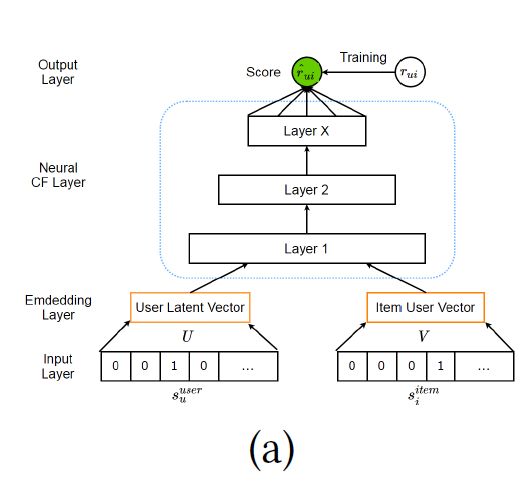
让s_u^user和s_i^item表示边信息(side information),例如用户画像和物品特征。或者就是用户u和物品i的one-hot标识。NCF的预测规则定义如下:
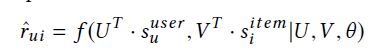
这里解释一下边信息:边信息(Side Information)是指利用已有的信息Y辅助对信息X进行编码,可以使得信息X的编码长度更短。边信息一个通俗的例子是:假设到马场去赌马,根据每个马的赔率可以得到一个最佳的投资方案。但是如果知道赌马的一些历史数据,例如上几场的胜负情况,那么可以得出一个更优的投资方案。赌马中的历史数据就是边信息。

这里解释一下Probit函数:在概率论和统计学中,probit函数是一个和标准的正态分布相关的分位函数,通常定义为N(0,1)。数学上,它是标准正态分布的累积分布函数的逆,它在exploratory statistical graphics和特定的二分变量回归模型有着广泛的应用。例如:
He等人把NCF模型拓展为交叉域的社交推荐,例如,推荐信息域的物品给社交网络的潜在用户,提出了一个神经社交协同等级推荐系统,另一个拓展是CCCFNet(Cross-domain Content-boosted Collaborative Filtering neural Network),CCCFNet的基本组件也是一个对偶的网络(分别对用户和物品),在最后一层用内积对用户-物品交互进行建模,为了嵌入内容信息,作者进一步把对偶的每个网络分解为两个成分:协同过滤因子(用户和物品潜在因素)和内容信息(物品特征的用户偏好和物品特征)。多视角神经框架建立在这个基本模型的基础上,用来进行交叉域推荐。
Wide & Deep Learning.
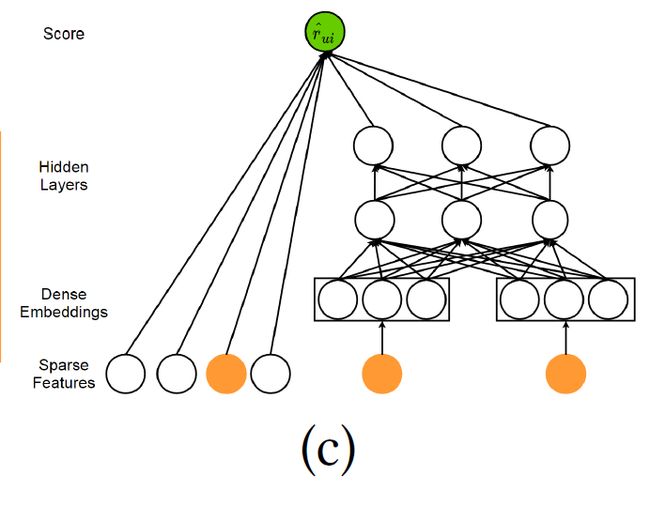
正式地,wide learning定义为:
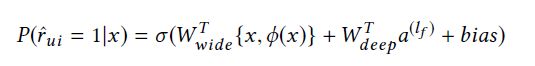
通过拓展这个模型,Chen等人设计了一个局部连接的wide & deep learning模型,用于大规模工业级别的推荐任务,它利用了高效的局部连接网络来替换深度学习组件,把运行时间减少到了一个数量级。
部署wide & deep learning的一个很重要的步骤就是选择宽度和深度部分的特征,换句话说,系统应该可以决定哪个特征该记忆或者被泛化。另外,交叉内积转换也需要手工设计,这些预步骤对模型的效果影响很大,为了缓解特征工程中的手工处理,Guo等人提出了深度因子分解机(Deep Factorization Machine, DeepFM)。
Deep Factorization Machine
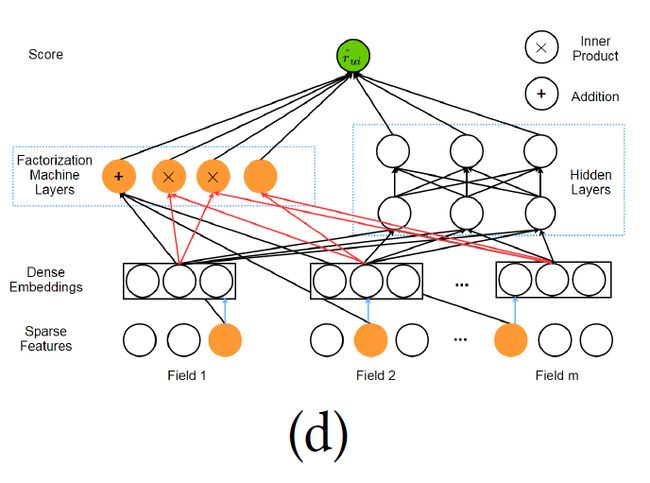
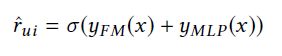
4.1.2 整合MLP和传统的推荐系统
注意力的协同过滤(Attentive Collaborative Filtering)
Alashkar等人提出了一个基于MLP的模型用于化妆品推荐。这个工作使用了两个相同的MLPs去分别对标记的样例和专家规则进行建模,这两个网络的参数同时更新,最小化他们的输出的差别。它证明了采用专业知识的功效,用它去指导推荐系统在MLP框架中的学习过程。但是,专业知识的获取需要大量的人力参与,代价很高。
Covington把MLP应用到YouTube推荐上。这个系统把推荐任务分为两个阶段:候选产生(candidate generation)和候选排序(candidate ranking)。候选产生网络从所有的视频语料库中检索一个子集(几千)。候选排序网络用基于最近邻分数的方法从候选项中产生top-n列表。我们注意到工业领域关注的是特征工程和推荐模型的可拓展性,特征工程例如例如转换,规范化,交叉。