卷积神经网络
一、备注
最近在研究DCGAN,需要卷积神经网络的相关知识,之前零零散散地看过一些卷积神经网络的相关博客,打算乘此机会好好做一个总结,也算是为后面的学习打下基础。
卷积神经网络主要用于图像方面的应用例如图像识别与分类等,比较著名的卷积神经网络有VGGnet, AlexNet,GoogleNet,Resnet等。
二、定义
卷积神经网络的历史就不多阐述了,它的灵感来源于对生物的视觉系统的研究,卷积神经网络是受生物学上感受野的机制而提出的,感受野(receptive field)主要是指听觉、视觉等神经系统中一些神经元的特性,即神经元只接受其所支配的刺激区域内的信号。一个神经元的感受野是指视网膜上的特定区域,只有区域内的刺激才会激活该神经元。
目前卷积神经网络一般由卷积层、汇聚层和全连接层交叉堆叠而成,利用反向传播算法进行训练。卷积神经网络有三个特性:局部连接、权重共享以及子采样,这些特性使得卷积神经网络具有一定程度上的平移、缩放和旋转不变性,这也符合人的视觉特点,和前馈神经网络相比,其参数更少。
三、相关操作
卷积
图像处理中比较常见的就是二维卷积。
给定一个图像 X ∈ R M ∗ N X\in R^{M*N} X∈RM∗N, 一个滤波器 W ∈ R m ∗ n W\in R^{m*n} W∈Rm∗n, m < < M m<<M m<<M, n < < N n<<N n<<N.
其卷积为 y i j = ∑ u = 1 m ∑ v = 1 n w u v ∗ x i − u + 1 , j − v + 1 y_{ij}=\sum_{u=1}^{m}\sum_{v=1}^{n}w_{uv}*x_{i-u+1,j-v+1} yij=∑u=1m∑v=1nwuv∗xi−u+1,j−v+1.
图像在经过卷积处理后的结果称为特征映射(feature map).
以下为示意图
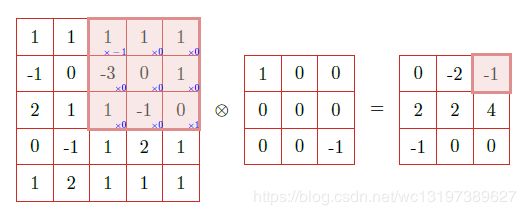
在输入层,如果是灰度图片,那么只有一个feature map;如果是彩色图片,一般就是3个feature map,层与层之间会有若干个卷积核(kernel),也称为过滤器,上一层的每个feature map与每个卷积核做卷积,会产生下一层的一个feature map, 有n个卷积核,就有n个feature map.
下层的核主要是一些简单的边缘检测器,上层的核主要是一些简单核的叠加。
卷积核
- 卷积核有长宽深三个维度,卷积核的长宽都是人为指定的,长*宽就是卷积核的尺寸;卷积核的深度与当前图像的深度相同,指定卷积核时,只需指定长和宽两个参数,在输入层,如果原始图像是灰度图像,则其feature的深度为1,卷积核的深度就是1;如果图像是rgb图像,则feature map的深度为3,卷积核的深度为3.
- 某个卷积层中可以有多个卷积核
- 随着网络的加深,feature map的长宽尺寸缩小,feature map的数量增加
池化
也称为下采样,主要用于特征降维,压缩数据和参数数量,减小过拟合,提高模型的容错性,常用的有最大池化和平均池化。这和人的视觉系统是符合的,比如,人的注意力有时会集中色彩比较鲜明的区域而忽视其他不那么重要的区域。
全连接层
在卷积神经网络最后会加一个flatten层,将之前所得到的feature map“压平”,然后用一个全连接层输出最后的结果,如果是分类的话,一般会利用softmax激活函数,最后就可以输出相应的分类结果了。
用keras搭建了一个简单的卷积神经网络,代码如下:
from keras import Sequential
from keras.layers import Dense
from keras.layers import BatchNormalization
from keras.layers.core import Activation
from keras import optimizers
from keras.datasets import mnist
from keras.utils import to_categorical
from matplotlib import pyplot as plt
from keras.layers import Conv2D
from keras.layers import MaxPooling2D
from keras.layers.core import Flatten
import keras.optimizers
BatchSize=128
num_class=10
epoch=20
input_shape=(28,28,1)
def DeepNeuralNetwork(inputDim:int,outputDim:int):
model=Sequential()
model.add(Dense(100,input_dim=inputDim))
model.add(Activation('relu'))
model.add(Dense(50,activation='relu'))
model.add(BatchNormalization())
model.add(Dense(outputDim,activation='softmax'))
#sgd=optimizers.sgd(lr=0.01,decay=0.0,momentum=0.0)
# 建议使用优化器默认的参数
model.compile(optimizer=optimizers.sgd(),loss='categorical_crossentropy',metrics=['accuracy'])
return model
def ConvNetModel():
model=Sequential()
model.add(Conv2D(5,kernel_size=(3,3),activation="relu",input_shape=input_shape))
model.add(MaxPooling2D(pool_size=(2,2),strides=(1,1)))
model.add(Conv2D(10,kernel_size=(3,3),activation="relu"))
model.add(MaxPooling2D(pool_size=(2,2),strides=(1,1)))
model.add(Flatten())
model.add(Dense(num_class,activation="softmax"))
model.compile(optimizer=optimizers.adam(),loss="categorical_crossentropy",metrics=['accuracy'])
return model
(x_train, y_train), (x_test, y_test) = mnist.load_data()
x_train=x_train.reshape(-1,28,28,1)
x_test=x_test.reshape(-1,28,28,1)
y_train=to_categorical(y_train,10)
y_test=to_categorical(y_test,10)
dnn_model=ConvNetModel()
history=dnn_model.fit(x=x_train,y=y_train,batch_size=BatchSize,epochs=epoch)
loss,accuracy=dnn_model.evaluate(x=x_test,y=y_test)
print("loss:{0} accuracy:{1}".format(str(loss),str(accuracy)))
'''
fig=plt.figure()
plt.plot(history.history['acc'])
plt.xlabel('epoch')
plt.ylabel('accuracy')
fig.savefig('train.jpg')
'''
# print(y_train.shape) (60000,)
# print(y_test.shape) (10000,1)
# print(x_train.shape) (60000,784)
# print(x_test.shape) (10000,784)
最后的效果还是很不错的,训练准确率可以达到0.99,测试准确率可以达到0.98.