小甲鱼python视频的笔记【斜杠派】
我就不设置导航了,要是直接看某一节的笔记,按ctrl+F,搜号码吧。
这个是斜杠达人的微信公众号:
斜杠达人→→→ ←←←斜杠达人
←←←斜杠达人
001 我和Python的第一次接触
使用的Python版本:3.3.2
IDLE是一个Python shell
print("I love fishc.com") #打印双引号里的字符串
print(5+3) #打印括号中四则运算的结果
print("well water"+"river") #把前后两个字符串连起来,中间不自动添加任何字符
print("I love fishc.com"+8) #报错,不相关的数据类型无法进行合并
002 用Python设计第一个游戏
Python是使用缩进来控制条件分支的作用域
temp = input("xxx") #向屏幕输出引号中的字符串,提示用户输入操作,将输入的东西存到temp里
guess = int(temp) #将temp转化为整形变量赋值给guess
if guess == 8 : #判断用户输入的值是否为8,这里有个冒号
print("xxx")
else: #注意这里也有个冒号
print("xxx")
print("xxx")Python提供了很多BIF(built in functions)
dir(__builtins__) #输出所有BIF
help(函数名) #返回函数功能说明
003 小插曲之变量和字符串
myteather = '小甲鱼'
yourteather = '老甲鱼'
print(myteather +yourteather ) #输出为两个字符串拼接到一起Python对大小写敏感,fish_c和fish_C是不一样的
在字符串里面打'或",需要使用转义字符,或使用原生字符串,即字符串前面添加r关键字标识
打印多行的长字符串,需要使用"""xxx""",要保证成对使用
004 小插曲之变量和字符串
> >= < <= == !=
六个比较操作符,返回的结果是True或False
if 条件:
条件为真(True)执行的操作
else:
条件为假(False)执行的操作while 条件:
条件为真(True)执行的操作and运算符的使用,功能是执行逻辑与运算
内建模块random,包含的格式是
import random #包含random模块
value = random.randint(1,10) #使用random内的函数randint()生成一个随机的int型常量005 闲聊之Python的数据类型
一些数值类型:整型、布尔类型、浮点型、科学技术法
类型转换:int( )、str( )、float( )
函数的参数要适当,不是任意转。
type( x )函数返回变量x的类型、isinstance( x,y )函数返回变量x是否为y类型
006 算术操作符
+ - * / % ** //
加、减、乘、除(精确除)、取余、幂次、除(取整除,舍弃小数部分)
and or not
逻辑与、逻辑或、取反
运算符优先级:
** #幂运算
+ - #一元=和一元-
* / // + - #算术运算符
< <= > >= == != #比较运算符
not and or #逻辑运算符007 了不起的分支和循环1
加载背景音乐
播放背景音乐(单曲循环)
我方飞机诞生
interval = 0
while True:
if 用户点击了关闭按钮:
结束
interval +=1
if interval == 50:
interval = 0
小飞机诞生
else:
小飞机移动一个位置
屏幕刷新
if 鼠标移动了位置:
我方飞机中心位置 = 鼠标位置
屏幕刷新
if 我方飞机与小飞机相撞:
我方飞机挂,播放撞机音乐
修改我方飞机图案
打印“Game Over”
停止背景音乐,淡出
跳出循环008 了不起的分支和循环2
遇到需要分类的条件判断使用if...elif结构
if 条件:
执行的代码
elif 条件:
执行的代码
else:
执行的代码Python通过缩进来匹配if和else,四个空格
三元操作符:
value = a if xassert关键字的使用格式是:
assert 表达式 #如果表达式返回True,则继续往下执行;
#若表达式返回False,则程序自动崩溃,抛出AssertionError的异常009 了不起的分支和循环3
while 条件:
循环体
for 目标 in 表达式:
循环体fav = 'fishC'
for i in fav:
print( i , end=' ')
member = ['小甲鱼','小布丁','黑夜','迷途','怡静']
for each in menber
print(each,len(each))range( )函数功能是生成数列,用法是:range( a,b,x )
其中a是数列的起始值,b是数列包含数字的个数,x是步长。
a和x可以省略,a的缺省值是0,x的缺省值是1
break关键字:终止循环,向下执行循环块后面的代码。【作用范围:一层循环】
continue关键字:跳过循环块中的剩余代码,立即执行下一轮循环。【作用范围:一层循环】
010 一个打了激素的数组1
列表:
menber = ["小甲鱼",“小布丁”,"迷途","怡静"]
number = [ 1, 2, 3, 4, 5]
mix = [ 1, "小甲鱼", 3.14, [1, 2, 3]]
empty = []menber = ["小甲鱼",“小布丁”,"迷途","怡静"]
member.append("福禄娃娃")
#将“福禄娃娃”添加到member末尾
menber = ["小甲鱼",“小布丁”,"迷途","怡静","福禄娃娃"]还有一种添加方式,extend()
menber = ["小甲鱼",“小布丁”,"迷途","怡静"]
member.extend(["竹林小溪","Crazy迷恋"])
#在列表末尾一次性追加另一个序列中的多个值insert()函数,可以指定插入的位置
menber = ["小甲鱼",“小布丁”,"迷途","怡静"]
member.insert(x, "y")
#将“y”插入到列表menber的x的位置,原列表x的位置的元素依次向后移位011 一个打了激素的数组2
menber = ["小甲鱼",“小布丁”,"迷途","怡静"]
member.remove("小甲鱼")
#从member列表里删掉“小甲鱼”这个元素,删完后面的元素向前移动
#如果member.remove("大笨猪"),就会报错,因为目标列表里没有这个元素
menber = ["小甲鱼",“小布丁”,"迷途","怡静"]
del member(1)
#删掉“小布丁”这个元素,后面元素一次向前补上
del member
#del后加列表名,就会删掉整个列表
menber = ["小甲鱼",“小布丁”,"迷途","怡静"]
member.pop()
#删除列表中最后一个元素,并返回该元素
member.pop(1)
#跟上面del一样,指定pop出哪个位置的元素,并返回该元素
切片:
menber = ["小甲鱼",“小布丁”,"迷途","怡静"]
member[1:3]
#会返回从1到3位置的元素,不包括3
member[:3]
#第一个数的缺省值为0,不写就表示从0开始
member[1:]
#第二个数的缺省值为列表的最后,不写就表示一直到列表的最后一个元素
member[:]
#两个数都不写,得到的就是列表的拷贝【数据的拷贝,非地址的拷贝】012 一个打了激素的数组3
list1 = [123,456]
list2 = [234,123]
print(list1 > list2)
#返回falsa,比较的是第0位。比较是从第0为开始,若相等则依次往后比较
list4 = list1 + list2
#list4返回[123,456,234,123],就是list2接到list1后面,拼起来
list2 * 3
#运行结果就是list2为[234,123,234,123,234,123]
#就是list2被复制三次,和list2 *=3是一样的效果
list2 = [234,123]
123 in list2 #返回True
123 not in list2 #返回False
'小甲鱼' not in list2 #返回True
list5 = [123,['小甲鱼','牡丹'],456]
'小甲鱼' in list5 #返回False 【只能查找一层】
'小甲鱼' in list5[1] #返回rue 【指定到这一层就能查到了】
#要打印'小甲鱼',就要使用类似二维数组的写法,list5[1][1]就是'小甲鱼'了
#1列表的添加:
#append()是添加单个元素、
#extend()是添加列表、
#insert()是想指定位置插入
#2列表的修改:
#列表名 * N :用列表名乘以N,则把当前列表复制N次,覆盖原列表
#sort(),对目标列表排序,默认从小到大排序,通过修改输入参数,可调整功能。
#比如,sort(reverse = True),则从大到小排序。参数还可指定使用哪个排序算法。
#sort()默认使用堆排序
#reverse()反转列表
#3列表的删除:remove()、del()、pop()
#remove()输入参数是具体元素、del()输入参数是位置、
# pop()默认删最后意思元素,若指定山某个元素,同del()
#4列表的查询:count()、index()
#count()是统计输入参数在目标列表中出现的次数
#index()是查找输入参数第一次出现在目标列表中的位置
#indec()还可在某个位置区间搜索,member.index('小甲鱼',3,7)
#则从下标位置3到7这些元素中搜索,返回第一次出现'小甲鱼'的下标,不包括7的位置。013 元组:戴上了枷锁的列表
元组和列表的区别:
1. 创建和访问
创建使用的是( ),访问和使用元组还是使用[ ]
元组被规定不可以被修改,比如:(但后面会讲修改的办法)
tuple1 = (1,2,3,4,5,6,7,8)
tuple1[1] = 0 #这样会报错,元组是不可以被修改的temp = (1) #以为创建了一个元素的元组
type(temp) #这句返回的是'int',实际上创建的是int型变量
temp2 = 2,3,4
type(temp2) #这句返回的是'tuple',及时不加括号,只要有逗号也是元组
temp = []
type(temp) #这里创建的就是'list'
temp = ()
type(temp) #这里创建的是'tuple'
temp = (1,)
type(temp) #这样创建的就是'tuple',因为有逗号了
temp = 1,
type(temp) #和上面带括号的一样,这里也是'tuple'
8 * (8) #这个结果是一个数值
8 * (8,) #这样返回的结果就是(8,8,8,8,8,8,8,8),因为这个时候,*就是复制功能了2. 更新和删除
temp = ('小甲鱼','黑夜','迷途','小布丁')
temp = temp[:2] + ('怡静') + temp[2:]
#通过使用切片的方法,来造一个新元组,再覆盖掉原来的temp
#新的temp就是('小甲鱼','黑夜','怡静','迷途','小布丁')
del temp #删除temp元组3. 元组相关的操作符
跟列表类似,只要不涉及到直接修改元组的,都可以用。
014 字符串:各种奇葩的内置方法
str1 = 'I love fishc.com'
str1[:6] #(切片)返回:'I love'
str1[5] #返回'e'
#字符串和元组一样,不能修改,所以要向字符串中插入字符串就还是要用切片的方法
str1[:6] + '要插入的字符串' + str1[6:]
#返回:'I love要插入的字符串 fishc.com'
| 1 | capitalize() |
| 2 | center(width, fillchar) 返回一个指定的宽度 width 居中的字符串,fillchar 为填充的字符,默认为空格。 |
| 3 | count(str, beg= 0,end=len(string)) 返回 str 在 string 里面出现的次数,如果 beg 或者 end 指定则返回指定范围内 str 出现的次数 |
| 4 | bytes.decode(encoding="utf-8", errors="strict") Python3 中没有 decode 方法,但我们可以使用 bytes 对象的 decode() 方法来解码给定的 bytes 对象,这个 bytes 对象可以由 str.encode() 来编码返回。 |
| 5 | encode(encoding='UTF-8',errors='strict') 以 encoding 指定的编码格式编码字符串,如果出错默认报一个ValueError 的异常,除非 errors 指定的是'ignore'或者'replace' |
| 6 | endswith(suffix, beg=0, end=len(string)) |
| 7 | expandtabs(tabsize=8) 把字符串 string 中的 tab 符号转为空格,tab 符号默认的空格数是 8 。 |
| 8 | find(str, beg=0 end=len(string)) 检测 str 是否包含在字符串中,如果指定范围 beg 和 end ,则检查是否包含在指定范围内,如果包含返回开始的索引值,否则返回-1 |
| 9 | index(str, beg=0, end=len(string)) 跟find()方法一样,只不过如果str不在字符串中会报一个异常. |
| 10 | isalnum() 如果字符串至少有一个字符并且所有字符都是字母或数字则返 回 True,否则返回 False |
| 11 | isalpha() 如果字符串至少有一个字符并且所有字符都是字母则返回 True, 否则返回 False |
| 12 | isdigit() 如果字符串只包含数字则返回 True 否则返回 False.. |
| 13 | islower() 如果字符串中包含至少一个区分大小写的字符,并且所有这些(区分大小写的)字符都是小写,则返回 True,否则返回 False |
| 14 | isnumeric() 如果字符串中只包含数字字符,则返回 True,否则返回 False |
| 15 | isspace() 如果字符串中只包含空白,则返回 True,否则返回 False. |
| 16 | istitle() 如果字符串是标题化的(见 title())则返回 True,否则返回 False |
| 17 | isupper() 如果字符串中包含至少一个区分大小写的字符,并且所有这些(区分大小写的)字符都是大写,则返回 True,否则返回 False |
| 18 | join(seq) 以指定字符串作为分隔符,将 seq 中所有的元素(的字符串表示)合并为一个新的字符串 |
| 19 | len(string) 返回字符串长度 |
| 20 | ljust(width[, fillchar]) 返回一个原字符串左对齐,并使用 fillchar 填充至长度 width 的新字符串,fillchar 默认为空格。 |
| 21 | lower() 转换字符串中所有大写字符为小写. |
| 22 | lstrip() 截掉字符串左边的空格或指定字符。 |
| 23 | maketrans() 创建字符映射的转换表,对于接受两个参数的最简单的调用方式,第一个参数是字符串,表示需要转换的字符,第二个参数也是字符串表示转换的目标。 |
| 24 | max(str) 返回字符串 str 中最大的字母。 |
| 25 | min(str) 返回字符串 str 中最小的字母。 |
| 26 | replace(old, new [, max]) 把 将字符串中的 str1 替换成 str2,如果 max 指定,则替换不超过 max 次。 |
| 27 | rfind(str, beg=0,end=len(string)) 类似于 find()函数,不过是从右边开始查找. |
| 28 | rindex( str, beg=0, end=len(string)) 类似于 index(),不过是从右边开始. |
| 29 | rjust(width,[, fillchar]) 返回一个原字符串右对齐,并使用fillchar(默认空格)填充至长度 width 的新字符串 |
| 30 | rstrip() 删除字符串字符串末尾的空格. |
| 31 | split(str="", num=string.count(str)) num=string.count(str)) 以 str 为分隔符截取字符串,如果 num 有指定值,则仅截取 num 个子字符串 |
| 32 | splitlines([keepends]) 按照行('\r', '\r\n', \n')分隔,返回一个包含各行作为元素的列表,如果参数 keepends 为 False,不包含换行符,如果为 True,则保留换行符。 |
| 33 | startswith(str, beg=0,end=len(string)) 检查字符串是否是以 obj 开头,是则返回 True,否则返回 False。如果beg 和 end 指定值,则在指定范围内检查。 |
| 34 | strip([chars]) 在字符串上执行 lstrip()和 rstrip() |
| 35 | swapcase() 将字符串中大写转换为小写,小写转换为大写 |
| 36 | title() 返回"标题化"的字符串,就是说所有单词都是以大写开始,其余字母均为小写(见 istitle()) |
| 37 | translate(table, deletechars="") 根据 str 给出的表(包含 256 个字符)转换 string 的字符, 要过滤掉的字符放到 deletechars 参数中 |
| 38 | upper() 转换字符串中的小写字母为大写 |
| 39 | zfill (width) 返回长度为 width 的字符串,原字符串右对齐,前面填充0 |
| 40 | isdecimal() 检查字符串是否只包含十进制字符,如果是返回 true,否则返回 false。 |
015 字符串:格式化
replacement字段:
#位置参数
"{0} love {1}.{2}".format("I","FishC","com")
#这句返回'I love FishC.com'
#关键字参数
"{a} love {b}.{c}".format(a="I",b="FishC",c="com")
#关键字参数需要指定一下,这句返回'I love FishC.com'
#位置&关键字参数混合使用
"{0} love {b}.{c}".format("I",b="FishC",c="com")
#要保证位置参数在关键字参数前
#如果下面这样,就报错了
"{a} love {b}.{0}".format(a="I",b="FishC","com")
#这样就报错了,提示"com"需要指定关键字
"{{0}}".format("不打印")
#前面已经不算位置参数了,所以返回:'{0}'
#如果把{0}当作关键字参数,在后面写上{0}=‘不打印’,会报错
'{0:.1f}{1}'.format(27.658,'GB')
#第一个位置参数后面多了:.1f,这个冒号表示后面是格式化符号的开始
#这个.1f是打印四舍五入到小数点后一位转义字符的使用:【类似C语言的printf()】
'%c' % 97 #返回的就是97对应的字符'a'
'%c' '%c' '%c' % (97, 98, 99) #返回'a b c'
'%d + %d = %d' % (4, 5, 4+5) #返回'4 + 5 = 9'
'%5.1f' % 27.658 #返回' 27.1',5指示返回的字符串最少占5个位置,1表示精确到小数点后一位
'%.2e' % 27.658 #返回'2.77e+01',2指示返回的字符串精确到小数点后两位,e指示用e的表示法
'%3d' % 5 #返回:' 5',3表示返回的字符串至少占3位
'%-3d' % 5 #返回:'5 ',加负号表示左对齐
'%#o' % 100 #返回100的八进制数
'%#x' % 100 #返回100的十六进制数
'%#d' % 100 #返回100的十进制数
'%010d' % 5 #返回的还是最少占10位,但改成了用0填充
'%-010d' % 5 #返回的还是用空格占位,因为如果用0占位,内容本身就变了,5就变成了5000000000016 序列!序列!
列表、元组和字符串的共同点:
1. 都可以通过索引得到每一个元素
2. 默认索引值从0开始
3. 可是使用切片
4. 都可以使用:重复操作符、拼接操作符、成员关系操作符(in、not in)
list()把一个可迭代对象转换为列表
有两个参数组合:
1. 无参数,返回空列表。
2. 参数为迭代器,从一个可迭代对象初始化一个新列表
b = 'I love FishC.com'
b = list(b)
#b现在就变成了['I',' ','l','o','v','e','F','i','s','h','C','.','c','o','m']
c = (1, 1, 2, 3, 5, 8, 13, 21, 34)
c = list(c)
#b现在变成了[1, 1, 2, 3, 5, 8, 13, 21, 34]
tuple() #是把对象转换成元组,用法和list()类似
str() #是把对象转换成字符串,用法和list()类似
len() #是返回对象的元素个数
max() #返回对象的最大值,按ASCⅡ来排列
min() #返回对象的最小值,一样是按ASCⅡ来排列
#如果输入为字符串,因为字符串也是可迭代对象,所以返回字符串中ASCⅡ值最小的那个字符
sum() #返回对象的相加总和
sum(list,8) #返回值是,把list的加和计算完再加上8
sorted() #把对象从小到大排序
reversed() #返回的是一个迭代器
#要返回翻转的值,需要使用其它的序列函数再转一下,比如:
list(reversed(c))
enumerate() #生成由每个元素的index值和item值组成的元组
#用法类似reversed()
numbers = [1, 18, 76]
list(enumerate(numbers))
#返回:[(0,1),(1,18),(2,76)]
zip() #返回由各个参数的序列组成的元组
a = [7, 6, 5, 4]
b = [2, 3, 4]
list(zip(a,b))
#返回:[(7,2),(6,3),(5,4)]017 函数:python的乐高积木
# 函数的格式:
def function(para_1,para_2):
result = para_1 + para_2
return result018 函数:灵活即强大
__doc__属性
def fnc():
'''函数语句中,如果第一个表达式是一个string,这个函数的__doc__就是这个string,否则__doc__是None'''
print(fnc.__doc__)def saysome(name,words):
print(name + '->' +words)
saysome('小甲鱼','xxx')
saysome('xxx','小甲鱼')
saysome(words='xxx',name='小甲鱼')
#通过关键字索引,使函数接收参数不受位置影响默认参数:
def saysome(name='小甲鱼',words='xxx'):
print(name + '->' +words)
#函数可以设置参数的缺省值,但带缺省值的参数只能放在没有缺省值参数的后面def test(*para):
print('参数长度:',len(para))
print('第一个参数:',para[0])
#不确定参数数量时使用可变参数这个语法
test(4,5,6,22,51,7)
def func_1(*para,env=250):
print('参数长度:',len(para))
print('第一个参数:',para[0])
func_1(4,5,6,22,51,7,env=100)
#可变参数后面的值需要使用关键字索引,否则就被当作可变参数
#通常会把可变参数后面的参数设置缺省值,防止没用关键字索引时函数报错019 函数:我的地盘听我的
def hello():
print('hello')
print(type(hello())) #函数没有返回值时,返回值类型就是'NoneType'
def back():
return 1,'小甲鱼',3.14
back() #调用该函数,返回的是元组(1,'小甲鱼',3.14),因为带逗号的表达式默认是元组def discounts(price,rate):
final_price = price * rate
old_price = 50 #此处是局部的old_price,在该函数的作用域下,使用局部的old_price
print('修改后的old_price值:',old_price)
return final_price
old_price = float(input('请输入原价:')) #输入100
rate = float(input('请输入折扣:')) #输入0.6
new_price = discounts(old_price,rate) #函数返回计算后的值:60
print('修改后的old_price的值是:',old_price) #打印的是全局的old_price
print('打折后的价格是',new_price) #打印经函数计算的结果:new_price这时局部的这个变量和全局的那个变量,名字虽然相同,
但不是同一个变量,类似C++中的代码块内的变量,当出现与全局变量一样名的变量时,
在当前局部代码块儿中,全局变量失效,使用的是局部变量。
如果想在局部改全局的变量,用global修饰变量,就ok啦。
020 内嵌函数和闭包
内嵌函数:
def fun1():
print('fun1()正在被调用...')
def fun2():
print('fun2()正在被调用...')
fun2()
fun1()
#运行结果是:
#fun1()正在被调用...
#fun2()正在被调用...闭包:
def FunX(x):
def FunY(y):
return x*y
return FunY
i = FunX(8) #返回的是函数
type(i) #返回结果为'function'
i(5) #返回40
FunX(8)(5) #返回40
FunY(5) #这行会报错,不能直接使用FunY()
def Fun1():
x = 5
def Fun2():
x *= x
return x
return Fun2()
Fun1() #这行会报错,因为在Fun2()中的x属于局部变量,
# 并不是Fun1()中的那个x,所以会提示x不能在被分配值前使用
#修改1:
def Fun1():
x = [5]
def Fun2():
x[0] *= x[0]
return x[0]
return Fun2()
Fun1() #这样就不会报错了,列表不是存放在栈中
# 因此这里返回25
#修改1:
def Fun1():
x = 5
def Fun2():
nonlocal x
x *= x
return x
return Fun2()
Fun1() #使用nonlocal关键字,表示此处使用的不是局部的变量
# 这样就能在此处使用Fun1()里的x了,因此这里返回25021 函数:lambda表达式
#1
def ds(x):
return 2 * x + 1
#2
ds = lambda x : 2 * x + 1
#1和#2等价
#1
def add(x,y):
return x+y
#2
add = lambda x,y: x+y
add(3,4) #返回7结合filter()和map()使用
filter(lambda x:x%2 ,range(10)) #筛选出0~9中的奇数
#range(10)里的值代入到第一个参数中,第一个参数返回为真的留下
map(lambda x:x*2 ,range(10)) #所有数都乘以2
#range(10)里的值代入到第一个参数中,按第一个参数的计算方式计算022 函数:递归是神马
非递归求阶乘:
def factorial(n):
result = n
for i in range(1,n):
result *=i
return result递归求阶乘:
def factorial(n):
if n==1:
return 1
else:
return n*factorial(n-1)#2 有终止条件
023 递归:这帮小兔崽子
实现斐波那契数列:
#迭代:
def fab(n):
n1 = 1
n2 = 1
n3 = 1
if n<1:
print('输入有误!')
return -1
while (n-2)>0:
n3 = n2+n1
n1 = n2
n2 = n3
n -= 1
return n3实现2:
def fibonacci_iteration(n):
a = 0
b = 1
list = []
for i in range(n):
next_value = a+b
a,b = b,next_value
list.append(a)
return list#递归:
def fab(n):
if n<1:
print('输入有误!')
return -1
if n==1 or n==2:
return 1
else:
return fab(n-1)+fab(n-2)024 递归:汉诺塔
将64个盘子从x上移动到z上,中间借助y
拆分过程:
1. 将前63个盘子从x上移动到y上(多步骤操作)
2. 将x上的第64个盘子从x移动到z上(单步操作)
3. 将y上的63个盘子移动到z上(多步骤操作)
将两个多步骤操作继续分:
1. 可以描述成新问题,将63个盘子从x上移动到y上,中间借助z
3. 可以描述成新问题,将63个盘子从y上移动到z上,中间借助x
代码如下:
def hanoi(n,x,y,z):
if n==1:
print(x,'-->',z)
else:
hanoi(n-1,x,z,y) #将前n-1个盘子从x移动到y上
print(x,'-->',z) #将最底下的最后一个盘子从x移动到z上
hanoi(n-1,y,x,z) #将y上的n-1个盘子移动到z上025 字典:当索引不好用时1
dict1 = {'李宁':'一切皆有可能','耐克':'Just do it','阿迪达斯':'Impossible is nothing','鱼C工作室':'让编程改变世界'}
print('鱼C工作室的口号是:',dict1['鱼C工作室'])
#返回的是'鱼C工作室'冒号后面对应的键值:'让编程改变世界'
dict3 = dict((('F',70),('h',104),('C',67)))
#dict3变成了字典{'F':70,'C':67,'h':104}
dict4 = dict(小甲鱼='让编程改变世界',苍井空='让AV征服所有宅男')
#dict4变成了字典{'苍井空':'让AV征服所有宅男','小甲鱼':'让编程改变世界'}
dict4['苍井空'] = '替换内容'
dict4['爱迪生'] = '测试添加项'
#原字典里有的键,会修改对应的键值;若没有的,则添加键和键值。创建字典的办法:
1、用{}创建字典
2、用内置函数dict()
1)、入参为类似a="1"的键值对
2)、入参为一个元组,元组内部是一系列包含两个值的元组,例如(("a", "1"), ("b", "2"))
3)、入参为一个元组,元组内部是一系列包含两个值的列表,例如(["a", "1"], ["b", "2"])
4)、入参为一个列表,列表内部是一系列包含两个值的元组,例如[("a", "1"),("b", "2")]
5)、入参为一个列表,列表内部是一系列包含两个值的列表,例如[["a", "1"],["b", "2"]]
3、用户fromkeys方法创建字典,第一个
026 字典:当索引不好用时2
字典的BIF:
fromkeys()
items()
keys()
values()
get()
in 操作符
clear()
copy()
pop()
popitem()
setdefault()
update()
027 集合:在我的世界里,你就是唯一
集合(set)是一个无序不重复元素的序列。
基本功能是进行成员关系测试和删除重复元素。
可以使用大括号 { } 或者 set() 函数创建集合,注意:创建一个空集合必须用 set() 而不是 { },因为 { } 是用来创建一个空字典。
num ={}
type(num) #返回'dict'
num2 = {1,2,3,4,5}
type(num2) #返回'set'创建集合的两种方法:
一种是上面的num2,直接用花括号括起来的方法;另一种是使用set()工厂函数创建集合
num = set([1,2,3,4,56,56])
print(num) #返回{1, 2, 3, 4, 56}set可以进行集合元算:交、并、差、补
集合可以使用in 操作符,常用的BIF有add()和remove(),用于添加和删除元素。
不可变的集合:
num = frozenset([1,2,3,4,56,56])028 文件:因为懂你,所以永恒
open()函数:读写文件,返回一个file对象,这个file对象可直接作为序列进行迭代。
open(filename, mode)
- filename:filename 变量是一个包含了你要访问的文件名称的字符串值。
- mode:mode决定了打开文件的模式:只读,写入,追加等。所有可取值见如下的完全列表。这个参数是非强制的,默认文件访问模式为只读(r)。
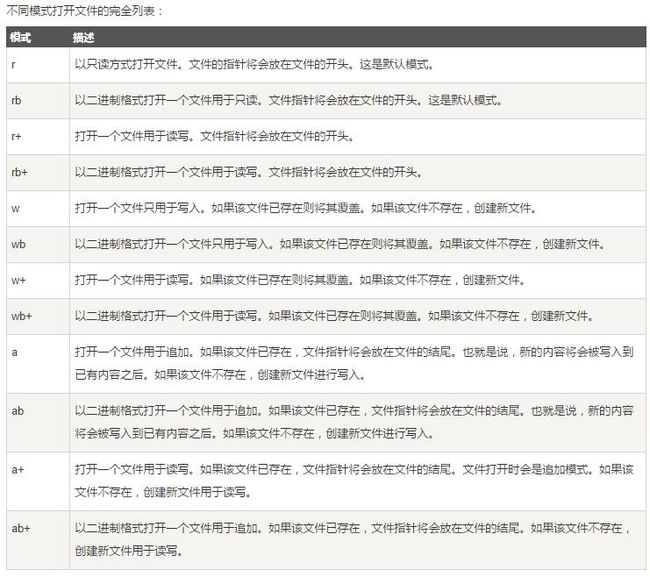
文件对象的各种方法:
常用的有read()、close()、readline()、readlines()、wrtite()、tell()、seek()等。
029 文件:一个任务
使用split()函数分割文本
把open()返回的对象直接当序列用时,每次迭代返回一行的内容。
030 文件系统:介绍一个高大上的东西
OS模块:
常用的函数有:getcwd()、chdir()、listdir()、mkdir()、rmdir()、remove()、system()、curdir()、、、、、、、、、、、、、、、
OS.PATH模块:
主要是对文件路径的各种拆分操作和对文件属性的获取。
031 永久存储:腌制一缸美味的泡菜
pickle模块:
主要就两个函数,一个是dump()、一个是load()
我个人的理解是类似C++里输入输出流的操作。
032 异常处理:你不可能总是对的1
python标准异常总结
033 异常处理:你不可能总是对的2
异常的捕获:
try:
可能出现异常的代码
except 标准异常的宏 as arr:
出现异常后要执行的代码其中,arr用于存储异常原因的描述。
finally关键字
finally存在的意义是如果try没捕获到的异常导致程序崩溃,finally后面的语句会在程序挂掉的时候,临死前呻吟一下。
关于try、except、else、finally这几个关键字正确使用的顺序:
与其他语言相同,在python中,try/except语句主要是用于处理程序正常执行过程中出现的一些异常情况,如语法错误(python作为脚本语言没有编译的环节,在执行过程中对语法进行检测,出错后发出异常消息)、数据除零错误、从未定义的变量上取值等;而try/finally语句则主要用于在无论是否发生异常情况,都需要执行一些清理工作的场合,如在通信过程中,无论通信是否发生错误,都需要在通信完成或者发生错误时关闭网络连接。尽管try/except和try/finally的作用不同,但是在编程实践中通常可以把它们组合在一起使用try/except/else/finally的形式来实现稳定性和灵活性更好的设计。
默认情况下,在程序段的执行过程中,如果没有提供try/except的处理,脚本文件执行过程中所产生的异常消息会自动发送给程序调用端,如python shell,而python shell对异常消息的默认处理则是终止程序的执行并打印具体的出错信息。这也是在python shell中执行程序错误后所出现的出错打印信息的由来。
python中try/except/else/finally语句的完整格式如下所示:
try:
Normal execution block
except A:
Exception A handle
except B:
Exception B handle
except:
Other exception handle
else:
if no exception,get here
finally:
print("finally") 说明:
正常执行的程序在try下面的Normal execution block执行块中执行,在执行过程中如果发生了异常,则中断当前在Normal execution block中的执行跳转到对应的异常处理块中开始执行;
python从第一个except X处开始查找,如果找到了对应的exception类型则进入其提供的exception handle中进行处理,如果没有找到则直接进入except块处进行处理。except块是可选项,如果没有提供,该exception将会被提交给python进行默认处理,处理方式则是终止应用程序并打印提示信息;
如果在Normal execution block执行块中执行过程中没有发生任何异常,则在执行完Normal execution block后会进入else执行块中(如果存在的话)执行。
无论是否发生了异常,只要提供了finally语句,以上try/except/else/finally代码块执行的最后一步总是执行finally所对应的代码块。
需要注意的是:
1.在上面所示的完整语句中try/except/else/finally所出现的顺序必须是try-->except X-->except-->else-->finally,即所有的except必须在else和finally之前,else(如果有的话)必须在finally之前,而except X必须在except之前。否则会出现语法错误。
2.对于上面所展示的try/except完整格式而言,else和finally都是可选的,而不是必须的,但是如果存在的话else必须在finally之前,finally(如果存在的话)必须在整个语句的最后位置。
3.在上面的完整语句中,else语句的存在必须以except X或者except语句为前提,如果在没有except语句的try block中使用else语句会引发语法错误。也就是说else不能与try/finally配合使用。
4.except的使用要非常小心,慎用。
class AError(Exception):
"""AError---exception"""
print('AError')
try:
#raise AError
asdas('123')
except AError:
print("Get AError")
except:
print("exception")
else:
print("else")
finally:
print("finally")
print("hello wolrd")在上面的代码中,Normal execution block中出现了语法错误,但是由于使用了except语句,该语法错误就被掩盖掉了。因此在使用try/except是最好还是要非常清楚的知道Normal execution block中有可能出现的异常类型以进行针对性的处理。