1.背景
日志主要包括系统日志、应用程序日志和安全日志。系统运维和开发人员可以通过日志了解服务器软硬件信息、检查配置过程中的错误及错误发生的原因。经常分析日志可以了解服务器的负荷,性能安全性,从而及时采取措施纠正错误。
通常,日志被分散的储存不同的设备上。如果需要管理数十上百台服务器,必须依次登录每台机器的传统方法查阅日志,这样很繁琐和效率低下。当务之急是使用集中化的日志管理,开源实时日志分析ELK平台能够完美的解决上述所提到的问题。
2.需要安装的工具
ELK由ElasticSearch(ES)、Logstash和Kiabana三个开源工具组成。
ES是个开源分布式搜索引擎,它的特点有:分布式,零配置,自动发现,索引自动分片,索引副本机制,restful风格接口,多数据源,自动搜索负载等,最重要的是近实时搜索。
Logstash是一个完全开源的工具,可以对日志进行收集、分析、并将其存储供以后使用。
kibana也是一个开源和免费的工具,他Kibana可以为Logstash和ES提供的日志分析友好的Web界面,可以帮助您汇总、分析和搜索重要数据日志
下载地址:https://www.elastic.co/downloads
 ELK是基于java的开源,所以需要安装jdk,配置环境变量
ELK是基于java的开源,所以需要安装jdk,配置环境变量
安装过程比较简单,运行可执行文件一直下一步即可。安装完成后,配置JAVA_HOME和JRE_HOME,如下图所示:

在cmd命令窗口中运行java -version命令,如果现实如下结果,表示安装成功:

Logstash服务依赖与ES服务,Kibana服务依赖Logstash和ES,所以ELK的服务启动顺序为:ES->Logstash->Kibana,为了配合服务启动顺序,我们安装顺序和启动顺序保持一致。
解压三个压缩包到同一个目录中,目录的绝对路径中最好不要出现中文字符和空格,解压目录如下:

3.安装
然后依次安装,在es的bin目录下执行service install命令安装就好了,默认端口是9200。

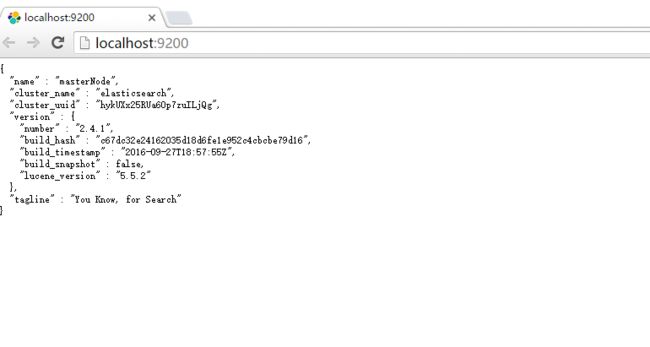
安装成功之后浏览器直接访问: http://localhost:9200/ 若出现以下结果,则表示安装成功,服务启动::
接下来我们安装head插件,在bin目录下,运行plugin install mobz/elasticsearch-head。安装完成后,在浏览器里输入:http://localhost:9200/_plugin/head/,出现类似以下结果,表示插件安装成功:(默认情况下是单节点的,下图是我配置的单机多节点,模拟集群部署的环境)

接下来安装 logstash服务,我们需要借助 nssm 来安装,具体nssm 是什么东西,请看官网解释:
nssm is a service helper which doesn't suck. srvany and other service helper programs suck because they don't handle failure of the application running as a service. If you use such a program you may see a service listed as started when in fact the application has died. nssm monitors the running service and will restart it if it dies. With nssm you know that if a service says it's running, it really is. Alternatively, if your application is well-behaved you can configure nssm to absolve all responsibility for restarting it and let Windows take care of recovery actions.
具体就不翻译了,应该都能看得懂。
从官网下载nssm.exe之后 拷贝到logstash的bin目录下,然后在bin目录下新建logstash.conf配置文件,具体内容如下,具体参数可以自定义:
我的定义如下:
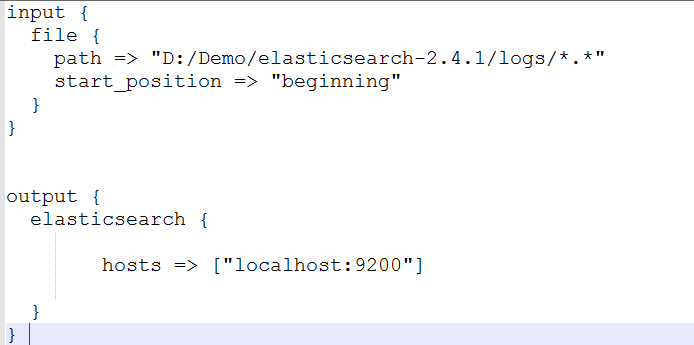
具体参数什么意思请参考官网文档解释。
然后再新建 run.bat文件,内容如下:

然后运行命令:nssm install logstash 安装:
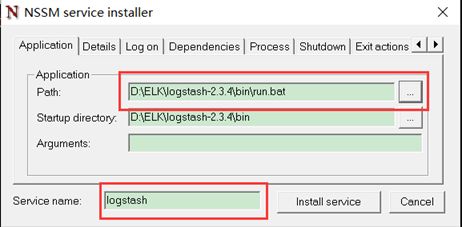
在依赖里面根据填写如下内容(注意:Java是32位的后缀是x86,64位的是x64):
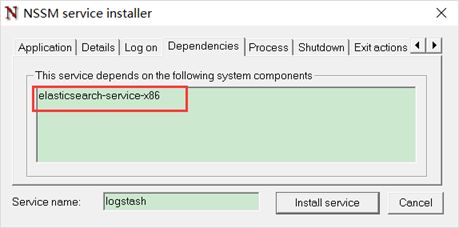
添加依赖的原因是,logstash的输出配置的是Elasticsearch,如果Elasticsearch没有启动,logstash无法正常工作。
最后单击install service按钮,执行安装过程。
最后安装kibana,步骤和上面的步骤一样,依赖里面配置如下内容:

4.启动服务
在cmd中运行services.msc打开windows服务,依次启动如下服务:
Elasticsearch
Logstash
Kibana
在浏览器中输入:http://localhost:5601/,如果出现如下界面,表示服务启动成功:

单击“create”按钮,我的index名字是:.kibana 然后点击Discover

到此我们的单节点的配置就完了,在生产环境一般都是多节点集群化部署,再加loadbalance处理。
我们也可以在单机做多节点部署,模仿集群环境,配置也比较简单把 es的目录拷贝三份
然后分别修改config/elasticsearch.yml 文件中的下面参数:
cluster.name: elasticsearch 集群名称,4个节点的集群名称一样才能识别到是属于同一个集群(前提是要在同一个网段,单机本身就是同一网段的)
node.name: followNode1 节点名称,集群中各个节点的名称,我的分别是 followNode1,followNode2,followNode3,主节点叫:masterNode
transport.tcp.port: 9301 tcp通信端口,默认主节点是:9300,我的几个从节点分别是: 9301,9302,9303
http.port: 9201 http通信端口,默认主节点是:9200,我的几个从节点分别是: 9201,9202,9203
注意我是直接拷贝的三份,所以service的名字也是一样的,我们需要手动修改一下

修改service_id参数,这就是安装到windows服务的名称,不能重复,所以我们依次改为backup1,backup2,backup3 ,名字可以自己随便起,但是最好起的有点意义
叫backup是因为他作为备份接节点存在。我们知道在集群化的管理中有master/slave的概念,也就是主/从节点,主要是为了双机备份,防止单节点宕机,几乎所有的集群化
都有这样的功能。比如solr,HBase,Cassandra,Hadoop等等。当master节点挂掉之后,其他的slave节点会自动重新选举出一个master节点,这个选举在ES集群中已经
实现,不像solr等其他的需要借助于zookeeper。
我们在创建节点的时候可以在配置文件elasticsearch.yml 中指定当前节点是否为主节点:
node.master: false 是否为主节点
node.data: true 是否作为数据节点
更多参数命令园子里已经有朋友整理的很详细了请参考: http://www.cnblogs.com/hanyouchun/p/5163183.html
修改好配置之后我们依次安装各个节点的服务,装好之后如下:

然后重启 elasticsearch-service-x64 服务,此时他作为master节点存在,重启之后才能识别到新的slave节点的存在,需要注意的是:
elasticsearch-service-x64 服务和 logstash,kibana有依赖,它停止之后这两个服务也就停止了,需要重新启动。
等服务重新启动完成之后在浏览器输入任何一个slave节点,都会显示在一个集群中:

ES提供了非常易用的Reful风格的api,非常易用,目前是非常活跃的开源搜索工具。
它支持多种类型的简单查询和复合查询,自己动手实践一下就知道他有多好用了:

学习地址:http://www.learnes.net/
欢迎关注微信公众平台联系我:上帝派来改造世界的人
