面向对象第三单元
前言
第三单元作业中,我们以JML为建模语言,实现对应接口,完成一个简单的地铁寻路系统的开发。本单元的代码量的确减少了很多,这主要是因为程序框架已经在提供的包中实现,我们只需要实现相关的代码,“有章可循”。测试也变得相对容易了起来。
JML的理论基础和工具链
在接触JML以前,笔者也接触过其他形式建模方法,最典型的就是UML语言。这一语言有很多优点:多样,直观,简化。但有时会比较抽象,在实现角度看难以理解。开发人员在拿到代码时,需要一杆“标尺”来明确自己需要做哪些事:“多的不做,也不能少某部分”。对于JAVA语言,jml则很好地实现了这一目的。在JAVA的注释中嵌入jml,以确定的语言,明确了模块或方法应实现的目标。
使用JML这样的建模语言,我们可以描述方法与其功能而不用实现,这样,对于设计人员,延迟过程设想的面向对象原则可以扩展到方法设计阶段。而JML为描述行为引入的各种构造,使得jml功能也异常强大。
最重要的是,JML通过不变式限制和约束限制清晰地告诉程序员“哪里怎么写”。
工具方面,OpenJML适配于Eclipse,可以用来检测规格实现的正确性。JML Editing和JML doc 则是方便设计人员编辑规格。SMTsolver是一个形式化方法求解器,可以用来验证程序等价性。JMLUnitNG则可以用来自动生成测试用例进行测试。
使用jmlTestNG构造测试样例
私以为这个自动构造十分不友好,配置过程不比写代码简单……尝试许久以后,总算能做出来最基本的测试。自动构造中主要涉及到的是边界条件。
为了实现TestNG的自动生成,笔者经历了:重新配置javac环境、重写规格说明(将容器改为了数组)、控制台执行编译、看不到正确现象又重复第一步……
(这么一看Rails 的test模组虽然死板了点,但是也起码能直接跑起来,好到不知道哪里去了)
架构设计
第一次作业
第一次作业中涉及到的是路径和路径容器,相对来说比较简单。路径需要保存相应的dictinctnode Count,路径容器则需要保存所有路径的DistinctNode集合。这就要求我们在增加和删除Node时就已经算好了相应修改后的点集信息。关于这部分我是这么设计的:用HashMap存储,Key为节点ID,value为出现的次数。在每次增加节点时,如果原不存在,则put(key,1),否则,将引用次数加1,即put(key, getValue()+1) 。删除路径时同理。最后,在访问distinctNode Count 时,返回HashMap.size()即可。
//e.g: deleteNode
private void deleteNode(Path path) {
for (Integer x : path) {
int count = disCounter.get(x);
if (count == 1) {
disCounter.remove(x);
} else {
disCounter.put(x, count - 1);
}
}
}类图:

其中,绿色为测试文件。
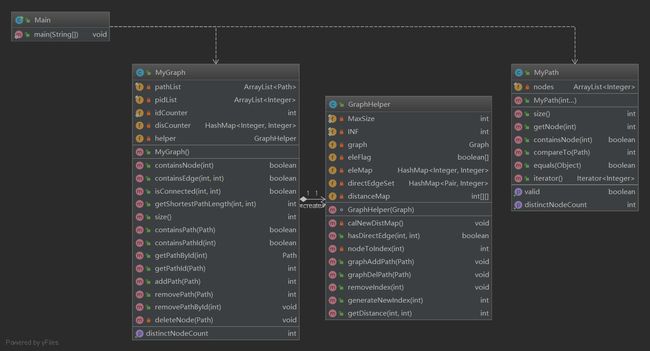
第二次作业(重构①!)
第二次作业中新增了关于图的最小运算单元,以及判断结点连接性。
鉴于路径容器里的信息需要提供给图,图又会生成自己的信息。因此在本次作业中,将图结构和路径、图的相关信息统一封装进Graph_Helper类当中。包括下面几类信息:
1、直连边,这是建图的关键。实际上,每次构建图,都是以直连边为权重1加入图当中。判断两点之间是否有边,也是判断直连边是否存在。因此,用DirectEdgeSet的HashMap存储直连边的信息及数量(原因同第一次作业对于distinctNode的处理),在Helper里又定义了内部类Pair,用于存储边。由于我们的作业中是无向图,因此用点ID递增顺序构建一条边,避免了(A、B) (B、A)被认为是两条边。
class Pair {
private int src;
private int dst;
Pair(int i, int i1) {
src = Math.min(i, i1);
dst = Math.max(i, i1);
}2、路径信息:
本次作业中用Floyd算法计算结点之间的最短路径,存储结构采取了静态数组(简单暴力且高效)。这需要我们把结点“映射”到相应的索引。因此,设计了方法NodeToIndex(在GraphHelper类中),使得结点信息从MyGraph进入Helper后,转变成索引信息。物理地址变成了虚拟地址,HOHO。
这样做,使得我们在查询最短路径时,只需要转化为相应索引进行数组查询即可,对于是否连接,则看最短路径是否小于INF。
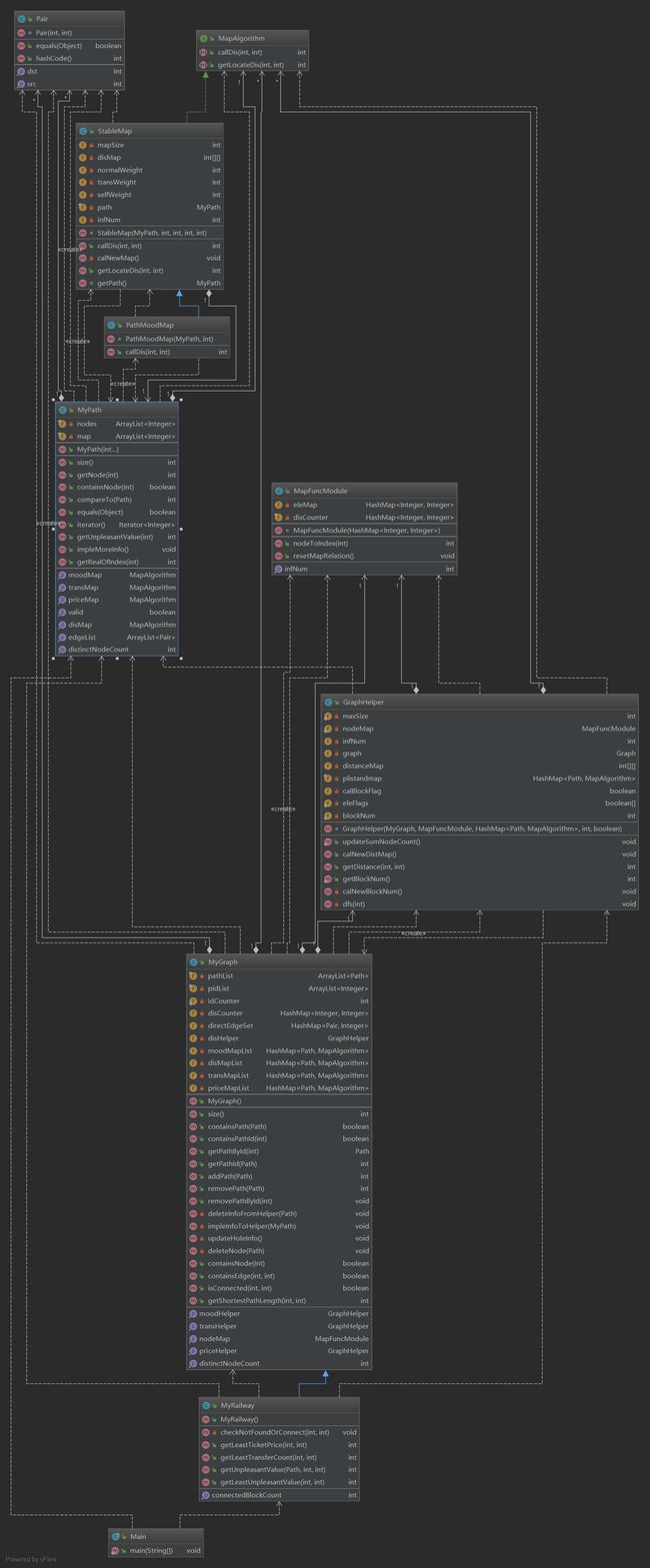
第三次作业(重构②!)
第三次作业中,添加了价格、满意度、换乘的权重图。实际上,这些图的本质是一样的。更抽象地说,权值的计算方式只有两类(固定权值型和计算权值型)。因此,第二次作业中的GraphHelper可以很好地用在第三次作业中。不过,也需要一定的改动:
1、抽离出结点映射模块。由于本次有四张图,所以需要一个统一的单例对象将图的映射机制统一化。在本次作业中,我将其封装为nodeMap类,在每次增加删除路径时,根据前面的作业,我们会把DistinctNode信息收集如Discounter中。将其修改,每次添加删除会触发NodeMap进行重新映射(隐含每次更新路径后,需要重新计算图)。
2、抽离出Pair内部类,这次将 “边”这一对象封装成独立模块,提供Path和Helper进行使用。
3、本次借鉴了第三次作业指导书中的分析,使RailWaySys 继承自第二次作业中的Graph,并实现了相应的扩展方法。
4、权重图计算上,依然是采用了Floyd算法。不过,进行了一些优化(且必要)。
其一是对每一条加入图的Path,会调用“补充”函数,先计算自己的“路径图”。这一路径图计算也会进行映射,且应当与总系统的映射机制隔离。在加入总图时,需要再次映射,如下:
for (Map.Entry path : plistandmap.entrySet()) {
MyPath it = (MyPath) path.getKey();
MapAlgorithm mapOfPath = path.getValue();
int size = it.getDistinctNodeCount();
for (int i = 0; i < size; i++) {
for (int j = i; j < size; j++) {
//映射间的映射关系,不应当混淆
int x = nodeMap.nodeToIndex(it.getRealOfIndex(i));
int y = nodeMap.nodeToIndex(it.getRealOfIndex(j)); 这样,计算每条路径自身的距离矩阵后,将其“缓存”下来,可以节省时间开销。
这样做也有其必要性----本次作业实现上,没有使用拆点法,而是用一种特殊的方式解决换乘难题:在计算Path 的“自图”后,对每一个(X,Y),都要加上一个换乘权重。可以这样理解:我是从图外换乘进来的。这样,在总图计算时,出发者就会站在“地图外面观察整个图”,在每次进入一个路径时都会换乘。再次站在出发点上考虑实际情况,只需要减去一个换乘代价即可。
//添加换乘代价
for (int i = 0; i < mapSize; i++) {
for (int j = i; j < mapSize; j++) {
if (disMap[i][j] < infNum) {
int tmp = disMap[i][j];
disMap[i][j] = disMap[j][i] = tmp + transWeight;
}
}
}
....
//减去1次换乘代价
//MyRailway.java
public int getLeastTicketPrice(int i, int i1)
throws NodeIdNotFoundException, NodeNotConnectedException {
checkNotFoundOrConnect(i, i1);
return getPriceHelper().getDistance(i, i1) - 2;
}在实现图方式上,只有满意度矩阵采用了特殊的权重计算方式,其他图都是同样的固定权重,我们不妨把它们称之为:换乘权重,自身权重,普通权重。且有如下对应关系:
| ... | 换乘 | 票价 | 心情 | 距离 |
|---|---|---|---|---|
| 普通权重 | 0 | 1 | cal | 1 |
| 自身权重 | 0 | 0 | 0 | 1 |
| 换乘权重 | 1 | 2 | 32 | 0 |
可以看到,只有情绪矩阵的权重计算比较复杂,因此,将CallDIS的重载,即可完成MoodPath矩阵。
本次重构也有一点美中不足。在计算Path的路径信息时也用到了FLOYD算法,但并没有和总系统的Helper组合实现重用,这是应为总系统中初始化距离矩阵使用的是Path的"补充图",而Path自己在生成图时用的是直连边信息。
BUG修复
本系列作业中,在第二次作业里,强测阶段出现了2个错误点。原因在于映射机制有瑕疵。我实现的映射机制,针对未映射的点先做了生成映射处理。而在删除路径时,先调用了删除映射,后调用删除直连信息,导致删除直连信息时又重新生成了映射。
再由于我使用了固定映射的办法(结点消失后,原有映射位置位FALSE,新的结点加入时,回去寻找映射数组中,为True的最小Index),最后导致映射数组在极端情况下被占满,程序报异常。修改两行代码顺序,程序BUG解决(血亏)。。。
因此,在第三次作业里,谨慎地提取整个映射模块,并封装使用。最后,用Python脚本生成随机测试用例并对拍测试,强测阶段没出现错误。
规格撰写理解
三次作业里,照猫画虎,学着自己写了一些规格。开始写的很顺利,但随着读的规格多了,自己反而在第六次课上实验里不敢去动手写了。究其原因,是自己一直在思考如何写得更严谨。恐怕,这需要我们不仅仅满足于JML Level 0 的规格文档,需要进一步地挖掘。
第三单元作业,相比前两单元更令人舒适,就是因为规格的加入,使得我明白自己应当做什么。并不能算得上一个优秀软件工程师的我,面对一个0的项目,设计出来的东西难免虎头蛇尾。给出一个范例和一个方向,确实能大大加快代码速度。并且,自己实现一个小块的代码时,也更容易写出“优美的代码”。
后记
本系列作业虽然没有强调设计架构,但实现环节里不经意间就考虑到重构的可能性。说明经过这么多训练,确实代码能力得到了很大的提升。
还剩最后一单元,要再加把劲啊!
压力马斯内!
2019.5.19
16231213
By:DorMouse