整型
先从最基本的数据类型整型说起,首先用一张表格归纳一下:
| 数据类型 | 字节数 | 带符号最小值 | 带符号最大值 | 不带符号最小值 | 不带符号最大值 |
| TINYINT | 1 | -128 | 127 | 0 | 255 |
| SMALLINT | 2 | -32768 | 32767 | 0 | 65535 |
| MEDIUMINT | 3 | -8388608 | 8388607 | 0 | 16777215 |
| INT | 4 | -2147483648 | 2147483647 | 0 | 4294967295 |
| BIGINT | 8 | -9223372036854775808 | 9223372036854775807 | 0 | 18446744073709551616 |
即使是带符号的BIGINT,其实也已经是一个天文数字了,什么概念,9223372036854775807我们随便举下例子:
- 以byte为例可以表示8589934592GB-->8388608TB-->8192PB
- 以毫秒为例可以表示292471208年
所以从实际开发的角度,我们一定要为合适的列选取合适的数据类型,即到底用不用得到这种数据类型?举个例子:
- 一个枚举字段明明只有0和1两个枚举值,选用TINYINT就足够了,但在开发场景下却使用了BIGINT,这就造成了资源浪费
- 简单计算一下,假使该数据表中有100W数据,那么总共浪费了700W字节也就是6.7M左右,如果更多的表这么做了,那么浪费的更多
要知道,MySQL本质上是一个存储,以Java为例,可以使用byte类型的地方使用了long类型问题不大,因为绝大多数的对象在程序中都是短命对象,方法执行完毕这块内存区域就被释放了,7个字节实际上不存在浪不浪费一说。但是MySQL作为一个存储,8字节的BIGINT放那儿就放那儿了,占据的空间是实实在在的。
最后举个例子:

1 drop table if exists test_tinyint; 2 create table test_tinyint ( 3 num tinyint 4 ) engine=innodb charset=utf8; 5 6 insert into test_tinyint values(-100); 7 insert into test_tinyint values(255);
执行第7行的代码时候报错"Out of range value for column 'num' at row 1",即很清楚的我们可以看到插入的数字范围越界了,这也同样反映出MySQL中整型默认是带符号的。
把第3行的num字段定义改为"num tinyint unsigned"第7的插入就不会报错了,但是第6行的插入-100又报错了,因为无符号整型是无法表示负数的。
整型(N)形式
在开发中,我们会碰到有些定义整型的写法是int(11),这种写法从我个人开发的角度看我认为是没有多大用,不过作为一个知识点做一下讲解吧。
int(N)我们只需要记住两点:
- 无论N等于多少,int永远占4个字节
- N表示的是显示宽度,不足的用0补足,超过的无视长度而直接显示整个数字,但这要整型设置了unsigned zerofill才有效
下面举个例子,写一段SQL:
drop table if exists test_int_width;
create table test_int_width (
a int(5),
b int(5) unsigned,
c int(5) unsigned zerofill,
d int(8) unsigned zerofill
) engine=innodb charset=utf8;
insert into test_int_width values(1, 1, 1, 1111111111);
select * from test_int_width;
从上面的两点,我们应该预期结果应该是1,1,00001,1111111111
我们看一下结果:
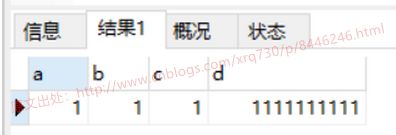
不符合预期是吧,因为这个问题我也有过困扰,后来查了一下貌似是Navicat工具本身的问题,我们使用控制台就不会有这个问题了:
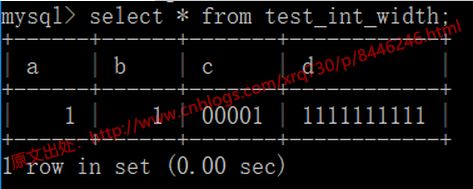
不过实际工作场景中反正我是没有碰到过指定zerofill的,也不知道具体应用场景,如果有使用这种写法的朋友可以留言告知具体在哪种场景下用到了这种写法。
浮点型
整型之后,下面是浮点型,在MySQL中浮点型有两种,分别为float、double,它们三者用一张表格总结一下:
| 数据类型 | 字节数 | 备注 |
| float | 4 | 单精度浮点型 |
| double | 8 | 双精度浮点型 |
下面还是用SQL来简单看一下float和double型数据,以float为例,double同理:
drop table if exists test_float;
create table test_float (
num float(5, 2)
) engine=innodb charset=utf8;
insert into test_float values(1.233);
insert into test_float values(1.237);
insert into test_float values(10.233);
insert into test_float values(100.233);
insert into test_float values(1000.233);
insert into test_float values(10000.233);
insert into test_float values(100000.233);
select * from test_float;
显示结果为:

从这个结果我们总结一下float(M,D)、double(M、D)的用法规则:
- D表示浮点型数据小数点之后的精度,假如超过D位则四舍五入,即1.233四舍五入为1.23,1.237四舍五入为1.24
- M表示浮点型数据总共的位数,D=2则表示总共支持五位,即小数点前只支持三位数,所以我们并没有看到1000.23、10000.233、100000.233这三条数据的插入,因为插入都报错了
当我们不指定M、D的时候,会按照实际的精度来处理。
定点型
介绍完float、double两种浮点型,我们介绍一下定点型的数据类型decimal类型,有了浮点型为什么我们还需要定点型?写一段SQL看一下就明白了:
drop table if exists test_decimal;
create table test_decimal (
float_num float(10, 2),
double_num double(20, 2),
decimal_num decimal(20, 2)
) engine=innodb charset=utf8;
insert into test_decimal values(1234567.66, 1234567899000000.66, 1234567899000000.66);
insert into test_decimal values(1234567.66, 12345678990000000.66, 12345678990000000.66);
运行结果为:

看到float、double类型存在精度丢失问题,即写入数据库的数据未必是插入数据库的数据,而decimal无论写入数据中的数据是多少,都不会存在精度丢失问题,这就是我们要引入decimal类型的原因,decimal类型常见于银行系统、互联网金融系统等对小数点后的数字比较敏感的系统中。
最后讲一下decimal和float/double的区别,个人总结主要体现在两点上:
- float/double在db中存储的是近似值,而decimal则是以字符串形式进行保存的
- decimal(M,D)的规则和float/double相同,但区别在float/double在不指定M、D时默认按照实际精度来处理而decimal在不指定M、D时默认为decimal(10, 0)
日期类型
接着我们看一下MySQL中的日期类型,MySQL支持五种形式的日期类型:date、time、year、datetime、timestamp,用一张表格总结一下这五种日期类型:
| 数据类型 | 字节数 | 格式 | 备注 |
| date | 3 | yyyy-MM-dd | 存储日期值 |
| time |
3 | HH:mm:ss | 存储时分秒 |
| year | 1 | yyyy | 存储年 |
| datetime | 8 | yyyy-MM-dd HH:mm:ss | 存储日期+时间 |
| timestamp | 4 | yyyy-MM-dd HH:mm:ss | 存储日期+时间,可作时间戳 |
下面我们还是用SQL来验证一下:
drop table if exists test_time;
create table test_time (
date_value date,
time_value time,
year_value year,
datetime_value datetime,
timestamp_value timestamp
) engine=innodb charset=utf8;
insert into test_time values(now(), now(), now(), now(), now());
看一下插入后的结果:

MySQL的时间类型的知识点比较简单,这里重点关注一下datetime与timestamp两种类型的区别:
- 上面列了,datetime占8个字节,timestamp占4个字节
- 由于大小的区别,datetime与timestamp能存储的时间范围也不同,datetime的存储范围为1000-01-01 00:00:00——9999-12-31 23:59:59,timestamp存储的时间范围为19700101080001——20380119111407
- datetime默认值为空,当插入的值为null时,该列的值就是null;timestamp默认值不为空,当插入的值为null的时候,mysql会取当前时间
- datetime存储的时间与时区无关,timestamp存储的时间及显示的时间都依赖于当前时区
在实际工作中,一张表往往我们会有两个默认字段,一个记录创建时间而另一个记录最新一次的更新时间,这种时候可以使用timestamp类型来实现:
create_time timestamp default current_timestamp comment "创建时间", update_time timestamp default current_timestamp on update current_timestamp comment "修改时间",
char和varchar类型
最后看一下常用到的字符型,说到MySQL字符型,我们最熟悉的应该就是char和varchar了,关于char和varchar的对比,我总结一下:
- char是固定长度字符串,其长度范围为0~255且与编码方式无关,无论字符实际长度是多少,都会按照指定长度存储,不够的用空格补足;varchar为可变长度字符串,在utf8编码的数据库中其长度范围为0~21844
- char实际占用的字节数即存储的字符所占用的字节数,varchar实际占用的字节数为存储的字符+1或+2或+3
- MySQL处理char类型数据时会将结尾的所有空格处理掉而varchar类型数据则不会
关于第一点、第二点,稍后专门开一个篇幅解释,关于第三点,写一下SQL验证一下:
drop table if exists test_string;
create table test_string (
char_value char(5),
varchar_value varchar(5)
) engine=innodb charset=utf8;
insert into test_string values('a', 'a');
insert into test_string values(' a', ' a');
insert into test_string values('a ', 'a ');
insert into test_string values(' a ', ' a ');
使用length函数来看一下结果:
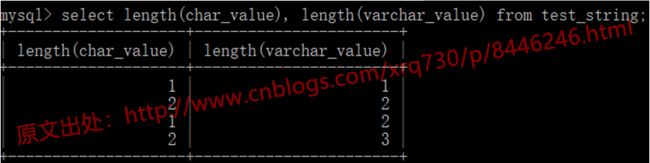
验证了我们的结论,char类型数据并不会取最后的空格。
varchar型数据占用空间大小及可容纳最大字符串限制探究
接上一部分,我们这部分来探究一下varchar型数据实际占用空间大小是如何计算的以及最大可容纳的字符串为多少,首先要给出一个结论:这部分和具体编码方式有关,且MySQL版本我现在使用的是5.7,当然5.0之后的都是可以的。
先写一段SQL创建表,utf8的编码格式:
drop table if exists test_varchar;
create table test_varchar (
varchar_value varchar(100000)
) engine=innodb charset=utf8;
执行报错:
Column length too big for column 'varchar_value' (max = 21845); use BLOB or TEXT instead
按照提示,我们把大小改为21845,执行依然报错:
Row size too large. The maximum row size for the used table type, not counting BLOBs, is 65535. This includes storage overhead, check the manual. You have to change some columns to TEXT or BLOBs
改为21844就不会有问题,因此在utf8编码下我们可以知道varchar(M),M最大=21844。那么gbk呢:
drop table if exists test_varchar;
create table test_varchar (
varchar_value varchar(100000)
) engine=innodb charset=gbk;
同样的报错:
Column length too big for column 'varchar_value' (max = 32767); use BLOB or TEXT instead
把大小改为32766,也是和utf8编码格式一样的报错:
Row size too large. The maximum row size for the used table type, not counting BLOBs, is 65535. This includes storage overhead, check the manual. You have to change some columns to TEXT or BLOBs
可见gbk的编码格式下,varchar(M)最大的M=32765,那么为什么会有这样的区别呢,分点详细解释一下:
- MySQL要求一个行的定义长度不能超过65535即64K
- 对于未指定varchar字段not null的表,会有1个字节专门表示该字段是否为null
- varchar(M),当M范围为0<=M<=255时会专门有一个字节记录varchar型字符串长度,当M>255时会专门有两个字节记录varchar型字符串的长度,把这一点和上一点结合,那么65535个字节实际可用的为65535-3=65532个字节
- 所有英文无论其编码方式,都占用1个字节,但对于gbk编码,一个汉字占两个字节,因此最大M=65532/2=32766;对于utf8编码,一个汉字占3个字节,因此最大M=65532/3=21844,上面的结论都成立
- 举一反三,对于utfmb4编码方式,1个字符最大可能占4个字节,那么varchar(M),M最大为65532/4=16383,可以自己验证一下
同样的,上面是表中只有varchar型数据的情况,如果表中同时存在int、double、char这些数据,需要把这些数据所占据的空间减去,才能计算varchar(M)型数据M最大等于多少。
varchar、text和blob
最后讲一讲text和blob两种数据类型,它们的设计初衷是为了存储大数据使用的,因为之前说了,MySql单行最大数据量为64K。
先说一下text,text和varchar是一组既有区别又有联系的数据类型,其联系在于当varchar(M)的M大于某些数值时,varchar会自动转为text:
- M>255时转为tinytext
- M>500时转为text
- M>20000时转为mediumtext
所以过大的内容varchar和text没有区别,同事varchar(M)和text的区别在于:
- 单行64K即65535字节的空间,varchar只能用63352/65533个字节,但是text可以65535个字节全部用起来
- text可以指定text(M),但是M无论等于多少都没有影响
- text不允许有默认值,varchar允许有默认值
varchar和text两种数据类型,使用建议是能用varchar就用varchar而不用text(存储效率高),varchar(M)的M有长度限制,之前说过,如果大于限制,可以使用mediumtext(16M)或者longtext(4G)。
至于text和blob,简单过一下就是text存储的是字符串而blob存储的是二进制字符串,简单说blob是用于存储例如图片、音视频这种文件的二进制数据的。
原文:https://www.cnblogs.com/xrq730/p/8446246.html