在语音通信中Jitter Buffer(下面简称JB)是接收侧一个非常重要的模块,它是决定音质的重要因素之一。一方面它会把收到的乱序的语音包排好序放在buffer里正确的位置上,另一方面它把接收到的语音包放在buffer中缓冲一些时间使播放的更平滑从而获得更好的语音质量。下图是JB在接收侧软件框图中的位置。

从上图可以看出,从网络上收到的语音包会放在JB里(这个操作叫做PUT),在需要的时候便从JB里取出来(这个操作叫做GET)解码直到播放出来。JB有两种模式:adaptive(自适应的)和fixed(固定的)。Adaptive是指buffer的大小可以根据网络环境的状况自适应的调整;fixed是指buffer的大小固定不变。自适应的模式实现难度大,要求高,fixed相对简单,现在基本上都用adaptive的模式。JB在生命周期里也有两种状态:prefetching(预存取)和processing(处理中),只有在processing时才能从JB中取到语音帧。初始化时把状态置成prefetching,当在JB中的语音包个数达到指定的值时便把状态切到processing。如果从JB里取不到语音帧了,它将又回到prefetching。等buffer里语音包个数达到指定值时又重新回到processing状态。
首先看PUT操作。RTP包有包头和负载(payload),为了便于处理,将包头和payload在buffer中分开保存,保存包头中相关属性的叫attribute buffer,保存payload的叫payload buffer。下图是JB里存RTP包的buffer关系图:
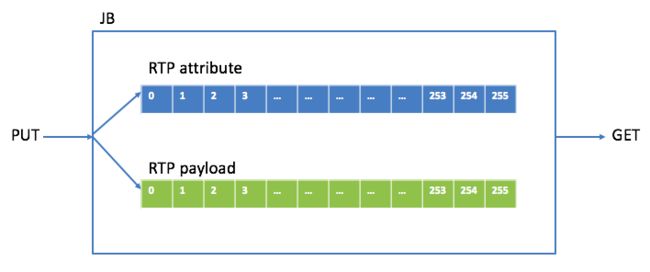
要明确哪几种类型的RTP包会被PUT进JB,我最初设计JB时类型有G711/G722/G729/SID(静音包)/RFC2833(DTMF包)。G711/G722十毫秒payload是80个字节,G729十毫秒payload是10个字节,当VAD使能时十毫秒payload是2个字节(G729 VAD是内置的)或0个字节(DTX),一个SID包payload是1个或11个字节,一个RFC2833包payload是4个字节,明确这些是为了确定payload buffer中一个block的大小(取这些类型中最大的,80个字节),attribute buffer中一个block的大小是固定的,即要保存的属性的个数(这些属性主要用于控制payload的存放和读取,有media type(G711/G722/G729/SID/RFC2833),sequence number,timestamp,ssrc,payload size,相对应的存放payload的buffer block指针等。每个RTP的包头占一个attribute buffer block,但每个RTP的payload有可能占几个payload buffer block,这跟media type 和packet time有关,例如一个packet time为20ms的G711包,就需要两个payload buffer block,attribute buffer block和payload buffer block之间有一个映射关系。将attribute buffer block和payload buffer block个数都定为256(index从0到255,设定256是为了早到的包绝不会把前面的包给覆盖掉,如果block个数小了则有可能),这样JB 里最少可以存2560ms的语音数据。
至于JB里最多能放多少个包(即容量capacity),这取决于media type和packet time。如果media type是G711/G722, capacity = 256*10/packet time,例如当packet time为20ms时,capacity是128,即最多放128个包。这样attribute buffer和payload buffer的映射关系如下图:
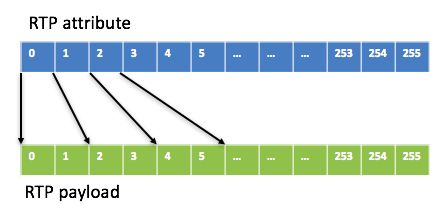
如果media type是G729,考虑到packet time 通常不会超过160ms, 就设定一个G7299包的payload占2个block(160个字节,一般是存不满的),这样capacity就是128(256/2)。至于SID和RFC2833包,payload只有几个字节,为了处理简单,它们的payload占几个block是跟着语音包走的,比如一个20ms的G711语音包payload占2个block,SID包和RFC2833包的payload也会占2个block。
从网络上来的RTP包有可能是乱序的,PUT操作要把这些乱序的包(attribute & payload)放在buffer里正确的block里,这主要依靠attribute里的sequence number和timestamp做判断。RTP协议里sequence number数据类型是unsigned short,范围是0~65535,就存在从65535到0的转换,这增加了复杂度。对于收到的RTP包,首先要看它是否来的太迟(相对于上一个已经取出的包),太迟了就要把这个包主动丢弃掉。设上一个已经取出的包的sequence number为 last_got_senq,timestamp 为last_got_timestamp,当前收到的将要放的包的sequence number为 cur_senq,timestamp 为cur_timestamp,当前包的sequence number与上一个取走的sequence number的gap为delta_senq,则delta_senq可以根据下面的逻辑关系得到。

如果delta_senq小于1,就可以认为这个包来的太迟,就要主动丢弃掉。由于我们的buffer足够大(256个block),如果包早到了也会被放到对应的position上,不会把相应位置上的还没取走的覆盖掉。
接下来看怎么把包放到正确的位置上。对于收到的第一个包,它的位置(position,范围是0 ~ capacity-1)是sequence number % capacity。后面的包放的position依赖于它上一个已放好的包的position。设上一个已放好的包的sequence number为 last_put_senq,timestamp 为last_put_timestamp,position为last_put_position,当前收到的将要放的包的sequence number为 cur_senq,timestamp 为cur_timestamp,position为cur_position,当前的包的sequence number与上一个放好的sequence number的gap为delta_senq,则cur_position可以根据下面的逻辑关系得到。

得到了当前包的position后就可以把包头里的timestamp等放到相应的attribute buffer block里了,payload根据算好的占几个block放到相应的那几个block上(有可能填不满block,不过没关系,取payload时是根据index取的)。如果放进对应block时发现里面已经有包了并且sequence number一样,说明这个包是重复包,就要把这个包主动丢弃掉。
再来看GET操作。每次从JB里不是取一个包,而是取1帧(能编解码的最小单位,通常是10ms,也有例外,比如AMR-WB是20ms),这主要是因为播放loop是10ms一次(每次都是取一帧语音数据播放)。取时总是从head上取,开始时head为第一个放进JB的包的position,每取完一个包(几帧)后head就会向后移一个位置。如果到某个位置时它的block里没有包,就说明这个包丢了,这时取出的就是payload大小就是0,告诉后续的decoder要做PLC。不同类型的包取法不一样,下面分别加以介绍。
对于G711/G722,每次从payload buffer里取10ms数据(一个block, 80个字节),一个包取完后取下一个包。对于G729,每次从payload buffer里取10ms数据(10个字节或2个字节(VAD使能后的静音payload)或0个字节(DTX)),一个包取完后取下一个包。至于VAD使能后取10个字节还是2个字节还是0个字节,要取决于当前包以及上一包的payload size。这处理好能显著提高G7229 VAD使能场景下的语音质量MOS值。以packet time为20ms为例,如果上一个包的payload size是20个字节,当前包的payload size是12个字节,在取时前10ms取10个字节,后10ms取2个字节。如果上一个包的payload size是12个字节,当前包的payload size是10个字节,在取时前10ms取0个字节(DTX),后10ms取10个字节。
对于SID包,每次都是从当前包中取相同的payload一直到发现JB里这个SID包后面又有包并且timestamp又大于等于这个包的timestamp,下一次就会从这个新包里取payload。对于RFC2833包,包里有个duration attribute,当前RFC2833包和上一个RFC2833包的duration相减再除以80就是当前包的packet time,根据这算是从这个包里取得次数,次数到后就从下一个包取。
上面说过现在JB一般都是用adaptive的mode,即buffer size(缓存包的个数)根据网络环境自适应的调整大小。那怎么来实现呢?JB初始化时会设定一个缓存包的个数值(叫prefetch),并处于prefetching状态,这种状态下是取不到语音帧的。JB里缓存包的个数到达设定的值后就会变成processing状态,同时可以从JB里取语音帧了。在通话过程中由于网络环境变得恶劣,GET的次数比PUT的次数多,GET完最后一帧就进入prefetching状态。当再有包PUT进JB时,先看前面共有多少次连续的GET,从而增大prefetch值,即增大buffer size的大小。如果网络变得稳定了,GET和PUT就会交替出现,当交替出现的次数达到一定值时,就会减小prefetch值,即减小buffer size的大小,交替的次数更多时再继续减小prefetch值。
再来看一下在哪些情况下需要reset JB,让JB在初始状态下开始运行。
1)当收到的语音包的媒体类型(G711/G722/G729,不包括SID/RFC2833等)变了,就认为来了新的stream,需要reset JB。
2)当收到的语音包的SSRC变了,就认为来了新的stream,需要reset JB。
3)当收到的语音包的packet time变了,就认为来了新的stream,需要reset JB。
前面说过JB是语音通信接收侧最重要的模块之一,当然它也是容易出问题的模块之一。出问题不怕,关键是怎么快速定位问题。对于JB来说,需要知道当前的运行状态以及一些统计信息等。如果这些信息正常,就说明问题很大可能不是由JB引起的,不正常则说明有很大的可能性。这些信息主要如下:
1)JB当前运行状态:prefetching / processing
2)JB里有多少个缓存的包
3)从JB中取帧的head的位置
4)缓冲区的capacity是多少
5)网络丢包的个数
6)由于来的太迟而被主动丢弃的包的个数
7)由于JB里已有这个包而被主动丢弃的包的个数
8)进prefetching状态的次数(除了第一次)
上面就是JB设计的主要思想,在实现时还有很多细节需要注意,这里就不一一详细说了。我第一次设计实现JB是在2011年,当时从设计实现到调试完成(指标是:bulk call > 10000次,long call time > 60 小时,各种场景下的各种codec的语音质量要达标)总共花了近三个月,还是在对JB有基础的情况下,要是没基础花的时间更多。从设计到能打电话时间不长,主要是后面要过bulk call/long call/voice quality。有好多情况设计时没考虑到,这也是一个迭代的过程,当调试完成了设计也更完整了。最初设计时只支持G711/G722/G729这三种codec,但是机制定了。后来系统要支持AMR-WB,JB这部分根据现有的机制再加上AMR-WB特有的很快就调好了。