
最近一直在研究区块链,算是从以前听说过,到现在大概了解一些。先说下自己学习过程中的感受,那就是“干!能不能把话说明白些。”大部分学习材料都存在结构混乱,或者对一个点单薄,无法深入浅出。至于那些还在拿着露天麦喊什么是区块链,错过后悔一辈子的,都是骗子。
我相信现在很多投资机构都在瞄区块链,今年,即使AI也没有区块链这么火爆。那么对于一个区块链项目,到底靠不靠谱,是在画饼,还是真的可能搞成,所有人都应该擦亮眼睛。
1
三个最底层的技术
谈区块链最好先抛开各种币的价格,价格这种事你懂的,贵和便宜根本不是人能控制的。但是基于区块链技术去做项目,却是实实在在可以可持续发展。所以,了解区块链技术比炒币来的实在。
“区块链”三个字并不能阐明这项技术的全部,如果要非要用可以完整表达的命名,我觉得应该叫“Peer-to-Peer Encrypted Non-Tampered Database”,即“点对点的加密化不可篡改数据库”。
它不一个数据库(比如MySQL,MongoDB),也不是一类数据库(比如SQL,NoSQL),它是一种数据库架构,它在数据库本身的技术上还上升了一层,考虑到数据的可靠性如何保证,以及数据库服务如何不下线。因此,你不能把它跟普通的某个有名字数据库拿来类比,甚至,你可以在某一个具体的区块链实现时,使用其他的数据库来帮助存储和检索数据。
2
数据关系加密化
在我们普通的数据库中,无论是关系型还是非关系型,我们的不同记录之间可能存在关系,也可能不存在关系,但在区块链中,一条数据一定和另外一条数据存在联系,即使在现实的业务逻辑上没有联系,但是它总是存在于链上,无法脱离链而存在,总有一条路径从一个数据出发到达另外一个数据,不信往下读。
“区块”表达了区块链里面数据关系的最终呈现形式,一条记录,无论它是什么信息,最终它(或它的检索信息)都要被放置在一个区块中。而区块与区块之间,是一个“链表”的数据关系,会编程的人都知道什么是链表,就是后一个数据中存在指向前一个数据的索引键。因此,区块链上的任何两个数据永远可以通过这些索引键最终连在一起,数据无法逃离这个逻辑。
但是“区块链”这三个字无法阐述这样的数据结构和普通数据库结构之间的不同,因为上面描述的的这种链表数据结构,用普通的数据库也可以构建出来,只要你想要的话。
真正的价值在于,区块链用密码学的原理,现有的加密技术,把这些索引关系进行了层层加密,以至于在保存的数据中,这些索引键并没有那么明显,而是需要通过各种计算才能得到。比如区块在保存一堆交易信息时,采用了merkle树的方式进行保存,父节点是两个子节点的double hash得到的结果,而merkle算法确保了交易信息不能被篡改。
我们这里还不需要知道具体的加密都有什么用,我们需要了解的是,区块链里面到处是加密,这是一个显著的特点。
3
数据不可篡改
区块链上的数据是不可篡改的,大家都这样说。但其实,数据是可以改的,只是说改了以后就你自己认,而且被修改数据所在区块之后的所有区块都会失效。区块链网络有一个同步逻辑,整个区块链网络总是保持所有节点使用最长的链,那么你修改完之后,一联网同步,修改的东西又会被覆盖。这是不可篡改的一个方面。
更有意思的是,区块链通过加密校验,保证了数据存取需要经过严格的验证,而这些验证几乎又是不可伪造的,所以也很难篡改。加密并不代表不可篡改,但不可篡改是通过加密以及经济学原理搭配实现的。这还有点玄学的味道,一个纯技术实现的东西,还要靠理论来维持。但事实就是这样。这就是传说中的挖矿。
挖矿过程其实是矿工争取创建一个区块的过程,一旦挖到矿,也就代表这个矿工有资格创建新区块。怎么算挖到矿呢?通过一系列复杂的加密算法,从0开始到∞,找到一个满足难度的hash值,得到这个值,就是挖到矿。这个算法过程被称为“共识机制”,也就是通过什么形式来决定谁拥有记账权,共识机制有很多种,区块链采用哪种共识机制最佳,完全是由区块链的实际目的结合经济学道理来选择。
挖完矿没完,拿比特币来说,接下来矿工要把被广播到网络中的交易打包到这个区块里,一笔交易是不是合法的呢?发起这笔交易的人是不是伪造了一笔交易?要确保一笔交易的合法性,必须从已经存在的前面的区块里面去找到这笔交易的来源的真实性,而如何验证交易真实性呢?在前面的区块里,保存着交易来源的merkle root hash,只要找出这个交易所在的区块,再做一次merkle校验,就可以判定交易是否是合法的。得到merkle root hash是通过区块内的所有交易不断加密得到的,因此,只要交易是假的,就得不到这个merkle root hash。加密在这里又帮助实现了数据的可靠性。
除了这些,区块链里面的加密比比皆是,这些加密规则和算法,使得整个区块链遵循一种规律,让篡改数据的成本特别高,以至于参与的人对篡改数据都没有兴趣,甚至忌惮。这又是玄学的地方。
4
点对点网络让数据永不下线
如果区块链没有p2p网络,仅仅是按照前面的描述,有加密体系,有链式特征,然后运行在某一台(组)服务器上,按照我们现在中心化的模式运行,看上去也挺好玩的。但是发明者想玩的更大些,加密体系让数据不可篡改,但是我直接抛颗原子弹把你机房炸掉,不是不可篡改,是直接玩儿完了。
为了防止被原子弹炸掉机房,发明者设计了点对点的网络(客户端和客户端直接通信,不经过某一台特定的服务器)到区块链里面。简单说就是在这个点对点网络里面,所有人的电脑里保管着一模一样的一个数据结构(其实就是一个完整的“区块”“链”),他们相互通过网络连接,进行同步,当矿工创建了新的区块,其他人就会把这个区块同步到自己保管的数据结构中。因此,无论这个网络上哪一个节点被炸,其他节点都还活着,新加入的小伙伴就可以从这些节点里同步数据到自己的电脑。想要让区块链数据消失,那把地球炸了吧。
而这种加入点对点网络的设计,就叫“去中心化”,只要网络上还有一个节点活着,区块链的数据就不会消失。
更让政客们害怕的是,这些保存的数据,节点上的用户可以随便看,无所谓,完全公开。节点用户既然把数据同步过来了,你就可以随便用,就是你的数据了,想怎么用就怎么用。试想一下,哪天淘宝说我要把自己的数据区块链化……目不忍视……
5
核心技术概念
前面仅仅阐述的是区块链之所以是区块链的基础。本节要讲的是,现在已经有区块链在你面前了,我们需要去剖析区块链里面所使用的具体技术点或架构。
区块
前面已经提到区块了。那么到底什么是区块呢?区块是区块链的主要数据存储结构,一个区块包含区块头和区块体两个部分。而区块头则是区块的重头戏。

区块链中的一个区块结构示意图
(注:漏掉了version信息)
对于一个区块而言,它就是一个特殊的数据结构。它的区块头包含了一些固定信息:版本(客户端版本,每次升级客户端软件,这个信息就会不一样),块高度(其实就是表示这是链中的第几个区块),块哈希(这个区块的hash值,是挖矿得到的),上一个块的块哈希(这个字段是重点中的重点,是形成链表结构的关键),时间戳(区块创建时间),难度和Nonce(这两个字段和挖矿有关,后文讲挖矿的时候详细讲),merkle root(区块体的merkle根hash值,后文会简单介绍merkle树,详细会在其他文章讲)。除了这些字段,如果做一个自己的区块链,还可以添加一些其他信息到区块头中。
区块体是保存具体内容的位置,在比特币的区块链中,区块体保存的是一段时间的交易信息。在其他区块链中,这里可不一定保存的是交易信息,可能是其他信息,总之区块体是保存该区块链用来做什么业务的具体业务信息。
在部分区块链实现中,一个区块还可以有区块尾,用来保存一些区块创建结束之后的信息,这些信息可能是区块头和区块体已经创建完以后,附加上去的,比如区块的长度、容量等信息。
这就是一个区块。而一个区块头中的previousHash字段,保存的是上一个区块的hash值,因此,通过这个区块就知道了上一个区块是哪个,上一个区块又能知道上上个区块,直到可以追溯回整个链条的第一个区块。这就是区块链。

区块是如何构成链的的示意图
就像上图一样,后面一个区块总是指向前一个区块。一旦一个区块生成,并且后面有区块指向它,那它就不能被修改,因为一旦修改,所有的hash都需要重新计算。但是我们知道,hash算法的特点是,想要得到这个hash必须用原始内容进行一遍hash算法,所以,如果给的内容和原始内容不同,是得不到这个hash的,所以,中间某个区块链被修改而得到的hash,不可能被后面的区块指向,区块链就会断掉。断掉的区块链加入到网络中,要么不被认可,别的节点不会把你当作合法节点,要么你要再同步一遍,从网络中重新复制最长的链到你的本机覆盖原来的链。
但是你可能会有两个疑问:
这个blockHash又不是内容的hash,怎么确保区块体内的信息不被修改呢?要是我不改blockHash,只改内容,那不是可以瞒天过海?
如果有两个区块同时指向了一个区块,而这两个区块的区块体不一样,这该怎么办?
第一个问题,我们需要通过后面的挖矿和merkle tree两部分结合,知道这个原理。
第二个问题,实际上,这种情况非常常见,挖矿成功的概率其实是100%,关键在于哪一位矿工先挖到矿,一般当矿工挖到矿之后,会向全网广播,其他没有挖到矿的矿工就会停止。但是由于网络延时等情况,可能在短时间内多个矿工一起挖到矿,他们都创建了新的区块,并且广播到了网络中。这种情况叫“分叉”。
当分叉发生的时候,有两种办法。但都是顺其自然,不人工干预。后面挖新块的矿工,会自己决定把哪一个分支最后的块作为自己的前一个块。如果在比较短的块数内,一条链明显长于另外一条链,那么长的链会被保留,短的会被抛弃,挖短链的矿工算是白干了一场。所有的网络节点在同步的时候,都会选择当前最长的链进行同步,后面挖矿的矿工创建新块的时候也是选择最长的链。
但是还有一种情况,就是短链的矿工不依不饶,或者短时间内两条链无法分出胜负,甚至最后每条链都有了很多块跟在后面。一帮人的转账总不能有两个账单吧,如果两个账单最后发现还不一样就麻烦了。所以遇到这种情况,矿工们会决定分家。也就是一个区块链变成了两个链,其中一条链把前面的所有链复制出来,成为独立的链,从此这两条链再无瓜葛,虽然前面的区块都是一摸一样的,但是后面井水不犯河水。这种情况叫“硬分叉”,BitCoin Cash就是这样诞生的。新产生的链继承了前面的区块,但是后面的区块完全是挖这条链的矿工决定的。硬分叉的好处是,对于原来的用户而言,突然之间,自己的一份资产变成了两份。
至于区块体,真的是根据区块链应用的业务需求来设计。比如比特币,就被设计为交易模型,所有区块体里面的交易记录放在一起,就是一个长长的账单,每一分钱的来龙去脉写的一清二楚,如果当初红十字会用区块链来捐款,那就不会有那么大的风波。但是其他区块链应用不一定是交易模型,比如用于记录医疗信息的区块链,用于记录用户位置的区块链……所以,对于区块链技术本身而言,点到这里即止,再往下说就是比特币特有的技术了。
挖矿和共识机制
前面已经多次说了挖矿。简单说挖矿过程就是一堆矿工在抢创建一个新区块的权利的过程。在加密货币的世界里,抢到这个权利,就会在这个区块的最前面加上一笔转账给自己的交易,而这个交易的钱是凭空而来的,所以又叫“挖矿奖励”,而且数额还不少,所以矿工才挤破脑袋抢这一个记账权。但是在其他非币区块链应用里,假如没有这个奖励,怎么激励矿工挖矿呢?这也是区块链领域里一个玄而又玄的话题,至今没有答案。
那么挖矿,到底是怎么一个技术上的算法过程呢?
在矿机程序里,规定了如何得到一个hash,而这个规定,就被称为共识机制,所有矿工按照这个共识机制去进行某个算法,看谁先得到一个符合条件的结果,而这个结果又可以被轻而易举的验证是符合条件的(验证是否符合共识机制)。不同的区块链,共识机制不同,目前比较知名的是PoW和PoS,以及在这两者基础上衍生出来的其他共识机制。
为了能够把挖矿过程讲清楚,我们只拿比特币遵循的PoW来进行演示。
SHA256(SHA256(version + prevHash + merkleRoot + time + currentDifficulty + nonce )) < TARGET
矿机执行上面公式,只要满足上面这个公式(执行结果为真),就算挖到矿。现在对这个公式进行解释。
矿机会做一个double sha256的运算,运算的参数其实全部是块头里面的信息,但是因为这个时候区块还没有生成,所以这些信息是暂时保存的,如果抢到记账权,就把这些信息记录进去
version是当前运行矿机的客户端软件版本,每次版本升级,可能对一些参数会有影响,比如区块大小从1M扩容到2M,但是对于挖矿算法而言是不变的
prevHash是前一个区块的hash值
merkleRoot是当前矿机内存里暂存的交易的merkle算法得到的根hash,merkle会在下文讲
time是当前时间戳
currentDifficulty是当前难度,这个当前难度是由一个公式算出来的,这个公式是 currentDifficulty = diff_1_target/TARGET 这个公式里面的diff_1_target可以认为是一个常量,在比特币客户端里面是不变的,值为0x1d00ffff。当然,其实它也有可能变,但怎么变都差不多这个值,我们还是把它当作常量。而TARGET我们在下面会讲到。
nonce是一个正整数,nonce的值就算矿机要找的值。当矿机开始执行double sha256算法时,nonce为0,如果执行完一次,无法满足上面那个公式,那么nonce就自加1,再执行一遍算法,如果不满足公式,继续加1再执行,就是这样一直加上去,直到找到一个nonce满足上面的公式,就算挖到矿。所以,这个nonce每一次挖矿都可能不一样,它是完全随机出现的,到底是多少完全看运气。但不管怎样,你看每个区块里面但nonce值,就知道矿机做了多少次运算,也就知道挖到矿有多难了。
TARGET是用以对比的目标值,它是一个特定值,比特币的发明者希望10分钟产生一个区块,所以最初设计的TARGET就是为了让currentDifficulty能够到一个合适的值,保证10分钟一个块。但是实际情况并不可能保证10分钟一定出一个块,如果算力下降,时间就会加长,这时就应该调整一下难度,使出块时间尽可能恢复在10分钟左右。所以2016个区块(2周)TARGET就会调整一次,而如果真实的情况是产生2016个区块的时间超过2周,那么TARGET就会适当增加,从而使currentDifficulty减小,下面2016个区块的难度就会降低一些。相反,则提高难度。这个调整算法本文就不展开了。所以TARGET是一个2016次不变,但总体而言一直在变的值,它的目标就是让产生一个区块的时间大概在10分钟左右。
这就算比特币的挖矿,矿工们每天看着自己的机器,反复不断的执行这个公式,寻找那个nonce,日复一日,年复一年。
当矿机找到nonce之后,就夺得了记账权,就可以把内存中的交易信息调出来,打包到区块体中。而merkle root是通过交易记录计算得到的,所以不可能矿工在打包时又去做手脚,一旦他伪造了某一条交易,打包进区块体的交易就不能得到他挖矿时使用的那个merkle root,也就无法得到挖矿时找到的那个hash。
当然了,实际上比特币挖矿可能还要麻烦一些,比如说还有nonce溢出、矿池……
Merkle Tree
前面说了好多次Merkle,它到底是什么?Merkle Tree是一种数据结构,比特币里面就是一棵二叉树,也就是每个父节点有两个子节点那种。我之前写过一篇文章《区块链如何运用merkle tree验证交易真实性》里面详细讲了一些Merkle Tree的原理以及问题。这里主要还是做一个科普,不深入讲。
区块头里面的Merkle Root是怎么来的呢?它是通过对区块体内的记录做Merkle算法得到的。以比特币为例,一个区块里面包含n个交易,我们把这些交易两两分组,每两个一组,得到n/2组,如果有单数,那么最后一个交易复制一份凑数。先对每个交易做hash提取,这样就得到来n个hash,然后对每组的hash做double hash运算:
parentHash = sha256(sha256( hash1 + hash2 ))
也就是把这个组里的两个hash连起来,再计算得到一个新hash,这个新hash就算这两个hash的父节点。得到所有组的父节点之后,按照同样的逻辑,得到父父节点,如此一直下去,最后得到一个根节点,这个根节点就是merkle root。
merkle算法大致是这样,但它不仅限于区块链领域,在其他任何验证领域都可能用到,而且也不一定是这里讲的必须两个得到一个的算法,也可以是任意个得到一个的算法,总之merkle是一种对多个记录进行运算得到一个根hash的算法。
而可以想象,对参与算法的任何一个交易做小小的改动,都会导致得到的merkle root不一样,所以区块里面只需要保存merkle root就可以了。这就算密码学的力量。
6
区块链适合什么不适合什么
区块链数据的特征主要有两点:
公开透明,任何节点对数据有完全的权利去查看;
难以伪造或篡改。
因此,区块链非常适合两类场景:证据;监督。
如果区块链上的信息得到法律认可,那么但凡拿出区块链上的证据,侵权方将百口莫辩。而试想,如果将税收完全迁移到区块链,每个公民的每一笔税收,最后都用到哪里,一清二楚,这可能是令某些人害怕的点。
但区块链有两大缺点:
要挖矿,还有分叉风险,也就是说一个数据放到区块链上,要等很久才能成为不可篡改的可信数据。
分区块,数据被割裂存放,这给查询带来巨大的麻烦,非常影响效率。
所以,区块链不适合那种即时性要求高的场景,无论是信息交换的即时性(例如聊天)还是查询的即时性(如搜索引擎)。
区块链不是万能的,某些服务明明中心化模式效率更高,成本更低,却偏要为了风口搞区块链化,那只能看韭菜长没长齐。还有一点令人担心的是,由于区块链上信息的公开透明,而且不可删除,是否会对个人隐私造成极大的损害,试想一下,当年给冠希哥修电脑的小哥通过区块链网络炫耀自己发现的照片……那对当事人的伤害……连人死了都不会消散……
7
区块链应用
随着风口的来临,区块链应用此起彼伏。但目前比较成熟的,无非三种模式:1.比特币;2.以太坊智能合约;3.比特股。其他的,不多说,读者自己看着办。
一个区块链应用,它的架构是怎样的呢?在区块链本身之上,还需要有哪些其他的技术来支撑呢?
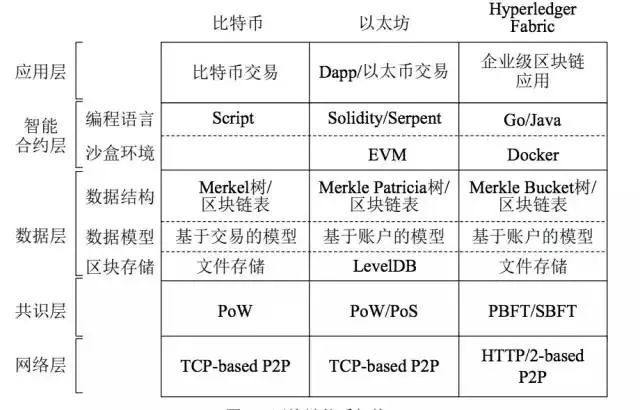
区块链应用体系架构图
(邵奇峰等《区块链技术:架构及进展》)
区块链应用,如比特币、以太坊,与区块链本身有比较大的耦合度,也就是说区块链作为数据库无法较为独立的成为应用中的一个模块,和我们现在流行的B/S架构稍有不同,区块链应用中会把区块链拆解之后,于应用其他层进行融合,最终实现应用的整体功能。
我们以比特币为例来讲一个区块链应用,比单纯一个区块链本身多了哪些部分。比特币是一个基于区块链的账单系统,它除了区块链,还要包含:
交易模型;
身份认证体系(类似PKI);
智能合约。
交易模型
交易模型就是区块体内保存的交易记录。之所以比特币里面的每一笔钱的来龙去脉都一清二楚,就是依赖于交易模型。我们现实中银行里面的一个账号,只会告诉你一个账号现在有多少钱,曾经花了多少钱,收入多少钱,还欠多少钱。但是不会告诉你“某一笔你花掉的钱,来自你某一笔收入”。
但比特币里面必须告诉你这样的逻辑,一条交易包含“输入”和“输出”两个部分,比如你要转10BTC,那么你的账号必须有一个或多个“输入”加起来总和等于或超过10BTC,而输出就是指你要把这10BTC转给谁。但是有一种情况,当所有“输入”加起来为10.5BTC时怎么办,就像你有100块毛爷爷,去买70块的东西一样,需要“找零”。所以“输出”有的时候会有一个是转给自己的,就是“找零”。
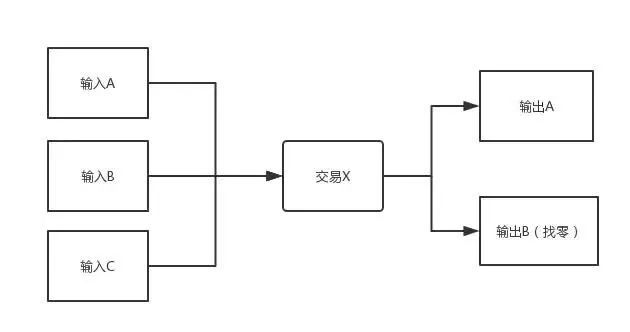
比特币交易输入与输出示意图
而实际上,输出在另外一个交易中,又是这个新交易的输入。
在区块体里面,这些交易记录,以及它们的输入输出都被如实记录。除此之外,还要进行merkle计算,将merkle root存到区块头中。
身份认证体系
既然是交易,那么必然涉及到交易双方的身份。比特币交易的两端是两个账号,至于到底是谁它不管,但它通过加密算法,保证这一笔交易是哪一个账号发起的,发起交易的人要对交易信息进行签名。
你可能听过非对称加密、公钥和私钥。比特币账号最关键的就是这个私钥,一旦私钥丢失,你就无法证明自己是这个账号的主人,也就无法从账号中进行转账要做的签名动作,你就不能再花这个账号里面的币,也就丢失了币。
那么签名是怎样的一个过程?怎么证明这个交易是我发出的?怎么证明这钱是转给我的?
密钥、地址与钱包
密钥通常指的是保护比特币资产的对应于所有权用户的私钥,个别时候也会模糊的统称私钥和公钥为密钥,这里我们以狭义的私钥解释为准。
地址 比特币的收款地址,大部分情况下是指对公钥的封装(个别时候除了公钥还有脚本)。
钱包 一种比特币客户端软件,是私钥的容器,通常通过有序文件或者简单的数据库实现。比特币钱包包含私钥和公钥数据,尽管公钥数据理论是是不需要存储的。
一般来说,用户的公钥和比特币地址可以划等号,但实际上不是。比特币地址是一串比公钥短很多的字符串,主要是为了方便输入。而公钥则用于各种非对称加密。

比特币公钥到比特币地址
公钥和地址都是公开在比特币网络中的,只有私钥是用户自己保存,不能给任何人。当一个交易发起时,交易发起方用“自己的私钥”和“接收方公钥”对交易进行签名,那么网络中的其他人就可以用发起人的公钥去验证这个交易是不是他发起的,对于接收方而言,要提供自己的私钥进行解密运算,来证明这个交易确实是发送给自己的。而比特币客户端(钱包)就是干这个加密解密和签名的事。
智能合约
比特币本身已经有智能合约的雏形,只是它所采用的编程语言脚本能力比较弱,能实现的合约逻辑不复杂。以太坊则是在这个基础上扩展链智能合约部分,使智能合约的编程能力大大增强。
在上文提到的输入和输出,输出其实就被作为另外一个新交易的输入。比特币的输出不单单是告诉系统要转给哪个地址多少钱,输出实际上是一段比特币脚本。这段脚本也经过复杂的非对称加密,要运行这段,想要得到一个输出里面的钱,把这笔钱作为自己交易的输入,必须用自己的私钥先解密脚本,然后运行脚本,脚本运行完,这笔钱就可以作为自己交易的输入了。结合前面的知识,只有拥有对应的私钥才能解密,所以,只有输出记录对应的比特币地址对应的那个用户才能解密脚本,得到这些钱。
在这个过程里面,“脚本”是一个关键,除了上面这种最简单的转账逻辑,还可以通过一些条件判断来实现稍微复杂一些的编程,比如只有当满足某些条件的时候,解密后的脚本才能运行。于是,基于这种设计,比特币的脚本系统可以用来实现多重签名、保证合同等功能,也就是智能合约的雏形。
8
结 语
对于区块链的研究,我也是刚刚开始,必定有不少地方没有理解透,有些地方也有误解。但对于想要了解这个领域的朋友,希望你们先了解区块链背后的技术原理(不必对技术细节掌握透彻),读一些比较成熟的可信的材料(我一不小心发现前人已经在《计算机学报》上发表类似综述的文章了,读者可以阅读《区块链技术:架构及进展》),而不是道听途说就信以为真。一旦你掌握了这些技术原理,就会发现,其实它的限制挺多,有美好的地方,也有没必要的地方,那些莫名奇妙的项目就坑不到你了。
【区块链100讲】系列将在周一-周五每天讲述一个区块链的知识点,上期我们用最简单的例子讲述了什么是区块链。
本文内容来源于公众号:区块链兄弟
作者:否子戈 原文发布于:否子戈博客
原文标题:区块链不谈技术的都是韭菜——区块链技术组成及架构
活动推荐
主题:Blockathon,挑战区块链开发,敢不敢来!(点击了解详情)
5月25-27日,Blockathon2018北京站,招募100名开发者一起挑战区块链开发。
开发者免费,报名需审核。识别下图二维码或点击“阅读原文”即可报名参加。

点击“阅读原文”即可报名。