关键词:DMA、sync、async、SIGIO、F_SETSIG。
DMA本身用于减轻CPU负担,进行CPU off-load搬运工作。
在DMA驱动内部实现有同步和异步模式,异步模式使用dma_async_issue_pending(),然后在callback()中发送SIGIO信号,用户空间收到SIGIO进行handler处理视为一个周期完成。
同步模式,采用dma_sync_wait()进行等待,期间并没有释放CPU给其他进程使用。
在一个项目中,发现DMA相关占用率高的问题,后来发现是因为其使用了同步模式。然后,将其改成异步模式,并对其进行详细的分析,记录如下。
那么当初为什么没有使用async IO模式呢?
原来是因为同一进程中其他线程也是用了async IO设备,由于kill_fasync()发送SIGIO信号,在一个进程内无法多个handler。
权宜措施使用了同步DMA,造成占用率高。
然后通过fcntl(fd, F_SETSIG, sig);解决了kill_fasync()发送相同SIGIO信号的冲突问题。
1. 问题发现:DMA同步模式占用率高
抓数据命令:
perf record -a -e cpu-clock -- sleep 60 perf report perf report -s comm
不同数据量,不同CMA处理方式下的top和perf结果:
| Item | 1 cma | per cma | ||
| top | perf | top | perf | |
| 4K 25fps | 15% | 84.43% swapper [kernel.kallsyms] [k] __sched_text_end 11.51% main [kernel.kallsyms] [k] dma_cookie_status 2.81% main [kernel.kallsyms] [k] dma_sync_wait 0.20% main [kernel.kallsyms] [k] uart_write 0.13% swapper [kernel.kallsyms] [k] cache_op_range 0.12% swapper [kernel.kallsyms] [k] __dma_tx_complete 0.06% swapper [kernel.kallsyms] [k] dw_dma_tasklet 0.04% ksoftirqd/0 [kernel.kallsyms] [k] finish_task_switch 0.03% perf [kernel.kallsyms] [k] raw_copy_from_user 0.02% swapper [kernel.kallsyms] [k] __softirqentry_text_start |
61% | 45.93% main [kernel.kallsyms] [k] dcache_wb_line 36.79% swapper [kernel.kallsyms] [k] __sched_text_end 4.86% main [kernel.kallsyms] [k] dma_cookie_status 4.06% main [kernel.kallsyms] [k] free_hot_cold_page 1.28% main [kernel.kallsyms] [k] dma_sync_wait 1.28% main [kernel.kallsyms] [k] skip_ftrace 0.66% main [kernel.kallsyms] [k] _mcount 0.58% main [kernel.kallsyms] [k] unset_migratetype_isolate 0.51% main [kernel.kallsyms] [k] __free_pages 0.41% main [kernel.kallsyms] [k] start_isolate_page_range |
| 1080p 50fps | 9% | 89.82% swapper [kernel.kallsyms] [k] __sched_text_end 5.63% main [kernel.kallsyms] [k] dma_cookie_status 1.48% main [kernel.kallsyms] [k] dma_sync_wait 0.49% ksoftirqd/0 [kernel.kallsyms] [k] finish_task_switch 0.24% swapper [kernel.kallsyms] [k] dw_dma_tasklet 0.13% swapper [kernel.kallsyms] [k] __dma_tx_complete 0.10% swapper [kernel.kallsyms] [k] tasklet_action 0.10% main [kernel.kallsyms] [k] do_futex 0.06% main [kernel.kallsyms] [k] raw_copy_from_user 0.06% main [kernel.kallsyms] [k] restore_from_user_fp |
44% | 53.49% swapper [kernel.kallsyms] [k] __sched_text_end 30.73% main [kernel.kallsyms] [k] dcache_wb_line 3.65% main [kernel.kallsyms] [k] free_hot_cold_page 3.36% main [kernel.kallsyms] [k] dma_cookie_status 1.03% main [kernel.kallsyms] [k] skip_ftrace 0.85% main [kernel.kallsyms] [k] dma_sync_wait 0.56% main [kernel.kallsyms] [k] _mcount 0.48% main [kernel.kallsyms] [k] unset_migratetype_isolate 0.38% main [kernel.kallsyms] [k] __free_pages 0.33% main [kernel.kallsyms] [k] isolate_migratepages_range |
问题的分析:
1. skip_trace和_mcount两个是因为ftrace引入的负荷,不合理。此时不应该有这些。----需要推动csky修改成Dynamic function/function_graph。
2. dcache_wb_line/free_hot_cold_page是CMA操作引起的。-----------------------------------这里需要修改处理方式,CMA不需要重复申请释放。
3. dma_cookie_status/dma_sync_wait是DMA操作引起的。------------------------------------这里可以通过修改DMA异步信号触发来降低占用率。
分析总结:
1. 从上面的测试结果看,应该尽量避免内存申请释放。csky内存处理效率很低。
2. 同步模式效率非常低,4K单路占用率达到15%,如果4K双路就没法使用了。
所以必须要使用异步模式,这也是使用DMA的初衷。
1.1 不同DMA size对性能影响
多大的传输使用DMA获得的收益最高呢?做了个实验,结果如下,横轴单位是B,纵轴单位是MB/s、
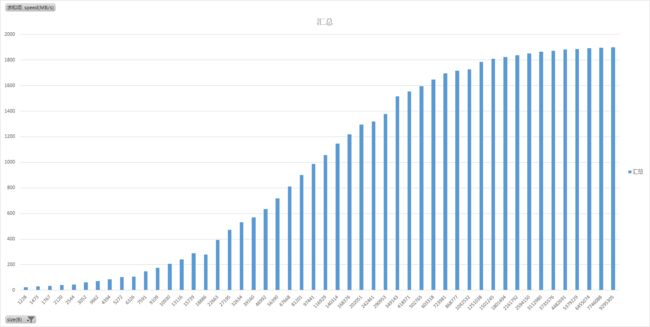
可以看出,DMA size大小越大效率越高,size接近3MB的时候,以及以后吞吐率就比较稳定了。
2. 分析问题:让DMA异步起来
int axidma_memcpy(dma_addr_t src, dma_addr_t dst, unsigned int len) { struct dma_async_tx_descriptor *tx = NULL; dma_cookie_t cookie; unsigned long flags; bool sync_wait = false;-------------------------------------------------------------------true表示同步等待模式;false表示异步模式,和callback()配合。 int err = 0; flags = DMA_CTRL_ACK | DMA_PREP_INTERRUPT; tx = xxxxxx->dma.chan->device->device_prep_dma_memcpy(xxxxxx->dma.chan, dst, src, len, flags); if (!tx) { pr_err("Fail to prepare memcpy.\n"); return -1; } tx->callback = axidma_callback; tx->callback_param = xxxxxx; cookie = tx->tx_submit(tx); if (dma_submit_error(cookie)) { pr_err("Fail to submit axi dma.\n"); return -1; } if (!sync_wait) { dma_async_issue_pending(dma_dev->dma.chan);------------------------------------------发送DMA传输请求,然后退出。这里不会等待操作结果。 } else { if (dma_sync_wait(dma_dev->dma.chan, cookie) == DMA_COMPLETE) { err = 0; } else { err = -EIO; } } return err; } enum dma_status dma_sync_wait(struct dma_chan *chan, dma_cookie_t cookie) { enum dma_status status; unsigned long dma_sync_wait_timeout = jiffies + msecs_to_jiffies(5000);-------------------超时5000ms,足够大了。 dma_async_issue_pending(chan);------------------------------------------------------------和之前同样功能,发送DMA传输请求。只是下面会进行等待,并有超时动作。 do { status = dma_async_is_tx_complete(chan, cookie, NULL, NULL);--------------------------pool DMA传输状态。 if (time_after_eq(jiffies, dma_sync_wait_timeout)) { dev_err(chan->device->dev, "%s: timeout!\n", __func__); return DMA_ERROR;-----------------------------------------------------------------超时退出。 } if (status != DMA_IN_PROGRESS) break; cpu_relax();--------------------------------------------------------------------------让出CPU执行。 } while (1); return status; } static inline enum dma_status dma_async_is_tx_complete(struct dma_chan *chan, dma_cookie_t cookie, dma_cookie_t *last, dma_cookie_t *used) { struct dma_tx_state state; enum dma_status status; status = chan->device->device_tx_status(chan, cookie, &state); if (last) *last = state.last; if (used) *used = state.used; return status; }
然后在callback()中发送SIGIO信号:
static void axidma_callback(void *arg) { if(dma_dev->async) { pr_debug("axidma callback: chan=%s.\n", dma_chan_name(dma_dev->dma.chan)); pr_debug("axidma_callback: magic=0x%08x pid_type=%d\n", dma_dev->async->magic, dma_dev->async->fa_file->f_owner.pid_type); kill_fasync(&dma_dev->async, SIGIO, POLL_IN);--------------------------------在传输完成后,异步发送SIGIO信号。 } }
3. 解决问题:DMA异步传输
为了排除其他进程影响,单独构造3个试用例:1. 4K 25fps;2. 1080p 2路 25fps;3. 1080p 4路 25fps。
然后改成DMA异步模式,CPU占用率是否明显下降?
测试程序如下:


#include#include #include #include #include #include #include #include #include #include #include #include #include #include #include "IFMS_MemCMA_API.h" int fd; unsigned int handle_count = 0; volatile unsigned int dmatest_exit = 0; volatile sigio_received = 0; #define LOOP_COUNT 10000 #define DMA_MEMCPY 0 #define DMA_FILE "/dev/dpeye1000_axidma" #define DPEYE1000_AXIDMA_IOC_MAGIC 'd' #define DPEYE1000_AXIDMA_REQUEST_CHNN _IOW(DPEYE1000_AXIDMA_IOC_MAGIC, 1, int) //Request channel. #define DPEYE1000_AXIDMA_RELEASE_CHNN _IOW(DPEYE1000_AXIDMA_IOC_MAGIC, 2, int) //Release channel. #define DPEYE1000_AXIDMA_MEMCPY _IOW(DPEYE1000_AXIDMA_IOC_MAGIC, 3, int) //Do 1d memcpy. //#define PERFORMANCE_DEBUG struct axidma_dma { struct dma_chan *chan; unsigned long src; unsigned long dst; // for memcpy unsigned int len; unsigned int n_channels; }; struct thread_para { unsigned int size; unsigned int expries; struct cma_block cma_block1; struct cma_block cma_block2; }; static struct axidma_dma axidma_dma; struct thread_para t_para; int dmacopy_tid = 0; void trigger_dma_copy(void) { int ret; #ifdef PERFORMANCE_DEBUG struct timespec time_0, time_1; unsigned long duration; float throughput = 0.0; clock_gettime(CLOCK_REALTIME, &time_0); #endif axidma_dma.src = (unsigned long)t_para.cma_block1.addr_p; axidma_dma.dst = (unsigned long)t_para.cma_block2.addr_p; axidma_dma.len = t_para.size; ret = ioctl(fd, DPEYE1000_AXIDMA_MEMCPY, &axidma_dma); if(ret < 0) { printf("fail to ioctl DPEYE1000_AXIDMA_MEMCPY!!!\n"); } #ifdef PERFORMANCE_DEBUG clock_gettime(CLOCK_REALTIME, &time_1); duration = (time_1.tv_sec-time_0.tv_sec)*1000000000 + (time_1.tv_nsec-time_0.tv_nsec); throughput = (float)t_para.size/1048576*1000000000/duration; printf("%ld.%ld %d %d, %ld, %f\n", time_1.tv_sec, time_1.tv_nsec, handle_count, t_para.size, duration, throughput); #endif } void sigint_handler(int sig) { if(sig == SIGINT) { printf("%s SIGINT\n", __func__); dmatest_exit = 1; } } void sigio_handler(int sig) { if(sig == SIGIO) { sigio_received = 1; } } static void pthread_func(void *arg) { int ret; int Oflags; struct f_owner_ex owner_ex; struct timespec time1, time2; struct sigaction sa, sa2; sigset_t set, oldset; long long duration; unsigned int mode = DMA_MEMCPY; ret = IFMS_MemCMAAlloc(t_para.size, &t_para.cma_block1); if(ret<0) { printf("CMA alloc failed.\n"); return -1; } ret=IFMS_MemCMAAlloc(t_para.size, &t_para.cma_block2); if(ret<0) { printf("CMA alloc failed.\n"); return -1; } //=========================================================================================== //Set thread name. prctl(PR_SET_NAME,"sigio"); dmacopy_tid = syscall(SYS_gettid); printf("sigio thread tid=%ld %ld.\n", syscall(SYS_gettid), getpid()); //Set SIGIO actiong. memset(&sa, 0, sizeof(sa)); sa.sa_handler = sigio_handler; sa.sa_flags |= SA_RESTART; sigaction(SIGIO, &sa, NULL); //Set proc mask. sigemptyset(&set); sigprocmask(SIG_SETMASK, &set, NULL); sigaddset(&set, SIGIO); fd = open(DMA_FILE, O_RDWR); if (fd < 0) { printf("Can't open %s!\n", DMA_FILE); } //If set F_SETOWN_EX, SIGIO will send to this thread only. owner_ex.pid = syscall(SYS_gettid); owner_ex.type = F_OWNER_TID; fcntl(fd, F_SETOWN_EX, &owner_ex); Oflags = fcntl(fd, F_GETFL); fcntl(fd, F_SETFL, Oflags | FASYNC); clock_gettime(CLOCK_REALTIME, &time1); ret = ioctl(fd, DPEYE1000_AXIDMA_REQUEST_CHNN, &mode); if(ret < 0) { printf("fail to ioctl DPEYE1000_AXIDMA_REQUEST_CHNN!!!\n"); } while(!dmatest_exit) { if(t_para.expries > 1) usleep(t_para.expries); trigger_dma_copy(); //Send DMA copy request. while(!sigio_received) while(!sigio_received) { pthread_sigmask(SIG_BLOCK, &set, &oldset); //sigprocmask(SIG_BLOCK, &set, &oldset); sigsuspend(&oldset); //Will pause here, and will be waked up by SIGIO. pthread_sigmask(SIG_UNBLOCK, &set, NULL); //sigprocmask(SIG_UNBLOCK, &set, NULL); handle_count++; } sigio_received = 0; } clock_gettime(CLOCK_REALTIME, &time2); duration = (long long)(time2.tv_sec-time1.tv_sec)*1000000000 + (time2.tv_nsec-time1.tv_nsec); sleep(1); printf("End time %lld.%09lld count=%d fps=%lld.\n", duration/1000000000, duration%1000000000, handle_count, (long long)handle_count*1000000000/duration); ioctl(fd, DPEYE1000_AXIDMA_RELEASE_CHNN, NULL); if(ret < 0) { printf("fail to ioctl DPEYE1000_AXIDMA_RELEASE_CHNN!!!\n"); } close(fd); //=========================================================================================== ret=IFMS_MemCMAFree(t_para.cma_block1); if(ret<0) { printf("CMA free failed.\n"); return -1; } ret=IFMS_MemCMAFree(t_para.cma_block2); if(ret<0) { printf("CMA free failed.\n"); return -1; } pthread_exit(0); } void main(int argc, char **argv) { pthread_t tidp; sigset_t set; unsigned int size = 0, expries = 0; struct sigaction sa; if(argc != 3) { printf("Usage: %s size(B) expries(us).\n", argv[0]); return -1; } size = atoi(argv[1]); if(!size) { printf("Please input right size.\n"); return -1; } expries = atoi(argv[2]); if(!expries) { printf("Please input right expries time.\n"); return -1; } t_para.size = size; t_para.expries = expries; memset(&sa, 0, sizeof(sa)); sa.sa_handler = sigint_handler; sa.sa_flags |= SA_RESTART; sigaction(SIGINT, &sa, NULL); sigemptyset(&set); sigaddset(&set, SIGIO); sigprocmask(SIG_BLOCK, &set, NULL); if(pthread_create(&tidp, NULL, pthread_func, NULL) == -1) { printf("Create pthread error.\n"); return; } if(pthread_join(tidp, NULL)) { printf("Join pthread error.\n"); return; } printf("Main exit.\n"); return; }
3.1 DMA异步和同步在不同场景下对比测试
dma_thread测试不同分辨率、不同帧率下的性能对比:
| Case | 同步DMA | 异步DMA | ||
| top -d 5 | perf record -a -e cpu-clock -- sleep 60 |
top -d 5 | perf record -a -e cpu-clock -- sleep 60 | |
| 1080p 50fps dma_thread 3110400 20000 |
7.5% 单次耗时:1.6ms |
91.12% swapper [kernel.kallsyms] [k] __sched_text_end 91.22% swapper 8.04% main0.43% perf 0.11% jbd2/mmcblk1p2- 0.08% mmcqd/1 |
dma_sigio 3110400 20000 0.3% 单次耗时:135us |
98.57% swapper |
| 1080p 100fps dma_thread 3110400 10000 |
14.1% 单次耗时:1.6ms |
84.27% swapper [kernel.kallsyms] [k] __sched_text_end 84.30% swapper |
dma_sigio 3110400 10000 0.5% 单次耗时:135us |
98.48% swapper |
| 4k 25fps dma_thread 13271040 40000 |
14.5% 单次耗时:6.7ms |
84.71% swapper [kernel.kallsyms] [k] __sched_text_end 84.75% swapper |
dma_sigio 13271040 40000 0.2% 单次耗时:135us |
98.51% swapper |
分析总结:
1. 同步模式下,CPU占用率跟数据量大小强相关,基本成正比;影响CPU占用率的最大因素是DMA传输同步等待,即上面dma_sync_wait()和dma_cookie_status()两个函数。
2. 异步模式下,请求发送后,交出CPU,在收到信号后继续下一次发送,期间不会占用CPU。CPU占用率跟DMA请求次数强相关,主要是发送请求,以及sigsuspend()和SIGIO信号处理占用。
3. 帧的吞吐率受DMA传输的帧大小影响。
3.2 那么异步模式的极限在哪里?
明显DMA的异步极限帧率,同样受限于DMA传输效率,并不会增大吞吐率。
那么看看不同帧率下的CPU情况:
| Case | 异步DMA | |
| top -d 5 | perf record -a -e cpu-clock -- sleep 60 | |
| 1080p 550 fps (max) |
2.6% |
96.50% swapper |
| 1080p 375 fps | 1.8 | 98.44% swapper |
| 1080p 273 fps | 1.2% | 98.43% swapper |
| 4K 145 fps (max) |
0.8% | 98.45% swapper |
所以DMA极限帧率,主要受DMA传输大小和传输速度影响。
3.3 kernelshark对比DMA同步/异步模式
分别看看上面3个场景下同步模式下,kernelshark输出可以看出1080p执行时间是1.67ms,4k时间是6.88ms;每次时间间隔跟fps设置也对应。
1080p 50fps、1080p 100fps、4k 25fps三种占用率应该是1.67/21.67=7.7%、1.67/11.67=14.3%、6.88/46.88=14.7%。



再来看一下异步情况下的输出,这时候越是大尺寸DMA传输CPU占用率的收益越大。4k的时候



下面以1080p和4k对比看一下异步的收益。
1080p的DMA传输占用时间从1.65,降到了1.65-1.57=0.08,收益率95%。


可以看出4k情况下异步DMA的CPU占用时间从6.70,降到6.70-6.64=0.06,收益率达到99%。


4. 同进程多SIGIO冲突解决
当测试通过,进入方案的时候遇到SIGIO无法接收到的问题。
检查得知,原来是存在多个设备kill_fasync()。而一个进程范围内,SIGIO只能有一个handler。
通过fcntl()设置F_SETSIG可以定义sig代提SIGIO发送信号。
操作如下:
#define SIGDMA (SIGRTMIN+1)--------------------------定义一个实时信号 fcntl(fd, F_SETSIG, SIGDMA);---------------------使用SIGDMA代提SIGIO作为async信号。 memset(&sa, 0, sizeof(sa)); sa.sa_sigaction = sigdma_handler;----------------一定要修改为sa_sigaction,对应的sigdma_handler参数也需要修改。 sa.sa_flags = SA_RESTART | SA_SIGINFO;-----------一定要增加SA_SIGINFO。 sigaction(SIGDMA, &sa, NULL);
除了有上面的好处之外,实时信号还能排队,这就比非实时信号更不会丢失。除非队列溢出。
5. 实际场景提升效果
在实际场景中,每40ms来一帧数据进行DMA搬运,

那么这段时间内,整个线程占用多少时间呢?2.303-0.225=2.078ms,对应的CPU占用率应该是5.2%。

再看看异步DMA实际效果如何?可以看出copy线程,中间调度出去的时间增大不小。

那么此时CPU占用率多少呢?2.288-1.177-0.431=0.68ms,对应的CPU占用率应该是1.7%。

从计算来看CPU占用率能降低3%左右。
6. 其他方案
1. 使用AXI DMA两通道,能否提高DMA吞吐率?相当于DMA并发,copy双线程?------------硬件双通道,如何构造同时触发的双通道case?
2. 如何标识每一次DMA传输,通过netlink port端口?--------------------------------------------------修改异步触发方式,port和channel绑定