上周写了一个腾讯旗下的一个小说网站的自动回帖程序:
具体怎么实现的呢?
其实它就是一个,找到评论接口,然后利用程序模拟HTTP请求的过程。再结合爬虫的相关技术具体实现。 大概分为这么几步:
第一步:先找到评论接口:
使用chrome或者火狐浏览器,或者专业点的fiddler对评论过程抓包

得到具体的请求为:
POST http://chuangshi.qq.com/bookcomment/replychapterv2 HTTP/1.1
Host: chuangshi.qq.com
Connection: keep-alive
Content-Length: 102
Accept: application/json, text/javascript, */*; q=0.01
Origin: http://chuangshi.qq.com
X-Requested-With: XMLHttpRequest
User-Agent: Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/40.0.2214.93 Safari/537.36
Content-Type: application/x-www-form-urlencoded; charset=UTF-8
Referer: http://chuangshi.qq.com/bk/xh/AGkEMF1hVjEAOlRlATYBZg-r-69.html
Accept-Encoding: gzip, deflate
Accept-Language: zh-CN,zh;q=0.8
Cookie: xxxxxx
bid=14160172&uuid=69&content=%E4%B9%A6%E5%86%99%E7%9A%84%E4%B8%8D%E9%94%99&_token=czo4OiJJRm9TQ0RnbSI7
第二步:模拟请求,它的逻辑是:首先通过频道页(玄幻·奇幻 武侠·仙侠 都市·职场 历史·军事 游戏·体育 科幻·灵异 二次元)抓取文章信息。
如玄幻小说的频道页为:http://chuangshi.qq.com/bk/huan/
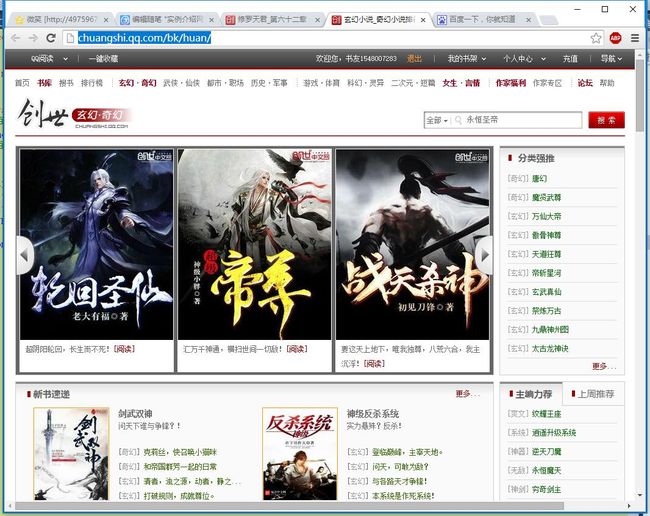
然后提取文章标题、文章ID,章节ID等数据

注入cookie等参数,模拟请求核心代码:
1 public class AutoCommentService : AutoComment.service.IAutoCommentService
2 {
3 public delegate void CommentHandler(Article article,Comment comment);
4 public event CommentHandler Commented;
5 bool stop;
6 /// GetArticles(string typeUrl)
75 {
76 var html = HttpHelper.GetString(typeUrl);
77 html = Regex.Match(html, ".*?(?=)