###通过http://192.168.50.200:7180/cmf/login 访问CM控制台
4.CDH安装
4.1CDH集群安装向导
1.admin/admin登陆到CM
2.同意license协议,点击继续

3.选择60试用,点击继续

4.点击“继续”
5.输入主机IP或者名称,点击搜索找到主机名后点击继续

6.点击“继续”

7.使用parcel选项,点击“更多选项”,点击“-”删除其他所有的地址,输入http://ip-192-168-50-200.hns.com/cdh5.12.1/点击“保存更改”

8.选择自定义存储库,输入cm的http地址

9.点击“继续”,进入下一步安装jdk
10.点击“继续”,进入下一步,默认多用户模式
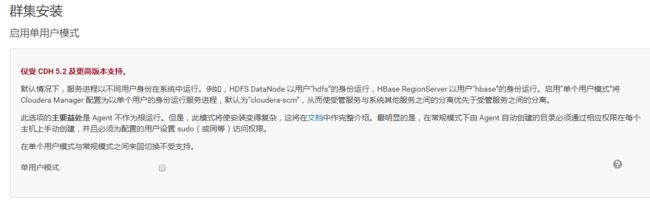
11.点击“继续”,进入下一步配置ssh账号密码:
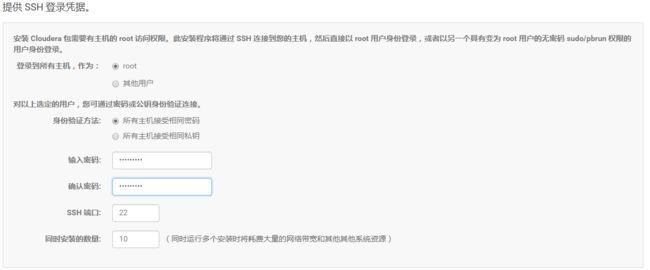
12.点击“继续”,进入下一步,安装Cloudera Manager相关到各个节点

13.点击“继续”,进入下一步安装cdh到各个节点


14.点击“继续”,进入下一步主机检查,确保所有检查项均通过
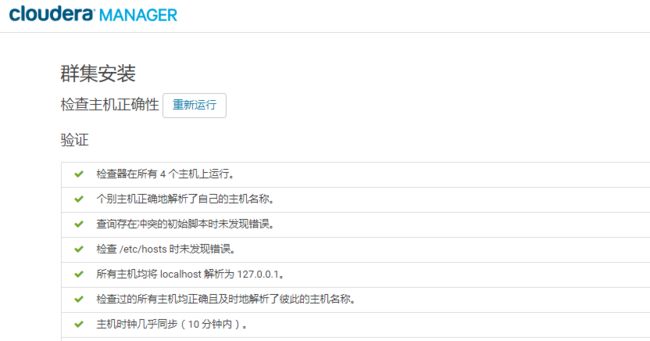

上述的解决方案:
在每台机器上执行如下操作:
[root@ip-192-168-50-200 ~]# echo never > /sys/kernel/mm/transparent_hugepage/enabled
[root@ip-192-168-50-200 ~]# echo never > /sys/kernel/mm/transparent_hugepage/defrag
[root@ip-192-168-50-200 ~]# echo "vm.swappiness = 10" >> /etc/sysctl.conf
[root@ip-192-168-50-200 ~]# sysctl -p
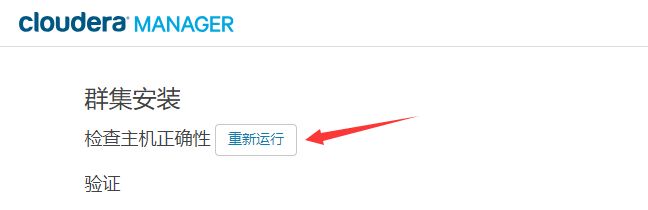

点击完成进入服务安装向导!!!
4.2 集群设置安装向导
1.选择需要安装的服务,此处使用自定义服务,如下图


2.点击“继续”,进入集群角色分配
HDFS角色分配:

Hive角色分配:

Cloudera Manager Service 角色分配:

Spark角色分配:(Spark on Yarn 所以没有spark的master和worker 角色)

Yarn角色分配:

Zookeeper角色分配:(至少3个Server)
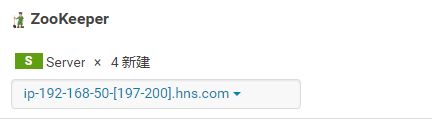
3.角色分配完成点击“继续”,进入下一步,测试数据库连接


4.测试成功,点击“继续”,进入目录设置,此处使用默认默认目录,根据实际情况进行目录修改



5.点击“继续”,等待服务启动成功!!!

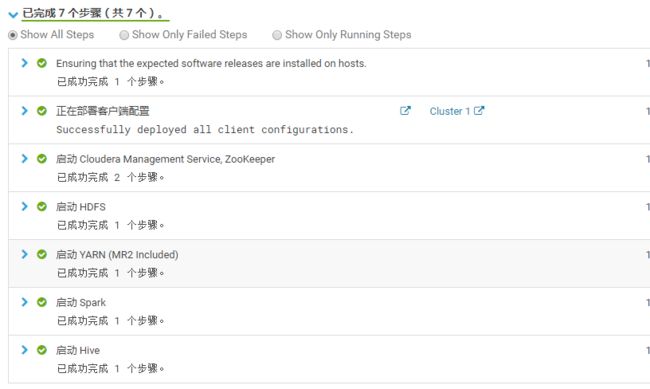
6.点击“继续”,显示集群安装成功!

7.安装成功后,进入home管理界面

5.快速组建服务验证
5.1HDFS验证(mkdir+put+cat +get)
mkdir操作:
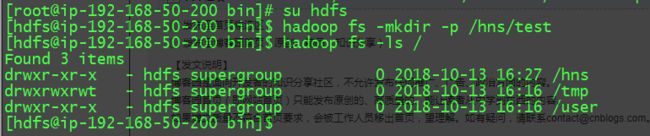
put 操作:


cat 操作:

get 操作:
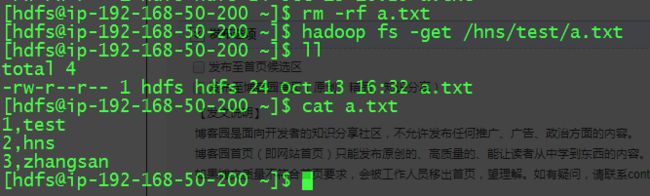
5.2 Hive 验证
使用hive命令行操作
hive> create external table test_table( > s1 string, > s2 string > )row format delimited fields terminated by ',' > stored as textfile location '/hns/test'; OK Time taken: 0.074 seconds hive> show tables; OK test_table Time taken: 0.012 seconds, Fetched: 1 row(s)
hive> select * from test_table;
OK
1 test
2 hns
3 zhangsan
Time taken: 0.054 seconds, Fetched: 3 row(s)
hive>
hive> insert into test_table values("4","lisi"); Query ID = hdfs_20181013220202_823a17d7-fb58-40e9-bf33-11f44d0de10a Total jobs = 3 Launching Job 1 out of 3 Number of reduce tasks is set to 0 since there's no reduce operator Starting Job = job_1539418452562_0003, Tracking URL = http://ip-192-168-50-200.hns.com:8088/proxy/application_1539418452562_0003/ Kill Command = /opt/cloudera/parcels/CDH-5.12.1-1.cdh5.12.1.p0.3/lib/hadoop/bin/hadoop job -kill job_1539418452562_0003 Hadoop job information for Stage-1: number of mappers: 1; number of reducers: 0 2018-10-13 22:02:42,009 Stage-1 map = 0%, reduce = 0% 2018-10-13 22:02:49,308 Stage-1 map = 100%, reduce = 0%, Cumulative CPU 0.93 sec MapReduce Total cumulative CPU time: 930 msec Ended Job = job_1539418452562_0003 Stage-4 is selected by condition resolver. Stage-3 is filtered out by condition resolver. Stage-5 is filtered out by condition resolver. Moving data to: hdfs://ip-192-168-50-200.hns.com:8020/hns/test/.hive-staging_hive_2018-10-13_22-02-31_572_2687237229927791201-1/-ext-10000 Loading data to table default.test_table Table default.test_table stats: [numFiles=2, numRows=1, totalSize=31, rawDataSize=6] MapReduce Jobs Launched: Stage-Stage-1: Map: 1 Cumulative CPU: 0.93 sec HDFS Read: 3658 HDFS Write: 81 SUCCESS Total MapReduce CPU Time Spent: 930 msec OK Time taken: 19.016 seconds hive> select * from test_table; OK 4 lisi 1 test 2 hns 3 zhangsan Time taken: 0.121 seconds, Fetched: 4 row(s) hive>
Hive MapReduce操作:
hive> select count(*) from test_table; Query ID = hdfs_20181013220606_1011d0ce-9ddd-43ec-a103-18b3a32ea292 Total jobs = 1 Launching Job 1 out of 1 Number of reduce tasks determined at compile time: 1 In order to change the average load for a reducer (in bytes): set hive.exec.reducers.bytes.per.reducer=In order to limit the maximum number of reducers: set hive.exec.reducers.max= In order to set a constant number of reducers: set mapreduce.job.reduces= Starting Job = job_1539418452562_0004, Tracking URL = http://ip-192-168-50-200.hns.com:8088/proxy/application_1539418452562_0004/ Kill Command = /opt/cloudera/parcels/CDH-5.12.1-1.cdh5.12.1.p0.3/lib/hadoop/bin/hadoop job -kill job_1539418452562_0004 Hadoop job information for Stage-1: number of mappers: 1; number of reducers: 1 2018-10-13 22:06:45,367 Stage-1 map = 0%, reduce = 0% 2018-10-13 22:06:52,595 Stage-1 map = 100%, reduce = 0%, Cumulative CPU 1.12 sec 2018-10-13 22:07:00,998 Stage-1 map = 100%, reduce = 100%, Cumulative CPU 2.28 sec MapReduce Total cumulative CPU time: 2 seconds 280 msec Ended Job = job_1539418452562_0004 MapReduce Jobs Launched: Stage-Stage-1: Map: 1 Reduce: 1 Cumulative CPU: 2.28 sec HDFS Read: 7350 HDFS Write: 2 SUCCESS Total MapReduce CPU Time Spent: 2 seconds 280 msec OK 4 Time taken: 24.471 seconds, Fetched: 1 row(s)

5.3 MapReduce 验证:
[hdfs@ip-192-168-50-200 hadoop-mapreduce]$ pwd /opt/cloudera/parcels/CDH/lib/hadoop-mapreduce
[hdfs@ip-192-168-50-200 hadoop-mapreduce]$ hadoop jar hadoop-mapreduce-examples.jar pi 5 5 Number of Maps = 5 Samples per Map = 5 Wrote input for Map #0 Wrote input for Map #1 Wrote input for Map #2 Wrote input for Map #3 Wrote input for Map #4 Starting Job . . . 18/10/13 22:12:33 INFO mapreduce.Job: Running job: job_1539418452562_0005 18/10/13 22:12:41 INFO mapreduce.Job: Job job_1539418452562_0005 running in uber mode : false 18/10/13 22:12:41 INFO mapreduce.Job: map 0% reduce 0% 18/10/13 22:12:49 INFO mapreduce.Job: map 40% reduce 0% 18/10/13 22:12:54 INFO mapreduce.Job: map 80% reduce 0% 18/10/13 22:12:59 INFO mapreduce.Job: map 100% reduce 0% 18/10/13 22:13:03 INFO mapreduce.Job: map 100% reduce 100% 18/10/13 22:13:03 INFO mapreduce.Job: Job job_1539418452562_0005 completed successfully 18/10/13 22:13:03 INFO mapreduce.Job: Counters: 49 File System Counters . . .
5.4 Spark 验证

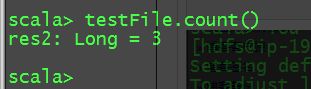
scala> val testFile=sc.textFile("hdfs://ip-192-168-50-200.hns.com:8020/hns/test/a.txt") testFile: org.apache.spark.rdd.RDD[String] = hdfs://ip-192-168-50-200.hns.com:8020/hns/test/a.txt MapPartitionsRDD[1] at textFile at:27
scala> testFile.count() res2: Long = 3