1,eclipse安装hadoop插件
插件下载地址:链接: https://pan.baidu.com/s/1U4_6kLFNiKeLsGfO7ahXew 提取码: as9e
下载hadoop-eclipse-plugin-2.7.3.jar包,放入eclipse路径下(本人eclipse版本为eclipse mars,路径为C:\Users\Administrator\.p2\pool\plugins,其他版本可直接放入eclipse安装路径下的plugin)
2,安装hadoop到本地,并配置环境变量
HADOOP_HOME:C:\hadoop-2.7.2
PATH后面追加%HADOOP_HOME%\bin;%HADOOP_HOME%\sbin;
3,修改hadoop配置文件hadoop-2.7.2\etc\hadoop\hadoop-env.cmd(JAVA_HOME路径中的空格会导致错误,所以此处单独处理)
set JAVA_HOME="C:\Program Files"\Java\jdk1.8.0_45
4,配置eclipse中hadoop路径
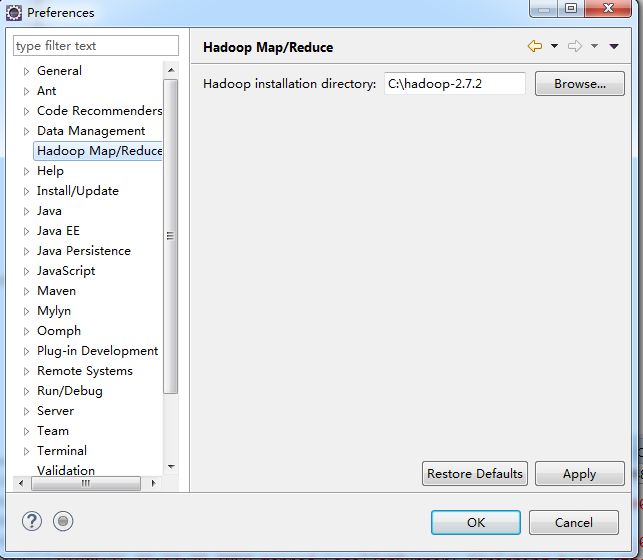
5,window-show views-other-Map/Reduce location,打开mapreduce窗口
6,点击右侧大象,在窗口中配置大数据服务器地址,若host中已配置ip映射可直接使用域名,否则填写集群ip地址
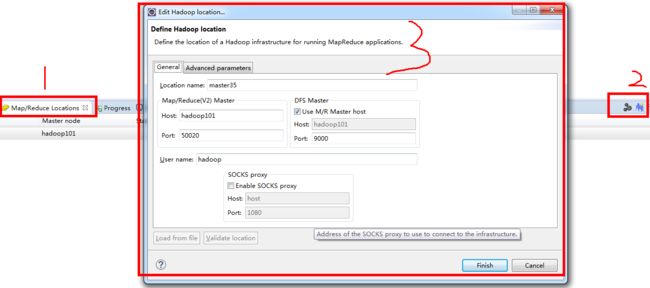
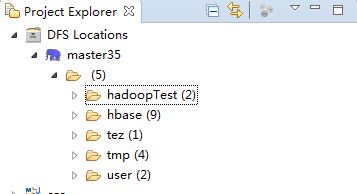
7,左侧窗口出现集群连接信息,目录应同直接在浏览器访问时相同。
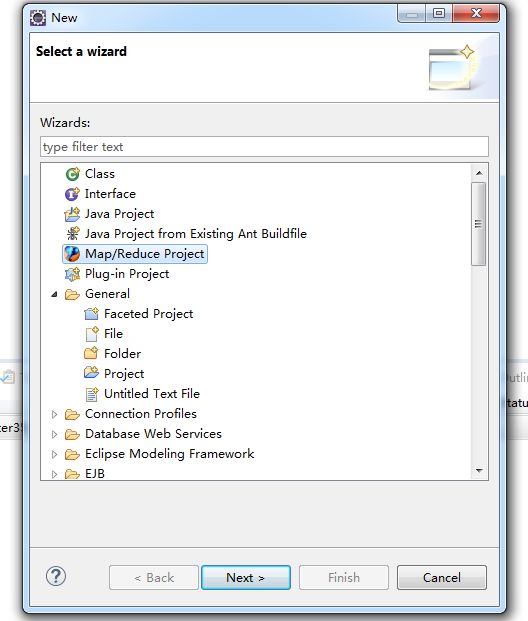
8,右键,新建mapreduce项目wordcount
9,将源码中wordcount.java类复制到项目中,代码路径hadoop-2.7.7-src\hadoop-mapreduce-project\hadoop-mapreduce-client\hadoop-mapreduce-client-jobclient\src\test\java\org\apache\hadoop\mapred
源码下载地址:链接: https://pan.baidu.com/s/1yRRymdG2hyhbv-PJjj_21w 提取码: 7chz
10,将log4j.properties文件放入项目src下,文件路径hadoop-2.7.7-src\hadoop-common-project\hadoop-common\src\test\resources
11,在集群创建输入文件夹,并修改权限
hadoop fs -mkdir /hadoopTest
hadoop fs -chmod -R 777 /hadoopTest
12,右键点击hadoopTest,创建input文件夹,注意不要创建output文件夹,若有页需要删除,因为执行程序会自动创建此文件夹
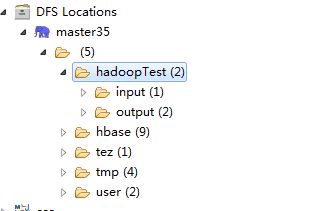
13,右键上传文件,将需要统计的文本,上传到input目录
14,右键wordcount项目,点击run configuration,配置执行执行参数
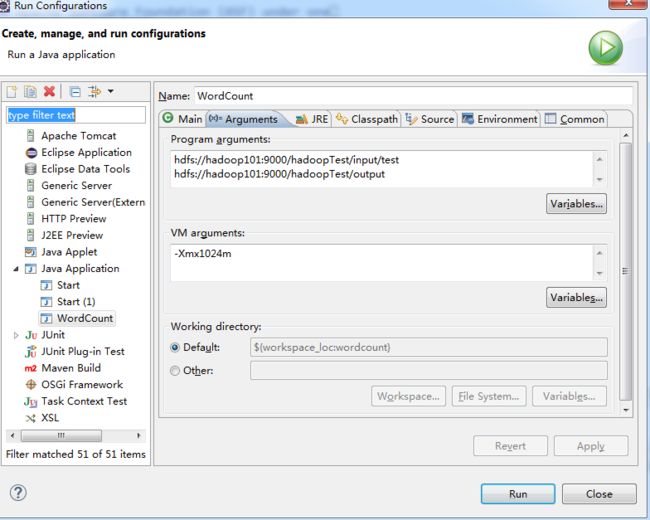
15,点击apply,再点击run按钮,执行程序,再查看dfs locations,发现多了output目录,下面有程序执行结果
16,如果程序执行报错:org.apache.hadoop.io.nativeio.NativeIO$Windwos.access0需要从源码中copy出NativeIO类,放入项目中,修改access方法,改为return0。注意,必须从源码中得到,从jar中得到的类是没有此方法的