随机更换user-agent
每次url请求更换一次user-agent
|
1
|
pip install fake
-
useragent
|
settings
|
1
2
3
4
|
DOWNLOADER_MIDDLEWARES
=
{
# 'ArticleSpider.middlewares.MyCustomDownloaderMiddleware': 543,
'ArticleSpider.middlewares.RandomUserAgentMiddleware'
:
400
,
}
|
middlewares
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
|
from
fake_useragent
import
UserAgent
class
RandomUserAgentMiddleware(
object
):
def
__init__(
self
, crawler):
super
(RandomUserAgentMiddleware,
self
).__init__()
self
.ua
=
UserAgent()
# 若settings中没有设置RANDOM_UA_TYPE的值默认值为random,
# 从settings中获取RANDOM_UA_TYPE变量,值可以是 random ie chrome firefox safari opera msie
self
.ua_type
=
crawler.settings.get(
'RANDOM_UA_TYPE'
,
'random'
)
@classmethod
def
from_crawler(
cls
, crawler):
return
cls
(crawler)
def
process_request(
self
, request, spider):
def
get_ua():
'''根据settings的RANDOM_UA_TYPE变量设置每次请求的User-Agent'''
return
getattr
(
self
.ua,
self
.ua_type)
ua
=
get_ua()
request.headers.setdefault(
'User-Agent'
, get_ua())
|
ip代理
方案一:免费版
自定义函数获取网上的一些免费代理ip
settings
|
1
2
3
|
DOWNLOADER_MIDDLEWARES
=
{
'ArticleSpider.middlewares.RandomProxyMiddleware'
:
400
,
}
|
middlewares
|
1
2
3
4
|
class
RandomProxyMiddleware(
object
):
#动态设置ip代理
def
process_request(
self
, request, spider):
request.meta[
"proxy"
]
=
get_random_ip()
# 这个自定义函数返回一个随机代理ip:port
|
方案二:收费版
github上scrapy-proxies等等
在线打码
编码识别:由于验证码识别难度大,而且易更新,所以编码识别验证码(不推荐)
在线打码:调用已经开发好的在线验证码识别软件接口识别验证码。识别率在90%以上,并且效率高(推荐)
人工打码:识别率近100%,但是成本高(用于复杂的)
cookie禁用
一些网站会跟踪cookie,如果不需要登陆的网站,可禁用cookie,降低被ban概率,scrapy默认开启cookie
|
1
|
COOKIES_ENABLED
=
False
|
自动限速
调整某些参数,如
|
1
2
|
AUTOTHROTTLE_ENABLED
=
True
DOWNLOAD_DELAY
=
3
|
selenium
官方文档 http://selenium-python-docs-zh.readthedocs.io/zh_CN/latest/
作用:浏览器操控
安装selenium
|
1
|
pip install selenium
|
下载对应浏览器的驱动
http://selenium-python.readthedocs.io/installation.html
第三方(微博)登录知乎
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
|
import
time
from
selenium
import
webdriver
from
scrapy.selector
import
Selector
browser
=
webdriver.Chrome(executable_path
=
"D:/Package/chromedriver.exe"
)
time.sleep(
2
)
# 延时为了让页面加载完
browser.get(
"https://www.zhihu.com/#signin"
)
browser.find_element_by_css_selector(
".qrcode-signin-cut-button"
).click()
browser.find_element_by_css_selector(
".signup-social-buttons"
).click()
browser.find_element_by_css_selector(
".js-bindweibo"
).click()
#browser.switch_to.window(browser.window_handles[-1])
browser.find_element_by_css_selector(
".WB_iptxt"
).send_keys(
"xxx"
)
browser.find_element_by_css_selector(
"input[node-type='passwd']"
).send_keys(
"xxx"
)
browser.find_element_by_css_selector(
"a[node-type='submit']"
).click()
time.sleep(
2
)
# 延时为了让页面加载完
browser.find_element_by_css_selector(
"a[node-type='submit']"
).click()
|
第三方(QQ)登录知乎
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
|
# -*- coding: utf-8 -*-
__author__
=
'hy'
import
time
from
selenium
import
webdriver
from
scrapy.selector
import
Selector
browser
=
webdriver.Firefox(executable_path
=
"D:/Package/geckodriver.exe"
)
#
browser.get(
"https://www.zhihu.com/#signin"
)
time.sleep(
2
)
# 点击QQ
browser.find_element_by_css_selector(
".qrcode-signin-cut-button"
).click()
browser.find_element_by_css_selector(
".signup-social-buttons"
).click()
time.sleep(
2
)
browser.find_element_by_css_selector(
".js-bindqq"
).click()
time.sleep(
5
)
browser.switch_to.window(browser.window_handles[
-
1
])
browser.switch_to.frame(
"ptlogin_iframe"
)
# iframe必须逐级切入
# 用户名 密码
# 隐藏初始界面
browser.execute_script(
'document.getElementById("qlogin").style="display: none;"'
)
browser.execute_script(
'document.getElementsByClassName("authLogin").style="display: none;"'
)
# 显示用户、密码输入界面
browser.execute_script(
'document.getElementById("web_qr_login").style="display: block;"'
)
# browser.evaluate_script('document.getElementById("batch_quto").contentEditable = true')
time.sleep(
5
)
# 输入用户、密码
elem_user
=
browser.find_element_by_name(
"u"
).send_keys(
"xxx"
)
elem_pwd
=
browser.find_element_by_name(
"p"
).send_keys(
"xxx"
)
elem_but
=
browser.find_element_by_id(
"login_button"
).click()
time.sleep(
5
)
|
scrapy集成selenium
为什么集成selenium
selenium取代下载器,编码难度大的操作交给selenium
优点:反爬虫难度大
缺点:同步selenium效率低,需要结合Twisted成异步
middleware方式
方式一
settings
|
1
2
3
|
DOWNLOADER_MIDDLEWARES
=
{
'ArticleSpider.middlewares.JSPageMiddleware'
:
1
,
}
|
middlewares
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
|
from
selenium
import
webdriver
from
scrapy.http
import
HtmlResponse
import
time
class
JSPageMiddleware(
object
):
def
__init__(
self
):
# 使用同一个self,保证只打开一个浏览器,所有spider使用一个浏览器
self
.browser
=
webdriver.Chrome(executable_path
=
"D:/Package/chromedriver.exe"
)
super
(JSPageMiddleware,
self
).__init__()
# 通过chrome请求动态网页
def
process_request(
self
, request, spider):
if
spider.name
=
=
"jobbole"
:
# self.browser = webdriver.Chrome(executable_path="D:/Package/chromedriver.exe")
self
.browser.get(request.url)
time.sleep(
1
)
print
(
"访问:{0}"
.
format
(request.url))
# browser.quit()
return
HtmlResponse(url
=
self
.browser.current_url, body
=
self
.browser.page_source,
encoding
=
"utf-8"
, request
=
request)
|
方式二
middlewares
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
|
from
scrapy.http
import
HtmlResponse
import
time
class
JSPageMiddleware(
object
):
# 通过chrome请求动态网页
def
process_request(
self
, request, spider):
if
spider.name
=
=
"jobbole"
:
# self.browser = webdriver.Chrome(executable_path="D:/Package/chromedriver.exe")
spider.browser.get(request.url)
time.sleep(
1
)
print
(
"访问:{0}"
.
format
(request.url))
# browser.quit()
return
HtmlResponse(url
=
spider.browser.current_url, body
=
spider.browser.page_source,
encoding
=
"utf-8"
, request
=
request)
|
spider
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
|
from
selenium
import
webdriver
from
scrapy.xlib.pydispatch
import
dispatcher
from
scrapy
import
signals
class
JobboleSpider(scrapy.Spider):
name
=
'jobbole'
allowed_domains
=
[
'blog.jobbole.com'
]
start_urls
=
[
'http://blog.jobbole.com/all-posts/'
]
def
__init__(
self
):
# 使用同一个self,每个spider使用一个浏览器
self
.browser
=
webdriver.Chrome(executable_path
=
"D:/Package/chromedriver.exe"
)
super
(JobboleSpider,
self
).__init__()
dispatcher.connect(
self
.spider_closed, signals.spider_closed)
# 爬虫关闭后
def
spider_closed(
self
, spider):
self
.browser.quit()
|
scrapy集成selenium模拟登录
为什么不直接用selenium替代原生下载器?
selenium是同步的方式,如果每个页面采用selenium则导致爬虫效率极低,目前并没有scrapy中的Twisted结合selenium的异步方案,因此selenium不推荐替代原生下载器
scrapy集成selenium能做什么?
由于模拟登录是编码很难解决的问题 ,因此采用selenium解决;其它页面继续用原生下载器的异步下载方案
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
|
# -*- coding: utf-8 -*-
import
re
import
datetime
try
:
import
urlparse as parse
except
:
from
urllib
import
parse
import
scrapy
from
selenium
import
webdriver
import
time
class
ZhihuSpider(scrapy.Spider):
name
=
"zhihu"
allowed_domains
=
[
"www.zhihu.com"
]
start_urls
=
[
'https://www.zhihu.com/'
]
login_cookies
=
[]
headers
=
{
"HOST"
:
"www.zhihu.com"
,
"Referer"
:
"https://www.zhizhu.com"
,
'User-Agent'
:
"Mozilla/5.0 (Windows NT 6.1; WOW64; rv:51.0) Gecko/20100101 Firefox/51.0"
}
# selenium登录保存cookies
def
get_cookies(
self
):
browser
=
webdriver.Chrome(executable_path
=
"D:/Package/chromedriver.exe"
)
time.sleep(
2
)
# 延时为了让页面加载完
browser.get(
"https://www.zhihu.com/#signin"
)
browser.find_element_by_css_selector(
".qrcode-signin-cut-button"
).click()
browser.find_element_by_css_selector(
".signup-social-buttons"
).click()
browser.find_element_by_css_selector(
".js-bindweibo"
).click()
# browser.switch_to.window(browser.window_handles[-1])
browser.find_element_by_css_selector(
".WB_iptxt"
).send_keys(
"xxx"
)
browser.find_element_by_css_selector(
"input[node-type='passwd']"
).send_keys(
"xxx"
)
browser.find_element_by_css_selector(
"a[node-type='submit']"
).click()
time.sleep(
2
)
# 延时为了让页面加载完
browser.find_element_by_css_selector(
"a[node-type='submit']"
).click()
login_cookies
=
browser.get_cookies()
browser.close()
# 第一步:先于parse方法执行,处理登陆逻辑。可以猜测,start_requests携带的cookie会给后续所有的访问自动带上
def
start_requests(
self
):
return
[scrapy.Request(
'https://www.zhihu.com/#signin'
, headers
=
self
.headers, cookies
=
self
.login_cookies,
callback
=
self
.parse)]
# 第二步:处理登陆后的逻辑
def
parse(
self
, response):
my_url
=
'https://www.zhihu.com/people/edit'
# 该页面是个人中心页,只有登录后才能访问
yield
scrapy.Request(my_url, headers
=
self
.headers)
|
爬取知乎文章和问答
scrapy shell调试
|
1
2
|
scrapy shell
-
s USER_AGENT
=
"Mozilla/5.0 (Windows NT 6.1; WOW64; rv:51.0) Gecko/20100101 Firefox/51.0"
https:
/
/
www.zhihu.com
/
question
/
56320032
|
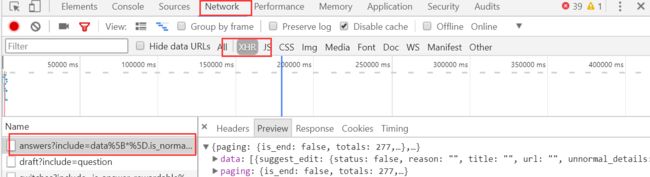
页面分析
chrome安装jsonview插件
xhr页面查看json数据,这样获取数据更轻松
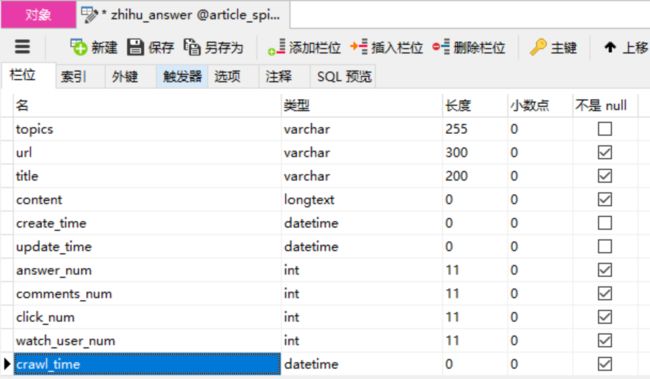
表设计
为了避免可能解析不到的字段或无法插入的情况,需要给字段设置默认值

 settings
item
pipeline
spider
settings
item
pipeline
spider
scrapy-redis分布式爬虫
优点:利用多台机器的宽带加速爬取,利用多台机器的ip加速爬取(单台机器需要限速防止ip被ban)
缺点:编码难度大于单机爬虫
分布式需要解决的问题
requests队列集中管理
去重集中管理
windows安装redis
|
1
|
https:
/
/
github.com
/
MicrosoftArchive
/
redis
/
releases
|
创建项目
|
1
|
scrapy startproject ScrapyRedisTest
|
scrapy-redis: https://github.com/rmax/scrapy-redis
scrapy-redis源码分析


import redis
# For standalone use.
DUPEFILTER_KEY = 'dupefilter:%(timestamp)s'
PIPELINE_KEY = '%(spider)s:items'
REDIS_CLS = redis.StrictRedis
REDIS_ENCODING = 'utf-8'
# Sane connection defaults.
REDIS_PARAMS = {
'socket_timeout': 30,
'socket_connect_timeout': 30,
'retry_on_timeout': True,
'encoding': REDIS_ENCODING,
}
SCHEDULER_QUEUE_KEY = '%(spider)s:requests'
SCHEDULER_QUEUE_CLASS = 'scrapy_redis.queue.PriorityQueue'
SCHEDULER_DUPEFILTER_KEY = '%(spider)s:dupefilter'
SCHEDULER_DUPEFILTER_CLASS = 'scrapy_redis.dupefilter.RFPDupeFilter'
START_URLS_KEY = '%(name)s:start_urls'
START_URLS_AS_SET = False
import six
from scrapy.utils.misc import load_object
from . import defaults
# Shortcut maps 'setting name' -> 'parmater name'.
SETTINGS_PARAMS_MAP = {
'REDIS_URL': 'url',
'REDIS_HOST': 'host',
'REDIS_PORT': 'port',
'REDIS_ENCODING': 'encoding',
}
def get_redis_from_settings(settings):
"""Returns a redis client instance from given Scrapy settings object.
This function uses ``get_client`` to instantiate the client and uses
``defaults.REDIS_PARAMS`` global as defaults values for the parameters. You
can override them using the ``REDIS_PARAMS`` setting.
Parameters
----------
settings : Settings
A scrapy settings object. See the supported settings below.
Returns
-------
server
Redis client instance.
Other Parameters
----------------
REDIS_URL : str, optional
Server connection URL.
REDIS_HOST : str, optional
Server host.
REDIS_PORT : str, optional
Server port.
REDIS_ENCODING : str, optional
Data encoding.
REDIS_PARAMS : dict, optional
Additional client parameters.
"""
# 把settings文件的配置和defaults配置更新到params
params = defaults.REDIS_PARAMS.copy()
params.update(settings.getdict('REDIS_PARAMS'))
# XXX: Deprecate REDIS_* settings.
for source, dest in SETTINGS_PARAMS_MAP.items():
val = settings.get(source)
if val:
params[dest] = val
# Allow ``redis_cls`` to be a path to a class.
if isinstance(params.get('redis_cls'), six.string_types):
params['redis_cls'] = load_object(params['redis_cls'])
return get_redis(**params) # 调用get_redis
# get_redis_from_settings函数的别名:from_settings,从这里可以知道这个文件是准备给其它文件调用的(这里没用。。)
# Backwards compatible alias.
from_settings = get_redis_from_settings
# 连接redis
def get_redis(**kwargs):
"""Returns a redis client instance.
Parameters
----------
redis_cls : class, optional
Defaults to ``redis.StrictRedis``.
url : str, optional
If given, ``redis_cls.from_url`` is used to instantiate the class.
**kwargs
Extra parameters to be passed to the ``redis_cls`` class.
Returns
-------
server
Redis client instance.
"""
redis_cls = kwargs.pop('redis_cls', defaults.REDIS_CLS)
url = kwargs.pop('url', None)
if url:
return redis_cls.from_url(url, **kwargs)
else:
return redis_cls(**kwargs)