ELK+kafka构建日志收集系统
背景:
最近线上上了ELK,但是只用了一台Redis在中间作为消息队列,以减轻前端es集群的压力,Redis的集群解决方案暂时没有接触过,并且Redis作为消息队列并不是它的强项;所以最近将Redis换成了专业的消息信息发布订阅系统Kafka, Kafka的更多介绍大家可以看这里: 传送门 ,关于ELK的知识网上有很多的哦, 此篇博客主要是总结一下目前线上这个平台的实施步骤,ELK是怎么跟Kafka结合起来的。好吧,动手!
ELK架构拓扑:
然而我这里的整个日志收集平台就是这样的拓扑:

1,使用一台Nginx代理访问kibana的请求;
2,两台es组成es集群,并且在两台es上面都安装kibana;( 以下对elasticsearch简称es )
3,中间三台服务器就是我的kafka(zookeeper)集群啦; 上面写的 消费者/生产者 这是kafka(zookeeper)中的概念;
4,最后面的就是一大堆的生产服务器啦,上面使用的是logstash,当然除了logstash也可以使用其他的工具来收集你的应用程序的日志,例如:Flume,Scribe,Rsyslog,Scripts……
角色:

软件选用:
|
elasticsearch - 1.7.3.tar.gz #这里需要说明一下,前几天使用了最新的elasticsearch2.0,java-1.8.0报错,目前未找到原因,故这里使用1.7.3版本 Logstash - 2.0.0.tar.gz kibana - 4.1.2 - linux - x64 . tar . gz 以上软件都可以从官网下载 : https : //www.elastic.co/downloads java - 1.8.0 , nginx 采用 yum 安装 |
部署步骤:
1.ES集群安装配置;
2.Logstash客户端配置(直接写入数据到ES集群,写入系统messages日志);
3.Kafka(zookeeper)集群配置;(Logstash写入数据到Kafka消息系统);
4.Kibana部署;
5.Nginx负载均衡Kibana请求;
6.案例:nginx日志收集以及MySQL慢日志收集;
7.Kibana报表基本使用;
ES集群安装配置;
es1.example.com:
1.安装java-1.8.0以及依赖包
|
yum install - y epel - release yum install - y java - 1.8.0 git wget lrzsz |
2.获取es软件包
|
wget https : //download.elastic.co/elasticsearch/elasticsearch/elasticsearch-1.7.3.tar.gz tar - xf elasticsearch - 1.7.3.tar.gz - C / usr / local ln - sv / usr / local / elasticsearch - 1.7.3 / usr / local / elasticsearch |
3.修改配置文件
|
[ root @ es1 ~ ] # vim /usr/local/elasticsearch/config/elasticsearch.yml 32 cluster . name : es - cluster #组播的名称地址 40 node . name : "es-node1 " #节点名称,不能和其他节点重复 47 node . master : true #节点能否被选举为master 51 node . data : true #节点是否存储数据 107 index . number_of_shards : 5 #索引分片的个数 111 index . number_of_replicas : 1 #分片的副本个数 145 path . conf : / usr / local / elasticsearch / config / #配置文件的路径 149 path . data : / data / es / data #数据目录路径 159 path . work : / data / es / worker #工作目录路径 163 path . logs : / usr / local / elasticsearch / logs / #日志文件路径 167 path . plugins : / data / es / plugins #插件路径 184 bootstrap . mlockall : true #内存不向swap交换 232 http . enabled : true #启用http |
4.创建相关目录
| mkdir / data / es / { data , worker , plugins } - p |
5.获取es服务管理脚本
|
[ root @ es1 ~ ] # git clone https://github.com/elastic/elasticsearch-servicewrapper.git [ root @ es1 ~ ] # mv elasticsearch-servicewrapper/service /usr/local/elasticsearch/bin/ [ root @ es1 ~ ] # /usr/local/elasticsearch/bin/service/elasticsearch install Detected RHEL or Fedora : Installing the Elasticsearch daemon . . [ root @ es1 ~ ] # #这时就会在/etc/init.d/目录下安装上es的管理脚本啦 #修改其配置: [ root @ es1 ~ ] # set . default . ES_HOME = / usr / local / elasticsearch #安装路径 set . default . ES_HEAP_SIZE = 1024 #jvm内存大小,根据实际环境调整即可 |
6.启动es ,并检查其服务是否正常
|
[ root @ es1 ~ ] # netstat -nlpt | grep -E "9200|"9300 tcp 0 0 0.0.0.0 : 9200 0.0.0.0 : * LISTEN 1684/ java tcp 0 0 0.0.0.0 : 9300 0.0.0.0 : * LISTEN 1684/ java |
访问http://192.168.2.18:9200/ 如果出现以下提示信息说明安装配置完成啦,

7.es1节点好啦,我们直接把目录复制到es2
|
[ root @ es1 local ] # scp -r elasticsearch-1.7.3 192.168.12.19:/usr/local/ [ root @ es2 local ] # ln -sv elasticsearch-1.7.3 elasticsearch [ root @ es2 local ] # elasticsearch/bin/service/elasticsearch install #es2只需要修改node.name即可,其他都与es1相同配置 |
8.安装es的管理插件
es官方提供一个用于管理es的插件,可清晰直观看到es集群的状态,以及对集群的操作管理,安装方法如下:
| [ root @ es1 local ] # /usr/local/elasticsearch/bin/plugin -i mobz/elasticsearch-head |
安装好之后,访问方式为: http://192.168.2.18:9200/_plugin/head,由于集群中现在暂时没有数据,所以显示为空,

此时,es集群的部署完成。
Logstash客户端安装配置;
在webserve1上面安装Logstassh
1.downloads 软件包 ,这里注意,Logstash是需要依赖java环境的,所以这里还是需要yum install -y java-1.8.0.
|
[ root @ webserver1 ~ ] # wget https://download.elastic.co/logstash/logstash/logstash-2.0.0.tar.gz [ root @ webserver1 ~ ] # tar -xf logstash-2.0.0.tar.gz -C /usr/local [ root @ webserver1 ~ ] # cd /usr/local/ [ root @ webserver1 local ] # ln -sv logstash-2.0.0 logstash [ root @ webserver1 local ] # mkdir logs etc |
2.提供logstash管理脚本,其中里面的配置路径可根据实际情况修改
|
#!/bin/bash #chkconfig: 2345 55 24 #description: logstash service manager #auto: Maoqiu Guo FILE = '/usr/local/logstash/etc/*.conf' #logstash配置文件 LOGBIN = '/usr/local/logstash/bin/logstash agent --verbose --config' #指定logstash配置文件的命令 LOCK = '/usr/local/logstash/locks' #用锁文件配合服务启动与关闭 LOGLOG = '--log /usr/local/logstash/logs/stdou.log' #日志 START ( ) { if [ - f $ LOCK ] ; then echo - e "Logstash is already \033[32mrunning\033[0m, do nothing." else echo - e "Start logstash service.\033[32mdone\033[m" nohup $ { LOGBIN } $ { FILE } $ { LOGLOG } & touch $ LOCK fi } STOP ( ) { if [ ! - f $ LOCK ] ; then echo - e "Logstash is already stop, do nothing." else echo - e "Stop logstash serivce \033[32mdone\033[m" rm - rf $ LOCK ps - ef | grep logstash | grep - v "grep" | awk '{print $2}' | xargs kill - s 9 > / dev / null fi } STATUS ( ) { ps aux | grep logstash | grep - v "grep" > / dev / null if [ - f $ LOCK ] && [ $ ? - eq 0 ] ; then echo - e "Logstash is: \033[32mrunning\033[0m..." else echo - e "Logstash is: \033[31mstopped\033[0m..." fi } TEST ( ) { $ { LOGBIN } $ { FILE } -- configtest } case "$1" in start ) START ; ; stop ) STOP ; ; status ) STATUS ; ; restart ) STOP sleep 2 START ; ; test ) TEST ; ; * ) echo "Usage: /etc/init.d/logstash (test|start|stop|status|restart)" ; ; esac |
3.Logstash 向es集群写数据
(1)编写一个logstash配置文件
|
[ root @ webserver1 etc ] # cat logstash.conf input { #数据的输入从标准输入 stdin { } } output { #数据的输出我们指向了es集群 elasticsearch { hosts = > [ "192.168.2.18:9200" , "192.168.2.19:9200" ] # es 主机的 ip 及端口 } } [ root @ webserver1 etc ] # |
(2)检查配置文件是否有语法错
|
[ root @ webserver1 etc ] # /usr/local/logstash/bin/logstash -f logstash.conf --configtest --verbose Configuration OK [ root @ webserver1 etc ] # |
(3)既然配置ok我们手动启动它,然后写点东西看能否写到es
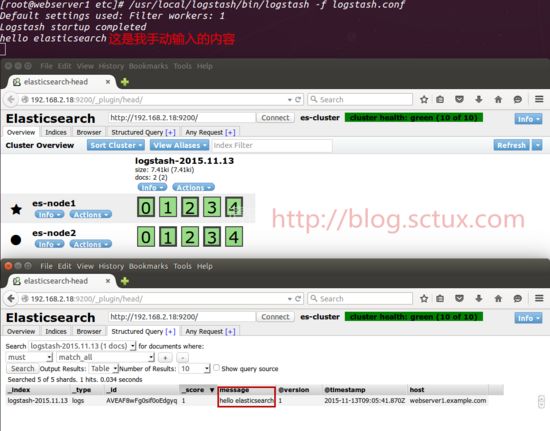
ok.上图已经看到logstash已经可以正常的工作啦.
4.下面演示一下如何收集系统日志
将之前的配置文件修改如下所示内容,然后启动logstash服务就可以在web页面中看到messages的日志写入es,并且创建了一条索引
|
[ root @ webserver1 etc ] # cat logstash.conf input { #这里的输入使用的文件,即日志文件messsages file { path = > "/var/log/messages" #这是日志文件的绝对路径 start_position = > "beginning" #这个表示从 messages 的第一行读取,即文件开始处 } } output { #输出到 es elasticsearch { hosts = > [ "192.168.2.18:9200" , "192.168.2.19:9200" ] index = > "system-messages-%{+YYYY-MM}" #这里将按照这个索引格式来创建索引 } } [ root @ webserver1 etc ] # |
启动logstash后,我们来看head这个插件的web页面
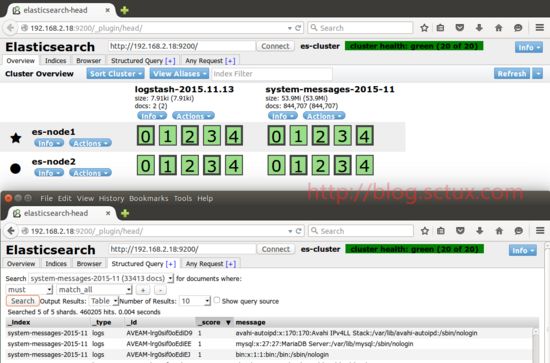
ok,系统日志我们已经成功的收集,并且已经写入到es集群中,那上面的演示是logstash直接将日志写入到es集群中的,这种场合我觉得如果量不是很大的话直接像上面已将将输出output定义到es集群即可,如果量大的话需要加上消息队列来缓解es集群的压力。前面已经提到了我这边之前使用的是单台redis作为消息队列,但是redis不能作为list类型的集群,也就是redis单点的问题没法解决,所以这里我选用了kafka ;下面就在三台server上面安装kafka集群
Kafka集群安装配置;
在搭建kafka集群时,需要提前安装zookeeper集群,当然kafka已经自带zookeeper程序只需要解压并且安装配置就行了
kafka1上面的配置:
1.获取软件包.官网: http://kafka.apache.org
|
[ root @ kafka1 ~ ] # wget http://mirror.rise.ph/apache/kafka/0.8.2.1/kafka_2.11-0.8.2.1.tgz [ root @ kafka1 ~ ] # tar -xf kafka_2.11-0.8.2.1.tgz -C /usr/local/ [ root @ kafka1 ~ ] # cd /usr/local/ [ root @ kafka1 local ] # ln -sv kafka_2.11-0.8.2.1 kafka |
2.配置zookeeper集群,修改配置文件
|
[ root @ kafka1 ~ ] # vim /usr/local/kafka/config/zookeeper.propertie dataDir = / data / zookeeper clienrtPort = 2181 tickTime = 2000 initLimit = 20 syncLimit = 10 server . 2 = 192.168.2.22 : 2888 : 3888 server . 3 = 192.168.2.23 : 2888 : 3888 server . 4 = 192.168.2.24 : 2888 : 3888 #说明: tickTime : 这个时间是作为 Zookeeper 服务器之间或客户端与服务器之间维持心跳的时间间隔,也就是每个 tickTime 时间就会发送一个心跳。 2888 端口:表示的是这个服务器与集群中的 Leader 服务器交换信息的端口; 3888 端口:表示的是万一集群中的 Leader 服务器挂了,需要一个端口来重新进行选举,选出一个新的 Leader ,而这个端口就是用来执行选举时服务器相互通信的端口。 |
3.创建zookeeper所需要的目录
| [ root @ kafka1 ~ ] # mkdir /data/zookeeper |
4.在/data/zookeeper目录下创建myid文件,里面的内容为数字,用于标识主机,如果这个文件没有的话,zookeeper是没法启动的哦
| [ root @ kafka1 ~ ] # echo 2 > /data/zookeeper/myid |
以上就是zookeeper集群的配置,下面等我配置好kafka之后直接复制到其他两个节点即可
5.kafka配置
|
[ root @ kafka1 ~ ] # vim /usr/local/kafka/config/server.properties broker . id = 2 # 唯一,填数字,本文中分别为 2 / 3 / 4 prot = 9092 # 这个 broker 监听的端口 host . name = 192.168.2.22 # 唯一,填服务器 IP log . dir = / data / kafka - logs # 该目录可以不用提前创建,在启动时自己会创建 zookeeper . connect = 192.168.2.22 : 2181 , 192.168.2.23 : 2181 , 192.168.2.24 :2181 #这个就是 zookeeper 的 ip 及端口 num . partitions = 16 # 需要配置较大 分片影响读写速度 log . dirs = / data / kafka - logs # 数据目录也要单独配置磁盘较大的地方 log . retention . hours = 168 # 时间按需求保留过期时间 避免磁盘满 |
6.将kafka(zookeeper)的程序目录全部拷贝至其他两个节点
|
[ root @ kafka1 ~ ] # scp -r /usr/local/kafka 192.168.2.23:/usr/local/ [ root @ kafka1 ~ ] # scp -r /usr/local/kafka 192.168.2.24:/usr/local/ |
7.修改两个借点的配置,注意这里除了以下两点不同外,都是相同的配置
|
( 1 ) zookeeper 的配置 mkdir / data / zookeeper echo "x" > / data / zookeeper / myid ( 2 ) kafka 的配置 broker . id = 2 host . name = 192.168.2.22 |
8.修改完毕配置之后我们就可以启动了,这里先要启动zookeeper集群,才能启动kafka
我们按照顺序来,kafka1 –> kafka2 –>kafka3
|
[ root @ kafka1 ~ ] # /usr/local/kafka/bin/zookeeper-server-start.sh /usr/local/kafka/config/zookeeper.properties & #zookeeper启动命令 [ root @ kafka1 ~ ] # /usr/local/kafka/bin/zookeeper-server-stop.sh #zookeeper停止的命令 |
注意,如果zookeeper有问题 nohup的日志文件会非常大,把磁盘占满,这个zookeeper服务可以通过自己些服务脚本来管理服务的启动与关闭。
后面两台执行相同操作,在启动过程当中会出现以下报错信息
|
[ 2015 - 11 - 13 19 : 18 : 04 , 225 ] WARN Cannot open channel to 3 at election address / 192.168.2.23 : 3888 ( org . apache . zookeeper . server . quorum . QuorumCnxManager ) java . net . ConnectException : Connection refused at java . net . PlainSocketImpl . socketConnect ( Native Method ) at java . net . AbstractPlainSocketImpl . doConnect ( AbstractPlainSocketImpl . java : 350 ) at java . net . AbstractPlainSocketImpl . connectToAddress ( AbstractPlainSocketImpl . java : 206 ) at java . net . AbstractPlainSocketImpl . connect ( AbstractPlainSocketImpl . java :188 ) at java . net . SocksSocketImpl . connect ( SocksSocketImpl . java : 392 ) at java . net . Socket . connect ( Socket . java : 589 ) at org . apache . zookeeper . server . quorum . QuorumCnxManager . connectOne( QuorumCnxManager . java : 368 ) at org . apache . zookeeper . server . quorum . QuorumCnxManager . connectAll (QuorumCnxManager . java : 402 ) at org . apache . zookeeper . server . quorum . FastLeaderElection . lookForLeader( FastLeaderElection . java : 840 ) at org . apache . zookeeper . server . quorum . QuorumPeer . run ( QuorumPeer . java : 762 ) [ 2015 - 11 - 13 19 : 18 : 04 , 232 ] WARN Cannot open channel to 4 at election address / 192.168.2.24 : 3888 ( org . apache . zookeeper . server . quorum . QuorumCnxManager ) java . net . ConnectException : Connection refused at java . net . PlainSocketImpl . socketConnect ( Native Method ) at java . net . AbstractPlainSocketImpl . doConnect ( AbstractPlainSocketImpl . java : 350 ) at java . net . AbstractPlainSocketImpl . connectToAddress ( AbstractPlainSocketImpl . java : 206 ) at java . net . AbstractPlainSocketImpl . connect ( AbstractPlainSocketImpl . java :188 ) at java . net . SocksSocketImpl . connect ( SocksSocketImpl . java : 392 ) at java . net . Socket . connect ( Socket . java : 589 ) at org . apache . zookeeper . server . quorum . QuorumCnxManager . connectOne( QuorumCnxManager . java : 368 ) at org . apache . zookeeper . server . quorum . QuorumCnxManager . connectAll (QuorumCnxManager . java : 402 ) at org . apache . zookeeper . server . quorum . FastLeaderElection . lookForLeader( FastLeaderElection . java : 840 ) at org . apache . zookeeper . server . quorum . QuorumPeer . run ( QuorumPeer . java : 762 ) [ 2015 - 11 - 13 19 : 18 : 04 , 233 ] INFO Notification time out : 6400 ( org . apache. zookeeper . server . quorum . FastLeaderElection ) |
由于zookeeper集群在启动的时候,每个结点都试图去连接集群中的其它结点,先启动的肯定连不上后面还没启动的,所以上面日志前面部分的异常是可以忽略的。通过后面部分可以看到,集群在选出一个Leader后,最后稳定了。
其他节点也可能会出现类似的情况,属于正常。
9.zookeeper服务检查
|
[ root @ kafka1 ~ ] # netstat -nlpt | grep -E "2181|2888|3888" tcp 0 0 192.168.2.24 : 3888 0.0.0.0 : * LISTEN 1959 / java tcp 0 0 0.0.0.0 : 2181 0.0.0.0 : * LISTEN 1959/ java [ root @ kafka2 ~ ] # netstat -nlpt | grep -E "2181|2888|3888" tcp 0 0 192.168.2.23 : 3888 0.0.0.0 : * LISTEN 1723 / java tcp 0 0 0.0.0.0 : 2181 0.0.0.0 : * LISTEN 1723/ java [ root @ kafka3 ~ ] # netstat -nlpt | grep -E "2181|2888|3888" tcp 0 0 192.168.2.24 : 3888 0.0.0.0 : * LISTEN 950 / java tcp 0 0 0.0.0.0 : 2181 0.0.0.0 : * LISTEN 950 /java tcp 0 0 192.168.2.24 : 2888 0.0.0.0 : * LISTEN 950 / java #可以看出,如果哪台是Leader,那么它就拥有2888这个端口 |
ok. 这时候zookeeper集群已经启动起来了,下面启动kafka,也是依次按照顺序启动
|
[ root @ kafka1 ~ ] # nohup /usr/local/kafka/bin/kafka-server-start.sh /usr/local/kafka/config/server.properties & #kafka启动的命令 [ root @ kafka1 ~ ] # /usr/local/kafka/bin/kafka-server-stop.sh #kafka停止的命令 |
注意,跟zookeeper服务一样,如果kafka有问题 nohup的日志文件会非常大,把磁盘占满,这个kafka服务同样可以通过自己些服务脚本来管理服务的启动与关闭。
此时三台上面的zookeeper及kafka都已经启动完毕,来检测以下吧
(1)建立一个主题
|
[ root @ kafka1 ~ ] # /usr/local/kafka/bin/kafka-topics.sh --create --zookeeper localhost:2181 --replication-factor 3 --partitions 1 --topic summer #注意:factor大小不能超过broker数 |
(2)查看有哪些主题已经创建
|
[ root @ kafka1 ~ ] # /usr/local/kafka/bin/kafka-topics.sh --list --zookeeper 192.168.2.22:2181 #列出集群中所有的topic summer #已经创建成功 |
(3)查看summer这个主题的详情
|
[ root @ kafka1 ~ ] # /usr/local/kafka/bin/kafka-topics.sh --describe --zookeeper 192.168.2.22:2181 --topic summer Topic : summer PartitionCount : 1 ReplicationFactor : 3 Configs : Topic : summer Partition : 0 Leader : 2 Replicas : 2 , 4 , 3 Isr : 2 , 4 , 3 #主题名称:summer #Partition:只有一个,从0开始 #leader :id为2的broker #Replicas 副本存在于broker id为2,3,4的上面 #Isr:活跃状态的broker |
(4)发送消息,这里使用的是生产者角色
|
[ root @ kafka1 ~ ] # /bin/bash /usr/local/kafka/bin/kafka-console-producer.sh --broker-list 192.168.2.22:9092 --topic summer This is a messages welcome to kafka |
(5)接收消息,这里使用的是消费者角色
|
[ root @ kafka2 ~ ] # /usr/local/kafka/bin/kafka-console-consumer.sh --zookeeper 192.168.2.24:2181 --topic summer --from-beginning This is a messages welcome to kafka |
如果能够像上面一样能够接收到生产者发过来的消息,那说明基于kafka的zookeeper集群就成功啦。
10,下面我们将webserver1上面的logstash的输出改到kafka上面,将数据写入到kafka中
(1)修改webserver1上面的logstash配置,如下所示:各个参数可以到 官网 查询.
|
root @ webserver1 etc ] # cat logstash.conf input { #这里的输入还是定义的是从日志文件输入 file { type = > "system-message" path = > "/var/log/messages" start_position = > "beginning" } } output { #stdout { codec => rubydebug } #这是标准输出到终端,可以用于调试看有没有输出,注意输出的方向可以有多个 kafka { #输出到kafka bootstrap_servers = > "192.168.2.22:9092,192.168.2.23:9092,192.168.2.24:9092" #他们就是生产者 topic_id = > "system-messages" #这个将作为主题的名称,将会自动创建 compression_type = > "snappy" #压缩类型 } } [ root @ webserver1 etc ] # |
(2)配置检测
|
[ root @ webserver1 etc ] # /usr/local/logstash/bin/logstash -f logstash.conf --configtest --verbose Configuration OK [ root @ webserver1 etc ] # |
(2)启动Logstash,这里我直接在命令行执行即可
| [ root @ webserver1 etc ] # /usr/local/logstash/bin/logstash -f logstash.conf |
(3)验证数据是否写入到kafka,这里我们检查是否生成了一个叫system-messages的主题
|
[ root @ kafka1 ~ ] # /usr/local/kafka/bin/kafka-topics.sh --list --zookeeper 192.168.2.22:2181 summer system - messages #可以看到这个主题已经生成了 #再看看这个主题的详情: [ root @ kafka1 ~ ] # /usr/local/kafka/bin/kafka-topics.sh --describe --zookeeper 192.168.2.22:2181 --topic system-messages Topic : system - messages PartitionCount : 16 ReplicationFactor : 1 Configs : Topic : system - messages Partition : 0 Leader : 2 Replicas : 2 Isr : 2 Topic : system - messages Partition : 1 Leader : 3 Replicas : 3 Isr : 3 Topic : system - messages Partition : 2 Leader : 4 Replicas : 4 Isr : 4 Topic : system - messages Partition : 3 Leader : 2 Replicas : 2 Isr : 2 Topic : system - messages Partition : 4 Leader : 3 Replicas : 3 Isr : 3 Topic : system - messages Partition : 5 Leader : 4 Replicas : 4 Isr : 4 Topic : system - messages Partition : 6 Leader : 2 Replicas : 2 Isr : 2 Topic : system - messages Partition : 7 Leader : 3 Replicas : 3 Isr : 3 Topic : system - messages Partition : 8 Leader : 4 Replicas : 4 Isr : 4 Topic : system - messages Partition : 9 Leader : 2 Replicas : 2 Isr : 2 Topic : system - messages Partition : 10 Leader : 3 Replicas : 3 Isr : 3 Topic : system - messages Partition : 11 Leader : 4 Replicas : 4 Isr : 4 Topic : system - messages Partition : 12 Leader : 2 Replicas : 2 Isr : 2 Topic : system - messages Partition : 13 Leader : 3 Replicas : 3 Isr : 3 Topic : system - messages Partition : 14 Leader : 4 Replicas : 4 Isr : 4 Topic : system - messages Partition : 15 Leader : 2 Replicas : 2 Isr : 2 [ root @ kafka1 ~ ] # |
可以看出,这个主题生成了16个分区,每个分区都有对应自己的Leader,但是我想要有10个分区,3个副本如何办?还是跟我们上面一样命令行来创建主题就行,当然对于logstash输出的我们也可以提前先定义主题,然后启动logstash 直接往定义好的主题写数据就行啦,命令如下:
| [ root @ kafka1 ~ ] # /usr/local/kafka/bin/kafka-topics.sh --create --zookeeper 192.168.2.22:2181 --replication-factor 3 --partitions 10 --topic TOPIC_NAME |
好了,我们将logstash收集到的数据写入到了kafka中了,在实验过程中我使用while脚本测试了如果不断的往kafka写数据的同时停掉两个节点,数据写入没有任何问题。
那如何将数据从kafka中读取然后给我们的es集群呢?那下面我们在kafka集群上安装Logstash,安装步骤不再赘述;三台上面的logstash 的配置如下,作用是将kafka集群的数据读取然后转交给es集群,这里为了测试我让他新建一个索引文件,注意这里的输入日志还是messages,主题名称还是“system-messages”
|
[ root @ kafka1 etc ] # more logstash.conf input { kafka { zk_connect = > "192.168.2.22:2181,192.168.2.23:2181,192.168.2.24:2181" #消费者们 topic_id = > "system-messages" codec = > plain reset_beginning = > false consumer_threads = > 5 decorate_events = > true } } output { elasticsearch { hosts = > [ "192.168.2.18:9200" , "192.168.2.19:9200" ] index = > "test-system-messages-%{+YYYY-MM}" #为了区分之前实验,我这里新生成的所以名字为“test-system-messages-%{+YYYY-MM}” } } |
在三台kafka上面启动Logstash,注意我这里是在命令行启动的;
|
[ root @ kafka1 etc ] # pwd / usr / local / logstash / etc [ root @ kafka1 etc ] # /usr/local/logstash/bin/logstash -f logstash.conf [ root @ kafka2 etc ] # pwd / usr / local / logstash / etc [ root @ kafka2 etc ] # /usr/local/logstash/bin/logstash -f logstash.conf [ root @ kafka3 etc ] # pwd / usr / local / logstash / etc [ root @ kafka3 etc ] # /usr/local/logstash/bin/logstash -f logstash.conf |
在webserver1上写入测试内容,即webserver1上面利用message这个文件来测试,我先将其清空,然后启动
|
[ root @ webserver1 etc ] # >/var/log/messages [ root @ webserver1 etc ] # echo "我将通过kafka集群达到es集群哦^0^" >> /var/log/messages #启动logstash,让其读取messages中的内容 |
下图为我在客户端写入到kafka集群的同时也将其输入到终端,这里写入了三条内容

而下面三张图侧可以看出,三台Logstash 很平均的从kafka集群当中读取出来了日志内容

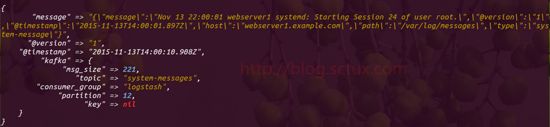
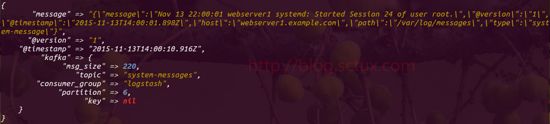
再来看看我们的es管理界面

ok ,看到了吧,
流程差不多就是下面 酱紫咯
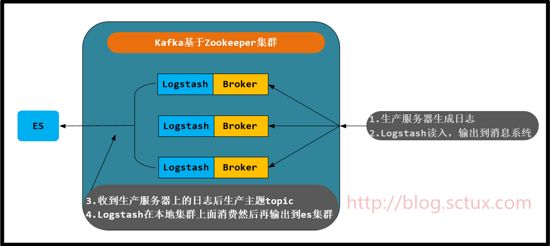
由于篇幅较长,我将
4.Kibana部署;
5.Nginx负载均衡Kibana请求;
6.案例:nginx日志收集以及MySQL慢日志收集;
7.Kibana报表基本使用;
Kibana的部署;
Kibana的作用,想必大家都知道了就是一个展示工具,报表内容非常的丰富;
下面我们在两台es上面搭建两套kibana
1.获取kibana软件包
|
1
2
|
[root@es1 ~]# wget https://download.elastic.co/kibana/kibana/kibana-4.1.2-linux-x64.tar.gz
[root@es1 ~]# tar -xf kibana-4.2.0-linux-x64.tar.gz -C /usr/local/
|
2.修改配置文件
|
1
2
3
4
5
6
7
8
9
|
[root@es1 ~]# cd /usr/local/
[root@es1 local]# ln -sv kibana-4.1.2-linux-x64 kibana
`kibana' -> `kibana-4.2.0-linux-x64'
[root@es1 local]# cd kibana
[root@es1 kibana]# vim config/kibana.yml
server.port: 5601 #默认端口可以修改的
server.host: "0.0.0.0" #kibana监听的ip
elasticsearch.url: "http://localhost:9200" #由于es在本地主机上面,所以这个选项打开注释即可
|
3.提供kibana服务管理脚本,我这里写了个相对简单的脚本
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
|
[root@es1 config]# cat /etc/init.d/kibana
#!/bin/bash
#chkconfig: 2345 55 24
#description: kibana service manager
KIBBIN='/usr/local/kibana/bin/kibana'
LOCK='/usr/local/kibana/locks'
START() {
if [ -f $LOCK ];then
echo -e "kibana is already \033[32mrunning\033[0m, do nothing."
else
echo -e "Start kibana service.\033[32mdone\033[m"
cd /usr/local/kibana/bin
nohup ./kibana & >/dev/null
touch $LOCK
fi
}
STOP() {
if [ ! -f $LOCK ];then
echo -e "kibana is already stop, do nothing."
else
echo -e "Stop kibana serivce \033[32mdone\033[m"
rm -rf $LOCK
ps -ef | grep kibana | grep -v "grep" | awk '{print $2}' | xargs kill -s 9 >/dev/null
fi
}
STATUS() {
Port=$(netstat -tunl | grep ":5602")
if [ "$Port" != "" ] && [ -f $LOCK ];then
echo -e "kibana is: \033[32mrunning\033[0m..."
else
echo -e "kibana is: \033[31mstopped\033[0m..."
fi
}
case "$1" in
start)
START
;;
stop)
STOP
;;
status)
STATUS
;;
restart)
STOP
sleep 2
START
;;
*)
echo "Usage: /etc/init.d/kibana (|start|stop|status|restart)"
;;
esac
|
4.启动kibana服务
|
1
2
3
4
|
[root@es1 config]# chkconfig --add kibana
[root@es1 config]# service kibana start
Start kibana service.done
[root@es1 config]#
|
5.服务检查
|
1
2
3
|
[root@es1 config]# ss -tunl | grep "5601"
tcp LISTEN 0 511 *:5601 *:*
[root@es1 config]#
|
ok,此时我直接访问es1这台主机的5601端口
ok,能成功的访问5601端口,那我把es1这台的配置放到es2上面去然后启动,效果跟访问es1一样
Nginx负载均衡kibana的请求
1.在nginx-proxy上面yum安装nginx
|
1
|
yum install -y nignx
|
2.编写配置文件es.conf
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
|
[root@saltstack-node1 conf.d]# pwd
/etc/nginx/conf.d
[root@saltstack-node1 conf.d]# cat es.conf
upstream es {
server 192.168.2.18:5601 max_fails=3 fail_timeout=30s;
server 192.168.2.19:5601 max_fails=3 fail_timeout=30s;
}
server {
listen 80;
server_name localhost;
location / {
proxy_pass http://es/;
index index.html index.htm;
#auth
auth_basic "ELK Private";
auth_basic_user_file /etc/nginx/.htpasswd;
}
}
|
3.创建认证
|
1
2
3
4
5
6
7
8
|
[root@saltstack-node1 conf.d]# htpasswd -cm /etc/nginx/.htpasswd elk
New password:
Re-type new password:
Adding password for user elk-user
[root@saltstack-node1 conf.d]# /etc/init.d/nginx restart
Stopping nginx: [ OK ]
Starting nginx: [ OK ]
[root@saltstack-node1 conf.d]#
|
4.直接输入认证用户及密码就可访问啦http://192.168.2.21/
Nginx及MySQL慢日志收集
首先我们在webserver1上面都分别安装了nginx 及mysql.
1.为了方便nginx日志的统计搜索,这里设置nginx访问日志格式为json
(1)修改nginx主配置文件
说明:如果想实现日志的报表展示,最好将业务日志直接以json格式输出,这样可以极大减轻cpu负载,也省得运维需要写负载的filter过滤正则。
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
|
[root@webserver1 nginx]# vim nginx.conf
log_format json '{"@timestamp":"$time_iso8601",'
'"@version":"1",'
'"client":"$remote_addr",'
'"url":"$uri",'
'"status":"$status",'
'"domain":"$host",'
'"host":"$server_addr",'
'"size":$body_bytes_sent,'
'"responsetime":$request_time,'
'"referer": "$http_referer",'
'"ua": "$http_user_agent"'
'}';
access_log /var/log/access_json.log json;
|
(2)收集nginx日志和MySQL日志到消息队列中;这个文件我们是定义在客户端,即生产服务器上面的Logstash文件哦.
注意:这里刚搭建完毕,没有什么数据,为了展示效果,我这里导入了线上的nginx和MySQL慢日志
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
|
input {
file { #从nginx日志读入
type => "nginx-access"
path => "/var/log/nginx/access.log"
start_position => "beginning"
codec => "json" #这里指定 codec格式为json
}
file { #从MySQL慢日志读入
type => "slow-mysql"
path => "/var/log/mysql/slow-mysql.log"
start_position => "beginning"
codec => multiline { #这里用到了logstash的插件功能,将本来属于一行的多行日志条目整合在一起,让他属于一条
pattern => "^# User@Host" #用到了正则去匹配
negate => true
what => "previous"
}
}
}
output {
# stdout { codec=> rubydebug }
if [type] == "nginx-access" { #通过判断input中定义的type,来让它在kafka集群中生成的主题名称
kafka { #输出到kafka集群
bootstrap_servers => "192.168.2.22:9092,192.168.2.23:9092,192.168.2.24:9092" #生产者们
topic_id => "nginx-access" #主题名称
compression_type => "snappy" #压缩类型
}
}
if [type] == "slow-mysql" {
kafka {
bootstrap_servers => "192.168.2.22:9092,192.168.2.23:9092,192.168.2.24:9092"
topic_id => "slow-mysql"
compression_type => "snappy"
}
}
}
|
(3)Logstash 从kafka集群中读取日志存储到es中,这里的定义logstash文件是在三台kafka服务器上面的哦,并且要保持一致,你可以在一台上面修改测试好之后,拷贝至另外两台即可。
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
|
input {
kafka {
zk_connect => "192.168.2.22:2181,192.168.2.23:2181,192.168.2.24:2181"
type => "nginx-access"
topic_id => "nginx-access"
codec => plain
reset_beginning => false
consumer_threads => 5
decorate_events => true
}
kafka {
zk_connect => "192.168.2.22:2181,192.168.2.23:2181,192.168.2.24:2181"
type => "slow-mysql"
topic_id => "slow-mysql"
codec => plain
reset_beginning => false
consumer_threads => 5
decorate_events => true
}
}
output {
# stdout { codec=> rubydebug }
if [type] == "nginx-access" {
elasticsearch {
hosts => ["192.168.2.18:9200","192.168.2.19:9200"]
index => "nginx-access-%{+YYYY-MM}"
}
}
if [type] == "slow-mysql" {
elasticsearch {
hosts => ["192.168.2.18:9200","192.168.2.19:9200"]
index => "slow-mysql-%{+YYYY-MM}"
}
}
}
|
通过上图可以看到,nginx日志以及MySQL慢日志已经成功抵达es集群
然后我们在kibana上面创建索引就可以啦
(4)创建nginx-access 日志索引
此时就可以看到索引啦
(5)创建MySQL慢日志索引
p
MySQL的索引也出来啦
Kibana报表展示
kibana报表功能非常的强大,也就是可视化;可以制作出下面不同类型的图形
下面就是我简单的一些图形展示
由于篇幅问题,可以看官方介绍。
参考:
https://github.com/liquanzhou/ops_doc/tree/master/Service/kafka
http://www.lujinhong.com/kafka%E9%9B%86%E7%BE%A4%E6%93%8D%E4%BD%9C%E6%8C%87%E5%8D%97.html
http://www.it165.net/admin/html/201405/3192.html
http://blog.csdn.net/lizhitao/article/details/39499283
https://taoistwar.gitbooks.io/spark-operationand-maintenance-management/content/spark_relate_software/zookeeper_install.html
转自: http://blog.sctux.com/?p=451