一、过程
目的:将25000条评论当中的热词提取出来,并制作词云图
1)数据下载
链接:https://pan.baidu.com/s/1qJPazyFBSzYqjv8k7eb-VA 提取码:rufi
在某路径下(如桌面)新建wordCloud文件夹,将上面下载的数据转移到该文件夹内,在该文件夹内按下shift+鼠标右键,然后选择:在此处打开命令窗口,即开启dos窗口,然后输入jupyter notebook,开始编程
如果读者并未安装jupyter notebook,安装过程请参考:jupyter notebook的安装与使用
2)文件读取
import pandas as pd
df = pd.read_csv('labeledTrainData.csv', sep='\t')
df.head()我们看到下面的运行结果中存在一些斜杠,这些并不是我们想看到的词,因此我们修改上面的代码,加上escapechar参数:
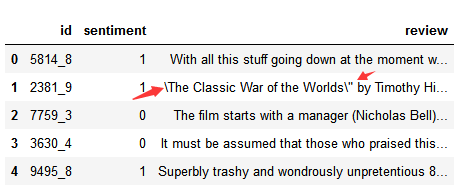
import pandas as pd
df = pd.read_csv('labeledTrainData.csv', sep='\t', escapechar='\\')
df.head()

3)获取评论列表
df['review']是Series对象,Series对象有tolist方法,返回值的数据类型为列表list。df['review'].tolist()的返回值是每一条评论组成的列表list
导入BeautifulSoup库,去除评论当中的标签
review_list = df['review'].tolist()
from bs4 import BeautifulSoup as bs
comment_list = [ bs(k, 'lxml').text for k in review_list ]
第三行代码如果出如下错误:
![]()
需要安装lxml包:
pip install lxml

从上可以看出经过BeautifulSoup处理,内容部分的
已经被去除
4)去除标点并让所有字母小写
all_comment = ' '.join(comment_list)
import re
pattern = r'[^\w\s]'
replace = ''
all_comment = re.sub(pattern, replace, all_comment)
all_comment = all_comment.lower()关于正则匹配:https://blog.csdn.net/wl_ss/article/details/78241782
5)词频统计
首先引入collection中的Counter方法,Counter方法需要填入1个参数,参数的数据类型为列表。Counter方法的返回值数据类型是一个collections.Counter对象,集成了字典dict的一些特性
from collections import Counter
word_list = all_comment.split(' ')
wordCount_dict = Counter(word_list)
wordCount_dict 
6)停顿词删除
下载停词文件,链接:https://pan.baidu.com/s/1zNp4m83uipKF8zVieZF0sw 提取码:3o0a
with open('stopwords.txt') as file:
stopword_list = [k.strip() for k in file]
for stopword in stopword_list:
if stopword in wordCount_dict:
wordCount_dict.pop(stopword)
wordCount_dict.pop('')
7)取出出现次数排名前200的单词
sorted(wordCount_dict.items(), key=lambda k:k[1], reverse=True)[0:200]

choices_number = 200
count_list = sorted(wordCount_dict.items(), key=lambda k:k[1],reverse=True)
count_list = count_list[:choices_number]
keyword_list = [ k[0] for k in count_list ]
value_list = [ k[1] for k in count_list ]
8)利用pyecharts库绘图
安装包:pip install pyecharts
wordcloud.add需要填入4个参数,第1个参数是标签,可以为空,第2个参数是出现的单词,第3个参数是单词对应的词频,第4个参数是词云上字体大小
from pyecharts import WordCloud
wordcloud = WordCloud(width=800, height=500)
wordcloud.add('', keyword_list, value_list, word_size_range=[20, 100])
wordcloud
9)绘图结果
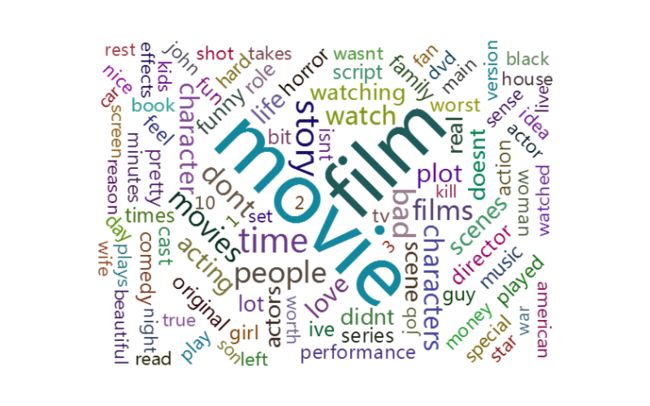
10)致谢
本文参考简书:https://www.jianshu.com/p/96b983784dae
感谢作者的详细过程,让自己学会了词云图制作,再次感谢!