2019独角兽企业重金招聘Python工程师标准>>> 
废话:
第一次学习并尝试分析、爬取一个网站的数据,全部是从零开始的经验,希望对各位看官有帮助,当然,本次爬取的是一个比较简单的网页,没有任何反爬虫措施的网页。
网上查了一下Java爬数据,最原始的方式是用请求网页的字符串然后用正则解析标签,再查了一下有什么爬虫、解析网页的工具,然后就查到了这个gecco,当是也没多想,就是干吧。
主要参考了两个博客:
1、入门到精通:https://segmentfault.com/a/1190000010086659
2、精通到放弃:https://blog.csdn.net/gf771115/article/details/53218022
最后附上官方地址:http://www.geccocrawler.com/
导入gecco包
maven代码:
com.geccocrawler
gecco
1.0.8
目标网站
因为我是搞定了才会过来写博客的,所以就直奔主题,说明我主要要做什么了。
网站是:https://doutushe.com/portal/index/index
(站主要是看到了,请联系我删除,没看到的话,嘿嘿,我就不厚道的继续放着了)
经过观察,分页之后的格式是:https://doutushe.com/portal/index/index/p/1(没错,这个1就是对应页数)
页面大概是这样的:

然后每一个帖子的详情:https://doutushe.com/portal/article/index/id/XR5(最后的XR5是帖子id)
页面是这样的:
我的任务
我的任务很简单,就是把列表的所有的帖子的标题、所有的图片,这两个数据爬下来
逻辑
1、访问第1页
2、读取第一页的帖子列表,然后进入每一个帖子的帖子详情,将标题、图片列表的数据拿出来
3、访问下一页,然后遍历帖子列表拿数据,一直循环,直到没有下一页
第一步:解析第一页
废话:按照我做的时候,我解析第一页的时候,是先解析列表信息,最后才开始研究怎么解析出来哪个是下一页,现在是回过来写的,所以就一步到位了,直接解析第一页的列表信息和下一页的连接地址
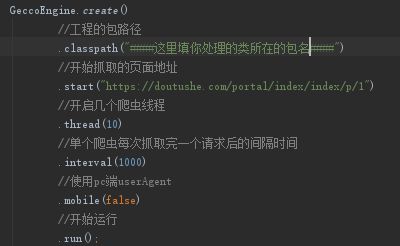
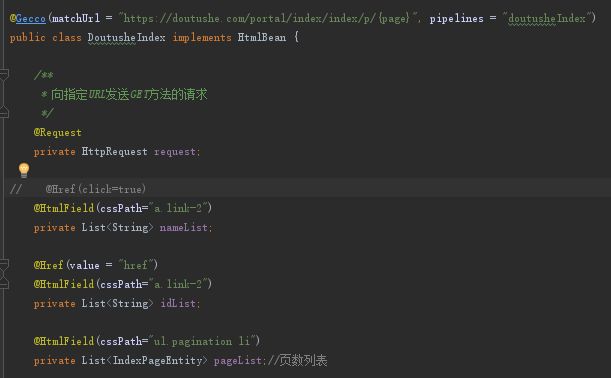
1、创建一个类(我这里命名是:DoutuSheIndex)

大概意思是主要gecco爬了这个https://doutushe.com/portal/index/index/p/格式的网址,就会交给DuotusheIndex这个类来解析,后面这个popelines则是解析出来的结果传送到另外一个类做下一步处理,这个popelines算是一个标识,之后就会发现玄机。
我们通过页面的审查元素,可以看到列表的标签信息(如下图),我们所要的信息,基本上全部包含在这个class为link-2的a标签里面:

所以我分为两个List
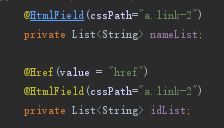
这里需要再次提醒的是,@Href注解不能单独使用,必须用@HtmlField定位到对应的地方,然后再在上方加上@Href标签才能拿到href的值,否则拿到的就是a标签的值,其他的注解用法,可以直接查看gecco官网的“使用手册”,吐槽一些,写得好简单,只有说明没有示例,有时候不太明白他的意思,又没有例子可以参考,蛋蛋的忧伤。
然后接着也需要将下一页的地址给解析出来,给分页审查元素的时候,得到下图:
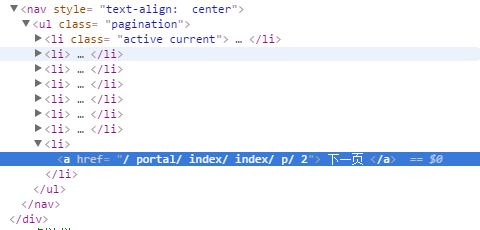
我没有找到只解析后面一个或者是根据标签内容过滤的方法,所以我只能是用最原始的办法,就是将所有的分页链接都解析出来。所以就涉及到了另外一个东西,前面是解析单个内容,这次解析的话,除了解析分页的连接,我还需要页数,以判定是否是下一页,所以需要解析的是一个对象。
这东西跟json是一个道理,我要将一个东西直接解析为一个对象的时候,首先要将整个对象的数据拿下来,然后再把这串数据解析为对象。看上面的图,ul标签的li标签就是一个对象的数据,所以我们就将一个个li定位出来,也就有了下图的解析(IndexPageEntity是页数的对象)(建议第一次的时候,将IndexPageEntity改成String,看看输出了什么):

接着是IndexPageEntity:
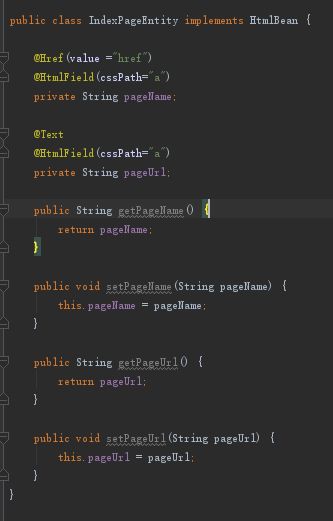
因为a里面已经包含了我们所要的信息,所以我们将a标签解析为我们需要的数据格式就可以了。
最后附上DoutusheIndex类的详细内容(省略get set方法,注:代码中必须要有)
2、创建一个类,我这里命名(FinishDoutusheIndex)
这个类就是前面提到的需要用到popelines的,这个类主要的作用就是等待DoutusheIndex类解析好了网页的内容之后,跳到这一个类来处理下一步的信息,比如我这里如下图这样写:
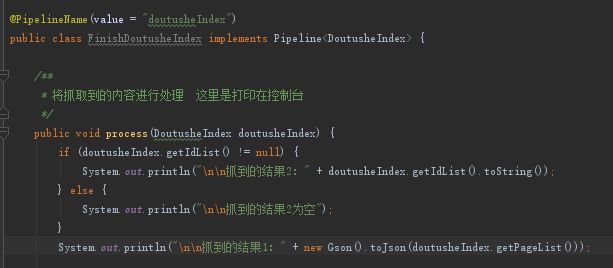
然后得到的输出结果是(我没有打印名称列表):

我们需要的信息已经打印出来了,所以我们需要完善我们的逻辑。
3、第一页的逻辑
第一页的数据我们其实不需要保存的,详情页的数据才是我们需要的,所以第一页的数据解析出来之后,就要执行我们的两个逻辑了:1、遍历列表(打开列表的每一个详情页)2、跳到下一页
所以我们改一下FinishDoutusheIndex就可以了,修改之后如下:
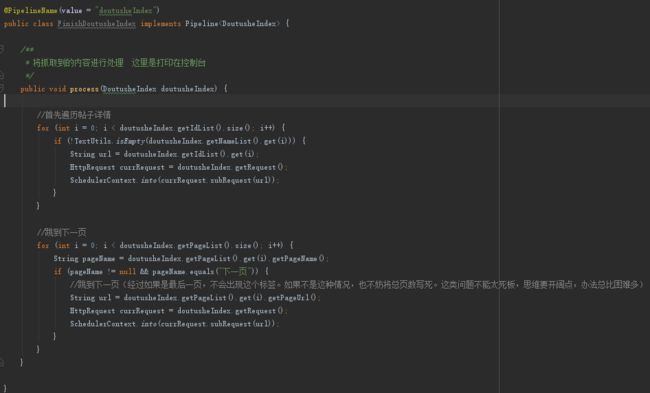
注:我们做好相关网页解析就好,如果访问了这个网页,url匹配的上的话,会调起解析程序,所以这里遍历的放心大胆的访问连接就可以了,不需要其他操作。
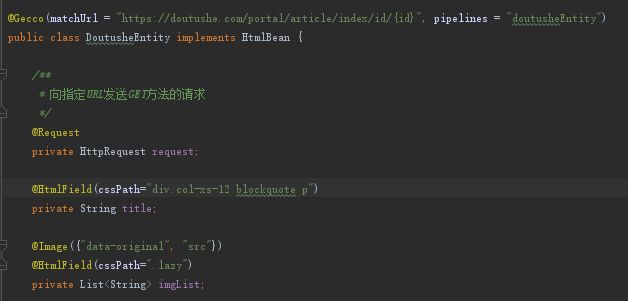
4、创建类DoutusheEntity、FinishDoutusheEntity
解析帖子详情,并对我们索需要的数据进行处理,该说的上面都说了,这里直接贴代码就好了。

最后输出的结果,随便贴一点:
5、调用