为什么80%的码农都做不了架构师?>>> 
总体框架
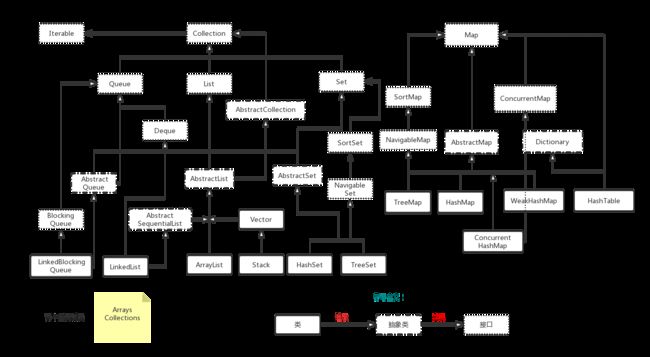
Java集合,总体框架及主要接口,抽象类分析
Java集合,Java中的队列都有哪些,有什么区别
Java集合,阻塞队列的基本结构
Java集合, ArrayBlockingQueue源码解析(常用于并发编程)
Java集合, LinkedBlockingQueue源码解析(常用于并发编程)
Java集合,ConcurrentLinkedQueue源码解析(常用于并发编程)
Java集合,ArrayList底层实现和原理
Java集合,LinkedList底层实现和原理(也是基于queue的实现)
Java集合,Vector底层实现和原理
Java集合,ConcurrentHashMap底层实现和原理(常用于并发编程)
Java之一致性hash算法原理及实现
Java集合,HashSet底层实现(由HashMap实现)和原理
Java集合,TreeSet底层实现(由TreeMap实现)和原理
Java集合,HashMap底层实现和原理(1.7数组+链表与1.8+的数组+链表+红黑树)
Java集合,TreeMap底层实现和原理
Java集合,LinkedHashMap底层实现和原理
下面对上面的文章做一下总结,一些在上面文章中没有涉及到的点,在详细的说明一下。
Set和Map的关系
Set代表一种无序不可重复的集合,Map代表一种由多个Key-Value对组成的集合。表面上看它们之间似乎没有啥关系,但是Map可以看成是Set的扩展。为什么这么说呢?看下面的这个例子:
在Map的方法中有一个这样的方法,Set
HashSet和HashMap的关系
HashSet和HashMap有很多的相似之处,对于HashSet而言,采用了Hash算法来决定元素的存储位置,HashMap而言,将value当成了key的附属品,根据Key的Hash值来决定存放的位置。
有一点需要说明一下,经常听说,集合存储的是对象, 这其实是不准确的。准确来说,集合中存储的其实是对象的引用地址或者称为引用变量。而引用地址或者引用变量指向了实际的java对象。java集合实际是引用变量的集合而非java对象的集合。
通过之前的源码解析其实可以发现,HashMap在存放key-value时,并没有过多的考虑value的内容。只是根据key来确定key-value对在数组中应该存放的位置。HashMap的底层是一个Entry[]数组,key-value组成了一个entry。当需要向HashMap中添加元素时,首先根据key的hashcode来确定在数组中存放的位置,如果key为null,采用特殊方法进行处理,存放在数组的0号位置。如果当前位置已经有元素存在,则遍历单链表,如果两个key相等,则用新值替换掉旧值,如果key不相等,则插入到链表中。有一点需要说明,在jdk8之前,hashmap使用数组+单链表存储,在8后,采用了数组+链表+红黑树存储。
对于HashSet要说的没有太多,HashSet的实现也是比较的简单,它的底层使用HashMap实现的,只是封装了一个HashMap对象来存储所有的集合对象。
TreeSet和TreeMap的关系
TreeSet底层采用了一个NavigableMap来保存TreeSet集合的元素,但实际上NavigableMap只是一个借口,因为底层依然是使用TreeMap来包含Set集合中的元素。 与HashSet类似,TreeSet也是调用TreeMap的方法来实现一些操作。TreeMap的底层是使用“红黑树”的排序二叉树来保存Map中的每个Entry.关于TreeMap的实现在上面的链接中有详细的解释,请自行查阅。
HashSet和HashMap是无序的,而TreeSet和TreeMap是有序的
ArrayList和LinkedList的关系
List代表的是一种线性结构,ArrayList则是一种顺序存储的线性表,ArrayList底层采用数组来保存每个元素,LinkedList是一种链式存储的线性表,本质是一个双向链表。
迭代器Iterator
fast-fail快速失败机制
在迭代的过程中,如果删除了某一个元素,collection会抛出ConcurrentModificationException异常。
为什么会出现这个异常呢?
这是因为在迭代时,某个线程对该collection在结构上进行了更改,从而产生fail-fast.当方法检测到对象修改后,但是不允许这种修改就会抛出该异常。fail-fast只是一种异常检测机制,JDK并不能保证该机制一定会发生。
通过一个demo来详细的说明下:
LinkedList list = new LinkedList();
list.add("a");
list.add("b");
list.add("c");
list.add("d");
for (String a : list) {
System.out.println(a);
list.remove(2);
}
执行上面的代码便会抛出 java.util.ConcurrentModificationException;
来看一下LinkedList remove()方法的源码:
//删除方法
public E remove(int index) {
checkElementIndex(index); //验证index是否合法
return unlink(node(index)); //调用unlink方法
}
E unlink(Node x) {
// assert x != null;
final E element = x.item;
final Node next = x.next;
final Node prev = x.prev;
if (prev == null) {
first = next;
} else {
prev.next = next;
x.prev = null;
}
if (next == null) {
last = prev;
} else {
next.prev = prev;
x.next = null;
}
x.item = null;
size--;
modCount++; //modCount+1 敲黑板划重点
return element;
}
关于上面代码的具体含义请自行查阅上面的文章。 上面代码在删除指定位置的元素后将执行私有内部类ListItr中的next()方法,进行下一个元素的遍历。
//在私有内部类ListItr中有如下的属性定义,再进行遍历时,将遍历对象的modCount值赋值给了expectedModCount。
private int expectedModCount = modCount;
public E next() {
checkForComodification();
if (!hasNext())
throw new NoSuchElementException();
lastReturned = next;
next = next.next;
nextIndex++;
return lastReturned.item;
}
final void checkForComodification() {
if (modCount != expectedModCount)
throw new ConcurrentModificationException();
}运行next()方法后,会先执行checkForComodification()方法,判断modCount与expectedModCount是否相等,不相等则抛出异常。
因为是遍历对象单方面改变的modCount值,ListItr并没有监测到,所以变造成了modCount和expectedModCount不相等的情况。于是出现了异常。我的理解是,在使用迭代器进行对象遍历时,创建了一个新的引用,而新引用指向了遍历的对象,同时将遍历对象的一些属性赋值给了迭代器对象。调用遍历对象的方法时,对象的属性发生变化,而迭代器对象中的遍历对象的拷贝唯有进行更新,导致了值得不匹配,从而抛出异常。这只是我的个人理解,欢迎深入交流。
采用下面的方法就不会出现该异常,是因为迭代器对象进行了属性的更新! 通过Iterator的方法删除后,保证了modCount与expectedModCount值的统一。
Iterator iterator = list.iterator();
while(iterator.hasNext()){
String str = iterator.next();
if(str.equals("a")){
iterator.remove();
}
}